似乎我们沉浸在高负荷开发的丛林中,以至于我们根本没有考虑基本问题。 以分片为例。 如果有可能在数据库设置中写入条件分片= n,并且一切将由其自己完成,那该怎么办? 没错,他是对的,但是,如果发生问题时,如果资源开始真正匮乏,我想了解是什么原因以及如何解决它。
简而言之,如果您要在Cassandra中贡献您的替代哈希实现,那么几乎没有任何启示。 但是,如果您的服务负担已经到来,而系统知识跟不上它,那么欢迎您。 伟大而可怕的
安德烈· 阿克索诺夫 (
shodan )会以通常的方式告诉我们,
分片是不好的,不是分片也是不好的 ,它是如何安排在内部的。 偶然地,关于分片的故事的一部分根本就不是真正的分片,而是魔鬼知道什么-如何将对象映射到分片。

印章的照片(即使它们偶然偶然变成了小狗)似乎已经回答了为什么这就是所有问题,但是我们将按顺序开始。
什么是分片?
如果您坚持不懈地使用google,事实证明,在所谓的分区和所谓的分片之间有一个相当模糊的边界。 每个人都比他想要的要调用任何东西。 有些人区分水平分区和分片。 还有人说分片是一种水平分区。
我没有找到一个可以由开国元勋批准并获得ISO认证的术语标准。 个人内心的想法是这样的:平均
划分是任意地“分割基础”。
- 垂直分区 例如,有一个巨大的表,在60列中有数十亿个条目。 我们没有保留一个如此巨大的表,而是保留了60个同样具有20亿条记录的巨大表-这不是兼职数据库,而是垂直分区(作为术语的示例)。
- 水平分区-我们在服务器内部逐行剪切。
这里的尴尬时刻是水平分区和分片之间的细微差别。 您可以将我切成碎片,但我不能肯定地告诉您它的组成。 感觉分片和水平分区是同一回事。
通常,如果针对数据库或文档,对象的集合(如果您没有数据库,而是文档存储)来切割大型表时,则专门针对对象进行分片。 也就是说,无论大小如何,都会选择20亿个对象。 每个对象内部的对象本身不会被切成碎片,我们不会分解成单独的列,即,我们将捆束布置在不同的位置。
链接到演示文稿以确保完整性。细微的术语差异已经存在。 例如,相对而言,Postgres开发人员可以说水平分区是指将主表划分为的所有表都位于同一方案中,而在不同的计算机上则是分片。
从一般意义上讲,与分片特定数据库和特定数据管理系统的术语无关,感觉分片只是逐行切片,依此类推-就是这样:
分片(〜=,\ in ...)是典型的水平分区==。
我通常会强调。 从某种意义上说,我们不仅要将20亿个文档切成20个表,每个表都将更易于管理,而且还要将其分发到许多核心,许多磁盘或许多不同的物理或虚拟服务器中。
可以理解,我们这样做是为了使每个碎片(每个数据shatka)都被复制多次。 但实际上,没有。
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
实际上,如果您进行这样的数据切片,并且从MySQL上的一个巨型SQL表中进行,您将在英勇的便携式计算机上生成16个小表,而不会超出单个便携式计算机,单个模式,单个数据库等。 等 -一切,您已经拥有分片功能。
记住带有小狗的插图,这将导致以下结果:
- 带宽在增加。
- 延迟不会改变,也就是说,在这种情况下,工人或消费者每个人都有自己的。 尚不清楚图片中有哪些幼犬,但是大约是在同一时间处理请求,就像幼犬是一个人一样。
- 或两者兼而有之,并且仍然具有高可用性(复制)。
为什么要带宽? 有时我们可能有不适合的数据量-不清楚在哪里,但不适合-由1 {core | 驱动器 服务器| ...}。 根本没有足够的资源,仅此而已。 为了使用此大型数据集,您需要对其进行剪切。
为什么要延迟? 在一个内核上,扫描20亿行的表比并行扫描20个内核上的20个表要慢20倍。 数据在一种资源上的处理速度太慢。
为什么要高可用性? 或者,我们为了同时执行一个和另一个操作而剪切数据,并且同时每个碎片的多个副本-复制可提供高可用性。
一个简单的例子,“如何用手做
可以使用测试表test.documents中的32个文档,并通过从该表中生成16个测试表,分别用于约2个文档test.docs00、01、02,...,15,来剪切条件分片。
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
为什么呢 因为先验的我们不知道id的分布方式,如果从1到32(含1和32),那么每个将有2个文档,否则就没有。
我们这样做是为了什么。 完成16个表之后,我们可以“捕获”所需的16个表。 无论我们基于什么,我们都可以并行处理这些资源。 例如,如果没有足够的磁盘空间,则有必要将这些表分解为单独的磁盘。
不幸的是,所有这些都不是免费的。 我怀疑在使用规范的SQL标准(我很长时间没有重新阅读SQL标准,也许很长时间没有更新)时,没有正式的标准化语法可以对任何SQL Server说:并将它们放在4张光盘上。” 但是在个别实现中,通常原则上会使用特定的语法来执行相同的操作。 PostgreSQL有分区机制,MySQL MariaDB有分区机制,Oracle很久以前就完成了所有这些工作。
但是,如果我们在没有数据库支持的情况下并且在标准框架内手动进行此操作,那么我们将
有条件地支付访问数据的复杂性 。 那里有一个简单的SELECT * FROM文档,其中id = 123,现在是16 x SELECT * FROM docsXX。 好吧,如果我们尝试按键获取记录。 如果我们尝试尽早获得记录,那就更加有趣了。 现在(如果我强调,就好像傻瓜一样,并且仍然在标准之内),这16个SELECT * FROM的结果必须在应用程序中合并。
预期会有什么性能变化?- 直观地线性。
- 从理论上讲是次线性的,因为阿姆达尔定律 。
- 实际上-可能几乎是线性的,也许不是。
实际上,正确答案是未知的。 通过巧妙运用分片技术,您可以在应用程序的操作中实现显着的超线性下降,甚至DBA都将使用炙手可热的扑克。
让我们看看如何实现这一目标。 显然,仅将设置设置为PostgreSQL shards = 16,然后它就自动退出了-这并不有趣。 让我们考虑一下如何实现
从分片减慢到32倍的速度 ,这从不这样做的角度来看很有趣。
我们加速或减速的尝试始终会违背经典-古老的阿姆达尔定律,该定律说,对任何请求都没有完美的并行化,总有一些一致的部分。
阿姆达尔定律
总有一个序列化的部分。
请求的执行总有一部分是并行的,并且总有一部分不是并行的。 即使您认为完全并行的查询(至少从每个分片接收的行中收集要发送给客户端的结果行)也总是存在,并且始终是一致的。
总有某种顺序的部分。 它可能很小,在一般背景下是绝对不可见的,它可能是巨大的,因此会严重影响并行化,但始终存在。
此外,它的影响力正在
发生变化,并且可能会显着增长,例如,如果我们削减表格(让我们提高利率)从64条记录变为16条表(共4条记录),那么这部分将发生变化。 当然,从如此庞大的数据量来看,我们使用的是手机和86 MHz处理器,因此没有足够的文件可以同时打开。 显然,有了这样的输入,我们一次打开一个文件。
- 总计= 串行+ 并行 。 例如,并行是数据库内部的所有工作,而串行则将结果发送给客户端。
- 它变为Total2 =串行+并行/ N + Xserial。 例如,当一般ORDER BY时,Xserial> 0。
通过这个简单的示例,我尝试显示一些Xserial出现。 除了总有一个序列化的部分以及我们试图并行处理数据这一事实外,还有一个附加部分似乎可以确保对数据进行切片。 粗略地说,我们可能需要:
- 在内部数据库字典中找到这16个表;
- 打开文件;
- 分配内存;
- 重新定位内存;
- 染色结果;
- 核心之间同步;
任何不同步的效果总是会出现。 它们可以忽略不计,并占总时间的十亿分之一,但是它们始终为非零且始终存在。 在他们的帮助下,分片后我们可能会大大损失生产力。
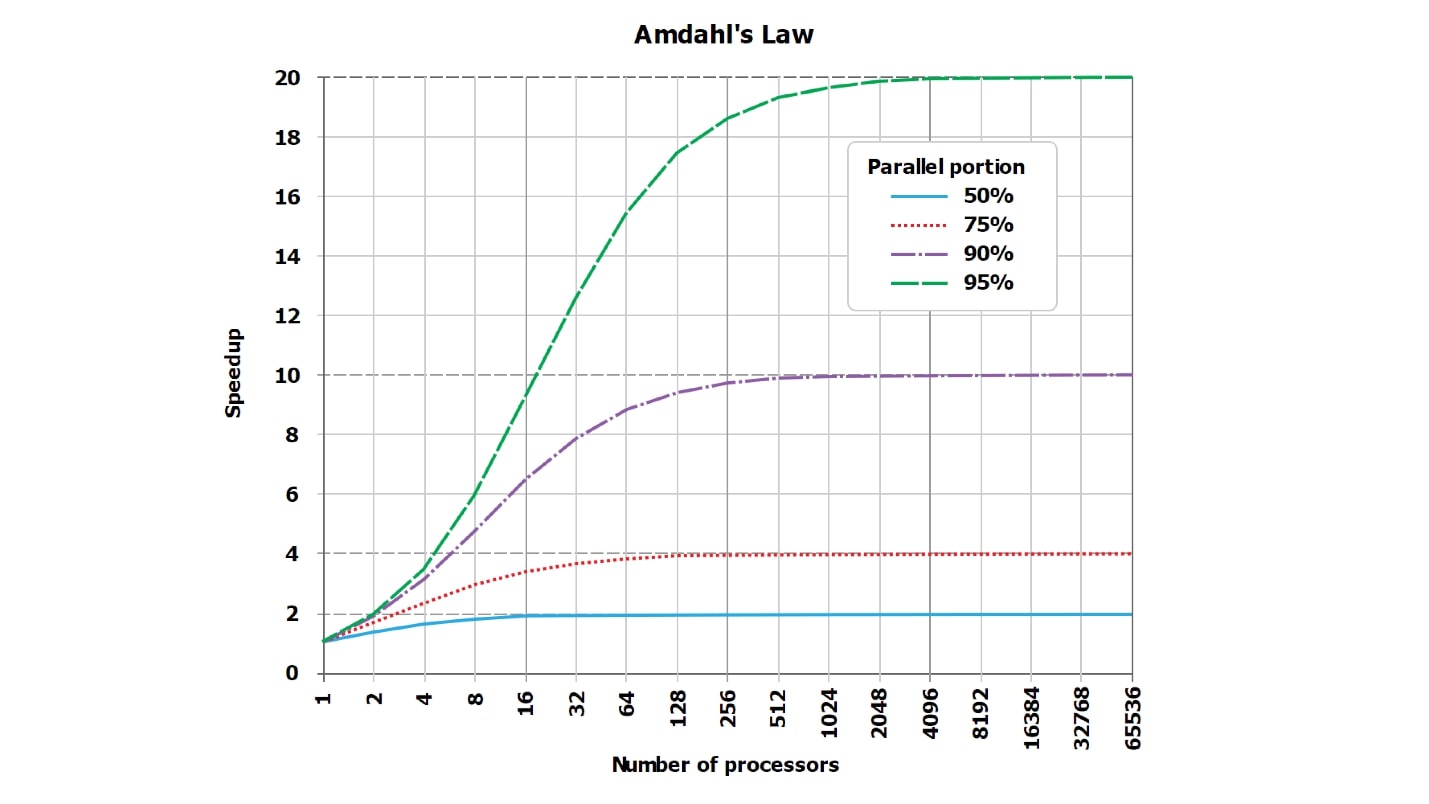
这是关于阿姆达尔定律的标准描述。 它不是很易读,但是重要的是,直线应该理想地是直的并且呈线性增长,并且紧挨渐近线。 但是,由于无法读取Internet上的图表,因此,我认为我制作了带有数字的更直观的表格。
假设我们在请求处理中有一些序列化的部分,只占5%:
serial = 0.05 = 1/20。凭直觉看,似乎序列化部分仅占用请求处理的1/20,如果我们将请求的处理并行化为20个内核,则它将变成大约20个,在最坏的情况下,速度会快18倍。
实际上,
数学是无情的事情 :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)事实证明,如果仔细计算,序列化部分为5%,则加速度将是10倍(10.3),与理论理想值相比,这是51%。
| 8核 | = 5.9 | = 74% |
| 10芯 | = 6.9 | = 69% |
| 20芯 | = 10.3 | = 51% |
| 40核 | = 13.6 | = 34% |
| 128核 | = 17.4 | = 14% |
使用20个内核(如果需要,可以使用20个磁盘)来完成以前完成的任务,理论上讲,我们获得的加速永远不会超过20倍,而实际上却很少。 此外,随着并联数量的增加,效率低下的情况正在迅速增长。
当仅剩下1%的序列化工作而99%并行化时,加速度值会有所改善:
| 8核 | = 7.5 | = 93% |
| 16核 | = 13.9 | = 87% |
| 32核 | = 24.4 | = 76% |
| 64核 | = 39.3 | = 61% |
对于一个自然热核的查询,该查询自然会运行几个小时,而准备工作和组装结果只需很少的时间(序列= 0.001),我们已经看到了很好的效率:
| 8核 | = 7.94 | = 99% |
| 16核 | = 15.76 | = 99% |
| 32核 | = 31.04 | = 97% |
| 64核 | = 60.20 | = 94% |
请注意,
我们永远不会看到100% 。 在特别好的情况下,您可以看到例如99.999%,但不完全是100%。
如何在N次洗牌和破门?
您可以准确地随机播放N次:
- 按顺序而不是并行发送docs00 ... docs15请求。
- 在简单查询中,不要按键选择WHERE something = 234。
在这种情况下,序列化的部分(序列)在现代数据库中所占的比例不是1%而不是5%,而是大约20%。 如果使用非常有效的二进制协议访问数据库或将其作为动态库链接到Python脚本,则可以获得序列化部分的50%。
一个简单请求的其余处理时间将由解析请求,准备计划等非并行操作占用。 也就是说,它会减慢不读取记录的速度。
例如,如果将数据分成16个表并按顺序运行(例如PHP编程语言中的惯例(它不知道如何很好地运行异步流程)),那么速度只会降低16倍。 并且,也许更多,因为还将添加网络往返。
在分片时,突然需要选择一种编程语言。
我们记得编程语言的选择,因为如果您将查询顺序发送到数据库(或搜索服务器),那么加速来自何处? 而是会出现减速。
生活中的自行车
如果选择C ++,请
写入POSIX线程 ,而不要
写入 Boost I / O。 我看到了来自Oracle和MySQL本身经验丰富的开发人员的出色库,他们在Boost上编写了与MySQL服务器的通信。 显然,他们在工作中被迫用纯C语言编写,但随后他们设法转过身来,采用带有异步I / O的Boost,等等。 一个问题-这个异步I / O,理论上应该并行驱动10个请求,由于某种原因,它内部有一个看不见的同步点。 并行启动10个请求时,它们的执行速度比一个请求慢20倍,因为对请求本身执行10次,对同步点执行一次。
结论:用实现并行运行并很好地等待不同请求的语言编写。 老实说,我不知道除了Go之外还有什么建议。 不仅是因为我真的很喜欢Go,还因为我没有更合适的东西。
不要使用不合适的语言编写语言 ,因为这些
语言无法对数据库运行20个并行查询。 或抓住每一个机会,不要用手做所有-了解其工作原理,但不要手动进行。
A / B测试车
有时您会放慢速度,因为您已经习惯了一切正常的事实,而您没有注意到序列化的部分,首先,其次是很大的部分。
- 立即〜60个搜索索引分片,类别
- 在主题范围内,这些是正确的碎片。
- 最多有1000个文档,并且有50,000个文档。
这是一款量产自行车,当搜索查询略有更改,并且他们开始从60个搜索索引碎片中选择更多文档时。 一切都迅速进行,并遵循以下原则:“有效-请勿触摸”,他们全都忘记了,实际上位于60个碎片中。 我们将每个分片的采样限制从一千个文档增加到五万个文档。 突然,它开始变慢,并行性停止了。 根据分片执行的请求本身进行得非常顺利,并且从60个分片中收集了5万份文档,因此阶段变慢了。 将这300万个最终文档放在一个核心上,进行合并,排序,然后选择300万个文档中的最高文档并提供给客户。 相同的系列部分放慢了速度,相同的安道尔残酷法则起作用了。
因此,也许您不应该用手来分片,而应该是人类
告诉数据库:“执行!”
免责声明:我真的不知道该怎么做。 我就像从错误的地板上!
在我整个有意识的生活中,我一直在倡导一种称为“算法原教旨主义”的宗教。 它的简要表述非常简单:
您实际上并不想做任何事情,但是了解它在内部的排列方式非常有用。 这样一来,当数据库中出现问题时,您至少应了解那里出了什么问题,它在内部的排列方式以及如何修复。
让我们看一下这些选项:
- “手 。 ” 之前,我们手动将数据分割成16个虚拟表,然后用手重写所有查询-这样做非常不舒服。 如果有机会不洗手-请勿洗手! 但是有时这是不可能的,例如,您拥有MySQL 3.23,然后必须这样做。
- “自动”。 碰巧您可以自动或几乎自动地进行改组,而当数据库可以分发数据本身时,您只需要在某个地方写一个特定的设置即可。 有很多基础,并且它们有很多不同的设置。 我敢肯定,在每个可能写入分片= 16(无论语法如何)的数据库中,引擎都会将许多其他设置粘合到这种情况。
- “半自动” -在我看来,这是一种完全宇宙的,残酷的模式。 也就是说,基础本身似乎不能够,但是存在外部附加补丁。
除了将机器发送到适当数据库(MongoDB,Elastic,Cassandra等……通常称为NoSQL)上的文档外,很难说出有关机器的信息。 如果幸运的话,只需拉一下“让我16个碎片”开关,一切都会正常。 那时,当它不起作用时,可能需要本文的其余部分。
关于半自动装置
在某些地方,尖端的信息技术激发了声波恐怖的恐惧。 例如,开箱即用的MySQL确实没有实现对某些版本的分片,但是可以肯定的是,在战斗中使用的基础大小已增长到不合理的值。
面对单个DBA所遭受的苦难已经折磨了多年,并编写了一些无缘无故构建的不良分片解决方案。 此后,编写了一个或多或少不错的分片解决方案,称为ProxySQL(MariaDB / Spider,PG / pg_shard / Citus等)。 这是同一套外套的著名例子。
当然,ProxySQL整体是一个完整的企业级解决方案,适用于开源,路由等。 但是要解决的任务之一是对数据库进行分片,而数据库本身并不知道如何人工分片。 您会看到,没有“ shards = 16”开关,您必须重写应用程序中的每个请求,并且有很多请求,或者在应用程序和看起来像这样的数据库之间放置一个中间层:“ Hmm ... SELECT * FROM document? 是的,必须撕成16个小SELECT * FROM server1.document1,SELECT * FROM server2.document2-到使用该用户名/密码的服务器,再到另一个。 如果一个人没有回答,那么……”等等。
确切地说,这可以通过中间补丁来完成。 它们比所有数据库都要少。 据我了解,对于PostgreSQL,同时有一些内置解决方案(我认为PostgresForeign数据包装器内置于PostgreSQL本身)中,有外部补丁程序。
配置每个特定的补丁程序是一个单独的重要主题,不会包含在一个报告中,因此我们将仅讨论基本概念。
让我们更好地讨论一下嗡嗡声理论。
绝对完美的自动化?
在这个字母F()
shard_id = F(object).片的情况下,整个嗡嗡声理论的基本原理
总是相同的:
shard_id = F(object).分片一般是关于什么的? 我们有20亿条记录(或64条记录)。 我们想将它们分成几部分。 一个意外的问题出现了-如何? 我应根据什么原则将20亿条记录(或64条记录)分散到16台可供我使用的服务器上?
我们中潜在的数学家应该建议,最终总会有一个魔术函数,对于每个文档(对象,线等),都将决定将其放在哪一块。
如果我们更深入地研究数学,则此功能不仅总是取决于对象本身(线本身),还取决于外部设置,例如分片总数。 对于每个对象必须说出放置位置的函数,返回的值不能超过系统上的服务器数量。 和功能有些不同:
- shard_func = F1 (对象);
- shard_id = F2 (shard_func,...);
- shard_id = F2 ( F1 (object),current_num_shards,...)。
但是更进一步,我们不会深入探讨各个函数的丛林,我们只讨论什么是魔术函数F()。
什么是F()?
他们可以提出许多不同的实施机制。 样本摘要:
- F = rand ()%nums_shards
- F = 哈希 (object.id)%num_shards
- F = object.date%num_shards
- F = object.user_id%num_shards
- ...
- F = shard_table [somehash()| ... object.date | ...]
一个有趣的事实-您可以自然地随机分散所有数据-我们将下一条记录扔到任意服务器,任意内核,任意表中。 这样做不会带来太多快乐,但它会起作用。
有一些更聪明的方法来骗取可重现甚至一致的哈希函数,或者针对某些属性进行骗局。 让我们来看看每种方法。
F =兰德()
散布不是一个非常正确的方法。 问题之一:我们随机散布了每千个服务器20亿条记录,而我们不知道记录在哪里。 我们需要拉用户_1,但是我们不知道它在哪里。 我们进入一千台服务器,对所有内容进行分类-某种程度上效率低下。
F =哈希()
让我们以成年人的方式分散用户:从user_id中读取复制的哈希函数,将剩下的部分除以服务器数量,然后立即联系所需的服务器。
我们为什么要这样做? 然后,我们的负载很大,一台服务器也没有任何东西。 如果相互干涉,生活将会如此简单。好了,情况已经好转了,要获得一张记录,我们去了一台著名的服务器。 但是,如果我们有一定范围的密钥,那么在所有这些范围中,我们都需要对所有密钥值进行排序,并且限制范围内的碎片数量要与我们在该范围内拥有的密钥数量一样多,或者通常是每个服务器。 情况当然有所改善,但并非针对所有要求。 一些请求已受到影响。
自然分片(F = object.date%num_shards)
有时,通常是95%的流量和95%的负载是具有某种自然分片的请求。 , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- 哎呀
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
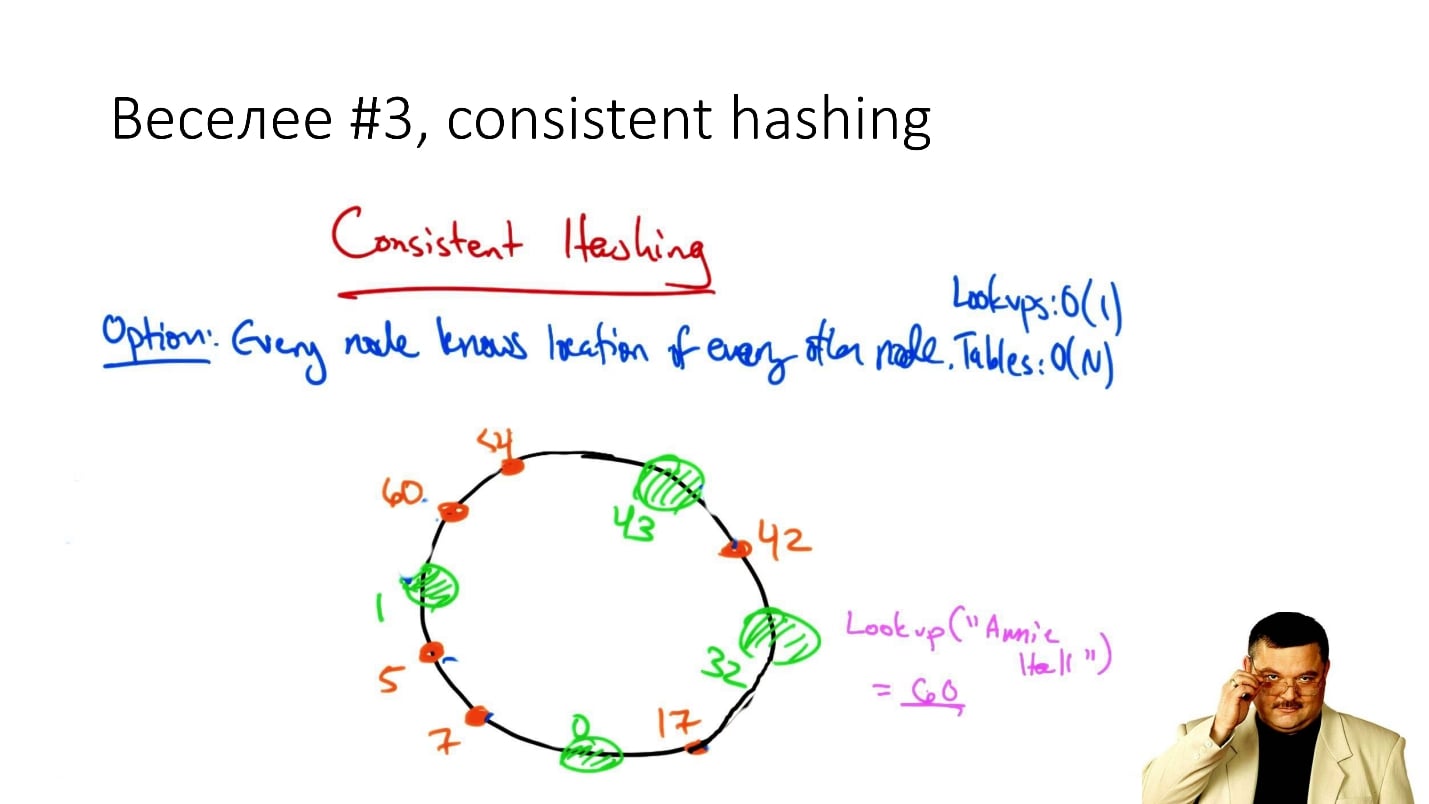
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
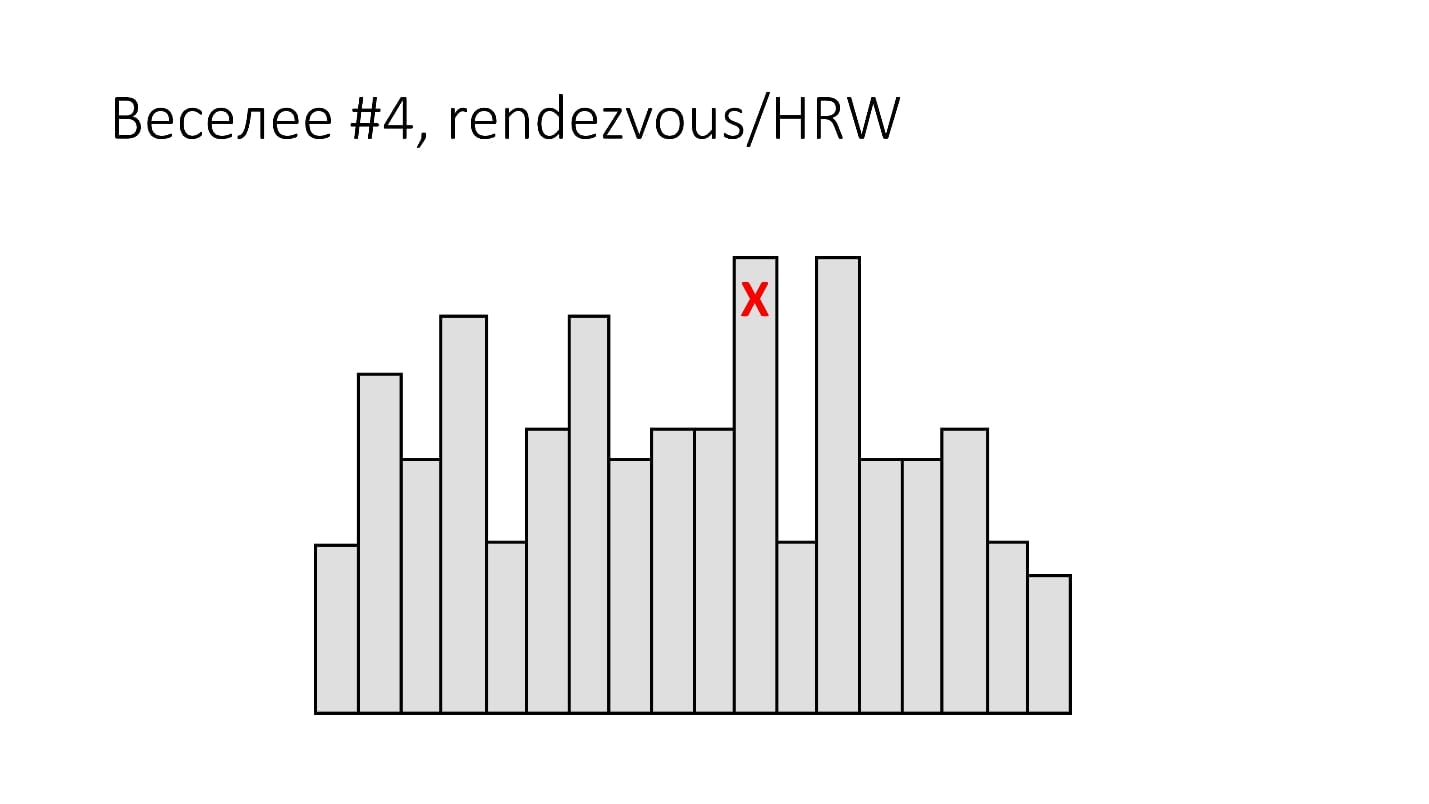
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
结论
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .