
我们努力确保在向用户订购出租车后,会向用户提供一辆清洁,可维修的,具有该应用程序中所显示品牌,颜色和编号的汽车。 为此,我们使用了远程质量控制(DCC)。
今天,我将向Habr的读者介绍如何在数十万台快速发展的服务中使用机器学习来降低质量控制的成本,以及如何将不符合服务规则的机器投入生产。
机器学习之前DCC如何安排
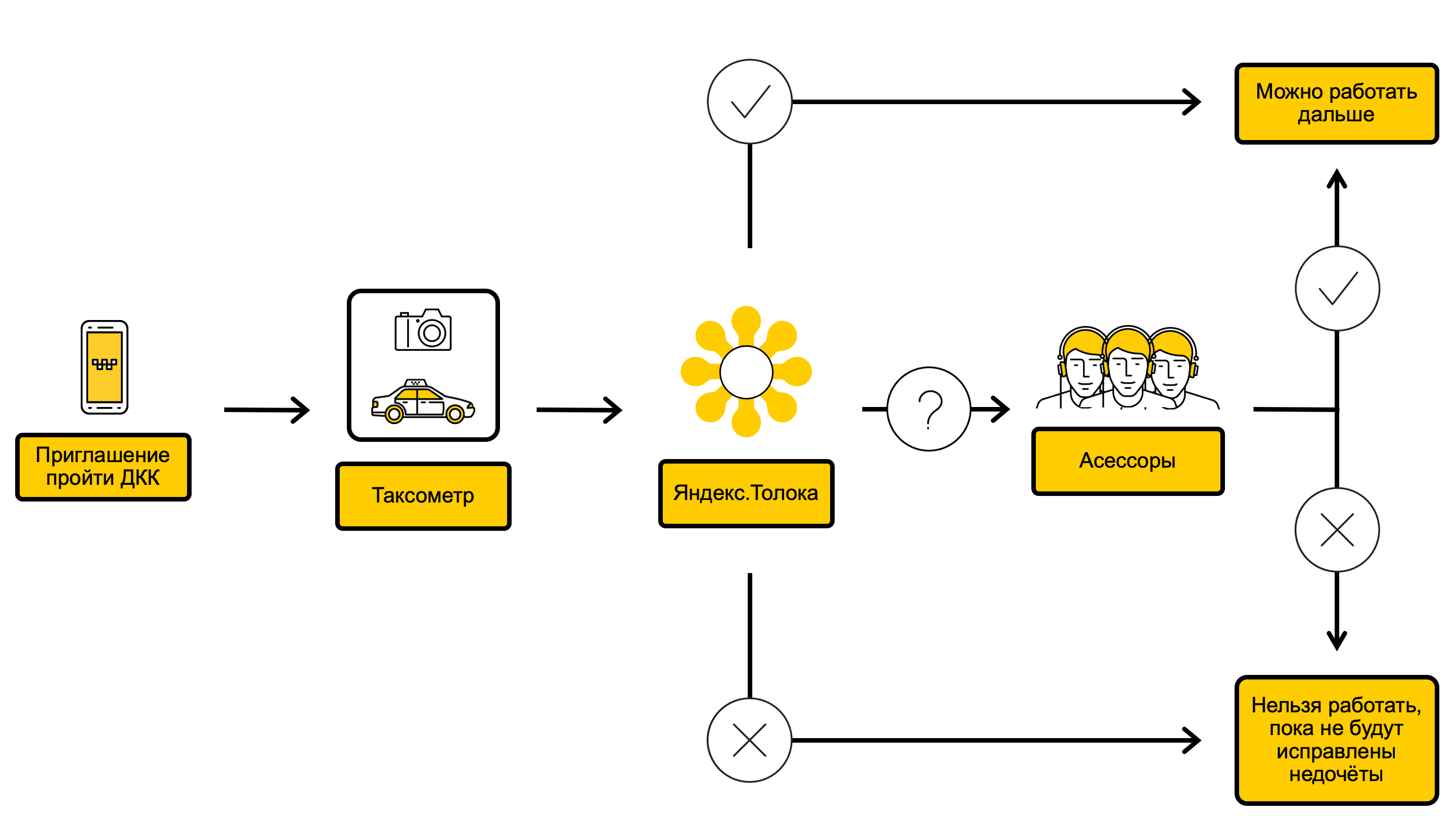
DCC流程图
在DCC流程中,我们检查汽车的照片,并决定是否可以履行此类汽车的订单,或者例如是否应先洗车。 一切始于以下事实:通过驱动程序应用程序出租车计价器,我们在DCC上调用了驱动程序。 这通常每10天发生一次,但有时会更少或更频繁-这取决于驾驶员通过先前检查的成功程度。 呼叫DCC之后,驱动程序会立即收到一条消息,邀请他们进行光控。 驾驶员接受邀请后,在同一应用程序中,他从不同角度拍摄了汽车的内部和内部,并发送了Yandex.Taxi照片。 DCC开启时,驾驶员可以接订单。

出租车计价器应用程序中的DCC开始屏幕

在计程表应用程序中为汽车拍照的屏幕
生成的照片将落入Yandex.Toloka中 -使用众包,您可以快速执行简单但大量的任务。 关于它的工作原理以及为什么需要Yandex.Tolok,我们在博客上写道。
在Yandex.Tolok中,在一次检查过程中,至少有三名表演者回答了有关汽车状况的问题,如果表演者根据他们的回答同意,则将决定驾驶员是否可以接受命令。 Yandex.Tolok中的检查有两个结果:
- 如果汽车在视觉上一切正常,驾驶员将继续接受命令。
- 如果汽车脏了,损坏了,或者其品牌,颜色或编号与驾驶员证上显示的不一致,则Yandex.Taxi会暂时限制驾驶员接受订单的能力。
如果表演者未能达成共识,则将照片发送给Yandex.Taxi员工-评估人员,他们会更彻底地检查汽车,然后做出最终决定。 评估人员接受了特殊的培训计划,并拥有更多的经验。

看到DCC执行者Yandex.Tolki
挑战赛
随着Yandex.Taxi的发展,DCC检查的数量也在增加,这意味着托船商和评估员的成本也在增加。 另外,检查汽车的速度下降。 在进行DCC时,您可以允许驾驶员接受或不接受订单。 两种选择都有其缺点:在第一种情况下,不道德的驾驶员将有时间接受不符合标准的汽车上的几笔订单,第二种-所有要求进行照片控制的驾驶员在检查完成之前将无法工作。 因此,快速检查汽车非常重要,这样用户和驾驶员都不会受到任何不便。
观察成本和平均检查时间的图表如何增长,我们意识到我们想降低Toloka,卸货评估员的成本并减少平均检查时间,换句话说,就是要使部分检查自动化。 自然,我们不想牺牲服务质量,而错过更多不符合生产线质量标准的汽车,也不想限制真正驾驶员接受订单。 我们需要使DCC自动化,同时又不增加检查总体流程中的错误份额。
我们如何在DCC实施机器学习
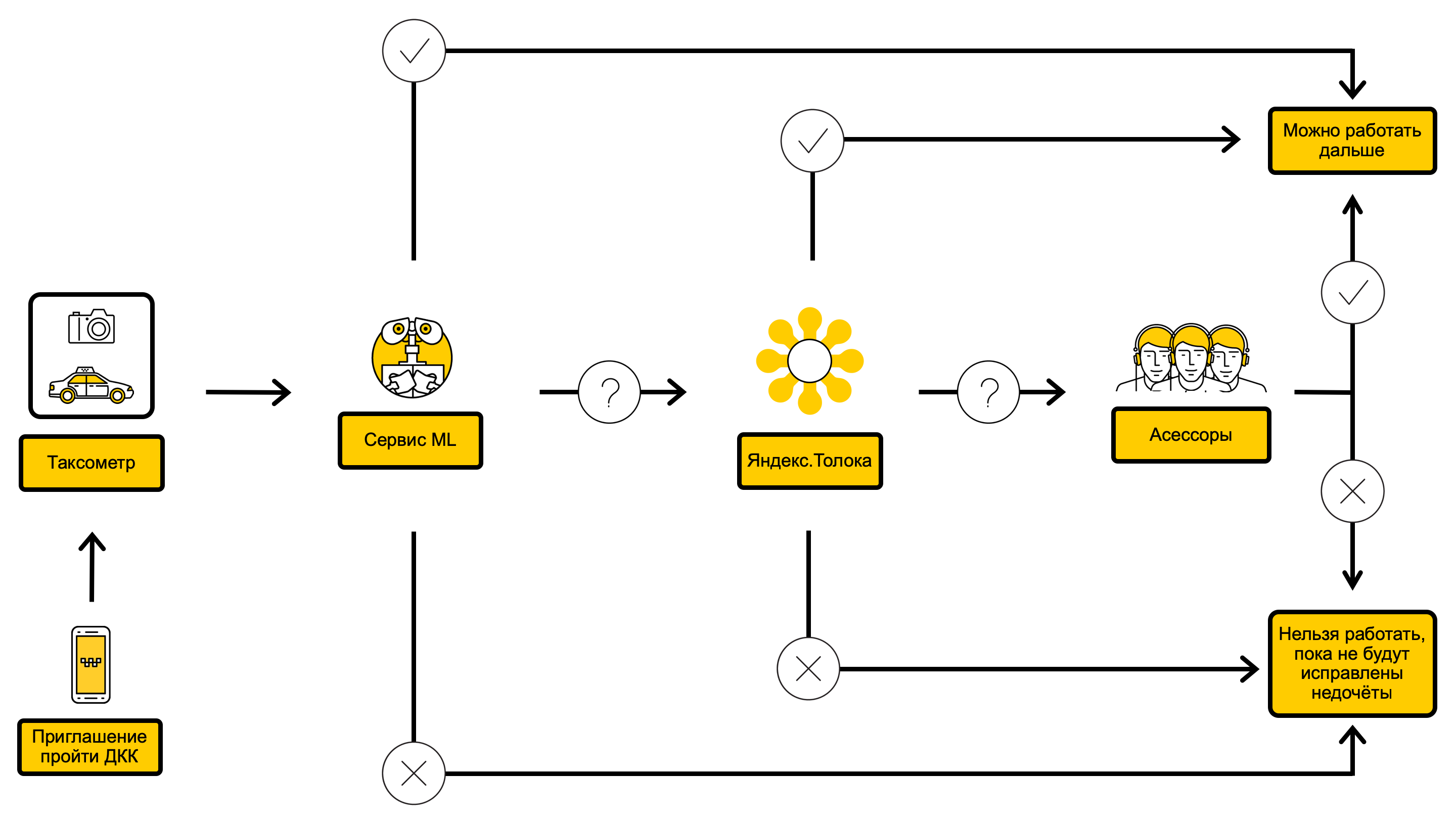
内置ML的DCC流程图
首先,我们决定对问题进行声明:在不增加总体流程错误率的情况下,使尽可能多的检查自动化。
让我们找出我们的任务中有哪些错误。 它们有两种形式: 错误肯定和错误否定 。 用我们的术语来说, 否定是驾驶员可以继续工作的检查结果,而肯定是对订单接收有时间限制的结果。 然后, 假阴性是一种情况,在这种情况下,我们被迫允许不良汽车的驾驶员下订单,而假阳性 –相反,当我们不允许驾驶员与质量好的汽车一起工作时。 事实证明,假阴性率(FNR)是允许我们接受订单的“不良”汽车驾驶员的比例,假阳性率(FPR)是我们不允许与之合作的驾驶员的百分比,尽管他们对汽车的看法很好。 因此,从将机器学习引入系统后,我们希望做到以下几点:与没有机器学习的系统相比,在不增加FPR和FNR的情况下,使尽可能多的检查自动化。
此外,有必要了解在选择模型和阈值以基于其预测进行决策时应遵循哪些度量标准。 从问题的情况可以明显看出,我们对三个数量感兴趣:
- 机器学习模型可以自动回答的那部分线程。
- FNR系统。
- FPR系统。
我们在观察第二个和第三个限制的同时最大化第一个值。
这可能会引起一个问题:为什么不直接通过自动支票而不是通过省钱来最大程度地节省资金或最小化平均扫描时间呢? 优化资金是一个非常诱人的想法,但是通常很难实现。 在我们的案例中,节省包括两个因素:第一个是每次自动检查所节省的成本,因为每次检查都是在评估人员处或在Yandex中进行。 第二-从减少错误的数量中节省成本,因为每个错误都要花费Yandex.Taxi钱。 客观地计算错误给我们造成的损失是一项非常艰巨的任务,因此我们仅受第一个因素的限制而无法计算节约。 此值在自动检查的比例中单调增加,因此可以最大化这一部分而不是节省。 相同的推理适用于平均DCC时间;它也会根据自动检查的份额单调减少。
选型
可以说,DCC检查简化为从照片中对有关汽车状态的许多问题的答案选项的选择,这听起来像是图像分类任务。 这些任务是通过计算机视觉解决的,而在我们这个时代是一种特定的工具,即卷积神经网络。 我们决定将它们用于DCC自动化。
第一种解决方案或“一次全部”的方法
既然我们已经了解了要优化的内容以及原因,现在该是收集数据和训练模型的时候了。 收集数据很容易,因为所有DCC检查都被记录并以方便的形式存储。 在该解决方案的第一个版本中,从四个角度拍摄了汽车外部和内部的照片,汽车的品牌,型号和颜色,以及之前进行的10次DCC检查的结果。 作为目标变量,我们采用了所有验证问题的答案,例如:“汽车是否损坏?” 或“汽车的颜色与驾驶员证上的颜色匹配吗?” 主要目标变量是对以下主要问题的答案:“是否有必要限制驾驶员接受命令的能力?” 我们教了一个非常类似于VGG并具有SENet注意的大型模型,可以同时回答所有问题,结果我们遇到了几个问题。

多合一方法
“一次全部”方法的问题:
- 我们无法回答关于驾驶证上所显示照片中的汽车编号的问题。 大型的图像分类网络无法解决此任务,为此,我们需要一种特殊的光学字符识别(OCR)模型,该模型应经过改进以识别车牌。
- 目标变量不完整且嘈杂。 评估人员发现汽车外观上存在严重缺陷,足以做出决定,因此常常忘记回答其他问题。 因此,如果照片中的汽车既脏又破,那么我们很可能只观察到其中一个标记:“脏车”或“有损坏的汽车”,而我们的模型则需要这两个模型。
- 模型解决方案没有可解释性。 该模型可以以高于随机性的准确性来回答主要验证问题,但是该答案与其他问题的答案之间存在弱关联。 换句话说,如果答案是:“必须限制接受订单的能力”,那么在模型的其余答案中,我们几乎看不到做出这一决定的原因。 通常,除了主要问题外,所有问题答案的准确性都接近随机性。 我们无法向驾驶员解释要再次下订单到底需要解决的问题,这意味着我们不能限制驾驶员下订单的能力。
- 问题答案中的假阴性错误数量:“是否有必要限制驾驶员下订单的能力?” -太大,无法开始自动批准检查。 我们无法提供与没有机器学习的系统相同的FNR,这是我们任务的要求之一。
这四个原因在一起使我们无法将第一个解决方案付诸实践,但是我们并没有灰心,而是提出了第二个解决方案。
第二种解决方案,或“全部但逐步”的方法
我们决定重点检查汽车的外观,因为它们占总流量的70%。 此外,我们决定将一般任务划分为子任务,并学习如何分别回答所有DCC问题。

处理“一切,但逐步”
曾几何时,我们的服务已经从事DCC自动化,并设法引入了一种模型,该模型可让您过滤暗淡和不相关的照片。 我们继续使用该模型来回答以下问题:“是否存在以下汽车的真实照片:前,左侧,右侧,后部?”。
我们在第二种解决方案上的工作始于我们使用Yandex 搜索计算机视觉服务模型(来自制造DeepHD的人 )来识别汽车牌照。 因此,我们能够回答以下问题:“汽车区域的编号和代码是否完全与驾驶员证上显示的一致?” 如果我们更详细地讨论这个问题,我们会将识别结果与驾驶证上指示的数字进行比较,并根据它们之间的Levenshtein距离,选择以下答案选项之一:“数字匹配”,“数字不匹配”或“问题无法完全回答”。
接下来,我们训练了汽车分类器,以识别品牌和型号以及颜色。 从这一刻起,我们可以回答以下问题:“驾驶员证上是否标明了汽车的品牌,型号和颜色?”
总而言之,我们训练了分类器以发现损坏和肮脏的汽车,这使我们得以解决以下问题:“车身是否有任何损坏或缺陷?” 和“车身有多脏?”
“从头到尾”的方法使我们能够解决检查汽车车牌号的问题。 我们还能够摆脱目标变量的不完整和嘈杂,因为现在我们可以选择否定类对象是完全成功的检查对象,而肯定类对象则是在评估者或所有三个Yandex都进行了检查的地方。 。 解决了前两个问题之后,我们的模型就变得可以解释了,我们可以向驾驶员解释限制的原因,以便在下一次测试中他可以纠正缺陷。 问题答案的整体质量也显着提高,并且模型置信度阈值的某些组合的FPR和FNR已降至Yandex.Tolki级别,从而使模型可以投入生产。
在生产中实施
我们可以选择:启动常规流程,将模型应用于队列中累积的检查,或者提供单独的服务,您可以在其中通过API并实时接收模型响应。 由于快速找到“不良”汽车对我们很重要,因此我们选择了第二个选项。 一旦编写了服务的主要部分并能够支持必要的功能,我们便开始向其中添加模型。
要完全批准检查,您必须能够回答说明中的所有问题,但是为了限制不道德的驾驶员访问该服务,在某些情况下,至少可以回答一个问题就足够了。 因此,我们决定不等所有模型准备就绪,而是在它们可用时添加它们。 添加模型的通用管道如下所示:
- 收集样品。
- 训练模型。
- 测量质量并离线选择阈值。
- 在后台向服务中添加模型,并在线评估质量。
- 将模型包含在生产中,并根据其预测开始做出决策。
这种方法不仅使我们能够在引入新模型时立即发现越来越多的“不良”汽车,而且还可以在模型在后台运行时在线测量质量而无需花费额外的时间成本。
最后,是我们添加到服务并测试最新模型的时刻。 现在我们可以回答所有检查问题,这意味着它们将自动获得批准。 由于Yandex.Taxi中的“好”汽车比“坏”汽车多,因此自动批准检查导致我们的主要指标(自动检查的一部分)急剧增加。 我们只能选择正确的阈值,以最大化自动检查的份额,同时将整个系统的整体FPR和FNR保持在同一水平。 为了选择阈值,我们使用了一个由Yandex.Tolki执行者,评估员和Yandex.Taxi雇员独立标记的样本,后者训练了评估员检查汽车。 我们将其标记用作目标变量的真实值。
结果
一旦我们在生产中加入模型,就必须根据其答案来评估决策的在线质量。 这是我们看到的数字:
- 现在,有30%的车辆外观检查收到了自动回复。
- FNR保持不变,而FPR却下降了,我们开始越来越少地限制那些不应该获得服务的人使用服务。
- 评估人员的负担减少了14%,他们能够将更多的时间投入到机器学习服务无法进行的复杂测试中。
- 在检查过程中,对具有严重缺陷的汽车的检测时间从几小时减少到了几秒钟。
因此,机器学习的引入不仅帮助节省金钱,而且使服务对于用户而言更加安全和舒适。 但是,这还远没有结束。 我们快速发展的团队将继续积极工作,以实现更多检查的自动化,并使Yandex.Taxi更加便捷,舒适和安全。
历史道德
在Yandex.Taxi中进行DCC自动化时,我们遇到了许多问题,找到了一些成功的解决方案,并得出了六个重要结论:
- 并非总是可以直接解决问题(即使您有深度学习)。
- 该模型与经过训练的数据一样好(听起来很老套,但确实如此)。
- 在解决任何问题时,重要的是要建立在业务的实际需求上,而不是最小化交叉熵。
- 尽管已经引入了机器学习,但在解决某些问题中,人仍然很重要(您好,Yandex.Toloka!)。
- 并非在所有情况下都基于机器学习模型的预测做出决策,而只能在模型对答案非常有信心的那部分做出决策。 在其他情况下,值得在人们的帮助下以旧的方式做出决策。
- 除了选择体系结构和模型培训之外,项目的更多阶段会极大地影响解决业务问题的能力。 这些阶段包括:数据收集,质量指标的选择,模型实施选项,基于模型预测的产品决策逻辑等等。
更多关于技术出租车的有趣信息
动态定价,或Yandex.Taxi如何预测高需求 。
Yandex.Taxi如何使用机器学习预测汽车交付时间 。