在开发产品时,他们很少充分注意产品性能以及高强度的传入请求。 很少或根本没有这样做-专家没有足够的时间,或者他们用典型的短语为自己辩护:“一切在产品上都能与我们快速合作,所以为什么还要检查其他东西呢?” 在这种情况下,有时可能会由于游客激增(例如在哈布拉效应下)而使正常运转的产品突然下降。 然后很明显,对生产率进行研究确实是必要的。
这项任务使许多人感到困惑,因为有需要,但是对什么以及如何测量以及如何解释结果没有清晰的了解,有时还没有形成的非功能性要求。 接下来,我将讨论如果您决定走这条路的起点,并说明在绩效研究中哪些指标很重要以及如何使用它们。
一点理论
想象一下,我们在真空中有一个球形应用程序-它接收请求并给出请求的答案。 为简单起见,它可以是一种微服务,其一种方法不会随处可见,并且不依赖于其他组件或应用程序。 在这种情况下,我们对它的内容,工作方式和启动环境并不感兴趣。
我们想了解总体性能? 最好了解稳定该服务的传入请求的最大流,该流的性能以及完成一个请求所花费的时间。 如果您可以确定限制生产率进一步增长的原因,那将非常好。
显然,您需要通过传入请求的流量或强度分别衡量对请求的响应时间,我们将表示每单位时间(通常为每秒)的请求数和性能-对相同时间单位的响应数。 响应时间可以分散在很宽的范围内,因此从一开始就将它们表示为平均每秒是有意义的。
此外,问题可能会在各个级别出现:首先,该服务会回答一个错误(如果它是500,那是很好的,而不是“ 200 OK {“ status”:“ error”}“),最后是,完全停止响应,或者在网络级别开始丢失答案。 需要能够捕获不成功的请求,并且方便地将请求占总数的百分比显示出来。 性能,响应时间以及错误率与强度的关系图如下所示:
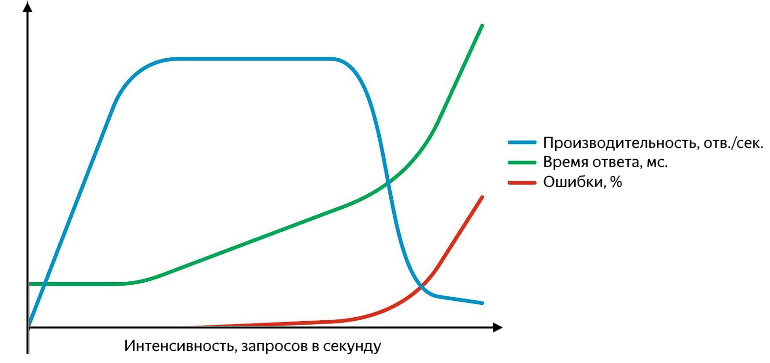
随着查询强度的增加,响应时间和错误率也会增加
尽管生产率随强度呈线性增长,但服务表现良好。 它成功处理了整个传入请求流,响应时间没有改变,没有错误。 持续增加强度,我们会导致生产率增长放慢直到达到饱和,在饱和状态下生产率达到最大,响应时间开始增长。 随后强度的增加将导致混乱-响应时间的显着增加和生产率的下降,错误的活跃增长将开始。 在增长和饱和阶段,有两个要点- 正常和最佳性能。
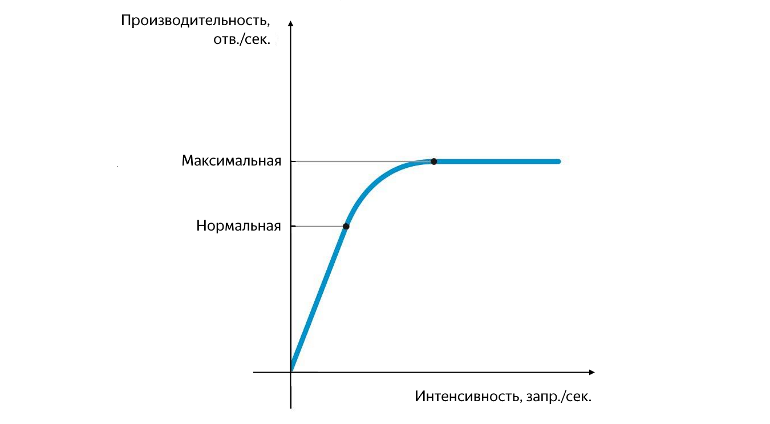
正常和最高性能位置
在增长率开始下降的那一刻就达到了正常的生产率,在增长率为零的那一刻达到了最高的生产率。 在正常和最高性能之间进行区分非常重要。 在与正常性能相对应的强度下,应用程序应该稳定运行,并且正常性能的值表征了阈值,在此阈值之后服务的瓶颈开始出现,对其运行产生了负面影响。 当达到最大性能时,瓶颈开始完全限制进一步的增长,服务不稳定,并且通常,此时此刻会出现小而稳定的错误背景。
该问题可能由多种原因引起-队列被阻塞,线程不足,池已耗尽,CPU或RAM已被完全利用,对磁盘的读取/写入速度不足等。 重要的是要了解,纠正一个瓶颈将导致性能受到下一个瓶颈的限制,依此类推。 不可能完全消除瓶颈,只能克服瓶颈。
实验
首先,必须确定服务达到正常和最大性能的强度的大小以及相应的平均响应时间。 为此,在一个实验中,仅增加传入请求的流量就足够了。 确定最大强度值和实验时间更加困难。
您可以从非功能性需求(如果有)中编写的内容开始,从销售中的最大用户负担开始,或者只是从上限中获取值。 如果输入流的强度不够,则服务将没有时间达到饱和,因此有必要重复实验。 如果强度太高,服务将很快达到饱和,然后进行调试。 在这种情况下,进行监视非常方便,这样可以大大增加错误数量,而不会白白浪费时间并停止实验。
在我们的实验中,我们在10分钟内将强度从每秒0请求逐渐提高到1000。 这足以使服务达到饱和,然后,如有必要,我们在下一个实验中调整时间和强度以获得更准确的结果。 在上面的图表中,所有内容都平滑且美丽,但在现实世界中,乍一看可能很难确定正常性能的值。
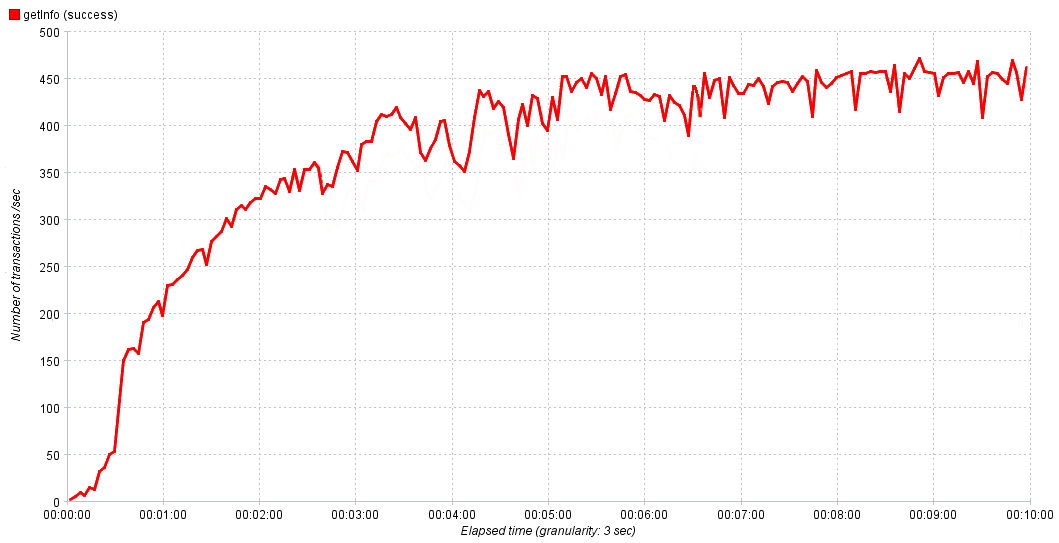
服务性能对时间的真正依赖
在这种情况下,对于正常性能,我们取最大值的80-90%。 如果我们观察到误差在达到饱和后会主动增长,则有必要进行调查,因为它们是瓶颈的结果,因此研究误差将有助于对其进行定位并将其传递给校正。
因此,获得了第一个结果。 现在我们知道了正常和最大的应用程序性能,以及与之相对应的响应时间。 这就是全部吗? 当然不是! 如果性能正常,则该服务应稳定运行,这意味着您需要检查其在正常负载下的运行情况。 哪一个 您可以再次查看非功能性需求,询问分析人员或监视产品上最大活动的持续时间。 在我们的实验中,我们将负载从0线性增加到正常,并保持10-15分钟。 如果最大用户负载明显小于正常负载,这就足够了,但是如果它们可比,则应增加实验时间。
为了快速评估实验结果,以以下指标的形式汇总获得的数据非常方便:
什么是平均响应时间是可以理解的,但是只有在样本呈正态分布的情况下,平均值才是适当的度量,因为它对“异常值”过于敏感-太大或太小的值都与总体趋势强烈偏离。 中值是整个响应时间样本的中间值,一半的值小于该值,其余的值较大。 为什么需要它?
首先,根据其定义,它对异常值不那么敏感,也就是说,它是更合适的指标;其次,通过将其与平均值进行比较,可以快速评估响应分布特征。 在理想情况下,它们是相等的-响应时间的分布是正常的,服务很好!
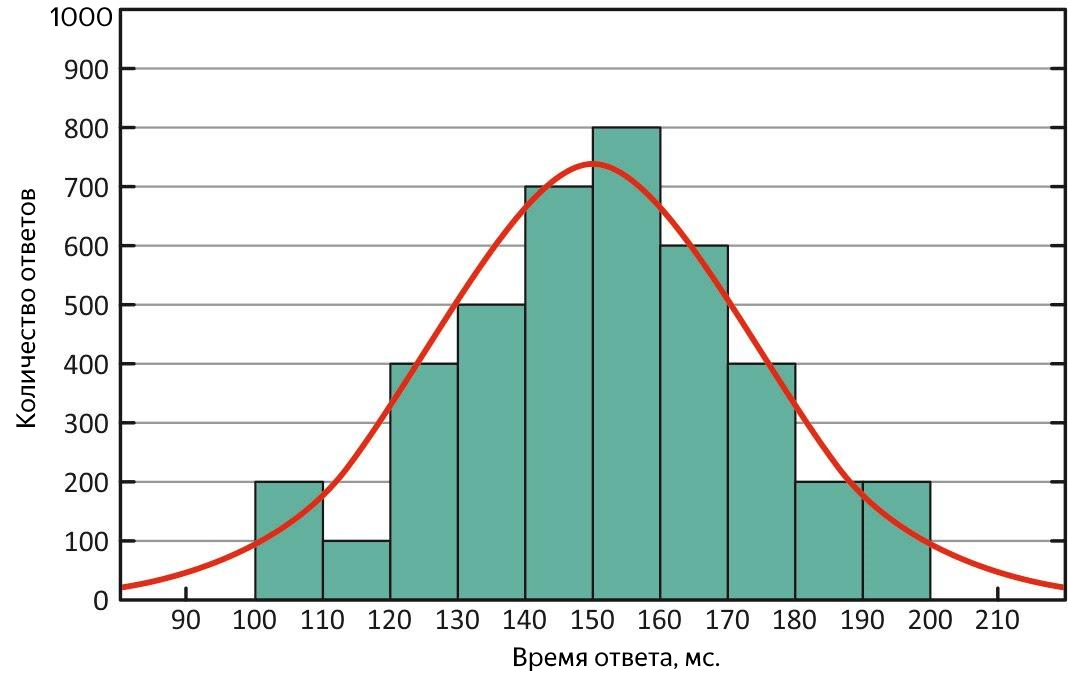
响应时间的正态分布。 在这种分布下,均值和中位数相等
如果平均值与中位数非常不同,则分布会偏斜,并且在实验过程中可能会出现“异常值”。 如果平均值更高-在某些时候服务响应非常慢,换句话说,它会放慢速度。
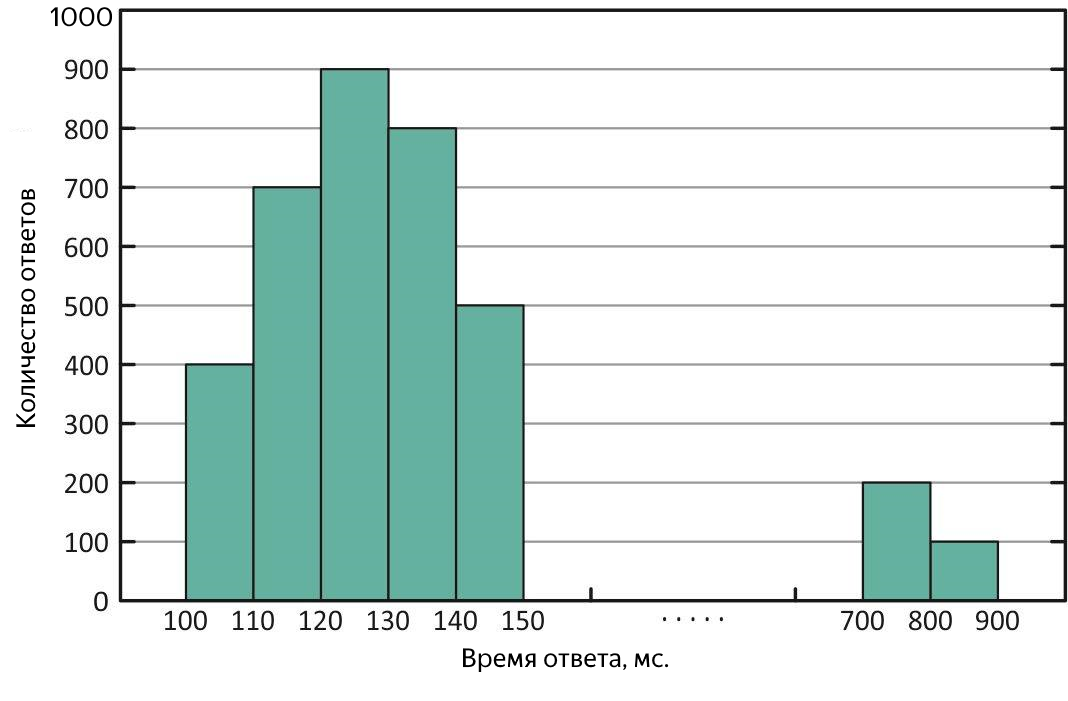
具有较长答案的“异常值”的响应时间分布。 在这种分布下,平均值大于中位数。
这种情况需要进一步分析。 为了估计“排放”的规模,需要采取分位数或百分位数的方法。
在获得的样本中,分位数是响应时间的值,所有请求的相应部分都适合该响应时间。 如果您使用查询的百分比,那么这就是百分比(顺便说一下,中位数是50%百分比)。 使用90%的百分位数估算排放量很方便。 例如,作为实验的结果,获得了100 ms的中值,而平均值-250 ms超过了中值2.5倍! 显然,这并不完全好,查看90%的分位数,然后看1000毫秒-所有成功请求中的10%的完成时间超过一秒钟,一团糟,您需要了解。 要搜索较长的查询,您可以在实验文件中查找该文件,也可以立即在服务日志中查找该文件,但最好以图表形式显示平均响应时间与时间,它会立即显示时间和可用“异常值”的性质。
总结
因此,您成功进行了实验并获得了结果。 它的好坏取决于服务的要求,但获得的数字并不重要,但是为什么要获得这些数字,以及了解进一步增长受到的限制。 如果您发现瓶颈-很好,如果不是,那么迟早可能需要提高生产力,并且仍然需要寻找瓶颈,因此有时可以更轻松地预防这种情况。
在本说明中,我通过回答一开始的问题为研究性能提供了一种基本方法。 不要害怕研究性能,这是必要的!
聚苯乙烯
访问我们舒适的电报聊天室 ,您可以在其中询问问题,提供建议以及谈论性能研究。