
和往常一样,感谢Fred Hebert和Sargun Dhillon阅读本文的草稿并提供了一些宝贵的建议。
Box的Tamar Berkovichi在谈到速度时强调了性能检查对于自动数据库故障转移的重要性。 特别是,她指出,监视端到端查询的执行时间作为确定数据库运行状况的一种方法,比简单的ping(ping)更好。
...为了将流量转移到另一个节点(副本)以消除不活动状态,有必要建立针对反弹和其他边界情况的保护。 这并不困难。 组织有效工作的重点是知道何时将数据库放在第一位,即 您必须能够正确评估数据库的运行状况。 现在,我们习惯关注的许多参数(例如,处理器负载,延迟,错误率)是辅助信号。 这些参数实际上都不能说明数据库处理客户端流量的能力。 因此,如果使用它们来决定切换,则可以同时得到假阳性和假阴性结果。 我们的运行状况检查器实际上是在数据库节点上执行简单查询,并使用已完成和失败查询中的数据来更准确地评估数据库的运行状况。
我与一个朋友讨论了这个问题,他建议运行状况检查应该非常简单,并且实际流量是评估流程运行状况的最佳标准。
通常,与运行状况检查的实现有关的讨论围绕两个相反的选择:简单的通信/信号测试或复杂的端到端测试。 在本文中,我想强调与将上述形式的运行状况检查用于某些类型的负载平衡解决方案相关的问题,以及需要一种更详细的方法来评估流程的运行状况。
两种健康检查
通常,即使在许多现代系统中,运行状况检查也分为两类:在节点级别和服务级别的检查。
例如,Kubernetes通过分析准备情况和生存能力来实施验证。 可用性检查用于确定炉床为流量提供服务的能力。 如果未执行就绪检查,则将从组成服务的端点中将其删除,因此,在炉膛中,直到完成检查为止,都不会路由任何流量。 另一方面,可生存性检查用于确定服务是否响应挂起或锁定。 如果失败, 则重新启动kubelet中的单个容器。 类似地, Consul允许多种形式的checks :针对特定URL的基于script的,基于HTTP的检查,基于TTL的检查甚至别名。
在服务级别实施运行状况检查的最常见方法是确定运行状况检查的终结点。 例如,在gRPC中,运行状况检查本身成为RPC调用。 gRPC还允许服务级别运行状况检查和常规gRPC服务器运行状况检查 。
过去,主机级别的运行状况检查被用作触发警报的信号。 例如,具有平均处理器负载的警报(当前被视为反设计模式)。 即使运行状况检查不直接用于通知,它仍然可以作为许多其他自动基础结构决策的基础,例如,有关负载平衡和(有时)断路的决策。 在诸如Envoy之类的服务网格数据方案中,当要确定到实例的流量路由时, 运行状况检查数据将针对服务发现数据继续进行。
效率是一个频谱,而不是二进制分类法
回声请求或ping只能确定服务是否正在运行 ,而端到端测试则可以用来确定系统是否能够执行特定的工作单元 ,其中工作单元可以是数据库查询或特定的计算 。 无论运行状况检查的形式如何,其结果都被视为纯二进制的:“通过”或“失败”。
在当今的动态且通常是“自动可伸缩”的基础架构选项中,如果单个流程不能执行特定的工作单元,则仅“正常工作”的单个过程并不重要。 事实证明,简化的检查(例如回声测试)几乎没有用。
确定何时将服务完全断开很容易,但是要确定正在运行的服务的可操作程度要困难得多。 进程很可能正在运行(即运行状况检查通过),并且路由了流量,但是要执行某个工作单元(例如在p99服务延迟期间),这还不够。
通常,由于过程过载,无法完成工作。 在竞争激烈的服务中,“拥塞”与仅一个进程和过多排队处理的并发请求的数量紧密相关,这可能导致RPC调用的延迟增加(尽管通常情况下,较低级别的服务只是将请求置于保留状态并重试)超时)。 如果运行状况检查端点配置为自动返回HTTP 200状态代码,而服务执行的实际操作涉及网络I / O或计算,则尤其如此。

工艺性能是一个频谱。 首先,我们对服务质量感兴趣,例如,恢复特定工作单元的结果所需的时间以及结果的准确性。
在整个使用寿命期间,过程可能会在不同程度的工作能力之间波动:从完整的工作能力 (例如,以预期的并行度运行的能力)到无法操作的点(当队列开始填满时)和过程完全进入无效区域(感觉到)的点之间服务质量下降)。 仅在以下情况下才能构建最琐碎的服务:在任何时期内都不会出现部分故障,在这种情况下,部分故障意味着某些功能正常工作,而其他功能则处于关闭状态,并且不仅“某些请求已执行,有些未执行”。 如果服务体系结构不允许正确纠正部分故障,则客户端将自动修复错误纠正任务。
必须在了解这种波动完全正常的前提下构建自适应的,自我修复的基础结构。 同样重要的是要记住,这种差异仅与负载平衡有关,例如,对于协调器,仅由于进程处于过载的边缘而重新启动进程是没有意义的。
换句话说,对于编排级别,将进程的可操作性视为二进制状态并仅在失败或冻结后才重新启动进程是非常合理的。 但是在负载平衡层中(无论是外部代理(例如Envoy)还是客户端的内部库),在有关流程可操作性的更详细信息的基础上进行操作-当它做出有关中断电路和倾销负载的适当决策时,至关重要。 如果无法随时准确确定服务性能水平,则服务的逐步降级是不可能的。
让我从经验中告诉您:无限的并发通常是导致服务降级或生产力永久下降的主要因素。 负载平衡(以及因此导致的负载减少)通常归结为有效管理并发和施加背压,从而防止系统过载。
施加背压时需要反馈
马特·拉尼 ( Matt Ranney)写了一篇 非凡的文章,涉及无限并发以及Node.js中对背压的需求。 整篇文章都很好奇,但主要结论(至少对我而言)是在流程及其输出单元(通常是负载平衡器,有时还需要其他服务)之间需要反馈。
诀窍是,当资源用尽时,必须在某处提供一些东西。 需求在增长,而生产率却无法神奇地提高。 要限制传入的任务,首先要做的是在站点级别上通过IP地址,用户,会话或最好是通过对应用程序重要的一些元素来设置一些速度限制。 与限制传入的Node.js服务器相比,许多负载均衡器可以通过更复杂的方式来限制速度,但是通常直到过程陷入困境时他们才注意到问题。
就正确性和可伸缩性而言,基于静态阈值和限制的速度限制和开路可能不可靠且不稳定 。 一些负载均衡器(尤其是HAProxy)提供了有关每个服务器和服务器部分内部队列长度的大量统计信息。 此外,HAProxy允许进行agent-check (独立于正常运行状况检查的辅助检查),这允许该过程向代理服务器提供更准确和动态的运行状况反馈。 链接到文件 :
通过基于指定的agent-port参数的TCP连接到agent-port并读取ASCII字符串来执行检查代理的运行状况。 一行由一系列单词组成,这些单词由空格,制表符或逗号以任意顺序分隔,可以选择以/r和/或/n结尾,并包括以下元素:
-ASCII的正整数百分比值的表示形式,例如75% 。 此格式的值确定与初始重量成比例的重量
启动HAProxy时配置的加权服务器值。 请注意,从零开始对服务器产生类似影响(从LB服务器场中删除该值)起,统计信息页面上的零权重值就会显示为DRAIN 。
-字符串参数maxconn :后跟一个整数(无空格)。 中的值
此格式定义maxconn服务器maxconn 。 最大人数
使用此运行状况检查,必须将声明的连接数乘以负载平衡器和各种服务器部件的数量,以获得服务器可以建立的连接总数。 例如: maxconn:30
- ready 。 这会将服务器的管理状态转换为
READY模式,取消DRAIN或MAINT 。
-字drain 。 这会将服务器的管理状态转换为
排水模式(“排水”),此后服务器将不接受新的连接,但通过数据库接受的连接除外。
- maint字。 这会将服务器的管理状态转换为
MAINT模式(“维护”),此后服务器将不接受任何新连接,并且运行状况检查将停止。
- down , failed或stopped字样,其后可以在尖线符号(#)后加上描述行。 它们全部指示DOWN服务器的运行状态(“关闭”),但是由于单词本身显示在统计信息页面上,因此差异使管理员可以确定是否预期这种情况:该服务可能被有意停止了,可能出现了一些确认测试,但未通过,或被视为已禁用(无进程,端口无响应)。
-如果运行状况检查还可以确认服务的可用性,则单词up表示UP服务器的运行状态(“ on”)。
代理未声明的参数不会更改。 例如,一个代理只能设计为监视处理器使用情况,并且仅报告相对权重值,而不与操作状态进行交互。 同样,可以将代理程序设计为具有3个开关的最终用户界面,从而允许管理员仅更改管理状态。
但是,应该记住,只有代理才能撤消其自己的操作,因此,如果使用代理将服务器设置为DRAIN或DOWN,则代理必须执行其他等效操作才能重新启动服务。
无法连接到代理不视为错误,因为通过定期执行运行状况检查来测试连接能力,运行状况检查是使用check参数启动的。 但是,如果收到关闭消息,则警告不是停止代理的好主意,因为只有报告关闭的代理才能重新启用服务器。
服务与输出单元之间动态通信的方案对于创建自适应基础结构非常重要。 一个例子就是我上一份工作所使用的体系结构。
我曾经在实时图像处理启动公司imgix工作。 使用简单的API URL,可以实时检索和转换图像,然后通过CDN在世界任何地方使用。 我们的堆栈相当复杂( 如上所述 ),但简而言之,我们的基础架构包括一个平衡和负载平衡级别(与从源接收数据的级别并列),源缓存级别,图像处理级别和内容交付级别。

负载均衡级别基于Spillway服务,该服务充当反向代理和请求代理。 这纯粹是内部服务; 濒临破产的时候,我们启动了nginx以及HAProxy和Spillway,因此它的设计初衷并不是要完成TLS或执行通常由边界代理胜任的那无数个集合中的任何其他功能。
Spillway由两个部分组成:客户端部分(Spillway FE)和代理。 尽管最初两个组件都在同一个二进制文件中,但是在某些时候,我们还是决定将它们分成单独的二进制文件,这些文件同时部署在同一主机上。 主要是因为这两个组件具有不同的性能配置文件,并且客户端部分几乎完全与处理器连接。 客户端部分的任务是对每个请求进行初步处理,包括在源缓存级别进行初步验证,以确保在将图像转换请求发送给执行者之前,将图像缓存在我们的数据中心中。
在任何给定时间,我们都有固定的艺术家池(如果有记忆的话,大约十二个),这些艺术家可以连接到同一Spillway经纪人。 艺术家负责图像的实际转换(裁剪,调整大小,PDF处理,GIF渲染等)。 他们处理了从数百页PDF和数百帧GIF到简单图像文件的所有内容。 承包商的另一个特点是,尽管所有网络都是完全异步的,但GPU本身并未进行任何实际转换。 鉴于我们是实时工作的,因此无法预测特定时间点的流量情况。 我们的基础设施必须适应各种形式的传入流量-无需人工操作。
考虑到我们经常遇到的异构流量模式,执行者有必要拒绝接受传入的请求(即使完全运行),如果接受连接可能会使执行者超负荷。 对执行者的每个请求都包含关于请求性质的一组特定的元数据,这使执行者可以确定他是否能够处理该请求。 每个执行者都有自己的统计数据集,这些数据与他当前正在处理的请求有关。 员工将这些统计信息与请求元数据和其他启发式数据(例如套接字缓冲区大小数据)结合使用,以确定他是否正确接收了传入请求。 如果员工确定他不能接受该请求,那么他将创建一个与HAProxy代理检查没有不同的响应,告知其Spillway其可操作性。
Spillway监视了所有台球艺术家的表现。 最初,我尝试连续三次向不同的执行者发送请求(优先选择那些在本地数据库中具有原始映像且未超载的执行者),如果所有三个执行者均拒绝接受该请求,则该请求将在内存中的代理中排队。 代理支持三种形式的队列:LIFO队列,FIFO队列和优先级队列。 如果所有三个队列均已满,则代理仅拒绝该请求,从而允许客户端(HAProxy)在延迟期后重试。 当一个请求被放入三个队列之一时,任何自由的执行者都可以从那里删除并处理它。 与为请求分配优先级以及确定应放置三个队列(LIFO,FIFO,基于优先级的队列)中的哪一个相关联时,存在某些困难,但这是另一篇文章的主题。
为了使服务有效运行,我们不需要讨论这种形式的动态反馈。 我们仔细监视了代理队列(所有三个队列)的大小,当队列大小超过某个阈值时(这非常罕见),Prometheus发出了关键警告之一。
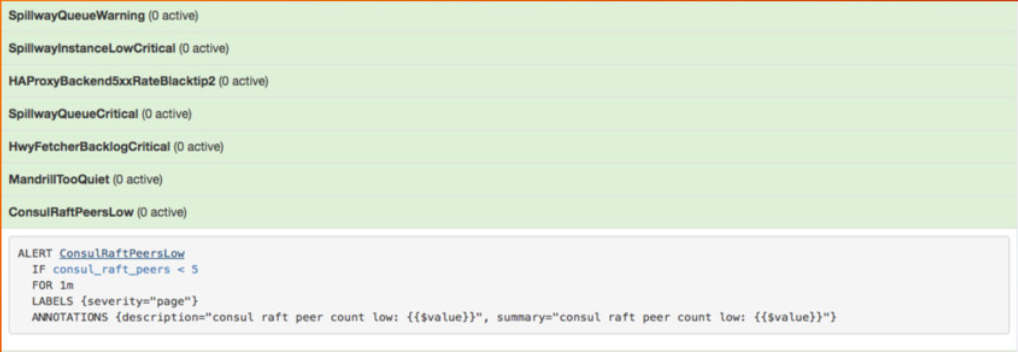
图片来自我于2016年11月在Google纽约市关于Prometheus监控系统的演讲中

该警告摘自我在2017年5月的OSCON会议上关于Prometheus监控系统的演讲中。
在今年年初,Uber发表了一篇有趣的文章,其中阐明了基于服务质量实现减载水平的方法。
通过分析过去六个月中的故障,我们发现可以通过平滑降级来减轻或预防28%的故障。
三种最常见的故障类型与以下因素有关:
-传入请求的模式更改,包括拥塞和错误的操作员节点。
-资源耗尽,例如处理器,内存,输入/输出电路或网络资源。
-依赖项故障,包括基础结构,数据仓库和下游服务。
我们基于CoDel算法实现了过载检测器。 对于每个已启用的端点,添加了轻量级请求缓冲区(基于gourutin和channel实现 ),以跟踪从呼叫源接收到请求的时间到开始在处理程序中处理请求之间的延迟。 , , .
, , , - . 2013 Google «The Tail at Scale» , ( ), ( ) .
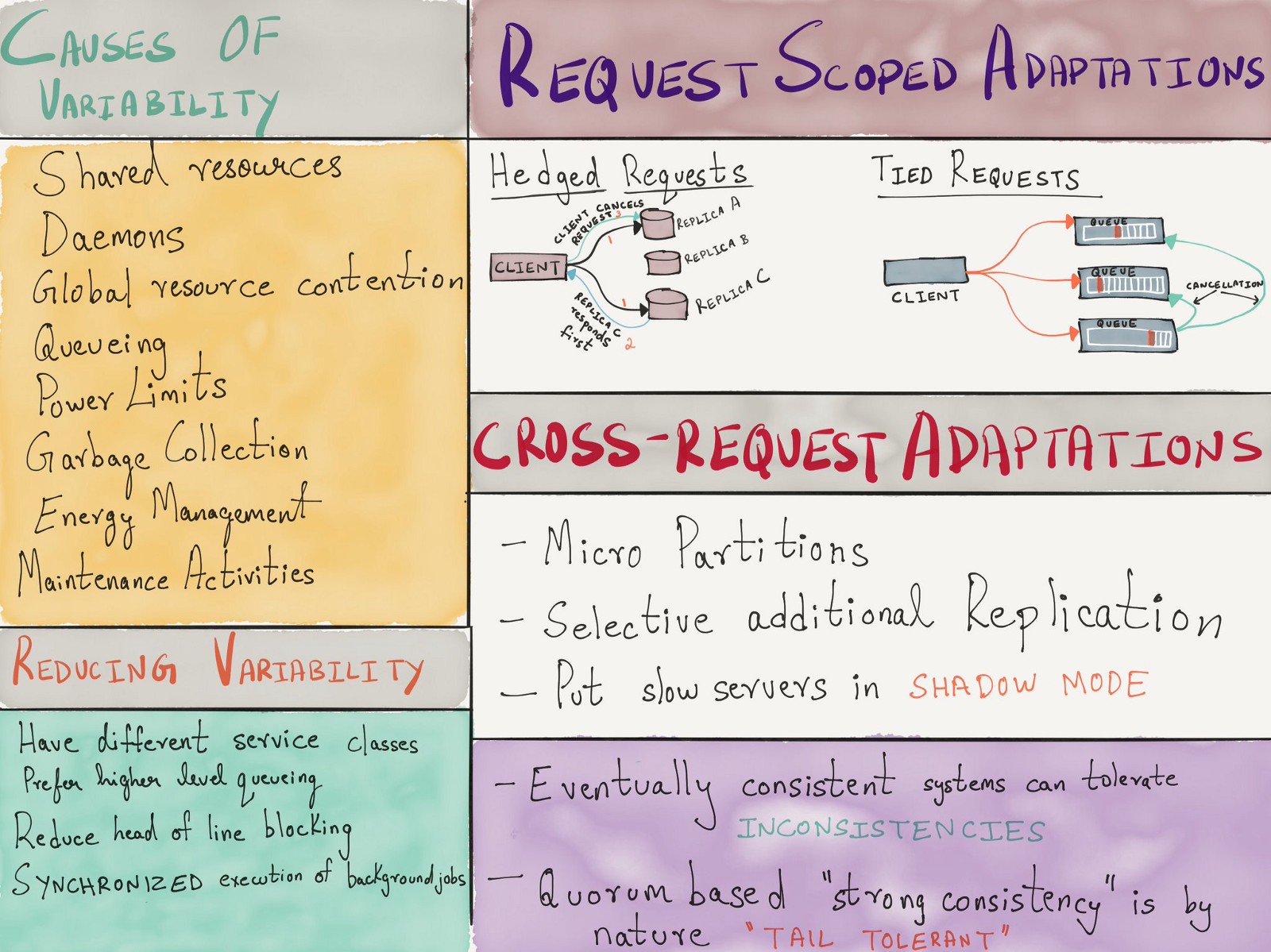
, . , .

( )
, , :
- , , QCon London 2018.
- : - , , LISA 2017.
- – , , Strangeloop 2017.
- : , , , Strangeloop 2017.
- « » .
结论
, TCP/IP ( ), IP ECN ( IP ) Ethernet, , .
, . . , . .