哈Ha! 我叫帕维尔·利普斯基(Pavel Lipsky)。 我是一名工程师,我在Sberbank-Technology工作。 我的专长是测试大型分布式系统后端的容错能力和性能。 简而言之,我破坏了别人的程序。 在本文中,我将讨论故障注入-一种测试方法,该方法可让您通过创建人为故障来查找系统中的问题。 我将首先介绍如何使用此方法,然后再讨论该方法本身以及如何使用它。
本文将提供Java示例。 如果您不是用Java编程-没关系,只需了解方法本身和基本原理即可。 Apache Ignite用作数据库,但是相同的方法也适用于任何其他DBMS。 所有示例都可以从我的
GitHub下载。
为什么我们需要所有这些?
我将从故事开始。 2005年,我在Rambler工作。 到那时,Rambler用户的数量迅速增长,而我们的两层体系结构“服务器-数据库-服务器-应用程序”已无法应对。 我们考虑了如何解决性能问题,并提请注意内存缓存技术。
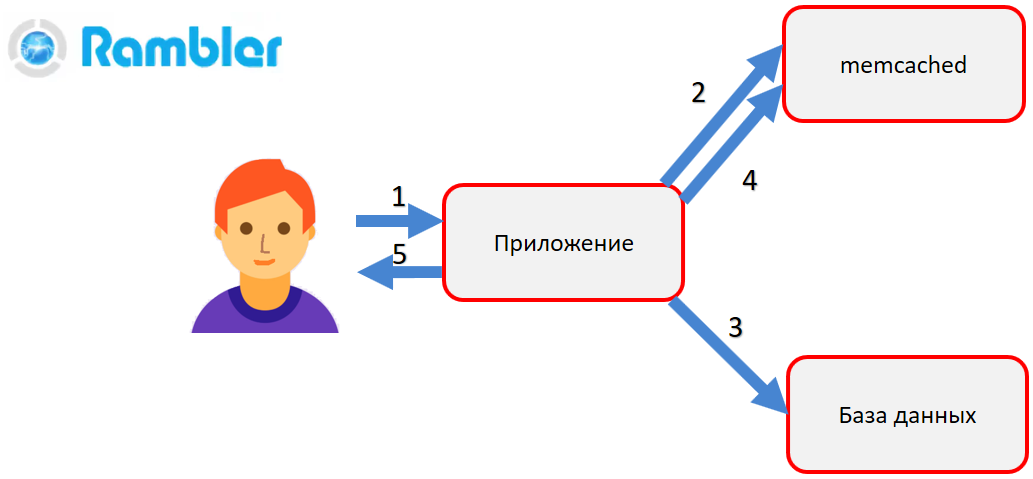
什么是memcached? Memcached-随机存取存储器中的哈希表,可通过键访问存储的对象。 例如,您需要获取用户个人资料。 该应用程序访问memcached(2)。 如果其中有一个对象,那么它将立即返回给用户。 如果没有对象,则对数据库进行上诉(3),形成对象并将其放入memcached(4)。 然后,在下一个调用中,我们不再需要对数据库进行资源消耗大的调用-我们将从主内存memcached中获取完成的对象。
由于使用了内存缓存,我们明显卸载了数据库,并且我们的应用程序开始运行得更快。 但是,事实证明,现在还为时过早。 随着生产力的提高,我们遇到了新的挑战。
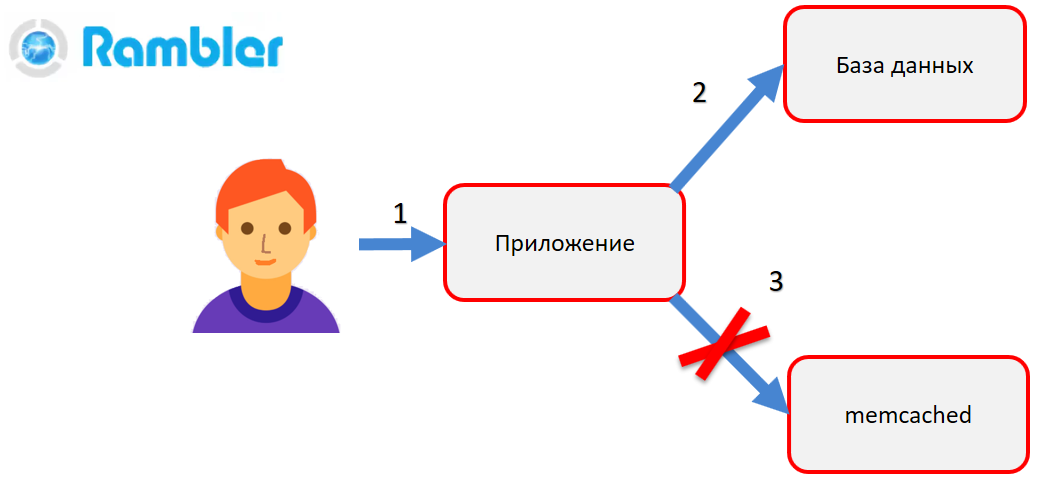
当您需要更改数据时,应用程序首先对数据库进行更正(2),创建一个新对象,然后尝试将其放入memcached(3)。 也就是说,旧对象必须替换为新对象。 想象一下,这时发生了一件可怕的事情-应用程序与memcached之间的连接断开,memcached服务器甚至应用程序本身崩溃。 因此,应用程序无法更新memcached中的数据。 结果,用户将转到该站点的页面(例如,他的个人资料),看到旧数据,并且不明白为什么会这样。
在功能测试或性能测试期间是否可以检测到此错误? 我认为很可能我们找不到他。 要搜索此类错误,有一种特殊类型的测试-故障注入。
通常在故障注入测试期间,存在一些通常称为“
浮动”的错误。 它们出现在负载下,系统中有多个用户在工作,发生异常情况-设备故障,断电,网络故障等。
新的Sberbank IT系统
几年前,Sberbank开始构建新的IT系统。 怎么了 以下是来自中央银行网站的统计数据:
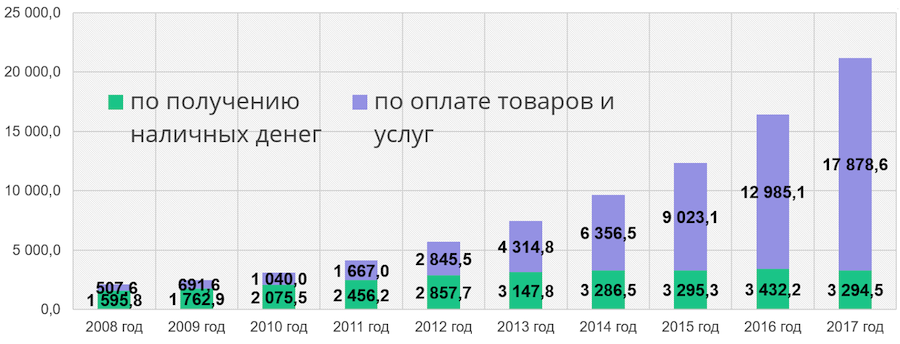
列的绿色部分是在自动柜员机上提取现金的次数,蓝色部分是用于支付商品和服务的操作数。 我们看到无现金交易的数量每年都在增长。 几年后,我们将需要能够处理不断增长的工作量并继续为客户提供新服务。 这是创建新的Sberbank IT系统的原因之一。 此外,我们希望减少对西方技术和昂贵的大型机(它们花费数百万美元)的依赖,并转而使用开源技术和低端服务器。
最初,我们在新的Sberbank架构的核心奠定了Apache Ignite技术的基础。 更准确地说,我们使用付费的Gridgain插件。 该技术具有相当丰富的功能:它结合了关系数据库(支持SQL查询),NoSQL,分布式处理以及RAM中数据存储的属性。 此外,当您重新启动时,RAM中的数据将不会在任何地方丢失。 从2.1版开始,Apache Ignite分发了具有SQL支持的Apache Ignite持久数据存储。
我将列出该技术的一些功能:
- RAM中的存储和数据处理
- 磁盘存储
- SQL支持
- 分布式任务执行
- 水平缩放
该技术相对较新,因此需要特别注意。
Sberbank的新IT系统实际上由组装在单个云集群中的许多相对较小的服务器组成。 所有节点在结构上相同,对等,执行存储和处理数据的功能。
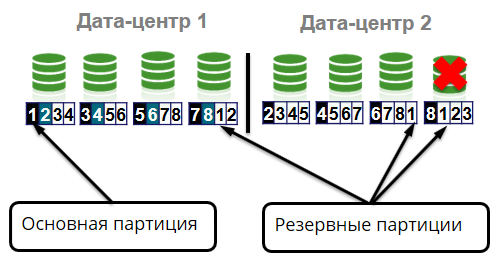
集群内部分为所谓的单元。 一个像元是8个节点。 每个数据中心有4个节点。
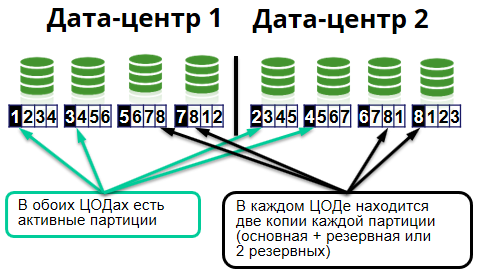
由于我们使用Apache Ignite内存数据网格,因此,所有这些都存储在服务器分布式缓存中。 此外,高速缓存又分为相同的部分-分区。 在服务器上,它们表示为文件。 同一缓存的分区可以存储在不同的服务器上。 对于集群中的每个分区,都有主节点和备份节点。
主节点存储主分区并处理对它们的请求,将数据复制到存储备份分区的备份节点(备份节点)。
在设计Sberbank的新体系结构时,我们得出的结论是,系统组件可能会并且将会失败。 说,如果您有1000个低端铁服务器集群,那么您将不时遇到硬件故障。 RAM条,网卡和硬盘驱动器等将发生故障。 我们将认为此行为是完全正常的系统行为。 此类情况应得到正确处理,我们的客户不应注意到它们。
但是,仅设计系统的故障抵抗能力是不够的;必须在这些故障期间测试系统。 正如著名的分布式系统研究人员Microsoft Research的Caitie McCaffrey所说:“在重现故障之前,您永远不会知道系统在意外故障期间的行为。”
丢失的更新
让我们举一个简单的例子,一个模拟货币转账的银行应用程序。 该应用程序将包括两部分:Apache Ignite服务器和Apache Ignite客户端。 服务器端是数据仓库。
客户端应用程序连接到Apache Ignite服务器。 创建一个缓存,其中键是帐户ID,值是帐户对象。 总共十个此类对象将存储在缓存中。 在这种情况下,最初我们将在每个帐户上投入100美元(这样就可以进行转帐了)。 因此,所有帐户上的总余额将等于$ 1,000。
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) { for (int i = 1; i <= ENTRIES_COUNT; i++) cache.put(i, new Account(i, 100)); System.out.println("Accounts before transfers"); printAccounts(cache); printTotalBalance(cache); for (int i = 1; i <= 100; i++) { int pairOfAccounts[] = getPairOfRandomAccounts(); transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]); } } ... private static void transferMoney(IgniteCache<Integer, Account> cache, int fromAccountId, int toAccountId) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); }
然后,我们在这10个帐户之间进行100次随机汇款。 例如,$ 50从帐户A转移到另一个帐户B。 示意地,该过程可以表示如下:

系统已关闭,只能在内部进行传输,即 总余额应保持为$ 1000。
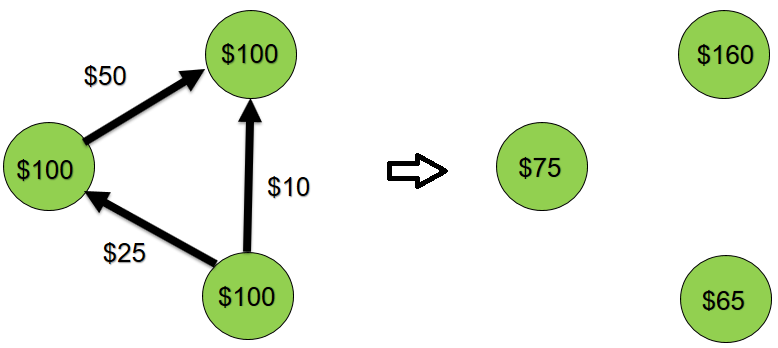
启动应用程序。
我们得到了总余额的期望值-$ 1000。 现在让我们的应用程序复杂一些-让它成为多任务。 实际上,多个客户端应用程序可以使用同一帐户同时工作。 运行两个任务,这将同时在十个帐户之间进行转账。
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setIndexedTypes(Integer.class, Account.class); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
总余额为$ 1296。 客户欢喜,银行蒙受损失。 为什么会这样呢?

在这里,我们看到两个任务如何同时更改帐户A的状态。但是第二个任务设法比第一个任务更早记录其更改。 然后,第一个任务记录其更改,第二个任务进行的所有更改立即消失。 这种异常称为更新丢失问题。
为了使应用程序正常运行,我们的数据库必须支持ACID事务,并且我们的代码应考虑到这一点。
让我们看一下应用程序的ACID属性,以了解为什么它如此重要。

- A-原子性,原子性。 将对数据库进行所有建议的更改,或者什么都不做。 也就是说,如果我们在第3步和第6步之间失败,则更改不应存储在数据库中
- C-一致性,完整性。 事务完成后,数据库必须保持一致状态。 在我们的示例中,这意味着A和B的总和应始终相同,总余额为$ 1000。
- 我-隔离,隔离。 交易不应相互影响。 如果一项交易进行了转帐,而另一项交易在第3步到第6步之后才收到帐户A和B的值,则她认为该系统的资金不足。 这里有些细微之处,我稍后会重点介绍。
- D-耐久性 在事务将更改提交到数据库之后,这些更改不应由于失败而丢失。
因此,在transferMoney方法中,我们将在交易中进行汇款。
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart()) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
启动应用程序。
嗯 交易没有帮助。 总余额为$ 6951! 此应用程序行为有什么问题?
首先,他们选择了ATOMIC缓存类型,即 没有ACID交易支持:
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TOMIC);
其次,txStart方法具有两个很重要的enum类型的重要参数,可以很好地指定它们:lock方法(Apache Ignite中的并发模式)和隔离级别。 根据这些参数的值,事务可以以不同的方式读取和写入数据。 在Apache Ignite中,这些参数设置如下:
try (Transaction tx = ignite.transactions().txStart( , )) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); ... tx.commit(); }
您可以使用PESSIMISTIC(悲观锁)或OPTIMISTIC(乐观锁)作为LOCK METHOD参数的值。 它们在阻塞的瞬间有所不同。 当使用PESSIMISTIC时,该锁在第一次读/写时强加并保持到提交事务为止。 例如,当具有悲观锁的交易从帐户A转移到帐户B时,其他交易将无法读取或写入这些帐户的值,直到进行转移的交易被提交为止。 显然,如果其他事务要访问帐户A和B,则它们被迫等待该事务完成,这对应用程序的整体性能有负面影响。 乐观锁定不会限制对其他事务的数据访问,但是,在提交事务的准备阶段(准备阶段,Apache Ignite使用2PC协议),将执行检查-数据是否随其他事务一起更改? 如果发生更改,则交易将被取消。 在性能方面,OPTIMISTIC将运行得更快,但更适合于没有数据竞争的应用程序。
INSULATION LEVEL参数确定事务之间的隔离程度。 SQL ANSI / ISO标准定义了4种隔离类型,对于每个隔离级别,相同的事务场景可能导致不同的结果。
- READ_UNCOMMITED是最低的隔离级别。 事务可以看到“脏”的未提交数据。
- READ_COMMITTED-当事务仅在内部看到敏感数据时
- REPEATABLE_READ-表示如果在事务内部进行读取,则此读取必须是可重复的。
- 可SERIALIZABLE-此级别假定最大程度的事务隔离-就像系统中没有其他用户一样。 并行事务的结果就像是按顺序(按顺序)执行一样。 但是,加上高度隔离,我们会降低性能。 因此,您必须谨慎地选择这种隔离级别。
对于许多现代DBMS(Microsoft SQL Server,PostgreSQL和Oracle),默认隔离级别为READ_COMMITTED。 对于我们的示例,这将是致命的,因为它不能保护我们免受丢失的更新的影响。 结果将与我们根本没有使用交易一样。

根据
Apache Ignite交易文档 ,适合将锁方法和隔离级别结合使用:
- PESSIMISTIC REPEATABLE_READ-首次读取或写入数据时施加该锁,并保持到完成。
- PESSIMISTIC SERIALIZABLE-与PESSIMISTIC REPEATABLE_READ类似
- OPTIMISTIC SERIALIZABLE-会记住第一次读取后获得的数据版本,如果在提交的准备阶段该版本不同(数据已由另一个事务更改),则该事务将被取消。 让我们试试这个选项。
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Hooray,得到了$ 1,000,与预期的一样。 在第三次尝试。
负载测试
现在,我们将使测试更加实际-我们将在负载下进行测试。 并添加一个额外的服务器节点。 有许多进行压力测试的工具,在Sberbank,我们使用HP Performance Center。 这是一个非常强大的工具,支持50多种协议,是为大型团队设计的,花费很多钱。 我在JMeter上写了我的示例-它是免费的,可以100%解决我们的问题。 我不想用Java重写代码,因此我将使用JSR223采样器。
我们将从应用程序的类创建一个JAR存档,并将其加载到测试计划中。 要创建并填充缓存,请运行CreateCache类。 初始化缓存后,您可以运行JMeter脚本。
一切都很棒,得到了1,000美元。
群集节点紧急关闭
现在,我们将更具破坏性:在集群操作期间,我们将使两个服务器节点之一崩溃。 通过Gridgain软件包随附的Visor实用程序,我们可以监视Apache Ignite群集并制作不同的数据样本。 在“ SQL查看器”选项卡中,执行SQL查询以获取所有帐户的总体余额。
怎么了 553美元。 客户感到恐惧,银行蒙受声誉损失。 这次我们做错了什么?
事实证明,Apache Ignite中有缓存类型:
- 已分区-群集中存储了一个或几个备份副本
- 复制的缓存-所有分区(缓存的所有部分)都存储在一台服务器中。 此类缓存主要适合参考书-很少更改且经常阅读的东西。
- 本地-全部在一个节点上

我们经常会更改数据,因此我们将选择分区缓存并为其添加其他备份。 也就是说,我们将有两个数据副本-主副本和备份副本。
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setBackups(1);
我们启动该应用程序。 提醒您,在转帐之前,我们有1000美元。 我们启动并在操作过程中“扑灭”节点之一
在Visor实用程序中,我们进行SQL查询以获取总余额$ 1000。 一切顺利!
可靠性案例
两年前,我们才刚刚开始测试新的Sberbank IT系统。 不知何故,我们去了护送工程师,问:有什么可以打破的? 他们回答我们:一切都会破裂,一切都会测试! 当然,这个答案不适合我们。 我们一起坐下来,分析了故障统计信息,并意识到我们可能遇到的最有可能的情况是节点故障。
此外,这可能由于完全不同的原因而发生。 例如,应用程序可能崩溃,JVM崩溃,操作系统崩溃或硬件故障。
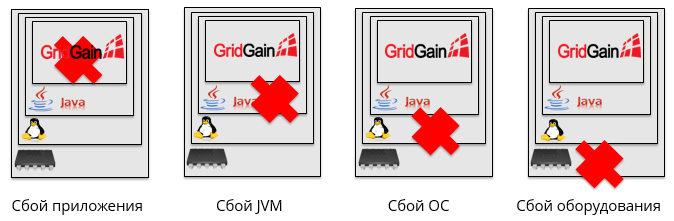
我们将所有可能的失败案例分为4组:
- 配套设备
- 联播网
- 软体类
- 其他
他们为他们提出了测试,并称其为可靠性案例。 一个典型的可靠性案例包括对测试前系统状态的描述,重现故障的步骤以及对故障期间预期行为的描述。
可靠性案例:设备
该组包括以下情况:
- 停电
- 完全无法访问硬盘
- 一条硬盘访问路径故障
- CPU,RAM,磁盘,网络负载
群集为每个分区存储4个相同的副本:一个主分区和三个备份分区。 假设节点由于设备故障而离开群集。 在这种情况下,主分区应移至其他尚存的节点。
还有什么可能发生? 单元中机架丢失。
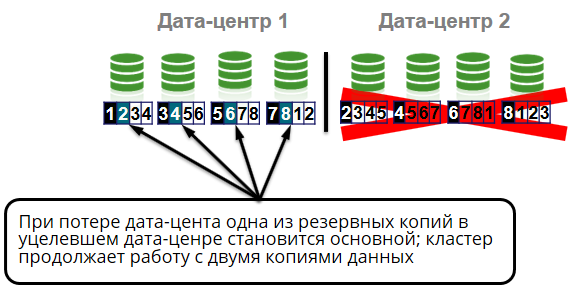
单元的所有节点都在不同的机架中。 即 机架输出不会导致群集故障或数据丢失。 我们将有四个副本的三个副本。 但是,即使我们失去了整个数据中心,这对我们也不是什么大问题,因为 我们仍然有四个数据的两个副本。
在支持工程师的协助下,某些情况直接在数据中心执行。 例如,关闭硬盘驱动器,关闭服务器或机架的电源。
可靠性案例:网络
为了测试与网络碎片相关的案例,我们使用iptables。 并使用NetEm实用程序进行仿真:
- 具有不同分配功能的网络延迟
- 丢包
- 包重试
- 重新排序数据包
- 包失真
我们正在测试的另一个有趣的网络案例是裂脑。 此时群集的所有节点都处于活动状态,但是由于网络分段,它们无法相互通信。 这个术语来自医学,意味着大脑被分为两个半球,每个半球都认为自己是独特的。 集群可能发生相同的情况。
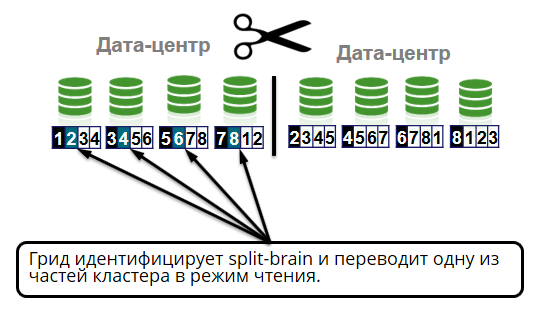
发生在数据中心之间的连接消失了。 例如,去年,由于挖掘机损坏了光缆,Tochka,Otkrytie和Rocketbank银行的银行客户数小时未通过Internet进行交易,终端机不接受卡且ATM机无法工作。 在Twitter上已经有很多有关此事故的文章。
在我们的情况下,应该正确处理裂脑情况。 网格标识裂脑-将群集分为两部分。 一半进入读取模式。 这是存在更多活动节点或协调器位于的一半(集群中最旧的节点)。
可靠性案例:软件
这些是与各种子系统故障有关的情况:
- DPL ORM-数据访问模块,例如Hibernate ORM
- 模间传输-模块之间的消息传递(微服务)
- 测井系统
- 门禁系统
- Apache Ignite群集
- ...
由于大多数软件都是用Java编写的,因此我们很容易遇到Java应用程序固有的所有问题。 测试各种垃圾收集器设置。 Java虚拟机崩溃时运行测试。
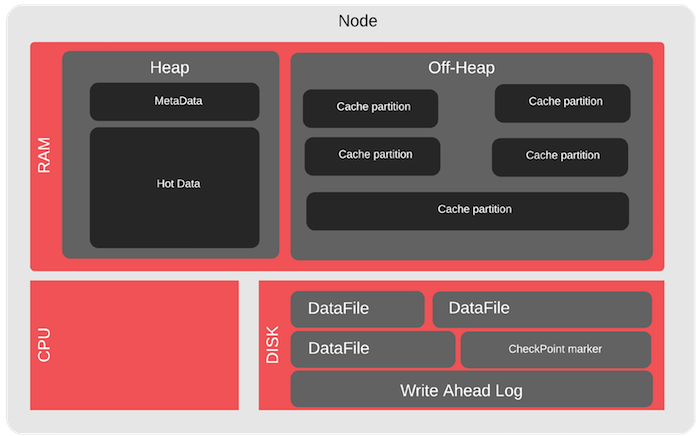
对于Apache Ignite集群,有一些特殊情况会出现堆外情况-这是Apache Ignite控制的内存区域。 它比Java堆大得多,并且旨在存储数据和索引。 例如,您可以在此处测试溢出。 我们从堆外溢出,看看当某些数据不适合RAM时群集如何工作,即 从磁盘读取。
其他情况
这些是前三组中未包括的情况。 这些工具包括一些实用程序,它们可以在发生重大事故或将数据迁移到另一个群集时恢复数据。
- 用于创建数据快照(备份)的实用程序-测试完整快照和增量快照。
- 恢复到特定的时间点-PITR(时间点恢复)机制。
故障注入实用程序
我记得我报告中的示例
链接 。 您可以从官方网站
Apache Ignite Downloads下载Apache Ignite发行版 。 现在,如果您突然对该主题感兴趣,我将分享我们在Sberbank使用的实用程序。
构架
配置管理:
Linux实用程序:
负载测试工具:
无论是在现代世界还是在Sberbank中,所有变化都是动态的,很难预测未来几年将使用哪些技术。 但是我确定我们将使用“故障注入”方法。 该方法是通用的-适用于测试任何技术,它确实有效,它有助于捕获许多错误并使我们开发的产品更好。