可能,任何通常具有搜索功能的服务迟早都需要学习如何解决用户查询中的错误。 人文交流; 用户经常被封印和错误输入,因此搜索的质量不可避免地受到影响-随之而来的是用户体验。
此外,每个服务都有其自己的详细信息,自己的词汇表,这些词汇表应能够操作错字校正器,这使现有解决方案的使用大大复杂化。 例如,此类请求必须学会编辑我们的监护人:
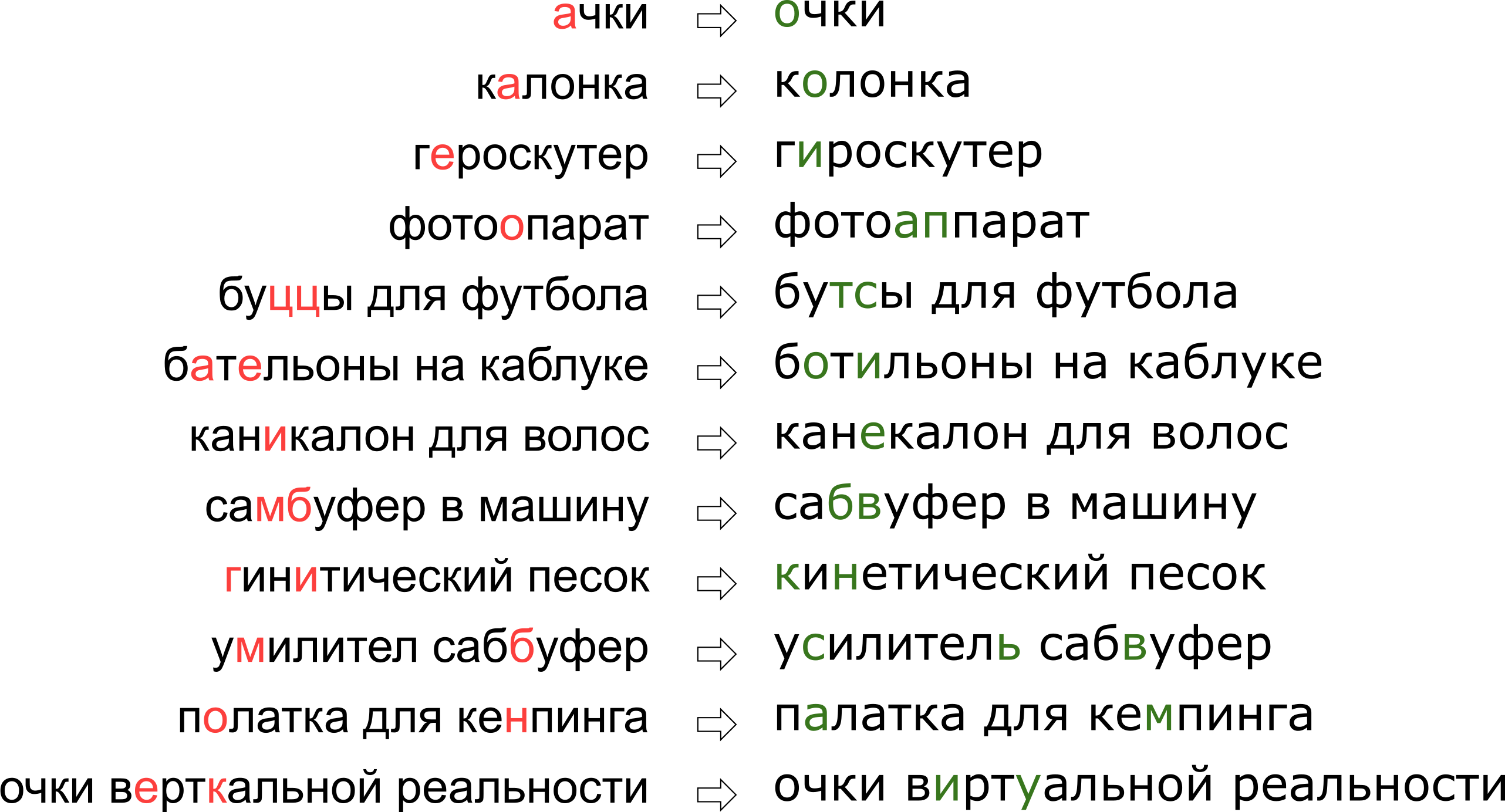 似乎我们已经拒绝了用户他对垂直现实的梦想,但实际上,字母K只是站在键盘上,字母U旁边。
似乎我们已经拒绝了用户他对垂直现实的梦想,但实际上,字母K只是站在键盘上,字母U旁边。在本文中,我们将介绍纠正拼写错误的经典方法之一,从构建模型到用Python和Go编写代码。 另外,我的报告“
垂直现实眼镜”中有一段视频
:我们纠正了Highload ++上
搜索查询中的错别字 。
问题陈述
因此,我们收到了密封的要求,我们需要对其进行修复。 通常,该问题在数学上是如下所示:
- 给定单词 s 错误地传送给我们;
- 有字典 \西格玛 正确的话;
- 对于词典中的所有单词w,都有条件概率 P ( w的| s ) 这个词是什么意思 w 只要我们知道 s ;
- 您需要以最大的概率从字典中找到单词w P ( w的| s ) 。
该陈述(最基本的陈述)表明,如果我们收到几个单词的请求,那么我们将分别更正每个单词。 当然,在现实中,考虑到相邻单词的兼容性,我们将需要对整个短语进行整体校正。 我将在稍后的“如何更正短语”部分中对此进行讨论。
有两个不清楚的时刻-在哪里获得字典以及如何计数
P ( w的| s ) 。 第一个问题被认为很简单。 在1990年[1],该字典是从
拼写实用程序数据库和电子词典中汇编而来的; 在2009年,Google [4]做得更简单,仅采用了互联网上最流行的单词(以及流行的拼写错误)。 我采用这种方法来建立我的监护人。
第二个问题更为复杂。 仅仅是因为他的决定通常始于贝叶斯公式的应用!
P ( w的| s ) = m a t h r m c o n s t c d o t P ( s | 瓦特) Ç d Ô 吨P (瓦特)
现在,我们需要评估两个新的,更容易理解的东西,而不是最初难以理解的可能性:
P (小号| w ) -键入单词时的概率
w 可以密封起来
s 和
P ( w ) -原则上,用户使用单词的概率
w 。
如何评价
P (小号| w ) ? 显然,与b与S相比,用户更可能将A与O混淆。 并且,如果我们更正了从扫描文档中识别出的文本,那么rn和m之间很可能会造成混淆。 一种或另一种方式,我们需要某种模型来描述错误及其概率。
这样的模型称为噪声通道模型(噪声通道模型;在我们的例子中,噪声通道始于用户
Brock中心的某个
位置,在用户键盘的另一端结束),或更简单地说,错误模型就是错误模型。 此模型将在下面的单独部分中进行讨论,它将负责同时考虑拼写错误和错别字。
评价使用单词的可能性-
P ( w ) -有可能以不同的方式。 最简单的选择是采用该词在某些大型语料库中出现的频率。 对于我们的监护人来说,考虑到短语的上下文,当然,需要更复杂的东西-另一种模型。 该模型称为语言模型,即语言模型。
错误模型
考虑了第一个错误模型
P (小号| w ) ,计算训练集中基本替换的概率:他们写了AND而不是E多少次,他们写了T而不是T-T而不是T等等[1]。 事实证明,该模型具有少量参数,可以学习一些局部效应(例如,人们经常将E和I混淆)。
在我们的研究中,我们选择了Brill和Moore [2]在2000年提出的,并在以后进行重用的更先进的错误模型(例如,由Google专家[4]使用)。 想象一下,用户不会考虑使用单独的字符(将E和I混淆,按K而不是Y,跳过软符号),但是可以将单词的任意部分更改为其他任何部分-例如,用TYSYA替换TSYA,用K替换Y,用SHCHYA,SS替换SHCHA到C等。 用户被密封而不是TSYA写下THY的概率,我们表示
P(\文字千 rightarrow\文字千) 是我们模型的参数。 如果所有可能的碎片
alpha, beta 我们可以数
P( alpha rightarrow beta) ,那么期望的概率
P(s|w) 尝试在Brill and Moore模型中键入单词w时,可以得到一组单词s,如下所示:我们以所有可能的方式将单词w和s分成较短的片段,以使两个单词中的片段数量相同。 对于每个分区,我们计算所有片段w变成相应片段s的概率乘积。 所有此类分区的最大值将作为
P(s|w) :
P(s|w)= maxs= alpha1 alpha2 ldots alphak,w= beta1 beta2 ldots betakP( alpha1 rightarrow beta1) cdotP( alpha2 rightarrow beta2) cdot ldots cdotP( alphak rightarrow betak)\,
让我们看一下在计算打印“附件”而不是“附件”的可能性时发生的分区的示例:
\开始矩阵\文本ak&\文本cec&\文本sou&\文本a&\文本p downarrow& downarrow& downarrow& downarrow& downarrow\文本a&\文本cc&\文本e&\文本soua&\文本p\结束matrix
您可能已经注意到,这是分区不是很成功的一个示例:很明显,单词的各个部分并没有尽可能地成功地位于彼此之间。 如果数量
P(\文字ak rightarrow\文字a) 和
P(\文字p rightarrow\文字p) 那还算不错
P(\文字sou rightarrow\文字e) 和
P(\文字a rightarrow\文字soua) 他们很可能会使该分区的最终“分数”完全令人难过。 一个更成功的分区如下所示:
beginmatrix textak& textce& textss& texty& textar downarrow& downarrow& downarrow& downarrow& downarrow\文本ak&\文本ce&\文本c&\文本y&\文本ar\结束matrix
在这里,一切立即就位,很明显最终概率将主要由值决定
P(\文字ss rightarrow\文字s) 。
如何计算 P(s|w)
尽管存在两个单词可能的分区顺序
O(2|s|+|w|) 使用动态规划计算算法
P(s|w) 可以做得非常快-对于
O(|s|2|w|2) 。 该算法本身将非常类似于
Wagner-Fisher算法,用于计算
Levenshtein距离 。
我们将创建一个矩形表,该表的行将与正确单词的字母相对应,而列将与密封的表格相对应。 尝试打印
w[:i]时,在算法结束时,第i行与第j列交点处的像元将完全具有获得
s[:j]的概率。 为了对其进行计算,只需计算先前行和列中所有单元格的值并遍历它们,然后乘以相应的
P( alpha rightarrow beta) 。 例如,如果我们有一张桌子
,然后要填充第四行和第三列(灰色)中的单元格,您需要取最大值
0.8 cdotP(\文本cc rightarrow\文本c) 和
0.16 cdotP(\文本c rightarrow\文本k) 。 同时,我们浏览了图中绿色突出显示的所有单元格。 如果我们还考虑修改表格
P( alpha rightarrow\文字空白行) 和
P(\文字空白行 rightarrow beta) ,那么您必须遍历以黄色突出显示的单元格。
如上所述,该算法的复杂度为
O(|s|2|w|2) :我们填写表格
|s|\次|w| ,并填充所需的单元格(i,j)
O(i cdotj) 操作。 但是,如果我们只考虑片段长度不超过一定限制的片段
L (例如[4]中最多两个字母),复杂度将降低为
O(|s| cdot|w| cdotL2) 。 我在实验中以俄语学习
L=3 。
如何最大化 P(s|w)
我们学会了寻找
P(s|w) 对于多项式时间是好的。 但是我们需要学习如何快速找到整个词典中的最佳单词。 最好的不是
P(s|w) ,但是
P(w|s) ! 实际上,对于我们来说,获得一些合理的最佳(例如最佳20个)字词就足够了
P(s|w) ,然后我们将其发送到语言模型以选择最适当的更正(有关更多信息,请参见下文)。
要了解如何快速浏览整个词典,请注意,上面列出的表格在两个带有共同前缀的单词上有许多共同之处。 的确,如果我们纠正“ accessory”一词,并尝试为两个词汇单词“ accessory”和“ accessories”填写,我们会注意到它们中的前九行根本没有区别! 如果我们可以安排一个字典遍,以使接下来的两个单词具有足够长的公共前缀,则可以节省很多计算。
而且我们可以。 让我们接受词汇,使它们变
简 。 深入研究它,我们将获得所需的属性:当表需要填充最后几行时,大多数步骤是从节点到其后代的步骤。
该算法,加上一些其他的优化,使我们能够在100毫秒内以50万到10万个单词来整理出典型的欧洲语言的字典[2]。 缓存结果将使过程更快。
如何获得 P( alpha rightarrow beta)
计算方式
P( alpha rightarrow beta) 对于所有正在考虑的片段-构建错误模型中最有趣且最重要的部分。 正是这些数量决定了其质量。
[2,4]中使用的方法相对简单。 找很多夫妻
(si,wi) 在哪里
wi 是词典中的正确单词,并且
si -其密封版本。 (如何精确找到它们要低一些。)现在,我们需要从这些对中提取特定错别字的概率(将某些片段替换为其他片段)。
对于每一对,我们都会考虑其组成部分
w 和
s 并在它们的字母之间构造一个对应关系,以最小化Levenshtein距离:
\开始矩阵\文本a&\文本c&\文本c&\文本e&\文本c&\文本c&\文本y&\文本a&\文本p\文本a&\文本k&\文本c&\文本e&\文本c&\文本&\文本y&\文字a&\文字p\结束matrix
现在我们立即看到替换:a→a,e→和c→c,c→空字符串,依此类推。 我们还会看到两个或多个字符的替换:ak→ak,ce→si,ec→is,ss→s,ses→sis,ess→is和其他,依此类推。 必须对所有这些替换进行计数,每次替换次数与单词s出现在语料库中的次数相同(如果很可能是从语料库中获取的话)。
成对通过后
(si,wi) 为了概率
P( alpha rightarrow beta) 接受我们对中出现的替换数α→β(考虑到相应单词的出现)除以片段α的重复数。
如何寻找情侣
(si,wi) ? 在[4]中,提出了这种方法。 大量用户生成的内容(UGC)。 以Google为例,它只是数亿个网页的文字; 我们的网站拥有数百万个用户搜索和评论。 假定通常在正确的单词中比在任何错误的变体中都更容易找到正确的单词。 因此,让我们从语料库中的Levenshtein中找到每个与之接近的单词的单词,这些单词的受欢迎程度要低得多(例如,十倍)。 受欢迎
w ,不那么受欢迎-
s 。 因此,我们得到了嘈杂的训练,但是有很多对训练。
这种对匹配算法留有很大的改进空间。 在[4]中,仅按出现次数进行过滤(
w 比十倍流行
s ),但本文的作者试图在不使用任何先验知识的情况下进行八卦。 如果仅考虑俄语,例如,我们可以采用一
组俄语单词形式的字典,而只保留与单词成对的单词
w 在字典中找到的单词(不是一个好主意,因为字典很可能没有特定于服务的词汇),或者相反,丢弃与在字典中找到的单词s成对的单词(也就是说,几乎保证不加密封)。
为了提高接收对的质量,我编写了一个简单的函数来确定用户是否使用两个单词作为同义词。 逻辑很简单:如果经常在单词w和s周围发现相同的单词,那么它们很可能是同义词-根据Levenshtein的说法,由于它们的亲密关系,这意味着不太受欢迎的单词很可能是更受欢迎的单词的错误版本。 对于这些计算,我使用了为以下语言模型构建的三字组(三个单词的短语)的出现统计信息。
语言模型
因此,对于给定的字典词w,我们需要计算
P(w) -用户使用它的可能性。 最简单的解决方案是在某种较大的情况下考虑单词的出现。 通常,任何语言模型都可能首先收集大量的文本语料库并计算其中出现的单词数。 但是,我们不应该局限于此:实际上,在计算P(w)时,我们还可以考虑尝试更正单词的短语以及任何其他外部上下文。 任务变成计算任务
P(w1w2 ldotswk) 其中之一
wi -我们改正了错字并正在为之计数的单词
P(w) 其余的
wi -用户请求中已更正单词周围的单词。
要学习如何将它们考虑在内,有必要再次遍历语料库并编制n元语法,单词序列的统计信息。 通常采用有限长度的序列; 我将自己限制在Trigram上,以免膨胀索引,但这全都取决于您的思维能力(以及案例的大小-在很小的情况下,甚至Trigram的统计信息也会太嘈杂)。
传统的n-gram语言模型如下所示。 对于这句话
w1w2 ldotswk 它的概率由公式计算
P(w1w2 ldotswk)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2)P(wk|w1w2wk−1) ,,
在哪里
P(w1) -直接词的频率,和
P(w3|w1w2) -单词概率
w3 只要在他走之前
w1w2 -除了三连音频率的比率
w1w2w3 到二元频率
w1w2 。 (请注意,此公式只是重复使用贝叶斯公式的结果。)
换句话说,如果我们要计算
P(\文字妈妈肥皂架) ,表示中任意n-gram的频率
f 我们得到公式
P(\文本妈妈肥皂框架)=f(\文本妈妈肥皂) cdot fracf(\文本妈妈肥皂)f(\文本妈妈) cdot\蛋糕f( text妈妈肥皂框架)f( text妈妈肥皂框架)=f( text妈妈肥皂框架)\,。
这合乎逻辑吗? 是合乎逻辑的。 然而,当短语变得更长时,困难就开始了。 如果用户输入了一个包含令人印象深刻的细节的十字搜索查询,该怎么办? 我们不想保留所有10克的统计信息-这是昂贵的,并且数据很可能是嘈杂的且无指示性。 我们想用有限长度的n-gram来计算-例如,上面已经提出的长度3。
这是上面的公式派上用场的地方。 假设一个单词出现在词组末尾的概率仅受紧接在它前面的几个单词的影响很大,也就是说,
P(wk|w1w2 ldotswk−1)\约P(wk|wk−L+1 ldotswk−1)\,。
推杆
L=3 ,对于更长的短语,我们得到公式
P(\文字{卡尔从克拉拉偷走珊瑚})\约f(\文字{carl})\ cdot \压裂{f(\文字{carl})} {f(\文字{carl})} \ cdot \ frac {f(\ text {卡尔从克拉拉}}}} {f(\ text {卡尔从克拉拉}}} \ cdot \ frac {f(\ text {从克拉拉偷来的}}}} {f(\ text {来自克拉拉} )} \ cdot \ frac {f(\文字{claire偷珊瑚}}} {f(\文字{claire偷珊瑚})} \,。请注意:该短语包含5个单词,但是在公式中出现的n-gram不能超过3个。 这正是我们所追求的。
只剩下一个薄弱的时刻。 如果用户在我们的统计数据中输入了一个非常奇怪的词组和相应的n-gram,该怎么办呢? 不熟悉的n-gram容易放入
f=0 如果不需要除以该值。 这里涉及平滑(smoothing)的帮助,可以用不同的方法来完成。 但是,对诸如
Kneser-Ney平滑之类的严肃抗锯齿方法的详细讨论远远超出了本文的范围。
如何纠正短语
在进行实施之前,我们将讨论最后一个微妙的问题。 我在上面描述的问题的陈述暗示只有一个词,需要解决。 然后,我们澄清了这个单词可能在其他单词中间的短语中,还需要考虑它们,选择最佳的更正。 但是实际上,用户只是向我们发送了短语,而没有指定拼写哪个单词。 通常只需要纠正几句话,甚至全部纠正。
可以有很多方法。 例如,您可以仅考虑词组中单词的左上下文。 然后,按照从左到右的单词进行操作并根据需要进行更正,我们将获得一个质量更高的新短语。 例如,如果第一个单词被证明像几个受欢迎的单词一样,而我们选择了错误的选项,则质量会很差。 我们会将整个剩余的短语(可能一开始可能完全没有错误)调整为错误的第一个单词,并且我们可以获得与原始单词完全无关的文本。
您可以单独考虑这些单词,并应用特定的分类器来了解给定单词是否是密封的,如[4]中所建议。 分类器接受了我们已经知道如何计数的概率以及许多其他功能的训练。 如果分类器说出需要修复的内容,则在给定现有上下文的情况下,我们正在对其进行更正。 同样,如果几个单词拼写错误,您将必须根据存在错误的上下文对第一个单词做出决定,这可能会导致质量问题。
在执行我们的监护人时,我们使用了这种方法。 每个字都给我们
si 在我们的短语中,使用错误模型,我们找到了可能意味着最高前N个的词典单词,我们以各种可能的方式将它们连接到短语中,
NK 结果短语在哪里
K -原始短语中的单词数,如实计算值
P(s1|w1) cdotP(sK|wK) cdotP(sK|wK) cdotP(w1w2 ldotswK) lambda\,。
在这里
si -用户输入的单词,
wi -为他们选择的更正(我们正在对其进行排序),以及
lambda -由误差模型和语言模型的比较质量确定的系数(较大的系数-我们更信任语言模型,较小的系数-我们更信任错误模型),在[4]中提出。 总体而言,对于每个短语,我们将各个单词在相应的词典变体中要纠正的概率相乘,并且还将其乘以我们语言中整个短语的概率。 该算法的结果是来自字典单词的短语,该短语使该值最大化。
那停什么 蛮力
NK 短语?
幸运的是,由于我们限制了n-gram的长度,因此可以更快地找到所有短语中的最大值。 请记住:上面我们简化了公式
P(w1w2 ldotswK) 因此它开始仅取决于长度不超过3的n克频率:
P(w1w2 ldotswK)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2) cdot ldots cdotP(w K | 的瓦特K个- 2 w的K个- 1) \, 。。
如果我们将此值乘以
P (s ^ 我| w ^ 我) 并尝试通过最大化
w的K个 ,我们将看到足以整理出各种
w K - 2 和
w K - 1 并为他们解决问题-即短语
瓦特1 瓦特2升d ö 吨小号瓦特ķ - 2瓦特ķ - 1 。 总的来说,这个问题是通过动态编程解决的
O ( K N 3 ) 。
实作
将案件放在一起并计算n克
我会立即进行预订:我没有太多数据可用来启动一些复杂的MapReduce。 因此,我只是从我们的服务中收集了所有俄文中的评论,评论和搜索查询的文本(商品描述,a,英语,以及使用自动翻译的结果而不是改善结果的效果),然后将其存储在一个文本文件中,并将服务器设置为可计数的夜晚一个简单的Python脚本的三元组。
作为一本字典,我选择了频率最高的单词,所以我得到了约十万个单词。 排除了太长的单词(超过20个字符)和太短的单词(少于3个字符,硬编码的著名俄语单词除外)。 单独保留规则性
r"^[a-z0-9]{2}$"上的单词
r"^[a-z0-9]{2}$" -这样,iPhone版本和其他有趣的长度为2的标识符就可以保留下来。
当在短语中计算双字母组和三字母组时,可能会出现非字典词。 在这种情况下,我抛出了这个单词,并将整个短语分为两个部分(在该单词之前和之后),我分别与之合作。 那么,对于短语“
您知道“ abyrvalg”是什么吗? 这是……HEADMAN,同事 “将考虑三元组”。你知道吗,“”你知道什么,“”是什么意思,“这就是首席渔民同事”(当然,“ HEADMAN”这个词落入字典中……)。
我们训练错误模型
此外,我在Jupyter中执行了所有数据处理。 n-gram的统计信息是从JSON加载的,根据Levenshtein进行后处理以快速找到彼此接近的单词,对于循环中的单词对,调用了一个(相当麻烦的)函数来排列单词并提取形式为ss→c的简短编辑(在剧透下)。
Python代码 def generate_modifications(intended_word, misspelled_word, max_l=2):
计数编辑本身看起来很基础,尽管可能需要很长时间。
应用错误模型
此部分在Go上实现为微服务,并通过gRPC与主后端连接。 由Brill和Moore自己描述的算法[2]进行了较小的优化。 结果,它对我有用,大约是作者声称的速度的两倍。 我不敢判断是Go还是我。 但是在分析过程中,我学到了一些有关Go的新知识。
- 不要使用
math.Max来计算最大值。 这比if a > b { b = a }慢三倍! 只要看一下这个函数的实现 :
除非您突然需要+0一定要大于-0,否则不要使用math.Max 。
- 如果可以使用数组,请不要使用哈希表。 当然,这是非常明显的建议。 我必须在程序开始时将Unicode字符重新编号为数字,以将它们用作trie节点的后代数组中的索引(这样的查找是非常常见的操作)。
- Go中的回调并不便宜。 在代码审查期间的重构过程中,尽管算法没有正式更改,但我进行脱耦的一些尝试明显降低了程序的速度。 从那时起,我一直认为Go优化编译器有增长的空间。
应用语言模型
在这里,毫无意外地实现了以上部分描述的动态编程算法。 该组件的工作最少,最慢的部分是错误模型的应用。
因此,在这两层之间,错误模型缓存在Redis中的结果被额外拧紧了。结果
根据这项工作的结果(大约花了一个月的时间),我们对用户进行了A / B测试。在引入监护人之前,我们在所有搜索查询中没有空搜索结果的10%,而是5%。基本上,其余的请求是针对我们平台上根本没有的商品。没有第二个搜索查询的会话数量也有所增加(以及与UX相关的其他几种指标)。但是,与金钱相关的指标并未发生重大变化-这是出乎意料的,这使我们对其他指标进行了彻底的分析和交叉检查。结论
有人告诉史蒂芬·霍金(Stephen Hawking),他在书中包含的每个公式都会使读者数量减半。好吧,在本文中,大约有五十个-我祝贺你,其中一个到达此地点的 10 至10位读者!红利
参考文献
[1]西澳大风KW教堂的MD Kernighan。基于噪声通道模型的拼写校正程序。第13届计算语言学会议论文集,第2卷,1990年。[2] E.Brill,RC摩尔。一种改进的噪声通道拼写校正误差模型。关于计算语言学协会的第38届年度会议论文集,2000年。[3] T.布兰特,AC Popat,P。Xu,FJ Och,J。Dean。机器翻译中的大语言模型。 2007年自然语言处理的经验方法会议论文集。[4] C. Whitelaw,B。Hutchinson,GY Chung,G。Ellis。使用Web进行语言独立的拼写检查和自动更正。2009年自然语言处理经验方法会议论文集:第2卷。