晚上好
在
“ C ++开发人员”课程中,
我们为您提供了有关并行算法的小型而有趣的研究。
走吧
随着C ++ 17中并行算法的问世,您可以轻松地更新“计算”代码并从并行执行中受益。 在本文中,我想考虑STL算法,它自然揭示了独立计算的思想。 我们可以期望10核处理器实现10倍的加速吗? 也许更多? 还是更少? 让我们来谈谈。
并行算法简介
C ++ 17为大多数算法提供了执行策略设置:
- sequenced_policy-执行策略的类型,用作消除并行算法过载和无法并行执行并行算法的要求的唯一类型:相应的全局对象为
std::execution::seq ; - parallel_policy-一种执行策略的类型,用作消除并行算法过载的唯一类型,并表示可以并行执行并行算法:相应的全局对象为
std::execution::par ; - parallel_unsequenced_policy-一种执行策略,用作唯一类型,以消除并行算法重载并表明并行算法执行的并行化和矢量化是可能的:
简要地:
- 使用
std::execution::seq顺序执行算法; - 使用
std::execution::par并行执行算法(通常使用某些线程池实现(线程池)); - 使用
std::execution::par_unseq可以并行执行算法,并可以使用矢量命令(例如SSE,AVX)。
举个简单的例子,调用
std::sort并行
std::sort :
std::sort(std::execution::par, myVec.begin(), myVec.end());
请注意,向算法添加并行执行参数是多么容易! 但是,能否实现显着的性能改进? 会增加速度吗? 还是有放缓的趋势?
并行std::transform在本文中,我要注意
std::transform算法,它可能是其他并行方法的基础(以及
std::transform_reduce ,
for_each ,
scan ,
sort等)。
我们的测试代码将根据以下模板构建:
std::transform(execution_policy,
假设
ElementOperation函数没有同步方法,在这种情况下,代码具有并行执行甚至矢量化的潜力。 每个元素的计算都是独立的,顺序无关紧要,因此,实现可以生成多个线程(可能在线程池中)以进行元素的独立处理。
我想尝试以下事情:
- 向量场的大小是大还是小;
- 一个简单的转换,花费大部分时间访问内存;
- 更多算术(ALU)运算;
- 在更现实的情况下使用ALU。
如您所见,我不仅要测试使用并行算法的“好”元素数量,还要测试占用处理器的ALU操作。
其他算法,例如排序,累加(以std :: reduce的形式)也提供并行执行,但还需要更多工作来计算结果。 因此,我们将把它们视为另一篇文章的候选人。
基准说明
对于我的测试,我使用Visual Studio 2017 15.8-因为这是当前(2018年11月)流行的/ STL编译器实现中的唯一实现(正在开发中的GCC!) 而且,由于MSVC中不支持
execution::par_unseq (我的工作方式与
execution::par相似),因此我仅关注
execution::par 。
有两台计算机:
- i7 8700-PC,Windows 10,i7 8700-3.2 GHz,6核/ 12线程(超线程);
- i7 4720-笔记本电脑,Windows 10,i7 4720、2.6 GHz,4核/ 8线程(超线程)。
该代码在x64中编译,发布更多,默认情况下启用自动矢量化,我还包括一组扩展命令(SSE2)和OpenMP(2.0)。
代码在我的github中:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cpp对于OpenMP(2.0),我仅对循环使用并行处理:
#pragma omp parallel for for (int i = 0; ...)
我将代码运行5次,并查看最低结果。
警告 :结果仅反映粗略的观察;在生产中使用之前,请检查系统/配置。 您的要求和环境可能与我的有所不同。您可以在本文中阅读有关MSVC实现的更多
信息 。
这是 Bill O'Neill在CppCon 2018上的最新
报告 (Bill在MSVC中实现了并行STL)。
好吧,让我们从简单的例子开始!
简单转换考虑将非常简单的操作应用于输入向量的情况。 它可以是元素的复制或乘法。
例如:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
我的计算机有6或4个内核...我可以期望4..6倍的顺序执行速度吗? 这是我的结果(时间以毫秒为单位):
| 运作方式 | 向量大小 | i7 4720(4核) | i7 8700(6核) |
|---|
| 执行:: seq | 10k | 0.002763 | 0.001924 |
| 执行::票面金额 | 10k | 0.009869 | 0.008983 |
| openmp并行 | 10k | 0.003158 | 0.002246 |
| 执行:: seq | 100k | 0.051318 | 0.028872 |
| 执行::票面金额 | 100k | 0.043028 | 0.025664 |
| openmp并行 | 100k | 0.022501 | 0.009624 |
| 执行:: seq | 1000千 | 1.69508 | 0.52419 |
| 执行::票面金额 | 1000千 | 1.65561 | 0.359619 |
| openmp并行 | 1000千 | 1.50678 | 0.344863 |
在更快的机器上,我们可以看到大约需要一百万个元素才能注意到性能的提高。 另一方面,在我的笔记本电脑上,所有并行实现都比较慢。
因此,即使元素数量增加,使用这种转换也很难注意到任何显着的性能改进。
为什么这样
由于操作是基本操作,因此处理器内核几乎可以使用几个周期立即调用它。 但是,处理器内核会花费更多时间等待主内存。 因此,在这种情况下,大多数情况下他们将等待而不进行计算。
如果缓存了变量,则在内存中读写该变量大约需要2-3个周期,如果不缓存则需要数百个周期。https://www.agner.org/optimize/optimizing_cpp.pdf您可以粗略地注意到,如果您的算法依赖于内存,那么您不应指望并行计算会提高性能。
更多计算由于内存带宽至关重要,并且会影响事物的速度...让我们增加影响每个元素的计算量。
想法是最好使用处理器周期,而不是浪费时间等待内存。
首先,我使用三角函数,例如
sqrt(sin*cos) (这些是非最优形式的条件计算,只是为了占用处理器)。
我们使用
sqrt ,
sin和
cos ,每个
sqrt可能需要
sqrt ,每个三角函数可能需要〜100。 此计算量可以覆盖内存访问延迟。
有关团队延误的更多信息,请参阅
Agner Fogh撰写的出色的
Perf指南 。
这是基准代码:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
现在呢? 我们可以指望在以前的尝试中获得性能提升吗?
以下是一些结果(时间以毫秒为单位):
| 运作方式 | 向量大小 | i7 4720(4核) | i7 8700(6核) |
|---|
| 执行:: seq | 10k | 0.105005 | 0.070577 |
| 执行::票面金额 | 10k | 0.055661 | 0.03176 |
| openmp并行 | 10k | 0.096321 | 0.024702 |
| 执行:: seq | 100k | 1.08755 | 0.707048 |
| 执行::票面金额 | 100k | 0.259354 | 0.17195 |
| openmp并行 | 100k | 0.898465 | 0.189915 |
| 执行:: seq | 1000千 | 10.5159 | 7.16254 |
| 执行::票面金额 | 1000千 | 2.44472 | 1.10099 |
| openmp并行 | 1000千 | 4.78681 | 1.89017 |
最后,我们看到不错的数字:)
对于1000个元素(此处未显示),并行和顺序计算时间相似,因此对于1000个以上的元素,我们看到并行版本有所改进。
对于10万个元素,在速度更快的计算机上的结果几乎是串行版本(与OpenMP版本类似)的9倍。
在一百万个元素的最大版本中,结果快5或8倍。
对于此类计算,我实现了“线性”加速,具体取决于处理器内核的数量。 这是意料之中的。
菲涅耳和三维向量在上一节中,我使用了“发明”计算,但是真实代码呢?
让我们求解菲涅耳方程,该方程描述了来自平滑表面的光的反射和曲率。 这是在3D游戏中生成逼真的照明的一种流行方法。
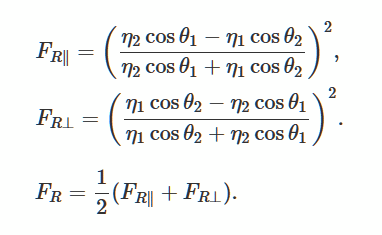
 维基媒体的照片
维基媒体的照片作为一个很好的例子,我找到了
这个描述和实现 。
关于使用GLM库我没有使用自己的实现,而是使用
glm库 。 我经常在我的OpenGl项目中使用它。
通过
Conan Package Manager可以轻松访问该库,因此我也将使用它。
链接到包。
柯南文件:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
以及安装库的命令行(它会生成可在Visual Studio项目中使用的props文件):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
该库包含一个标头,因此您可以根据需要手动下载它。
实际代码和基准我从
scratchapixel.com改编了glm的代码:
该代码使用了几种数学指令,标量乘积,乘法,除法,因此处理器需要做一些事情。 代替双重向量,我们使用4个元素的向量来增加使用的内存量。
基准测试:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
结果如下(时间以毫秒为单位):
| 运作方式 | 向量大小 | i7 4720(4核) | i7 8700(6核) |
|---|
| 执行:: seq | 1千 | 0.032764 | 0.016361 |
| 执行::票面金额 | 1千 | 0.031186 | 0.028551 |
| openmp并行 | 1千 | 0.005526 | 0.007699 |
| 执行:: seq | 10k | 0.246722 | 0.169383 |
| 执行::票面金额 | 10k | 0.090794 | 0.067048 |
| openmp并行 | 10k | 0.049739 | 0.029835 |
| 执行:: seq | 100k | 2.49722 | 1.69768 |
| 执行::票面金额 | 100k | 0.530157 | 0.283268 |
| openmp并行 | 100k | 0.495024 | 0.291609 |
| 执行:: seq | 1000千 | 08/25/28 | 16.9457 |
| 执行::票面金额 | 1000千 | 5.15235 | 2.33768 |
| openmp并行 | 1000千 | 5.11801 | 2.95908 |
通过“真实”计算,我们看到并行算法可提供良好的性能。 对于我的两台Windows机器上的此类操作,我实现了加速,并且对内核数的依赖关系几乎是线性的。
对于所有测试,我还展示了OpenMP和两个实现的结果:MSVC和OpenMP的工作原理类似。
结论在本文中,我研究了使用并行计算和并行算法的三种情况。 用std :: execution :: par版本替换标准算法似乎很诱人,但这并不总是值得做的! 您在算法内部使用的每个操作的工作方式可能不同,并且更多地取决于处理器或内存。 因此,请分别考虑每个更改。
要记住的事情:
- 通常,并行执行比顺序执行更多,因为库必须为并行执行做准备;
- 不仅元素的数量很重要,而且处理器占用的指令数量也很重要;
- 最好执行彼此独立且与其他共享资源无关的任务;
- 并行算法提供了一种将工作拆分为单独线程的简便方法;
- 如果您的操作依赖于内存,则不应期望性能有所提高,并且在某些情况下,算法可能会变慢;
- 为了获得可观的性能改进,请始终衡量每个问题的时机,在某些情况下,结果可能会完全不同。
特别感谢JFT为本文提供的帮助!
还请注意我有关并行算法的其他资料:
看看与并行算法有关的另一篇文章:
如何使用Intel Parallel STL和C ++ 17并行算法提高性能结束
我们正在等待您可以留在这里或在
敞开的门的 老师的意见和问题。