优化的AOT编译器通常是这样的:
- 前端将源代码转换为中间表示
- 与机器无关的优化(IR)管道:重写IR的一系列过程,以消除无法直接转换为机器代码的低效部分和结构。 有时这部分称为中端。
- 机器相关的后端,用于生成汇编代码或机器代码。

在某些编译器中,IR格式在整个优化过程中保持不变,而在另一些编译器中,其格式或语义会发生变化。 在LLVM中,格式和语义是固定的,因此可以按任何顺序运行传递,而不会产生错误的编译或编译器崩溃的风险。
优化过程的顺序是由编译器开发人员开发的,目的是在可接受的时间内完成工作。 它会不时变化,当然,还有一组不同的遍以不同的优化级别运行。 计算机研究中的长期主题之一是使用机器学习或其他方法来找到适用于常规用途和针对默认管道不太适合的特定应用的最佳优化管道。
设计段落的原则是极简主义和正交性:每遍都应做好一件事,并且其功能不应重叠。 实际上,折衷有时是可能的。 在实践中,当两个过程相互产生工作时,可以将它们合并为一个较大的过程。 而且,某些IR级功能(例如折叠常量运算符)非常有用,以至于没有必要将其放在单独的通道中,默认情况下,LLVM在创建指令时将常量操作减至最少。
在这篇文章中,我们将了解一些LLVM优化如何工作。 我的意思是,您阅读
了有关Clang如何编译函数的
这一部分 ,或者您或多或少了解了LLVM IR的工作方式。 理解SSA(静态单项分配)形式特别有用:
Wikipedia将为您提供简介,而
这本书将为您提供比您想知道的更多的信息。 另请阅读《
LLVM语言参考》和
优化过程列表 。
让我们看看Clang / LLVM 6.0.1如何优化此C ++代码:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
同时,我们记得优化管道是一个非常繁忙的地方,我们将错过很多有趣的时刻,例如:
内联是一个简单但非常重要的优化,在此示例中不会发生,因为 我们只考虑一种功能。 几乎所有针对C ++的优化,但并非针对C的优化。自动向量化可防止过早退出循环
在下面的文本中,我将跳过所有未更改代码的步骤。 另外,我们不会研究后端,后端也会做很多工作。 但是,即使剩下的段落也很多! (对不起,图片,但这似乎是避免格式化困难的最佳方法)。
这是 Clang创建
的IR文件 (我手动删除了Clang插入的“ optnone”属性)和用于查看每个优化过程效果的命令行:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
首先是
CFG简化 (控制流程图)。 由于Clang不执行优化,因此它产生的IR包含简单的优化选项:

在此,基本单元26简单地移动到块27。可以通过目的地块将对它们的引用重定向来删除这些块。 LLVM将自动为块重新编号。 由SimplifyCFG生成的转换的完整列表在通道的顶部列出。
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
CFG优化的大多数机会是其他LLVM通过的工作的结果。 例如,删除死代码消除和移动循环不变量很容易导致空基块。
下一段落
SROA (骨料的标量替代)是使用最广泛的方法之一。 由于SROA只是其功能之一,因此其名称引起了一些混乱。 通过检查每个alloca指令(函数堆栈上的内存分配),并尝试将其转换为SSA寄存器。 如果一条alloca指令(
实际上是大约Transl ..
堆栈上的一个变量 )被多次静态分配,则变成许多寄存器,如果alloca是类或结构,则将其分为多个组件(称为“标量”)替换”(在文章名称中指)。 一个简单的SROA版本会将其使用地址获取操作的堆栈变量交出,但是LLVM版本与别名分析算法交互并以智能的方式起作用(尽管在下面的示例中不需要这样做)。

在SROA之后,alloca指令(以及相应的加载和存储指令)消失,并且代码变得更简洁并且更适合后续优化(当然,在一般情况下SROA无法删除所有alloca,只有在指针分析可以完全摆脱别名)。 在此过程中,SROA将phi指令插入代码中。 phi指令构成了SSA表示法的核心,Clang生成的代码中缺少phi告诉我们Clang生成了SSA的普通版本,其中,基本块通过内存而不是通过SSA寄存器连接。
接下来是“
早期消除常见子表达 ”,CSE(早期消除常见子表达)。 CSE试图消除在人工编写的代码和部分优化的代码中都可能发生过度子表达式的情况。 “早期CSE”是CSE的快速简便版本,它揭示了微不足道的冗余计算。

此处,%10和%17做相同的事情,也就是说,可以重写代码,以便使用一个值,然后删除第二个值。 这使您对SSA的好处有了一些了解:当每个寄存器仅分配一次时,就不会有单个寄存器的多个版本。 因此,无需使用程序的深入分析就可以使用语法等价来检测冗余计算(SSA世界之外的内存位置不是这种情况)。
接下来,启动了对我们而言无效的多个遍,然后启动了“
全局变量优化器 ”,其描述如下:
, . , , , , ..此段进行了以下更改:
他添加了一个函数属性:元数据由编译器的一部分使用,用于存储有关可能对编译器的另一部分有用的信息。 您可以
在此处阅读有关此属性的用途。
与我们考虑的其他优化不同,全局变量的优化器是过程间的;它完全看待LLVM模块。 一个模块(或多或少)等效于C和C ++中的编译单元。 与过程间优化相反,过程内一次只能看到一个功能。
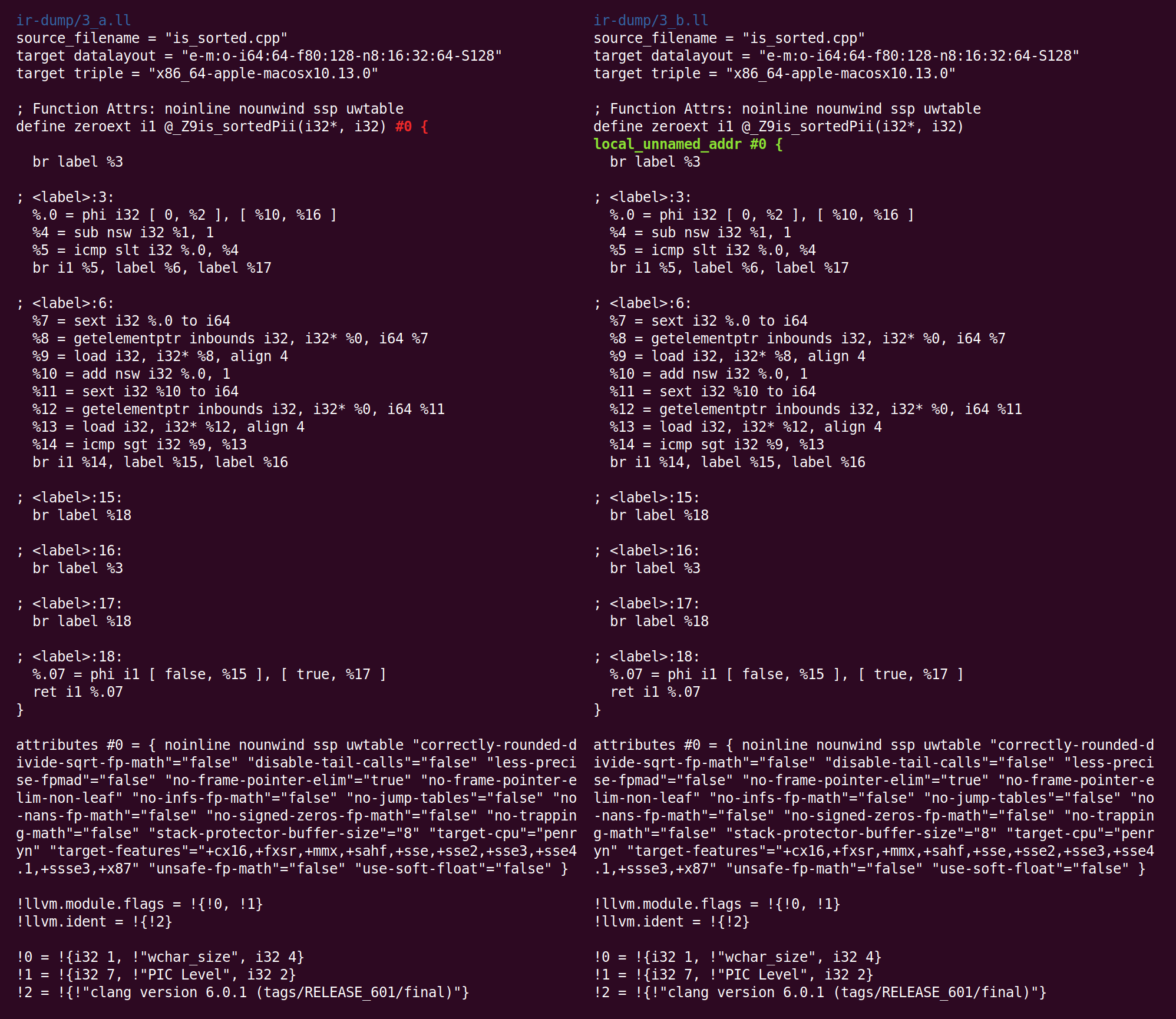
下一段结合指令,称为“
指令合并
器 ”,InstCombine。 这是
窥视孔优化的大量且多样化的集合,它们通常以更有效的形式重写一些指令,这些指令与常见数据结合在一起。 InstCombine不会更改函数的控制流。 在上面的示例中,他没有太大变化:
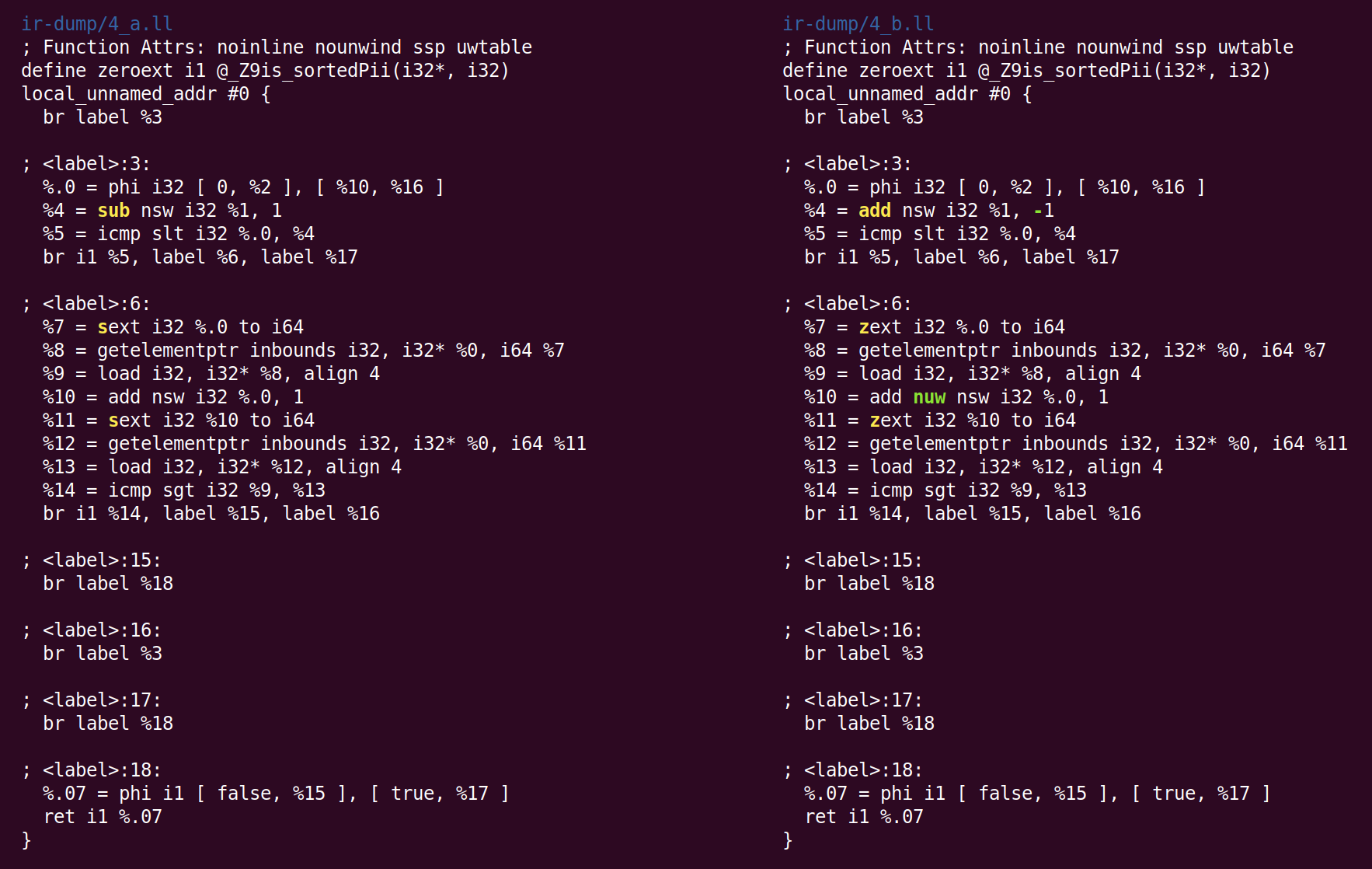
在这里,不是从%1减去1,而是为了计算%4,我们加上-1。 这不是优化,而是规范化。 当有很多方法可以进行计算时,LLVM会尝试将其转换为后续遍历和后端期望看到的规范(通常是随机选择)形式。 InstCombine所做的第二个更改是两个带符号的扩展运算(sext指令)的规范形式,这些运算将%7和%11计算为零扩展(zext)。 当编译器可以证明Sext操作数为非负数时,此转换是安全的。 在这种情况下,这是因为循环变量从0变为n(如果n为负,则循环根本不执行)。 最新的更改是在计算%10的指令中添加了“ nuw”(无符号换行)标志。 我们可以看到这是安全的,因为以下事实:(1)循环变量总是增加,而(2)如果变量从零开始并增加,则当符号在INT_MAX交集处发生变化而到达无符号溢出之前,它将变得不确定,跟随UINT_MAX。 该标志可用于后续优化。
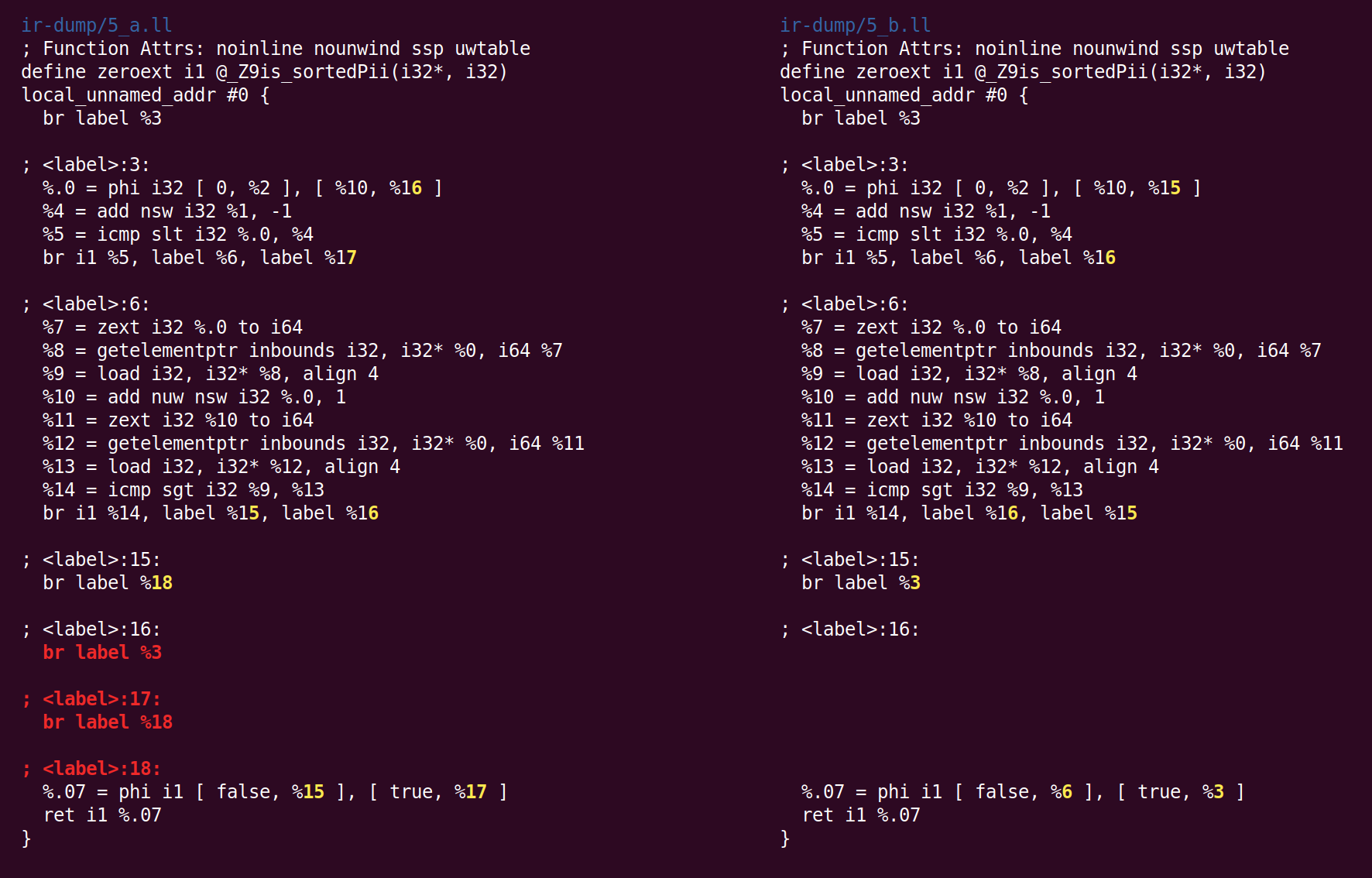
接下来,SimplifyCFG再次启动,并删除两个空的基本块:
然后,“推导函数属性”传递对函数进行注释:

“ Norecurse”表示该函数不包含在任何递归调用中,“ readonly”表示该函数不更改全局状态。 参数属性“ nocapture”表示退出该功能后未保存该参数,“只读”表示该功能未修改内存。 您可以看到
函数 属性和
参数属性的
列表 。
然后,“
rotate loops ”传递会移动代码,以尝试改善后续优化的条件:

尽管差异看起来令人生畏,但变化实际上很小。 如果我们要求LLVM在旋转周期之前和之后绘制一个控制传递图,我们可以以一种更具可读性的方式看到发生了什么。 这是他们在之前(左)和之后(右)的观点:
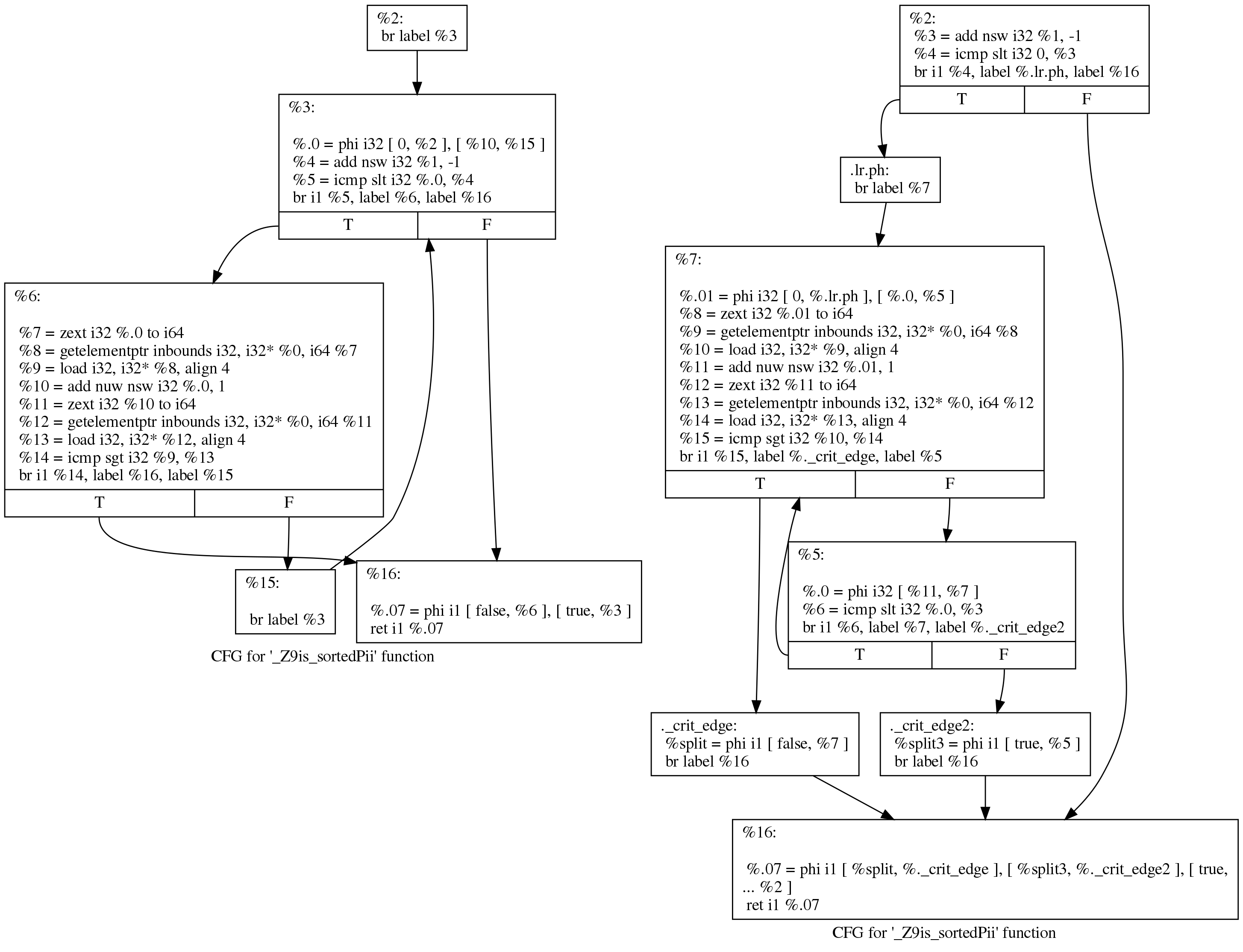
原始代码仍然遵循Clang生成的循环结构:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
运行后,循环如下所示:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(下面列出了约翰尼斯·杜弗特(Johannes Durfert)提出的更正-谢谢!)
循环旋转遍历的目的是删除一个分支,从而可以进行进一步的优化。 我在Internet上找不到这种转换的更好描述。
CFG简化过程使两个仅包含简并(单输入)phi指令的基本块最小化:

指令组合器将“%4 = 0 s <(%1-1)”转换为“%4 =%1 s> 1”(其中s <和s>是用于比较带符号操作数的操作),有用的转换,它减少了依赖链的长度,还可以创建“死的”(不可维持的)指令(请参阅执行此操作的
补丁程序 )。 此过程还删除了循环旋转过程添加的琐碎phi指令。

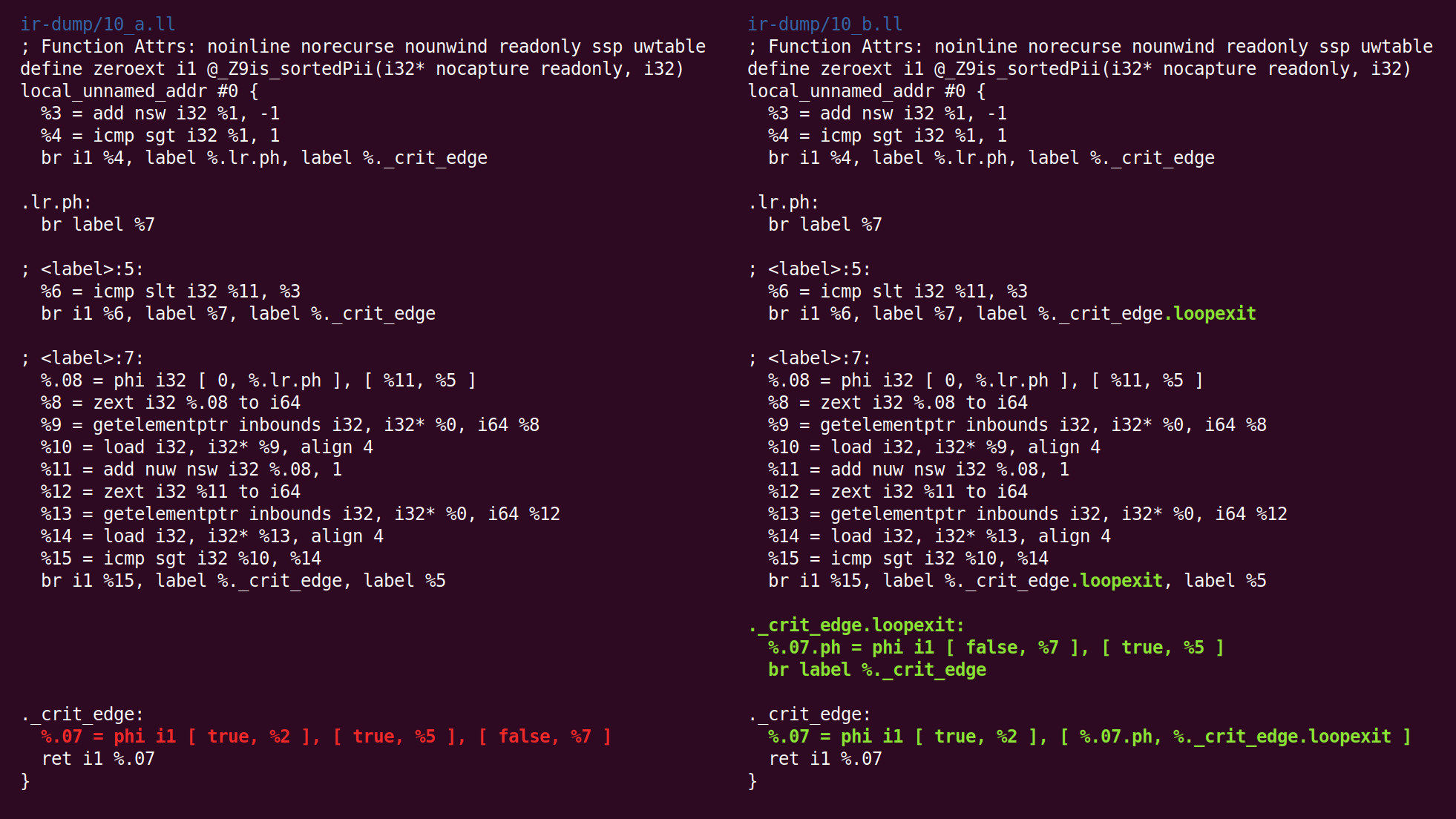
以下是“
规范化自然循环 ”段落,在其自己的源代码中对此进行了描述,如下所示:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
在这里,我们看到插入了输出块:
然后是“
简化循环变量 ”:
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
此步骤的作用是将32位循环变量更改为64位:
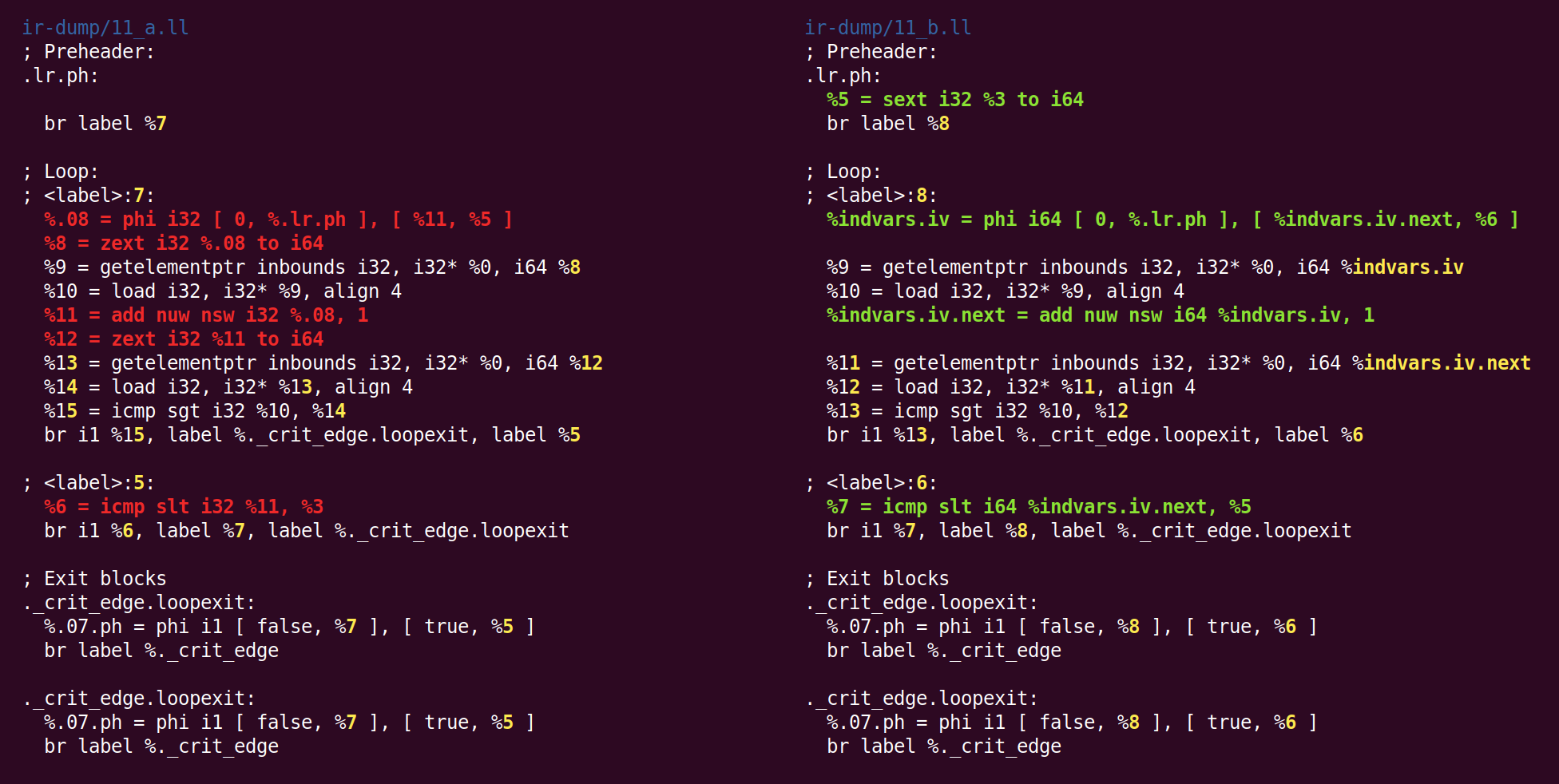
我不知道为什么zext-以前从sext转换为规范形式,然后又返回到sext。
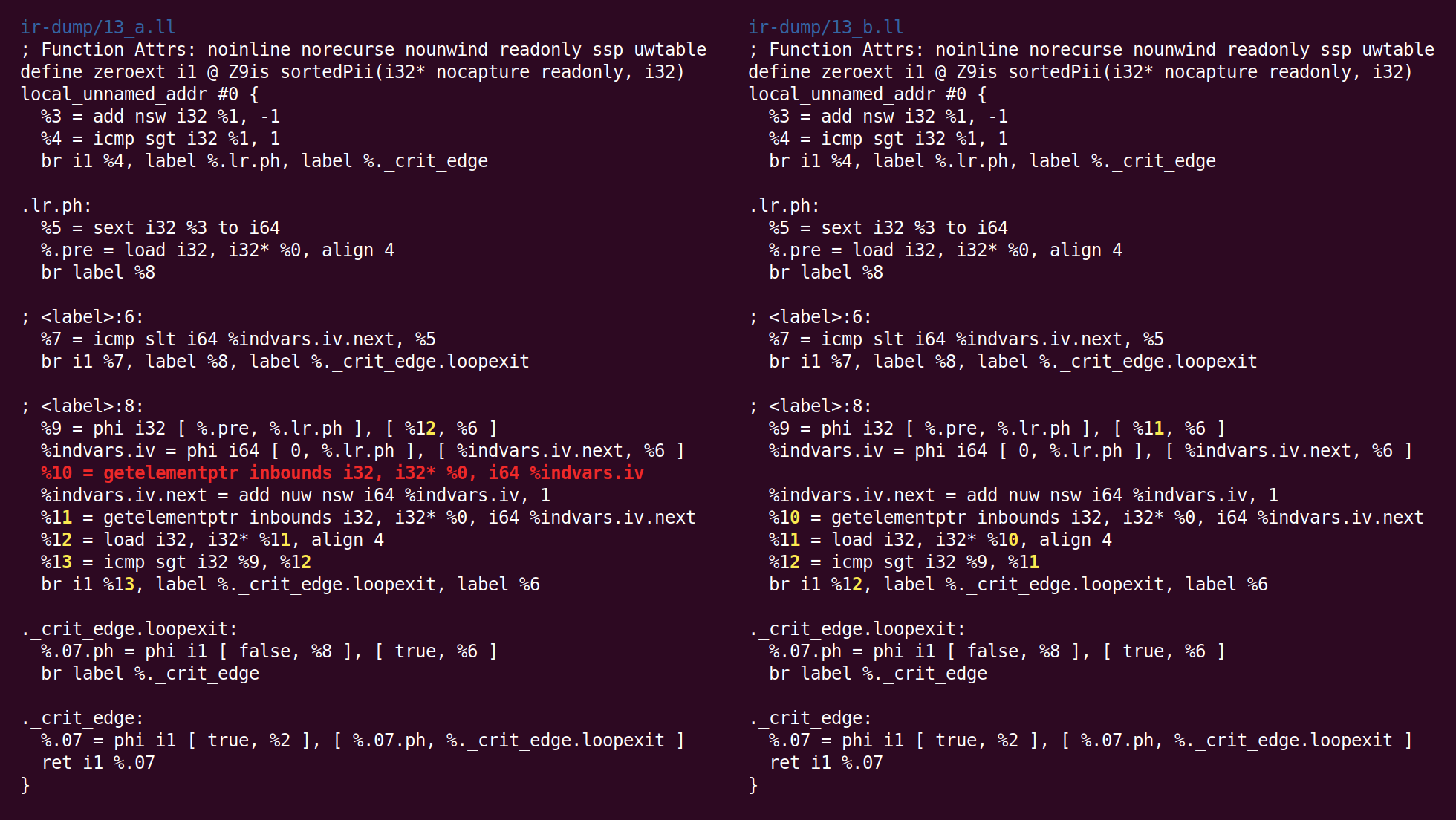
现在,“
全局值编号 ”过程正在执行非常智能的优化。 写这篇文章的原因之一是希望展示它。 你能在这里看到她吗?

看到了吗 是的,左侧循环中有两个加载指令,分别对应于[i]和[i + 1]。 在此,GVN发现不需要加载[i],因为可以将循环的一次迭代中的[i + 1]像[i]一样转移到下一次。 这个简单的技巧使该函数执行的内存读取次数减少了一半。 LLVM和
GCC都仅在最近才学会执行此转换。
如果我们将[i]与[i + 2]进行比较,您可能会问自己这个技巧是否有效。 事实证明,没有,但是对于这种情况,GCC最多可以分配
四个寄存器 。
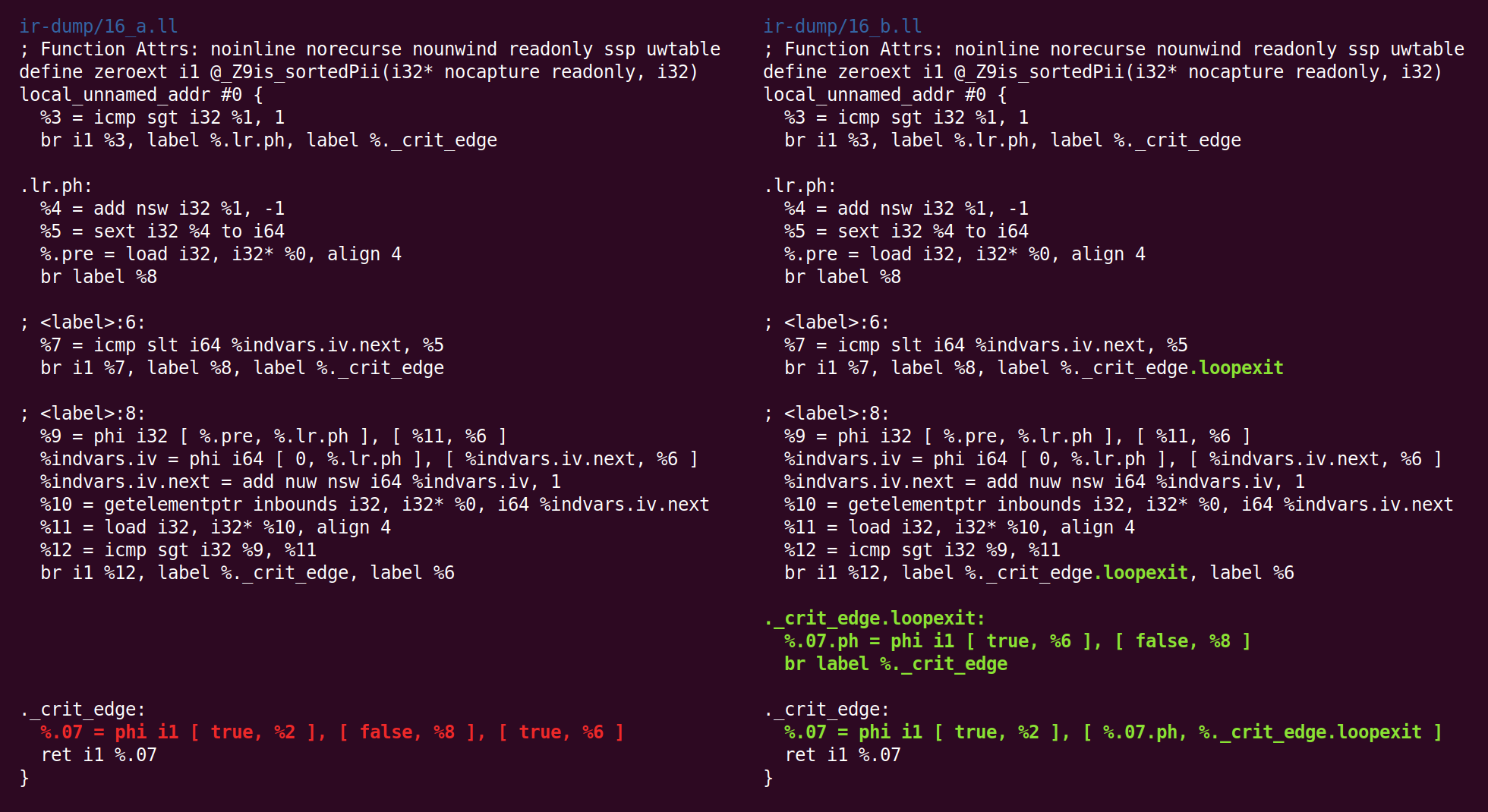
然后开始“
位跟踪无效代码消除 ”过程:
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .但是在这里事实证明并不需要这样的技巧,因为唯一的无效代码是GEP(获取元素指针)指令,而且它也非常无效(GVN传递删除了使用该指令计算的地址的加载指令):
现在,用于组合指令的算法已将add放置在另一个基本单元中。 在我看来,将此转换放置在InstCombine中的逻辑并不明确,也许没有明显的位置可以放置它:

现在发生了一些更奇怪的事情:“
跳转线程 ”传递删除了“规范化自然循环”传递之前所做的操作:

然后我们再次转换为规范形式:
CFG简化将其转换为不同的形式:
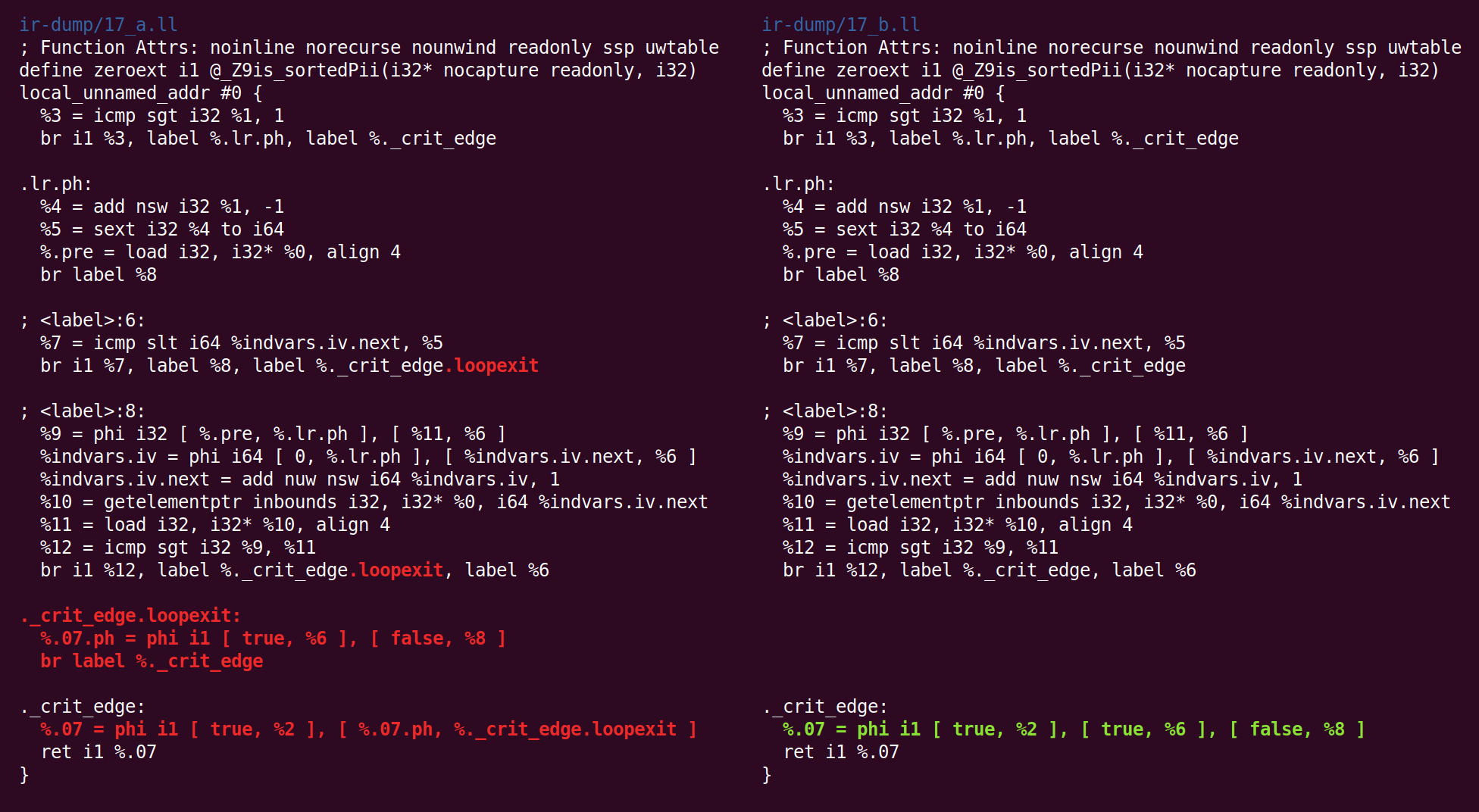
并返回:
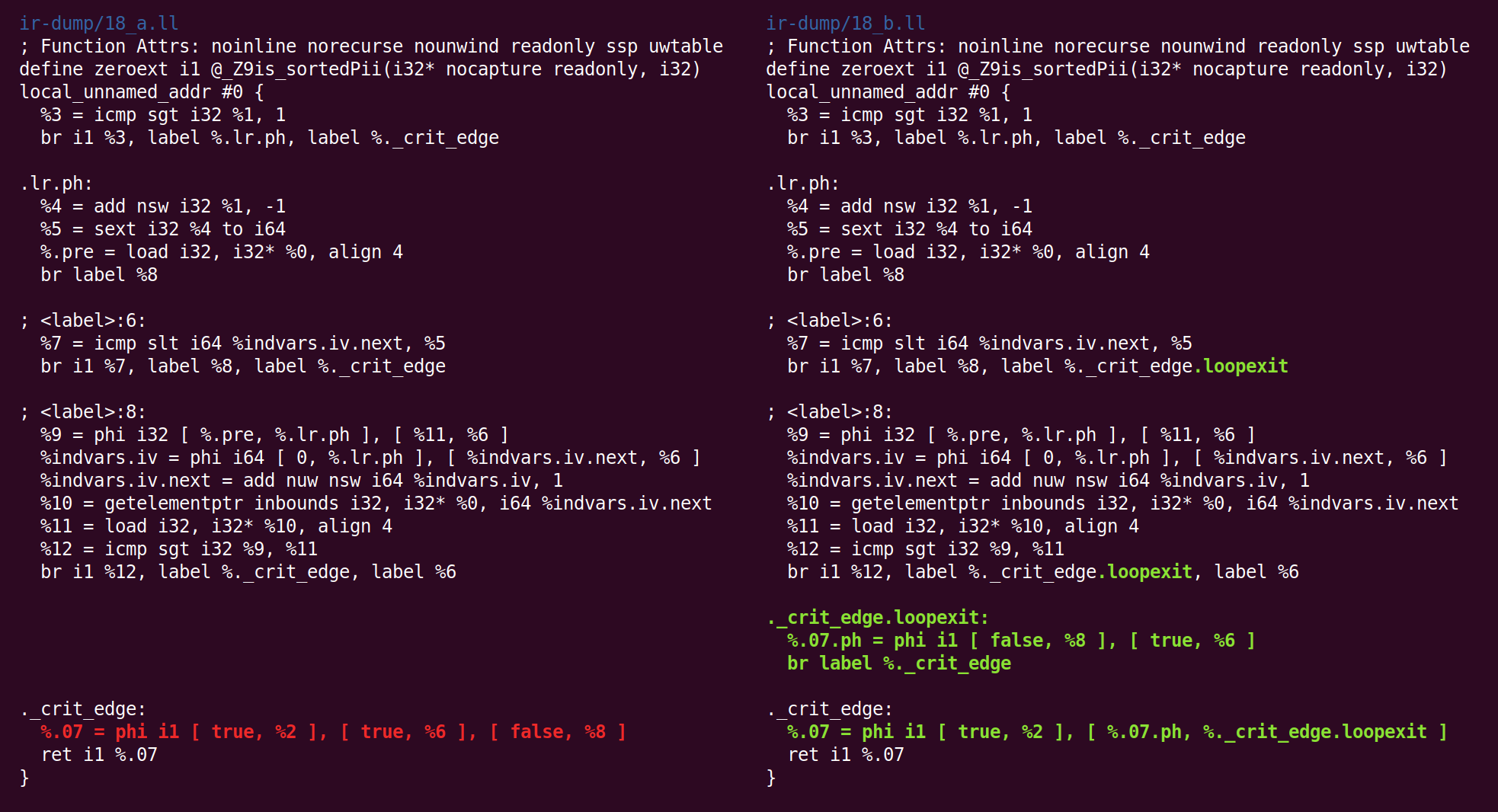
再有:

并返回:
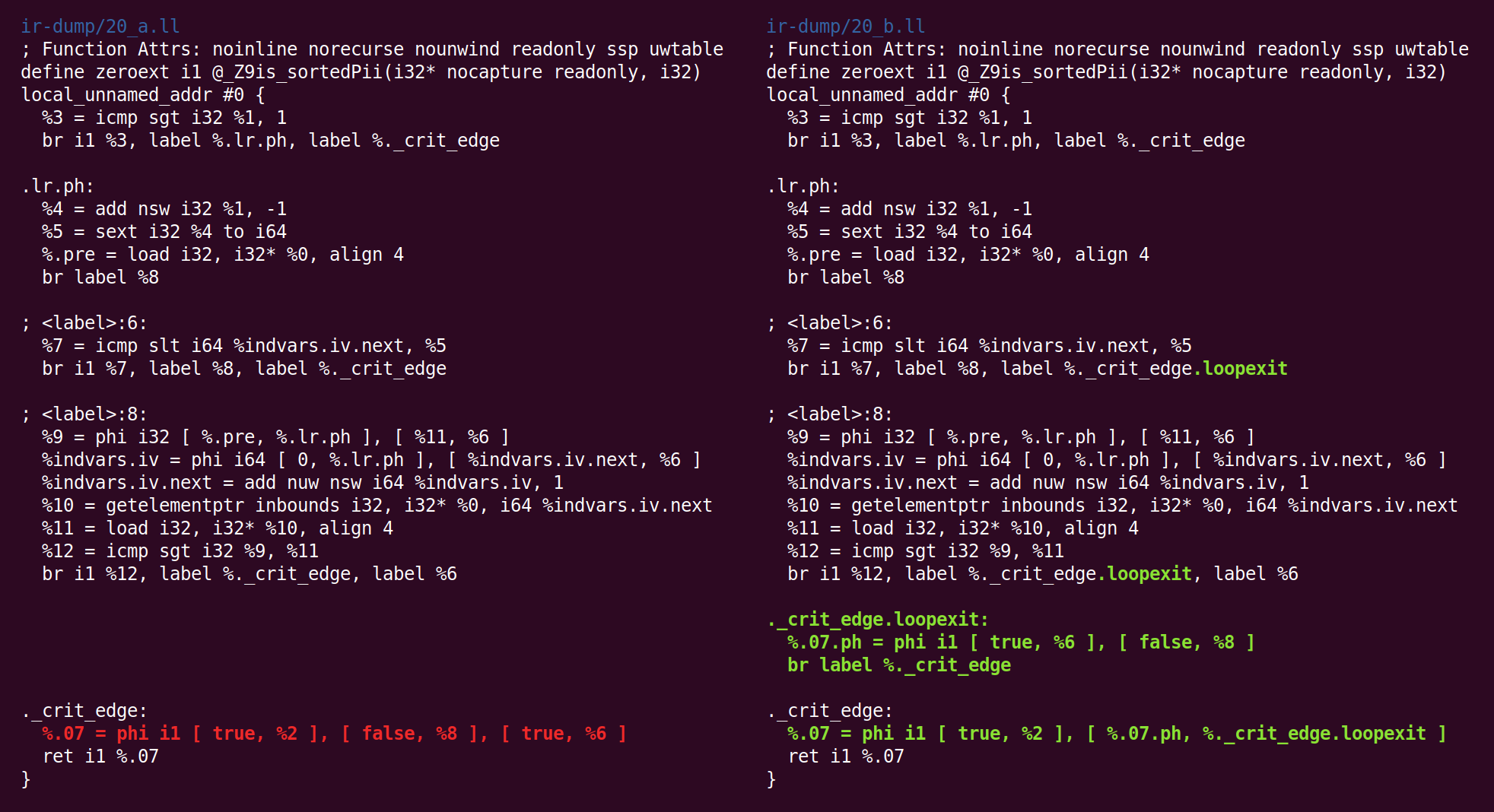
那里:

最后,我们完成了米德兰! 右边的代码是我们将(在我们的情况下)传递给x86-64后端的代码。
您可能很好奇,如果流水线末端的行为波动是由编译器错误引起的,但是让我们考虑到此函数非常非常简单,并且处理过程涉及很多过程,但是我什至没有提到它们,因为它们没有对代码进行任何更改。 在优化流程的后半部分,我们主要观察该函数的退化情况。
致谢:今年秋天,在我深入的编译器课程中,一些学生对这篇文章的草稿留下了反馈(我也将这些材料用于家庭作业)。 我在
这套关于循环优化的精彩讲座中介绍了此处讨论的功能。