 译者:
译者:今天,我们为您
出版由三位开发人员Akaash Chikarmane,Erte Bablu和Nikhil Gaur撰写的联合文章,其中介绍了预测Google Play商店中应用程序评级的方法。
在本文中,我们将展示如何处理用于预测收视率的信息。 我们还将解释为什么我们使用这些或这些。 我们将讨论我们使用的数据包的转换以及使用可视化可以实现的内容。
Skillbox建议:两年实践课程“我是PRO Web开发人员” 。
我们提醒您: 对于所有“哈勃”读者来说,使用“哈勃”促销代码注册任何Skillbox课程时均可享受10,000卢布的折扣。
为什么我们决定这样做
长期以来,移动应用程序已成为生活中不可或缺的一部分,越来越多的开发人员独自从事其创作。 而且,许多直接取决于申请带来的收入。 因此,预测成功对他们来说非常重要。
我们的目标是确定应用程序的总体评分,以进行全面评估,因为太多的人仅根据用户设置的“星级”来判断该程序。 4-5分的应用程序更可信。
准备工作
该项目的大部分内容都在处理数据,包括预处理。 由于所有信息均来自Google Play商店,因此生成的数组包含很多错误。 我们使用了几种回归模型,包括来自XGBoost软件包的Gradient-Boosting回归器,线性回归和RidgeRegression。
数据收集与分析
我们使用的数据集可以在
这里找到 。 它由两部分组成。 第一个是客观的信息,例如应用程序的大小,安装数量,类别,评论的数量,应用程序的类型,类型,上次更新的日期等,并且是主观的,即用户评论。
评论本身进行了分析。 比较结果之后,我们决定是否在最终模型中包括调查数据。
我们通过12个函数和一个目标变量(等级)形成了一个客观数据集。 该软件包包括1.08万个信息单元。 在用户评论方面,我们选择了100个最相关的功能,并使用了五个功能处理了6.43万个元素。 所有数据都是直接从Google Play商店收集的,这是三个月前的最后一次更新。
数据预处理
最初的信息集看起来像这样:
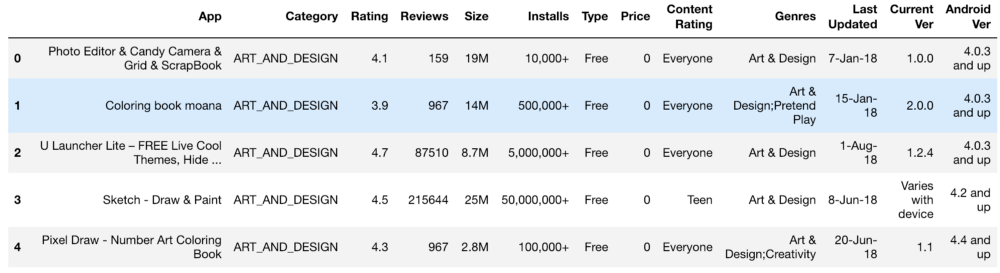
设置,等级,成本和尺寸-我们以一种获取机器理解的数字的方式来处理所有这些。 在处理各种功能时,出现了一些问题,例如需要删除“ +”。 在成本中,我们删除了$。 由于遇到了KB和MB的问题,因此在处理方面,应用程序的数量是最大的问题,因此有必要做一些工作以将所有内容缩减为一种格式。 主要数据如下所示,它们也在处理之后。
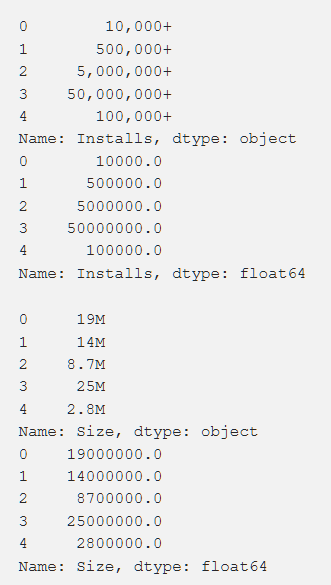
此外,我们转换了一些数据,使其与我们的工作更加相关。 例如,有关最新应用程序更新的信息不是很有用。 为了使它们更有意义,我们将其转换为有关自上次更新以来经过的时间的信息。 该任务的代码如下所示。
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
还必须将具有多个不同值的单个标准变量(例如“流派”)带入。 如下所示。
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
为了规范化数据,我们尝试了log1p转换。 在他之前:
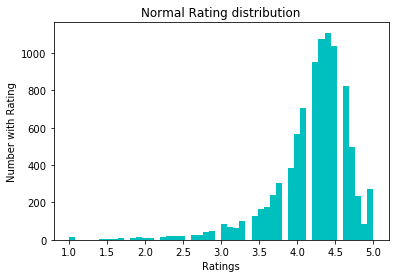
之后:
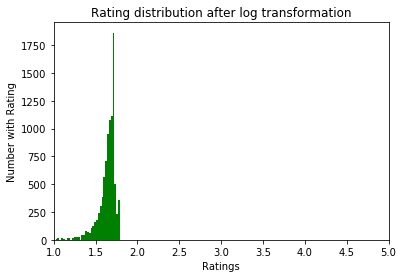
数据探索
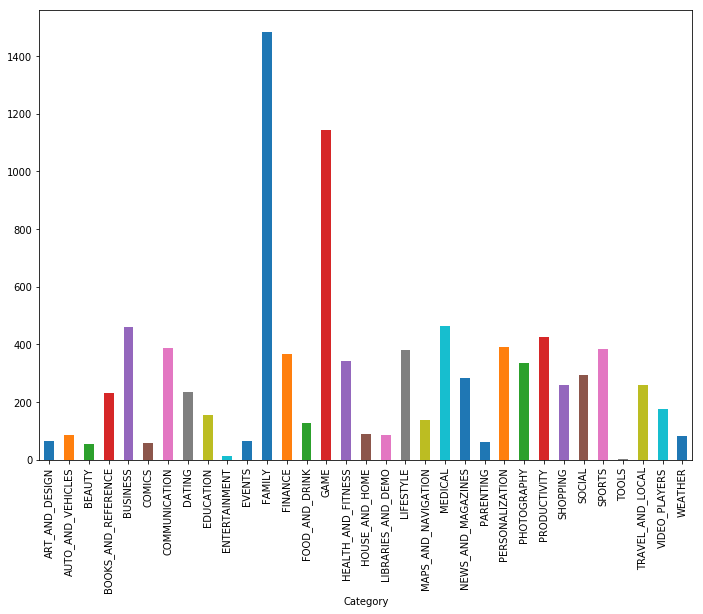
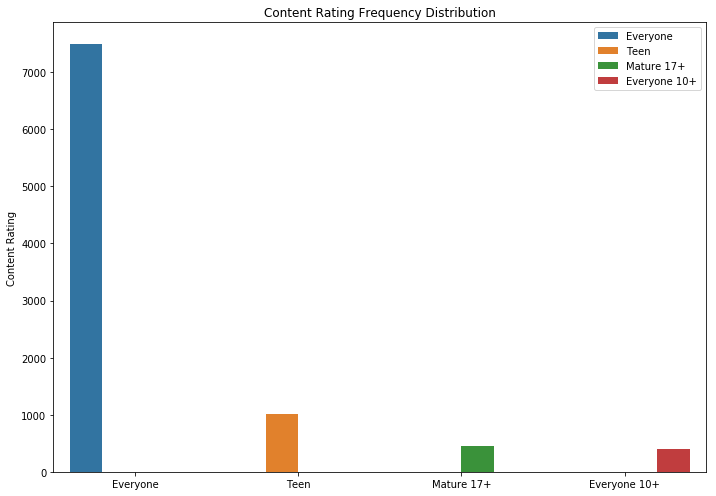
如您所见,家庭游戏和应用程序是两个最受欢迎的类别。 大多数应用程序也属于“所有年龄段”类别。

逻辑上,具有最高评分的应用程序具有比低评分的应用程序更多的评论。 他们中有些人的评论比其他人都多。 造成这种情况的原因可能是弹出消息,致电进行评分或其他类似技术。

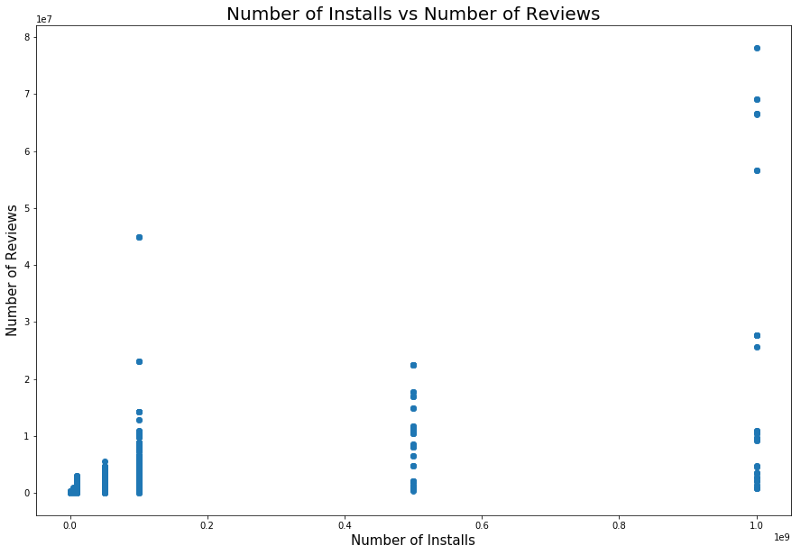
安装数量和评论数量之间也存在关系。 相关性显示在下面的屏幕快照中。
对这种依赖性的详细分析可以使您理解为什么流行的应用程序类别具有更多的安装和更多的评论。
模型与结果
我们使用测试拆分将数据分为测试集和训练集。 使用GridSearchCV的交叉验证来改善模型训练结果,以便从XGBoost包中找到带有Lasso,Ridge回归和XGBRegressor的最佳alpha。 后一种模型通常非常有效,但使用它时,必须提防调整结果-这是等待研究人员注意的危险之一。 初始rms值约为0.228,无需对对象进行任何特别仔细的处理(仅限编码和清洁)。
在对数值进行对数转换后,标准误降至0.219,这是一个轻微的改进,但是我们意识到我们做得很好。
在评估评论,态度和评分之间的关系后,我们使用了线性回归。 特别是,我们分析了这些变量的统计信息,包括r平方和p,从而决定了线性回归的结果。 使用的第一个线性回归模型显示了设置与等级0.2233之间的相关性,线性回归模型“我们的评论和评分”为我们提供了0.2107的MSE,以及组合的线性回归模型,“评论”,“设置”和“评分” ”,MSE为0.214。
另外,我们使用了KNeighborsRegressor模型。 其使用结果如下所示。

结论
将Google Play商店中的原始数据转换为可用格式后,我们绘制并导出了函数以了解各个值之间的相关性。 然后将这些结果用于建立最佳模型。
最初,我们认为找到它并不难,因此我们可以建立一个准确的模型。 但是任务比我们预期的要困难。
除了已完成的操作之外,您还可以:
- 为每种类型创建一个单独的模型;
- 像我们以前对日期所做的那样,从Android OS版本创建新功能;
- 为了更深入地学习算法-我们有足够数量的分类和数值数据点;
- 独立地解析和清除Google App Store中的数据。
所有结果
都可在此处获得 。
Skillbox建议: