英特尔下诺夫哥罗德办事处正在开发基于深度神经网络的计算机视觉算法。 我们的许多算法都发布在
Open Model Zoo存储库中。 模型训练需要大量的标记数据。 从理论上讲,有许多准备方法,但是专用软件的可用性使该过程加速了很多倍。 因此,为了提高标记的效率和质量,我们开发了自己的工具-
计算机视觉注释工具(CVAT) 。
当然,在Internet上可以找到很多带批注的数据,但是存在一些问题。 例如,不断出现新任务,而根本没有此类数据。 另一个问题是,由于其许可协议,并非所有数据都适合用于商业产品的开发。 因此,除了开发和训练算法外,我们的活动还包括数据标记。 这是一个相当漫长且耗时的过程,将其置于开发人员的肩膀上是不合理的。 例如,为了训练我们的一种算法,在3,100多个工时中标记了大约769,000个对象。
有两种解决方案:
- 首先是通过适当的专业化将标记数据传输给第三方公司。 我们也有类似的经历。 值得注意的是,复杂的数据验证和重新分区过程以及官僚主义的存在。
- 第二个对我们来说更方便的是我们自己的注释团队的创建和支持。 便利性在于能够快速设置新任务,管理其执行进度以及促进价格与质量之间的平衡的能力。 另外,可以实现定制的自动化算法并提高标记质量。
最初,计算机视觉注释工具是专门为我们的注释团队开发的。

当然,我们的目标不是创建“第15条标准”。 最初,我们使用了现成的解决方案
-Vatic ,但是在此过程中,注释和算法团队提出了新要求,最终实现了程序代码的完全重写。
在文章中进一步:
- 常规信息(功能,应用,工具的优缺点)
- 历史和演变(关于CVAT如何生活和发展的简短故事)
- 内部设备(高级体系结构描述)
- 发展方向(有关我想实现的目标以及实现这些目标的可能方式的一些信息)
一般资讯
计算机视觉注释工具 (CVAT)是用于标记数字图像和视频的开源工具。 它的主要任务是为用户提供方便有效的标记数据集的方法。 我们将CVAT创建为一种通用服务,它支持不同类型和格式的标记。
对于最终用户,CVAT是基于浏览器的Web应用程序。 它支持各种工作场景,可用于个人和团队工作。 在图像处理领域与老师进行机器学习的主要任务可以分为三组:
CVAT适用于所有这些情况。
优点:- 最终用户缺乏安装。 要创建任务或标记数据,只需在浏览器中打开特定链接。
- 一起工作的能力。 有机会将任务公开提供给用户并并行处理它。
- 易于部署。 通过使用Docker在本地网络上安装CVAT是几个命令。
- 标记过程的自动化。 例如,插值法允许您在许多帧上进行标记,而实际工作仅在某些关键帧上进行。
- 专业经验。 该工具是在注释和多个算法团队的参与下开发的。
- 整合能力。 CVAT适合集成到更广泛的平台中。 例如, Onepanel 。
- 对各种工具的可选支持:
- 深度学习部署工具包(作为OpenVINO的一部分)
- Tensorflow对象检测API(TF OD API)
- ELK(Elasticsearch + Logstash + Kibana)分析系统
- NVIDIA CUDA工具包
- 支持各种注释方案。
- 根据简单和免费的MIT许可开放源代码。
缺点:- 有限的浏览器支持。 仅在Google Chrome浏览器中才能保证客户端部分的性能。 我们不会在其他浏览器中测试CVAT,但是从理论上讲,该工具可以在Opera,Yandex浏览器和其他Chromium引擎中使用。
- 尚未开发自动测试系统。 所有运行状况检查都是手动执行的,这大大减慢了开发速度。 但是,我们已经在与UNN的学生一起努力解决此问题。 Lobachevsky作为IT实验室项目的一部分。
- 没有可用的源代码文档。 参与开发可能非常困难。
- 性能限制。 随着对标记量的需求不断增加,我们面临各种问题,例如Chrome沙盒在RAM使用方面的限制。
当然,这些列表并不详尽,但包含基本规定。
如前所述,CVAT支持许多其他组件。 其中包括:
深度学习部署工具包是
OpenVINO工具 包的一部分,用于在没有GPU的情况下加快TF OD API模型的启动。 我们正在为该组件开发其他两个有用的用途。
Tensorflow对象检测API-用于自动标记对象。 默认情况下,我们使用在
COCO (80类)上训练的Faster RCNN Inception Resnet V2模型,但是连接其他模型应该没有任何困难。
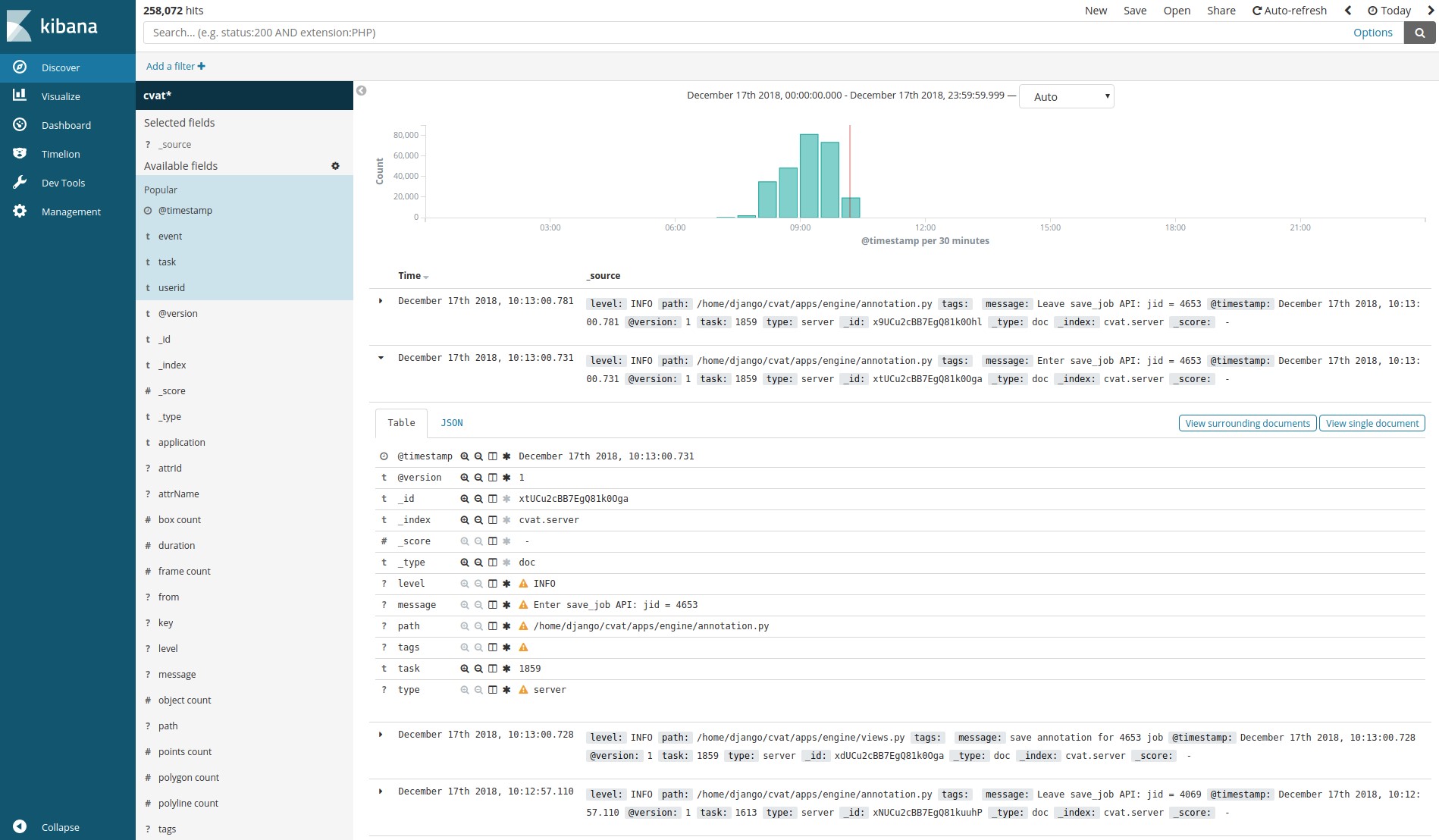
Logstash,Elasticsearch,Kibana-使您可以可视化和分析客户积累的日志。 例如,这可用于监视标记过程或搜索错误及其发生原因。
 NVIDIA CUDA Toolkit-
NVIDIA CUDA Toolkit-一组用于在图形处理器(GPU)上执行计算的工具。 可以使用TF OD API或其他自定义加载项来加快自动布局。
数据标记
- 该过程开始于布局问题的陈述。 阶段包括:
- 指定任务名称
- 枚举要标记的类及其属性
- 指定要下载的文件
- 数据是从本地文件系统或安装在容器中的分布式文件系统下载的
- 通过分布式存储下载任务时,一个任务可以包含一个包含图像的存档,一个视频,一组图像,甚至是包含图像的目录结构
- 可以选择设置:
- 链接到详细的标记规范以及任何其他附加信息(错误跟踪器)
- 链接到用于存储注释的远程Git存储库(数据集存储库)
- 将所有图像旋转180度(翻转图像)
- 分段任务的层支持(Z顺序)
- 段大小 可下载的任务可以分为几个子任务以并行工作
- 线段相交区域(重叠)。 用于视频中以合并不同段中的注释
- 转换图像时的质量等级(图像质量)
- 处理请求后,创建的任务将出现在任务列表中。

- “作业”部分中的每个链接都对应一个段。 在这种情况下,该任务先前未分段。 单击任何链接可打开标记页面。

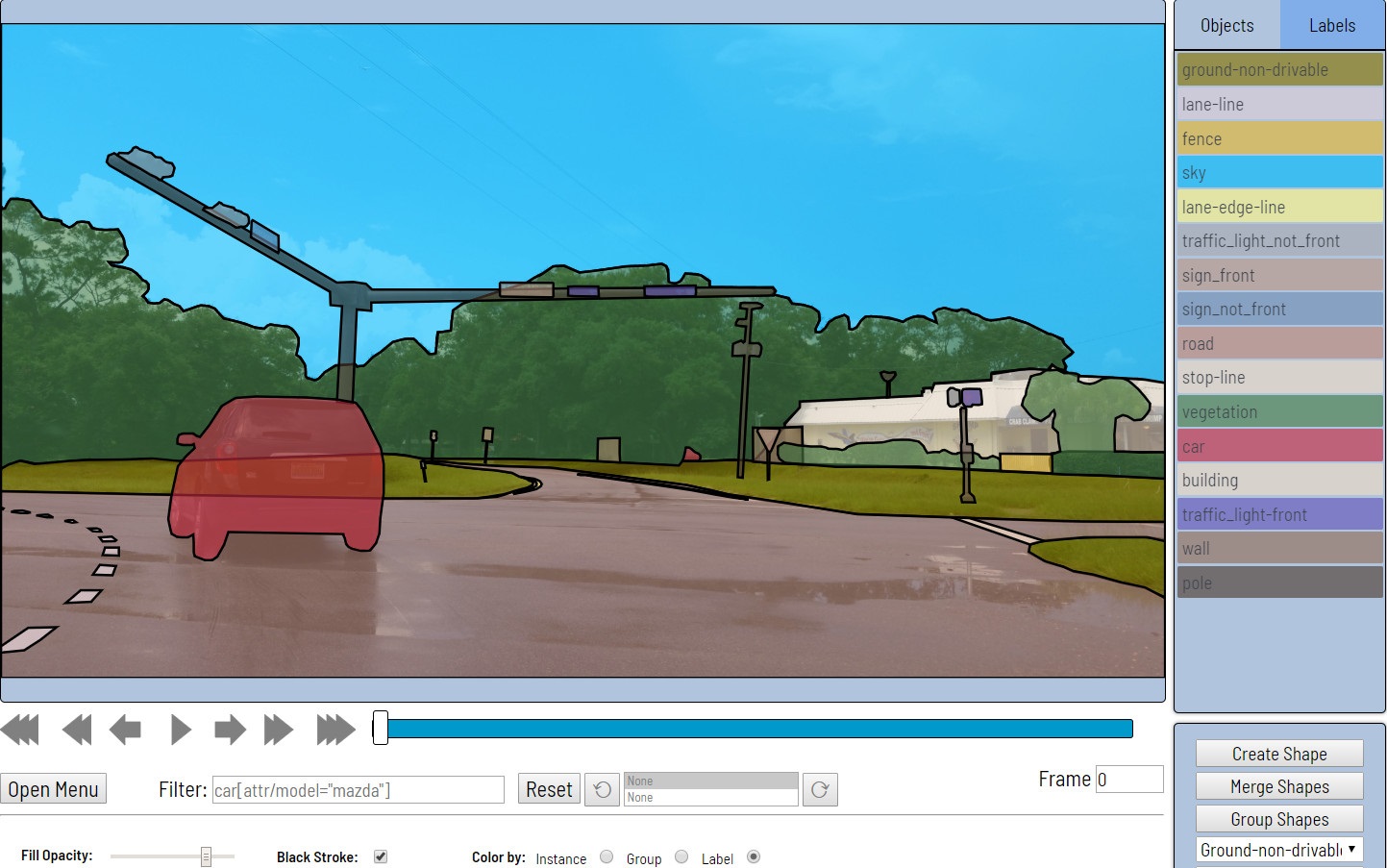
- 接下来,直接标记数据。 提供了矩形,多边形(主要用于分割任务),折线(例如对于道路标记可能有用)和许多点(例如,标记人脸地标或姿势估计)作为图元。
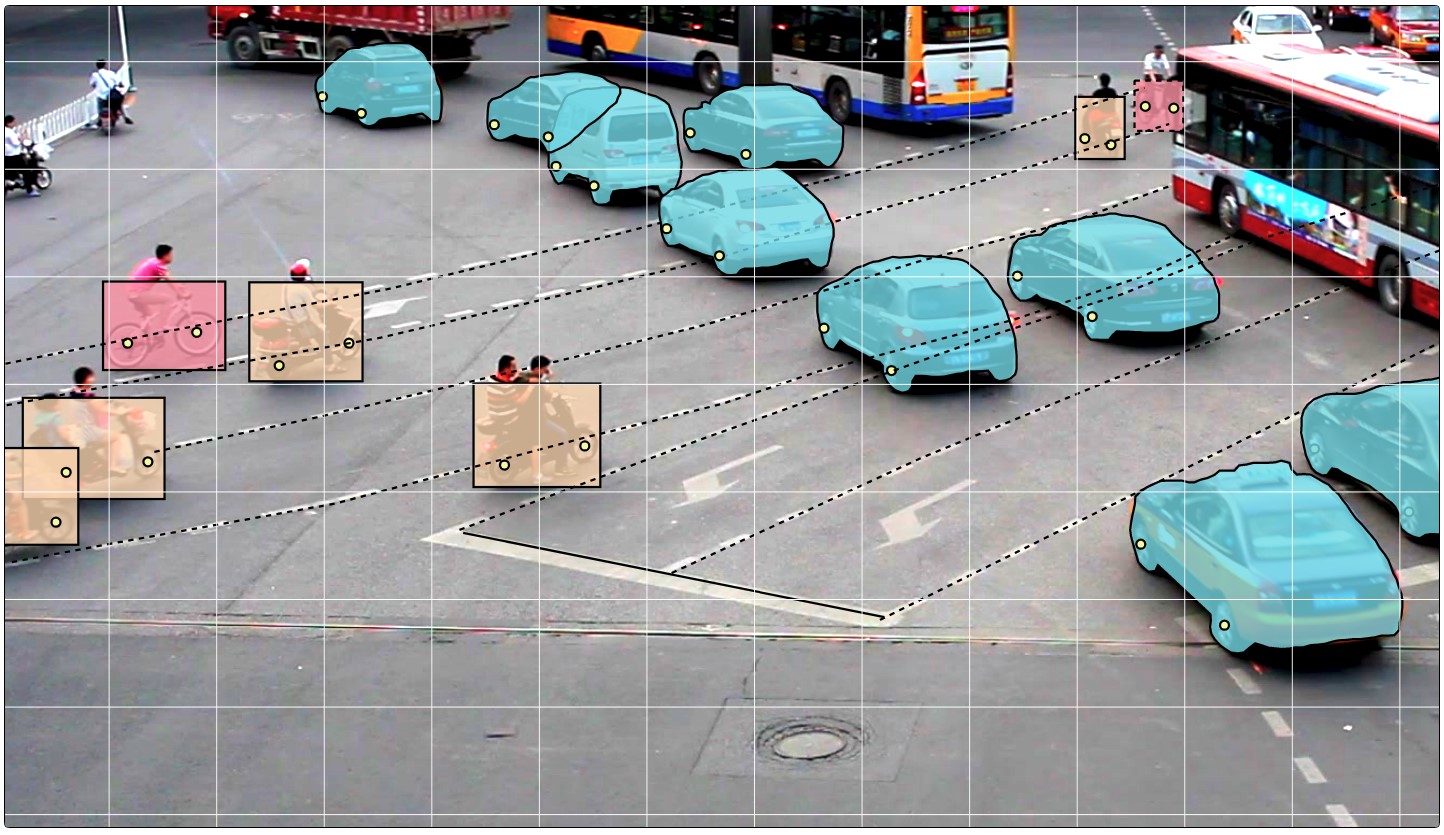
还提供了各种自动化工具(复制,与其他帧相乘,插值,使用TF OD API进行初步标记),视觉设置,许多热键,搜索,过滤和其他有用的功能。 在设置窗口中,您可以更改许多参数,以使工作更舒适。
帮助对话框包含许多受支持的键盘快捷键和其他提示。

在下面的示例中可以看到标记过程。
CVAT可以在视频的关键帧之间线性插入矩形和属性。 因此,将自动显示框架集上的注释。
对于分类方案,开发了“属性注释模式”,它允许您通过将标记集中在一个特定属性上来快速注释属性。 此外,此处的标记是通过使用“热键”进行的。
多边形支持语义分割和实例分割脚本。 不同的视觉设置有助于验证过程。
- 接收注释
按下“转储注释”按钮将启动准备和加载标记结果为单个文件的过程。 注释文件是指定的.xml文件,其中包含一些任务元数据和整个注释。 如果标记是在任务创建阶段连接的,则可以将标记直接下载到Git存储库。
历史与演变
最初,我们没有任何统一,每个标记任务都是使用自己的工具执行的,这些工具主要是使用
OpenCV库以C ++编写的。 这些工具是本地安装在最终用户计算机上的,没有共享数据的机制,用于设置和标记任务的通用管道,许多事情必须手动完成。
CVAT历史的起点可以被认为是2016年底,当时将
Vatic作为布局工具推出,其界面如下所示。 Vatic是开源的,并介绍了一些很棒的通用思想,例如在视频或客户端服务器应用程序体系结构的关键帧之间插入标记。 但是,总的来说,它提供了相当适度的标记功能,我们自己做了大量工作。
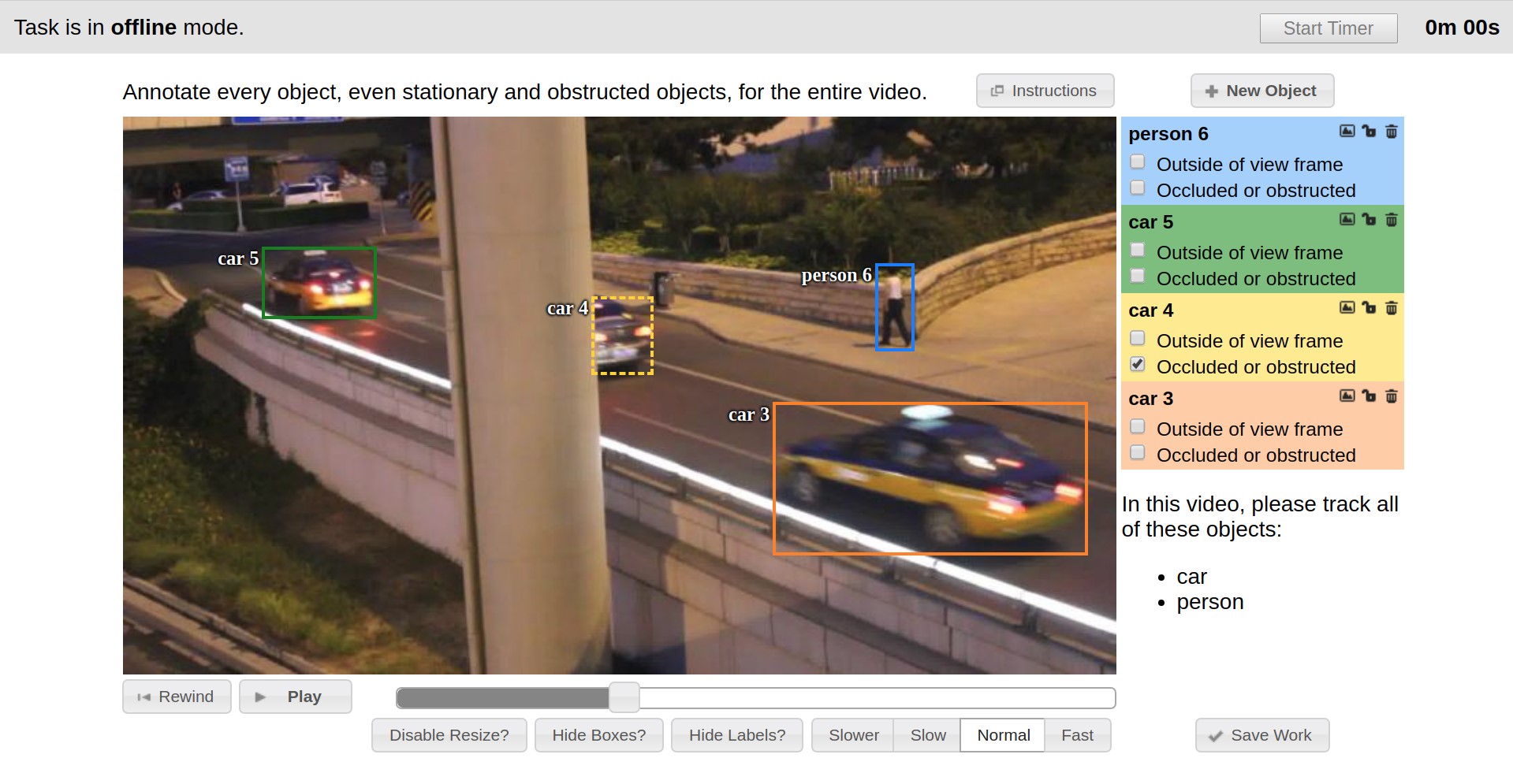
因此,例如,在最初的六个月中,实现了对图像进行注释的功能,添加了对象的用户属性,开发了包含现有任务列表的页面以及可以通过Web界面添加新任务的功能。
在2017年下半年,我们引入了Tensorflow对象检测API作为获取初步标记的方法。 客户有许多小的改进,但最终我们遇到了一个事实,即客户部分开始工作非常缓慢。 事实是,任务的大小增加了,任务的打开时间与框架和标记数据的数量成比例地增加了,由于标记对象的显示效率低下,UI变慢了,进度通常会在工作时间中丢失。 由于当时的体系结构最初是设计用于视频的,因此生产力主要集中在图像任务上。 我们需要成功应对客户端体系结构的彻底变化。 当时大多数性能问题都消失了。 Web界面变得更快,更稳定。 标记更大的任务已经成为可能。 在同一时期,尝试引入单元测试以在某种程度上提供变更期间检查的自动化。 这项任务尚未成功解决。 我们在Docker容器中配置了QUnit,Karma,Headless Chrome,编写了一些测试,并在CI上启动了所有这些功能。 但是,测试仍未发现很大一部分代码。 另一个创新是基于ELK Stack的用户操作记录系统,随后进行搜索和可视化。 它使您可以监视注释器的过程,并查找导致软件异常的操作方案。
在2018年上半年,我们扩展了客户端功能。 添加了“属性注释模式”,该模式实现了一个有效的脚本来标记属性,我们从同事那里借鉴并推广了这种思想 现在,您可以根据许多符号过滤对象,连接公共存储器以在设置任务时下载数据,并通过浏览器进行查看,等等。 任务变得越来越繁琐,性能问题又开始出现,但是这次服务器部分成为了瓶颈。 Vatic的问题在于,它包含许多用于任务的自行编写的代码,这些代码可以使用现成的解决方案更轻松,更有效地解决。 因此,我们决定重做服务器端。 我们选择Django作为服务器框架,主要是因为Django的流行以及开箱即用的许多功能。 在更改服务器部分之后,当Vatic几乎一无所有时,我们认为我们已经做了很多工作,可以与社区共享。 因此,决定开源。 在大型公司内部获得此许可是一个相当棘手的过程。 有很多要求。 包括,有必要提出一个名字。 我们草拟了方案,并在同事之间进行了一系列调查。 结果,我们的内部工具名为CVAT,并且在MIT许可下,源代码在2018年6月29日
在OpenCV组织的GitHub上发布,初始版本为0.1.0。 在公共存储库中进行了进一步的开发。
在2018年9月,主要版本0.2.0已发布。 有许多小的更改和修复,但主要重点是支持新型注释。 因此,出现了许多用于标记和验证分割的工具,以及使用折线或点进行注释的功能。
下一个版本就像圣诞节礼物一样,计划于2018年12月31日发布。 这里最重要的一点是作为OpenVINO的一部分的Deep Learning Deployment Toolkit的可选集成,该集成可用于在没有NVIDIA显卡的情况下加快TF OD API的启动; 用户日志分析系统,以前在公共版本中不可用; 客户端方面的许多改进。
我们总结了迄今为止(2018年12月)的CVAT历史并回顾了最重要的事件。 您始终可以在
changelog中阅读有关更改历史记录的更多信息。
内部装置
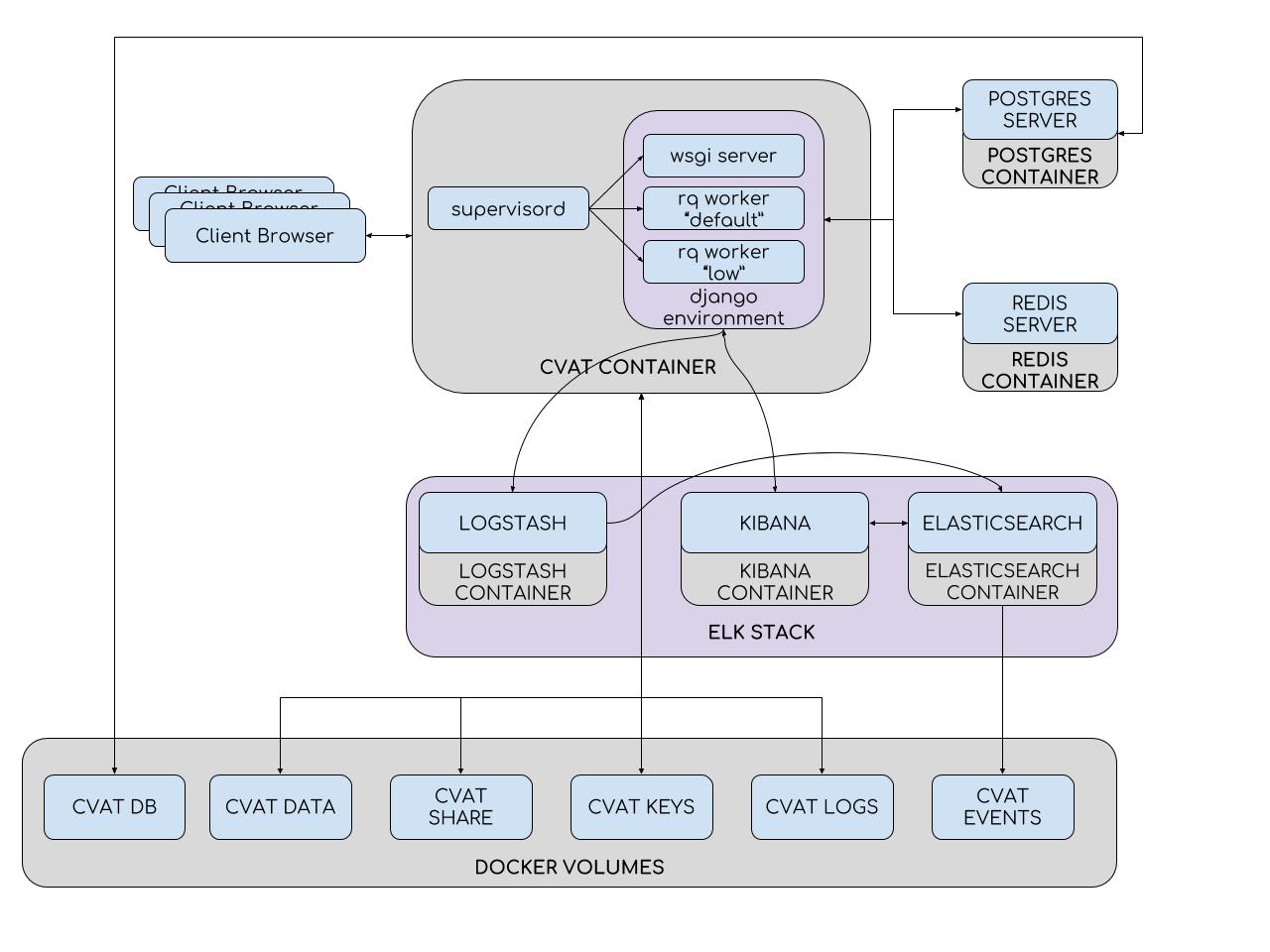
为了简化安装和部署,CVAT使用Docker容器。 该系统由几个容器组成。 一个受监管的进程在CVAT容器中执行,该容器在Django环境中产生了多个Python进程。 其中之一是wsgi服务器,它处理客户端请求。 其他进程,即rq worker,用于处理Redis队列中的“长”任务:默认和低。 这些任务包括无法在单个用户请求中处理的任务(设置任务,准备注释文件,使用TF OD API进行标记等)。 可以在受监管的配置文件中配置工作程序的数量。
Django环境与两个数据库服务器进行交互。 Redis服务器存储任务队列的状态,而CVAT数据库包含有关任务,用户,注释等的所有信息。 PostgreSQL(和正在开发的SQLite 3)用作CVAT的DBMS。 所有数据都存储在可插入分区(cvat db卷)上。 在更新容器时需要避免数据丢失的地方使用节。 因此,以下内容安装在CVAT容器中:
- 包含视频和图像的部分(cvat数据量)
- 带键部分(键盘键音量)
- 带有日志的部分(cvat日志量)
- 共享文件存储(cvat共享卷)
分析系统由包装在Docker容器中的Elasticsearch,Logstash和Kibana组成。 在客户端上保存工作时,所有数据(包括日志)都将传输到服务器。 然后,服务器将它们发送到Logstash进行过滤。 此外,还可以在发生任何错误时自动将通知发送到电子邮件。 接下来,日志进入Elasticsearch。 后者将它们保存在可插入分区(cvat事件卷)上。 然后,用户可以使用Kibana界面查看统计信息和日志。 同时,Kibana将积极与Elasticsearch互动。
在源代码级别,CVAT由许多Django应用程序组成:
- 身份验证-系统中用户的身份验证(基本和LDAP)
- 引擎-关键应用程序(基本数据库模型;加载和保存任务;加载和卸载注释;标记客户端界面;用于创建,更改和删除任务的服务器界面)
- 仪表板-用于创建,编辑,搜索和删除任务的客户端界面
- 文档-在客户端界面中显示用户文档
- tf_annotation-使用Tensorflow对象检测API的自动注释
- log_viewer-保存任务时将日志从客户端发送到Logstash
- log_proxy-CVAT代理连接→Kibana
- git-用于存储注释的Git存储库集成
我们努力创建一个结构灵活的项目。 因此,可选应用程序没有硬代码嵌入。 不幸的是,虽然我们没有理想的插件系统原型,但是随着新应用程序的开发,这种情况正在逐步改善。
客户端部分是在JavaScript和Django模板上实现的。 JavaScript , , - ( ) model-view-controller. , (, , ) , . ( - UI), (, , : , , models, views controllers).
open source, . , . . , CVAT. , , . :
- CVAT , , , , . UI .
- . , .
- , . , .
- . deep learning , . , Deep Learning Deployment Toolkit OpenVINO - . , . , .
- demo- CVAT, , , . demo- Onepanel, CVAT .
- Amazon Mechanical Turk CVAT . SDK .
, . , , . open source . – , .
, PR . , ,
Gitter . , ! !
参考文献