
在过去的文章中,我试图谈论定价的基础知识并为经典零售建立客户决策树 。 在本文中,我将向您介绍一个非常不标准的情况,并尝试说服您使用机器学习并不像看起来那样困难。 本文的技术性较差,更有可能表明您可以从小做起,这已经为企业带来了实实在在的好处。
最初的问题
例如,在我们的大陆上,有一家连锁店每周都会更改其商品种类,例如,首先出售包包 ,然后再出售男士运动服。 所有未售出的货物都被送到仓库,六个月后又再次回到商店。 同时,商店有大约6种不同类别的商品。 即 每周的商店分类如下:
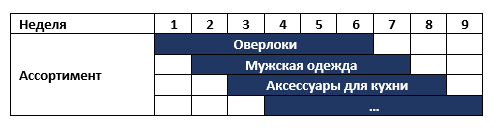
该网络要求有一个范围计划系统,该系统具有为类别管理者提供分析决策支持的先决条件。 与业务部门交谈之后,我们提出了两个非常快速的潜在解决方案,它们可以在部署计划系统时带来结果:
- 在主要销售期间未售出的商品的销售
- 提高商店预测需求的准确性
客户的第一点不满意-公司以不安排销售和维持恒定的利润水平为荣。 同时,在物流和货物存储上花费了大量金钱。 结果,决定提高预测需求的准确性,以更准确地分配商店和仓库。
当前过程
由于业务的性质,每个单独的产品都不会长时间出售,因此很难获得足够的历史记录进行经典分析。 当前的预测过程非常简单,其结构如下-在少数商店的主要销售开始测试销售开始之前的几周。 根据测试销售的结果,决定将商品引入整个网络,并假定每个商店的平均销售量与在测试商店的平均销售量相同。
着眼于客户,我们分析了当前数据,了解发生了什么,并提供了一个非常简单的解决方案来提高预测的准确性。
分析数据
根据我们提供的数据:
- 1年零2个月的交易记录
- 用于计划的产品层次结构。 不幸的是,它几乎完全缺乏商品的属性,但以后会更多
- 有关特定星期范围和价格的信息
- 有关商店所在城市的信息
我们无法在短时间内卸载有关余额的信息,这在这种分析中至关重要(如果您不存储此信息,请重新开始),因此,在将来,我们使用这样的假设,即货物在货架上并且不缺货。
立即我们将2个月分成一个测试样本以证明结果。 然后,我们将所有可用数据组合到一个大型展示柜中,以清除退货和奇特的销售额(例如,支票中的金额为每件商品0.51)。 花了好几天。 在准备好展示柜之后,我们查看了最高级别的商品销售[单位],并看到了以下图片:
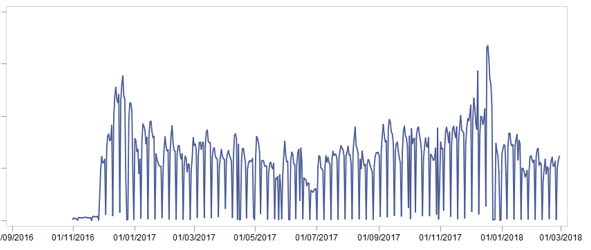
这张图片如何帮助我们?
- 显然,这是季节性因素-年末的销售额高于中期
- 一个月内有季节性-在月中,销售量高于年初和月末
- 一周内有季节性-不太有趣,因为 结果,预测是按周进行的
描述的项目确认了业务。 但是这些也是改善预测的重要功能! 在将它们添加到预测模型之前,让我们考虑应该考虑销售的其他哪些功能……我想到“显而易见”的想法:
- 不同产品组之间的平均销售额有所不同
- 不同商店之间的销售额有所不同
- (与上一段相似)不同城市之间的销售情况有所不同
- 由于公司的具体情况(思路不太明显),因此可以看到以下关系:如果将来的分类与以前的分类相似,则新分类的销售额将会降低。
为此,我们决定停止并建立模型。
建立ABT( 分析基表 )
作为模型构建的一部分,所有发现的特征都被转换为模型的“特征”。 结果是使用的功能列表:
- 目前的预测 分配给所有商店的[单位]中的测试商店的平均销售额
- 月数和月中的周数
- 所有类别变量(城市,商店,产品类别)均使用平滑的可能性 (有用的技术-尚未使用的人,请使用它)进行编码
- 计算出的滞后4个产品类别的平均销售额。 即 如果公司计划出售一件蓝色T恤,则计算出该T恤类别的平均销售滞后时间
事实证明,ABT很简单,每个参数都是企业可以理解的,并且不会引起误解或拒绝。 然后有必要了解我们将如何比较预测的质量。
指标选择
客户使用MAPE度量标准测量了当前的预测准确性。 该指标既流行又简单,但是在预测需求方面有一些缺点。 事实是,使用MAPE时,预测类型错误对最终指标的影响最大:

相对预测误差为900%-看起来很大,但让我们看一下另一种产品的销售情况:

相对预测误差为33%,远小于900%,但是对于业务而言,相对于18个[单位]的偏差,绝对偏差100 [单位]的重要性要大得多。 要考虑这些功能,您可以提出自己有趣的方法,或者可以使用另一种流行的方法来预测需求-WAPE 。 此措施将更多权重分配给具有较高销售额的商品,这对于完成任务非常有用。
我们向公司介绍了各种测量预测误差的方法,客户愿意同意在此任务中使用WAPE更合理。 在那之后,我们几乎没有调整超参数就启动了Random Forest,并获得了以下结果。
结果
在预测测试期间之后,我们将预测值与实际值以及公司的预测值进行了比较。 结果, MAPE下降了15%以上,WAPE下降了10%以上 。 计算出改进的预测对业务指标的影响后,成本降低了相当大的数百万美元。
1周花在所有工作上!
进一步的步骤
作为对客户的奖励,我们进行了一个小型DQ实验。 对于一个产品组,我们从产品名称中解析特征(颜色,产品类型,成分等)并将其添加到预测中。 结果令人鼓舞-在此类别中,两种错误措施均额外提高了8%以上。
结果,为客户提供了ABT展示柜的每个功能,模型参数,装配参数的描述,并描述了进一步改进预测的步骤(使用超过一年的历史数据;使用余额;使用商品的特性等)。
结论
与客户合作一周后,可以显着提高预测的准确性,而实际上不更改业务流程。
现在肯定有很多人认为这种情况非常简单,他们无法在公司中采用这种方法。 经验表明,几乎总是在某些地方仅使用基本假设和专家意见。 在这些地方,您可以开始使用机器学习。 为此,您需要仔细准备和研究数据,与业务部门交流并尝试应用不需要长时间调整的流行模型。 以及堆叠,嵌入功能,复杂模型-所有这些都将在以后提供。 我希望我说服您,这并不像看起来那样困难,您只需要稍微考虑一下,不要害怕入手。
不要害怕机器学习,寻找可以在流程中使用的地方,不要害怕研究您的数据,并让顾问来获取它们,并获得不错的结果。
PS:我们正在招募年轻的Padawan学生,在经验丰富的Jedi的指导下进行零售实习。 首先,常识和SQL知识就足够了,我们将教其余的知识。 您可以发展为业务专家或技术顾问,以较有趣的为准。 如果有兴趣或建议,请亲自写