系列文章“ Spring Boot上的应用程序的测试驱动开发”的第二篇文章,这次我将讨论测试数据库访问,这是集成测试的重要方面。 我将告诉您如何确定将来通过测试访问数据的服务的接口,如何使用内置的内存数据库进行测试,处理事务以及将测试数据上传到数据库。
我一般不会谈论TDD和测试,我邀请所有人阅读第一篇文章- 如何在主干中构建金字塔或如何在Spring Boot / geek杂志上进行应用程序的测试驱动开发
与上次一样,我将从理论上的一小部分开始,然后继续进行端到端测试。
测试金字塔
首先,对测试中的重要实体(如“测试金字塔”或“测试金字塔”)进行简短但必要的描述。
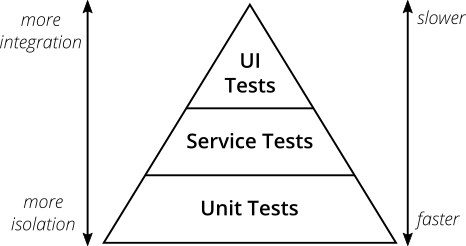
(摘自实用测试金字塔 )
测试金字塔是在多个级别组织测试时采用的方法。
- UI (或端到端E2E )测试很少,而且很慢,但是它们测试的是真实的应用程序-无需模拟程序,也不进行对应测试。 业务经常在此级别上进行思考,所有BDD框架都存在于此处(请参阅上一篇文章中的Cucumber)。
- 它们后面是集成测试 (服务,组件-每个都有其自己的术语),它们已经集中于系统的特定组件(服务),通过moki / doubles与其他组件隔离,但仍在检查与实际外部系统的集成-这些测试已连接到数据库,发送REST请求,我使用消息队列。 实际上,这些测试可验证业务逻辑与外界的集成。
- 最底层是快速的单元测试 ,它可以完全隔离地测试最少的代码块(类,方法)。
Spring可以帮助编写每个级别的测试- 甚至对于单元测试 ,尽管这听起来可能很奇怪,因为在单元测试的世界中,根本不存在有关框架的知识。 编写完端到端测试之后,我将展示Spring如何允许甚至像控制器这样的纯粹“集成”事物也可以单独进行测试。
但是,我将从金字塔的最高端开始-缓慢的UI测试,该测试将启动并测试完整的应用程序。
端到端测试
因此,一个新功能:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
这是一个非常有趣的方面-与先前的测试有关主页上的问候语怎么办? 似乎不再相关,在主页上启动网站后,将已经有目录,而不是问候语。 我会说没有一个答案-这取决于情况。 但主要建议-请勿参与测试! 当他们失去关联时将其删除,重写以使其更易于阅读。 特别是E2E测试-实际上,这应该是一个活泼的最新规范 。 就我而言,我只是删除了旧测试,并使用前面的一些步骤并添加了不存在的测试,将它们替换为新的测试。
现在,我谈到了重要的一点-选择用于存储数据的技术。 按照精益方法,我想将选择推迟到最后一刻-当我确定是否确定关系模型时,对一致性,事务性的要求是什么。 总的来说,有解决方案,例如创建测试对和各种内存存储,但是到目前为止,我不想使本文复杂化并立即选择技术-关系数据库。 但是为了保留至少某种选择数据库的可能性,我将添加一个抽象-Spring Data JPA 。 JPA本身是用于访问关系数据库的相当抽象的规范,而Spring Data使它的使用更加容易。
Spring Data JPA默认使用Hibernate作为提供程序,但也支持其他技术,例如EclipseLink和MyBatis。 对于不太熟悉Java Persistence API的人-JPA就像一个接口,而Hibernate是实现它的类。
因此,为了添加JPA支持,我添加了两个依赖项:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
作为数据库,我将使用H2-用Java编写的嵌入式数据库,并且能够在内存模式下工作。
使用Spring Data JPA,我立即定义了一个用于访问数据的接口:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
和本质:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
在实体的描述中有一些不太明显的事情。
sku字段的@NaturalId 。 该字段用作检查实体是否相等的“自然标识符”-在equals / hashCode方法中使用所有字段或@Id字段是一种反模式。 关于如何正确验证实体的相等性的文章写得很好,例如here 。- 为了稍微减少样板代码,我使用Project Lombok -Java的注释处理器。 它允许您添加各种有用的东西,例如
@Builder自动为类生成一个构建器,而@AllArgsConstructor为所有字段创建一个构造器。
Spring Data将自动提供接口实现。
下金字塔
现在是时候进入金字塔的下一个层次了。 根据经验,我建议您始终从e2e测试开始 ,因为这将使您确定“最终目标”和新功能的边界,但是没有更严格的规则。 在升级到单元级别之前,不必先编写集成测试。 通常,它更方便,更简单-顺理成章。
但特别是现在,我想立即打破此规则,编写一个单元测试,这将有助于确定尚不存在的新组件的接口和协定。 控制器应返回一个将从某个组件X填充的模型,我编写了以下测试:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
这是一个纯单元测试-没有上下文,没有数据库,只有Mockito for mok。 这个测试只是Spring如何帮助进行单元测试的一个很好的展示-Spring MVC中的控制器只是一个类,其方法接受普通类型的参数并返回POJO对象-视图模型 。 没有HTTP请求,没有响应,标头,JSON,XML-所有这些都将以转换器和序列化器的形式自动应用于堆栈。 是的,以ModelAndView的形式向Spring提供了一个小的“提示”,但这是一个常规的POJO,您甚至可以根据需要摆脱它,这是UI控制器特别需要的。
我不会谈论Mockito,您可以阅读官方文档中的所有内容。 具体来说,此测试中只有一些有趣的要点-我使用MockitoExtension.class作为测试运行程序,它将自动为@Mock注释的字段生成mokas,然后将这些mokas作为依赖项注入到@InjectMocks字段中的对象的构造函数中。 您可以使用Mockito.mock()方法手动完成所有这些操作,然后创建一个类。
此测试有助于确定新组件的方法findPromotedCakes ,这是我们要在主页上显示的蛋糕列表。 他没有确定它是什么,也不知道它如何与数据库一起使用。 管制员的唯一责任是取走转移给它的物品,并在特定领域退还模型(“蛋糕”)。 尽管如此, CakeFinder在我的界面中已经具有第一个方法,这意味着您可以为其编写集成测试。
我故意将cakes 包中的所有类都cakes 私有,以便包外的任何人都不能使用它们。 从数据库获取数据的唯一方法是使用CakeFinder界面,它是我访问数据库的“组件X”。 它成为自然的“连接器”,如果我需要隔离测试而不接触底座,我可以轻松锁定它。 它的唯一实现是JpaCakeFinder。 并且,例如,如果将来数据库类型或数据源发生更改,那么您将需要添加CakeFinder接口的实现,而无需更改使用它的代码。
使用@DataJpaTest对JPA进行集成测试
集成测试是春季面包和黄油。 实际上,在其中,集成测试的所有工作都做得非常好,以至于开发人员有时不希望进入单元级别或忽略UI级别。 这既不是不好也不是好-我重申测试的主要目标是信心。 一组快速有效的集成测试可能足以提供这种信心。 但是,随着时间的流逝,这些测试可能会变得越来越慢,或者只是孤立地而不是集成地开始测试组件。
集成测试可以按原样( @SpringBootTest )或其单独的组件(JPA,Web)运行应用程序。 就我而言,我想编写针对JPA的重点测试-因此,我无需配置控制器或任何其他组件。 在Spring Boot Test中, @DataJpaTest批注对此负责。 这是一个元注释,即 它结合了几个不同的注释,这些注释配置了测试的不同方面。
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @交易
首先,我将分别向您介绍每个测试,然后再向您展示完成的测试。
@AutoConfigureDataJpa
它加载了整套配置并配置了存储库(自动生成CrudRepositories的实现),用于FlyWay和Liquibase数据库的迁移工具,并使用DataSource,事务管理器以及最后的Hibernate连接到数据库。 实际上,这只是与访问数据有关的一组配置-这里既不包括Web MVC的DispatcherServlet ,也不包括其他组件。
@AutoConfigureTestDatabase
这是JPA测试最有趣的方面之一。 此配置在类路径中搜索受支持的嵌入式数据库之一,然后重新配置上下文,以便DataSource指向随机创建的内存数据库 。 由于我已将依存关系添加到H2基数中,因此我无需执行其他任何操作,仅在每次测试运行时自动具有此批注将提供一个空基数,这非常方便。
值得记住的是,如果没有计划,这个基础将完全是空的。 要生成电路,有两种选择。
- 使用Hibernate中的Auto DDL功能。 Spring Boot Test会自动将此值设置为
create-drop以便Hibernate将根据实体描述生成模式,并在会话结束时将其删除。 这是Hibernate强大的功能,对于测试非常有用。 - 使用由Flyway或Liquibase创建的迁移。
您可以在文档中详细了解有关初始化数据库的不同方法。
@AutoConfigureCache
它只是将缓存配置为使用NoOpCacheManager-即 不要缓存任何内容。 这对于避免测试出乎意料很有用。
@AutoConfigureTestEntityManager
向TestEntityManager添加一个特殊的TestEntityManager对象,它本身就是一个有趣的野兽。 EntityManager是JPA的主要类,负责将实体添加到会话中,删除和进行类似操作。 例如,仅当Hibernate投入运行时-向会话添加实体并不意味着将执行对数据库的请求,并且从会话加载并不意味着将执行选择请求。 由于Hibernate的内部机制,对数据库的实际操作将在适当的时间执行,而框架本身将确定适当的时间。 但是在测试中,可能有必要将某些内容强制发送到数据库,因为测试的目的是测试集成。 而且TestEntityManager只是一个帮助程序,它将帮助强制执行数据库中的某些操作-例如, persistAndFlush()将强制Hibernate执行所有请求。
@交易
该注释使该类中的所有测试都具有事务性,并在测试完成后自动回滚该事务。 这只是在每次测试之前“清理”数据库的一种机制,因为否则您将不得不从每个表中手动删除数据。
一个测试是否应该管理一个事务似乎并不是一个简单而明显的问题。 尽管数据库的“干净”状态很方便,但是如果“战斗”代码没有启动事务本身而是需要现有事务,则测试中@Transactional出现可能会令人不快。 这可能会导致集成测试通过,但是当从控制器而不是测试中执行实际代码时,该服务将没有活动的事务,并且该方法将引发异常。 尽管这看起来很危险,但是通过UI测试的高级测试,事务测试还不错。 以我的经验,当通过的集成测试使生产代码崩溃时,我只看到了一次,这显然需要现有事务的存在。 但是,如果仍然需要验证服务和组件本身是否正确管理事务,则可以使用所需的模式在测试中“阻止” @Transactional批注(例如,不要启动事务)。
与@SpringBootTest的集成测试
我还想指出, @DataJpaTest不是焦点集成测试的唯一示例,其中包括@WebMvcTest , @DataMongoTest等。 但是,最重要的测试注释之一仍然是@SpringBootTest ,它以所有配置的组件和集成“按原样”启动测试应用程序。 出现一个逻辑问题-如果您可以运行整个应用程序,为什么要进行集中DataJpa测试? 我要说的是,这里再也没有严格的规定了。
如果可以每次运行应用程序,隔离测试中的崩溃,不过载并且不使测试的设置复杂化,那么您当然可以并且应该使用@SpringBootTest。
但是,在现实生活中,应用程序可能需要许多不同的设置,连接到不同的系统,并且我不希望我的数据库访问测试失败,因为 未配置与消息队列的连接。 因此,使用常识很重要,如果要使用@SpringBootTest批注进行测试,您需要锁定一半的系统-那么在@SpringBootTest中是否有意义?
准备测试数据
测试的关键点之一是数据准备。 每个测试都应单独执行,并在启动之前准备环境,以使系统进入其原始期望状态。 最简单的方法是使用@BeforeEach / @BeforeAll批注,然后使用存储库EntityManager或TestEntityManager在数据库中添加条目。 但是还有另一个选项可以让您运行准备好的脚本或执行所需的SQL查询,这是@Sql批注。 在运行测试之前,Spring Boot Test将自动运行指定的脚本,而无需添加@BeforeAll块,而@Transactional将负责数据@Transactional 。
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
红绿重构循环
尽管有这么多的文本,对于开发人员来说,该测试仍然看起来像是带有@DataJpaTest批注的简单类,但是我希望我能够展示在幕后正在发生的有用的事情,开发人员无法想到。 现在我们可以进入TDD周期,这次我将展示一些TDD迭代,并提供重构示例和最少的代码。 为了更清楚一点,我强烈建议您查看Git中的历史记录,其中每个提交都是一个单独的重要步骤,并描述了它的作用和方式。
资料准备
我对@BeforeAll / @BeforeEach使用此方法,并在数据库中手动创建所有记录。 带有@Sql注释的示例移至一个单独的类JpaCakeFinderTestWithScriptSetup ,它复制了测试,这些测试当然不应存在,并且仅出于演示该方法的目的而存在。
系统的初始状态-系统中有两个条目,一个蛋糕参与促销,并且必须包含在该方法返回的结果中,第二个-否。
首次测试整合测试
第一个测试是最简单的findPromotedCakes应该包含参与促销的蛋糕的描述和价格。
红色的
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
测试当然会崩溃-默认实现返回一个空的Set。
绿色的
自然,我们想立即编写过滤,使用where向数据库发出请求where等等。 但是,按照TDD惯例,我必须编写最低代码以通过测试 。 这个最少的代码是返回数据库中的所有记录。 是的,如此简单和老套。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
可能有人会争辩说,即使没有基础,也可以使测试变成绿色-只需对测试预期的结果进行硬编码即可。 我偶尔会听到这样的争论,但是我想每个人都理解TDD并不是教条或宗教,因此将其带到荒谬的意义上是没有意义的。 但是,如果您确实愿意,那么您可以,例如,对安装中的数据进行随机化处理,以便不对其进行硬编码。
重构
我在这里看不到太多的重构,因此可以针对此特定测试跳过此阶段。 但是我仍然不建议忽略此阶段,最好停下来思考一下每次系统处于“绿色”状态-是否可以重构某些东西以使其变得更好,更容易?
第二次测试
但是第二个测试将已经验证没有任何升级的蛋糕落入findPromotedCakes返回的结果中。
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
红色的
正如预期的那样,该测试崩溃了-数据库中有两条记录,并且代码简单地将它们全部返回。
绿色的
再一次您可以考虑-通过测试您可以编写的最低代码是多少? 由于已经有一个流及其组合,因此您只需在其中添加一个filter块即可。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
我们重新启动测试-集成测试现在变为绿色。 重要的时刻已经到来-由于控制器的单元测试和与数据库一起使用的集成测试的结合,我的功能已准备就绪-UI测试现在通过!
重构
而且由于所有测试都是绿色的,所以该重构了。 我认为没有必要澄清内存过滤不是一个好主意,最好在数据库中执行此操作。 为此,我在CakesRepository添加了一个新方法CakesRepository :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
对于此方法,Spring Data自动生成一个方法,该方法将执行对形式select from cakes where promoted = true 。 在Spring Data 文档中阅读有关查询生成的更多信息。
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
这是集成测试和黑匣子方法提供的灵活性的一个很好的例子。 如果存储库被锁定,那么添加新方法而不更改测试并非没有可能。
连接生产基地
为了增加一些“真实性”并显示如何将测试配置和主应用程序分开,我将为“生产”应用程序添加数据访问配置。
传统上,所有内容都由application.yml的部分添加:
datasource: url: jdbc:h2:./data/cake-factory
这将自动将文件系统中的数据保存到./data文件夹中。 我注意到该文件夹不会在测试中创建-由于存在@AutoConfigureTestDatabase批注, @AutoConfigureTestDatabase内存中的随机数据库自动替换与文件数据库的连接。
, — data.sql schema.sql . , Spring Boot . , , , .
结论
, , , TDD .
Spring Security — Spring, .