“
公司 ”-电信运营商PJSC“ Megafon”
“
Noda ”是RabbitMQ服务器。
在我们的三个案例中,“
集群 ”是RabbitMQ节点整体工作的组合。
“
轮廓 ”-一组RabbitMQ群集,使用它们的规则由它们前面的平衡器确定。
“
Balancer ”,“ hap”-Haproxy-平衡器,执行在循环内的群集上切换负载的功能。 每个循环使用一对并行运行的Haproxy服务器。
“
子系统 ”-通过兔子传输的消息的发布者和/或使用者
“
系统 ”-子系统的集合,是公司使用的单个软件和硬件解决方案,其特征是在整个俄罗斯分布,但有几个中心,所有信息流在此进行,并且主要进行计算和计算。
系统-从哈巴罗夫斯克和符拉迪沃斯托克到圣彼得堡和克拉斯诺达尔的地理分布系统。 从体系结构上讲,这些是几个中央轮廓,按与之相连的子系统的功能划分。
电信现实中的运输任务是什么?
简而言之:子系统对每个订阅者的操作的响应如下,该响应又将其他事件和后续更改通知其他子系统。 消息是通过SYSTEM的任何操作生成的,不仅来自订户,而且来自公司员工和子系统的消息(自动执行大量任务)。
电信传输的特征:通过异步传输传输的各种数据的大型,无错,大数据流。
由于消息流繁重,一些子系统位于单独的集群上-集群上根本没有剩余资源,例如,消息流为5-6千条消息/秒,传输的数据量可以达到170-190兆字节/秒。 有了这样的负载配置文件,尝试将其他任何人降落到该集群上将导致可悲的后果:由于没有足够的资源同时处理所有数据,因此兔子将开始推动传入的连接进入
流程 -将开始一个简单的发布过程,对所有子系统和SYSTEMS造成所有后果整体。
运输的基本要求:
- 车辆的可达性应为99.99%。 实际上,这转化为24/7的操作要求,并具有自动响应任何紧急情况的能力。
- 数据安全:传输中丢失消息的百分比应趋于0。
例如,在发出呼叫的事实后,一些不同的消息通过异步传输传输。 一些消息用于居住在同一电路中的子系统,而某些消息则用于传输到中央节点。 几个子系统可以声明同一条消息,因此,在兔子中发布该消息的阶段,会将其复制并发送给不同的使用者。 在某些情况下,当需要将信息从哈巴罗夫斯克的电路传递到克拉斯诺达尔的电路时,在中间电路上强制执行复制消息。 通过中央轮廓之一进行传输,在中央轮廓中为中央接收者复制邮件。
除了由订户的操作引起的事件之外,交换子系统的服务消息还通过传输。 因此,获得了数千种不同的消息传递路由,有些相交,有些孤立地存在。 只需列出不同轮廓上的路由所涉及的队列数即可了解传输图的大致比例:在中央电路600、200、260、15 ...和远程电路80-100 ...上
有了传输的这种参与,对所有传输节点100%可访问性的要求似乎不再过多。 我们正在继续执行这些要求。
我们如何解决任务
除了
RabbitMQ本身之外 ,
Haproxy还用于平衡负载并提供对紧急情况的自动响应。
关于我们的兔子所处的硬件和软件环境的几句话:
- 所有Rabbit服务器都是虚拟的,参数为8-12 CPU,16 Gb Mem,200 Gb HDD。 正如经验所表明的那样,即使使用具有90个内核和一组RAM的令人毛骨悚然的非虚拟服务器也可以以显着更高的成本提高性能。 使用的版本:3.6.6(实际上是3.6中最稳定的),erlang为18.3; 3.7.6,erlang为20.1。
- 对于Haproxy,要求要低得多:2个CPU,4 Gb内存,haproxy版本是1.8稳定版。 所有haproxy服务器上的资源负载不超过15%CPU / Mem。
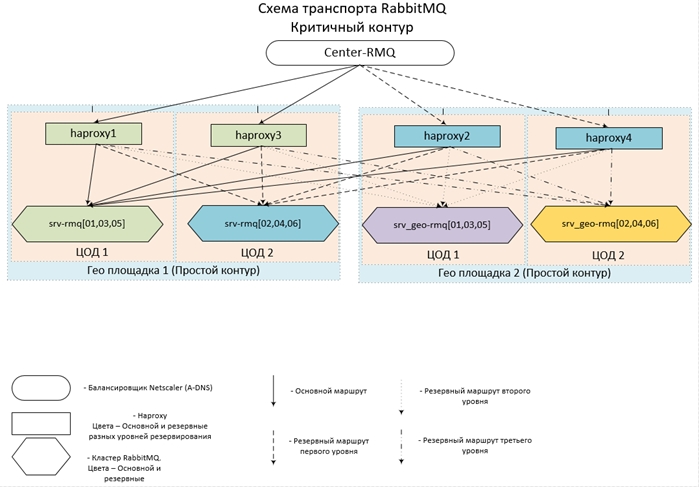
- 整个动物园位于全国7个站点的14个数据中心中,并形成一个单一网络。 在每个数据中心中,都有一个由三个节点和一个集线器组成的集群。
- 对于远程电路,每个中央电路使用2个数据中心-4。
- 中央电路彼此之间以及与远程电路交互;反过来,远程电路仅与中央电路一起工作;它们彼此之间没有直接的通信。
- 同一电路内的臀部和丛集的配置完全相同。 每个电路的入口点是多个A-DNS记录的别名。 因此,为了防止这种情况的发生,每个电路中的至少一个hap和至少一个群集(群集中的至少一个节点)将可用。 由于极不可能发生两个数据中心中同时出现6台服务器同时发生故障的情况,因此,可接受性被认为接近100%。
它看起来像是在构思(并实现)了以下所有内容:

现在进行一些配置。
代理配置| 前端中心-rmq_5672 | |
| 捆绑 | *:5672 |
| 模式 | tcp |
| 麦克斯康 | 10,000 |
| 超时客户端 | 3小时 |
| 选项 | tcpka |
| 选项 | tcplog |
| default_backend | 中心rmq_5672 |
| 前端中心-rmq_5672_lvl_1 | |
| 捆绑 | 本地主机:56721 |
| 模式 | tcp |
| 麦克斯康 | 10,000 |
| 超时客户端 | 3小时 |
| 选项 | tcpka |
| 选项 | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| 后端中心-rmq_5672 |
| 平衡 | 最小康 |
| 模式 | tcp |
| 富康 | 10,000 |
| 超时时间 | 服务器3小时 |
| 伺服器 | srv-rmq01 10/10/10/10/106767检查Inter 5s上升2下降3标记为关闭-备份-会话 |
| 伺服器 | srv-rmq03 10/10/10/2011 11672检查Inter 5s上升2下降3标记为shutdown-backup-sessions |
| 伺服器 | srv-rmq05 10/10/10/126767检查Inter 5s上升2下降3标记为shutdown-backup-sessions |
| 伺服器 | 本地主机127.0.0.1 * 6721检查Inter 5s上升2下降3备份标记为关闭的会话 |
| 后端中心-rmq_5672_lvl_1 |
| 平衡 | 最小康 |
| 模式 | tcp |
| 富康 | 10,000 |
| 超时时间 | 服务器3小时 |
| 伺服器 | srv-rmq02 10/10/10/136767检查Inter 5s上升2下降3标记为shutdown-backup-sessions |
| 伺服器 | srv-rmq04 10/10/10/14/1067检查Inter 5s上升2下降3标记为shutdown-backup-sessions |
| 伺服器 | srv-rmq06 10.10.10.5:0767检查Inter 5s上升2下降3标记为shutdown-backup-sessions |
前面的第一部分描述了进入点-通往主集群,第二部分旨在平衡备用级别。 如果仅在后端部分描述所有的备份兔子服务器(备份指令),它将以相同的方式工作-如果完全无法访问主群集,则连接将进入备份服务器,但是所有连接将进入列表中的第一台备份服务器。 为了确保所有备份节点上的负载平衡,我们只介绍了一个前端(仅适用于localhost),并为其分配了备份服务器。
上面的示例描述了在两个数据中心内运行的远程环路的平衡:srv-rmq服务器{01,03,05}-位于2号数据中心中的1号数据中心srv-rmq {02,04,06}中。 因此,要实现四尾码解决方案,我们只需要添加两个相应的Rabbit服务器的本地前端和两个后端部分。
采用这种配置的平衡器的行为如下:当至少一个主服务器处于活动状态时,我们使用它。 如果主服务器不可用,我们将与备用服务器合作。 如果至少有一个主服务器可用,则到备份服务器的所有连接都将断开,并且在恢复连接时,它们已经落在主群集上。
这种配置的操作经验表明,每个电路的可用性几乎为100%。 此解决方案要求子系统完全合法且简单:断开连接后才能与兔子重新连接。
因此,我们为任意数量的集群提供了负载平衡,并在它们之间自动切换,是时候直接进入兔子了。
如实践所示,每个群集都是从三个节点创建的-最佳数量的节点,可确保可用性/容错/速度的最佳平衡。 由于兔子无法水平扩展(集群性能等于最慢服务器的性能),因此我们为CPU / Mem / Hdd创建具有相同最佳参数的所有节点。 我们将服务器放置在尽可能近的位置-在我们的情况下,我们正在同一服务器场中归档虚拟机。
至于先决条件,随后子系统将确保最稳定的操作并满足保存已接收消息的要求:
- 仅通过amqp / amqps协议与兔子合作-通过平衡。 在本地帐户下进行授权-在每个群集内(井以及整个回路)
- 子系统以被动模式连接到兔子:不允许对兔子的实体进行任何操作(创建队列/ exchendzhe / bind),并且仅限于帐户权限级别-我们根本不授予配置权限。
- 所有必需的实体都是通过集中方式创建的,而不是通过子系统来创建的,并且在所有群集上,群集都是以相同的方式完成的-确保自动切换到备用群集,反之亦然。 否则,我们可以得到一张图片:我们切换到了保留,但是队列或绑定不存在,并且可以选择连接错误或消息丢失。
现在直接在兔子上设置:
- 本地主机无权访问Web界面
- 通过LDAP可以组织对Web的访问-我们与AD集成在一起,并记录了网络摄像头的去向和地点。 在配置级别,我们限制AD帐户的权限,不仅我们需要属于某个组,而且还仅授予“查看”权限。 监视组绰绰有余。 并且我们将管理员权限挂在AD中的另一个组上,因此极大地限制了对传输的影响范围。
- 为了便于管理和跟踪:
在所有VHOST上,我们立即挂起一个级别为0的策略,并将其应用到所有队列(模式:。*):
- ha模式:全部 -将所有数据存储在群集的所有节点上,消息的处理速度降低,但是可以确保其安全性和可用性。
- ha-sync-mode:自动 -指示搜寻器自动同步集群所有节点上的数据:数据的安全性和可用性也提高了。
- 队列模式:惰性 -可能是自3.6版以来在兔子中出现的最有用的选项之一-立即在HDD上记录消息。 此选项显着减少了RAM的消耗,并在节点或整个群集的停止/崩溃期间提高了数据安全性。
- 配置文件中的设置( rabbitmq-main / conf / rabbitmq.config ):
- 兔子节: {vm_memory_high_watermark_paging_ratio,0.5} -将消息下载到磁盘50%的阈值。 启用惰性后,当我们制定第1级的保险单时,它会更多地充当保险,而我们忘记包括惰性 。
- {vm_memory_high_watermark,0.95} -我们将兔子限制为总RAM的95%,因为只有兔子生活在服务器上,所以引入更严格的限制是没有道理的。 5%的“宽手势”就这样-离开操作系统,监视和其他有用的小东西。 由于此值是上限,因此每个人都足够。
- {cluster_partition_handling,pause_minority} -描述发生网络分区时群集的行为,对于三个或更多节点群集,建议使用此标志-它允许群集自行恢复。
- {disk_free_limit,“ 500MB”} -一切都很简单,当有500 MB可用磁盘空间时-消息发布将停止,只有减法才可用。
- {auth_backends,[rabbit_auth_backend_internal,rabbit_auth_backend_ldap]} -兔子的授权顺序:首先,检查本地数据库中是否存在超声波,如果没有,请转到LDAP服务器。
- 一节rabbitmq_auth_backend_ldap-与AD的交互配置: {servers,[“ srv_dc1”,“ srv_dc2”]} -将在其上进行身份验证的域控制器的列表。
- 在AD,LDAP端口等中直接描述用户的参数纯粹是单独的,并在文档中进行了详细描述。
- 对我们来说最重要的事情是对兔子的管理和访问Web界面的权利和限制的描述:tag_queries:
[{管理员,{in_group,“ cn = Rabbitmq-admins,ou = GRP,ou = GRP_MAIN,dc = My_domain,dc = ru”}},
{监视,
{in_group,“ cn = Rabbitmq-web,ou = GRP,ou = GRP_MAIN,dc = My_domain,dc = ru”}
}] -此设计为rabbitmq-admins组的所有用户提供管理特权,并为rabbitmq-web组提供监视权限(至少足以查看访问权限)。
- resource_access_query :
{
[{权限,配置,{in_group,“ cn = Rabbitmq-admins,ou = GRP,ou = GRP_MAIN,dc = My_domain,dc = ru”}},
{权限,写,{in_group,“ cn = Rabbitmq-admins,ou = GRP,ou = GRP_MAIN,dc = My_domain,dc = ru”}},
{权限,读取,{恒定,正确}}}
]
} -我们仅向管理员组,成功登录的其他所有人提供配置和写入权限,这些权限是只读的-它可以通过Web界面读取消息。
我们获得了一个已配置(在Rabbit本身中的配置文件和设置级别)的集群,该集群使数据的可用性和安全性最大化。 通过这种方式,我们可以实现要求-在大多数情况下确保数据的可用性和安全性。
在运行这种高负载的系统时,应考虑以下几点:
- 最好由政客组织队列的所有其他属性(TTL,过期,最大长度等),而不是在创建队列时挂起参数。 事实证明,该结构可以灵活地进行自定义,可以根据实际情况随时进行自定义。
- 使用TTL。 队列越长,CPU的负载就越高。 为了防止“突破上限”,最好也通过max-length限制队列长度。
- 除了Rabbit本身之外,服务器上还有许多实用程序在运行,这很奇怪,这也需要CPU资源。 默认情况下,食的兔子会占用所有可用的内核……结果可能会令人不快:争夺资源,这很容易导致兔子的刹车。 为了避免这种情况的发生,例如,如下所示:更改erlang的启动参数-对使用的内核数实行强制性限制。 我们这样做如下:找到文件Rabbitmq-env ,查找SERVER_ERL_ARGS =参数,然后向其添加+ sct L0-Xc0-X + SY:Y。 其中X是内核数1(从0开始计数),Y是内核数-1(从1开始计数)。 + sct L0-Xc0-X-更改与内核的绑定,+ SY:Y-更改由erlang启动的泄放程序的数量。 因此,对于具有8个内核的系统,添加的参数将采用以下形式:+ sct L0-6c0-6 + S 7:7。 这样,我们只给Rabbit提供7个内核,并期望OS通过启动其他进程来发挥最佳性能,并将其挂在未加载的内核上。
操作最终动物园的细微差别
任何设置都无法避免的是失忆症的基础萎缩-不幸的是,发生的可能性不为零。 这种灾难性的结果不是由全局故障(例如,整个数据中心的完全故障-负载将简单地切换到另一个群集)引起的,而是由同一网络段内的更多本地故障引起的。
而且,令人恐惧的是本地网络故障,因为 紧急关闭一两个节点不会导致致命的后果-所有请求都将发送到一个节点,并且正如我们所记住的,性能仅取决于节点本身的性能。 网络故障(我们不考虑通信中的小中断-会无痛地经历)导致以下情况:节点之间开始彼此的同步过程,然后连接一次又一次断开几秒钟。
例如,网络反复闪烁且频率超过5秒(仅在Hapov设置中设置了这样的超时时间,您当然可以播放它们,但是要检查有效性,您需要重复失败,这是没人希望的)。
集群仍然可以承受一两次这样的迭代,但是更多-机会已经很小。 在这种情况下,停下的节点可以节省下来,但是几乎不可能手动完成。 更常见的是,结果不仅是群集中丢失了带有
“网络分区”消息的节点,而且还显示了当队列中的部分数据仅生活在该节点并且没有时间与其余节点同步时的情况。 视觉上排队的数据为
NaN 。
现在这是一个明确的信号-切换到备份群集。 切换将提供一个机会,您只需将兔子停在主群集上-只需几分钟。 结果,我们可以恢复运输工具的工作能力,并且可以安全地进行事故分析和排除。
为了从负载下移除损坏的群集,以防止进一步的退化,最简单的方法是使兔子在除5672之外的其他端口上工作。由于我们通过常规端口监视兔子,因此,例如通过5673来监视兔子的位移在Rabbit的设置中,它将使您毫不费力地完全启动集群,并尝试恢复其可操作性和消息。
我们分几步来做:
- 停止故障群集的所有节点-hap将把负载切换到备份群集
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
在启动时,将重建索引,并且在大多数情况下,所有数据将全部还原。不幸的是,由于发生崩溃,您必须从磁盘上物理删除所有消息,而仅留下配置-在数据库文件夹中删除msg_store_persistent,msg_store_transient,队列(对于3.6版)或msg_stores(对于3.7版)目录。经过这种彻底的治疗后,簇开始发射并保留了内部结构,但没有信息。而最不愉快的选择(仅观察到一次):损坏基座,必须完全移除整个基座并从头开始重建群集。为了方便管理和更新兔子,不使用rpm中现成的程序集,而是使用cpio分解并重新配置(更改脚本中的路径)兔子。主要区别在于:它不需要root特权即可安装/配置,也没有安装在系统上(重建的Rabbit完美包装在tgz中),并且可以从任何用户运行。这种方法允许您灵活地升级版本(如果不需要完全停止群集-在这种情况下,只需切换到备份群集并进行更新,而不必忘记指定操作的移位端口)。甚至可以在同一台机器上运行RabbitMQ的多个实例-为了测试该选项非常方便-您可以部署战斗动物园的简化体系结构副本。由于脚本和脚本中都存在cpio和路径的萨满教化,我们得到了一个构建选项:两个Rabbitmq基文件夹(在原始程序集中-mnesia文件夹)和rabbimq-main-在这里,我放置了Rabbit和erlang本身的所有必需脚本。在rabbimq-main / bin中-指向兔子和erlang脚本以及兔子跟踪脚本(以下描述)的符号链接。在rabbimq-main / init.d中-日志开始/停止/循环通过的Rabbitmq服务器脚本;在lib中,兔子本身;在lib64中-erlang(使用精简版,仅适用于erlang版本的Rabbit)。发布新版本时,更新生成的程序集非常容易-从新版本中添加rabbimq-main / lib和rabbimq-main / lib64的内容,并替换bin中的符号链接。如果更新也影响控制脚本-只需在其中更改我们脚本的路径即可。这种方法的一个显着优势是版本的完整连续性-所有路径,脚本,控制命令均保持不变,这使您可以使用任何自写的实用程序脚本而无需为每个版本添加掺杂。自从兔子跌倒以来,尽管很少见,但确实发生了,所以有必要实施一种监测其健康的机制-跌倒时饲养(保持跌倒原因的原木)。在99%的情况下,节点的故障都伴随有日志条目,甚至杀死甚至留下痕迹,这使得使用简单的脚本实现对兔子状态的监视成为可能。对于版本3.6和3.7,由于日志条目中的差异,脚本略有不同。对于3.7,仅更改了两行 if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
我们设置了一个crontab帐户,兔子可以在每分钟下工作(默认情况下为rabbitmq)每分钟执行此脚本(脚本名称:check_and_run)(首先,我们要求管理员授予该帐户使用crontab的权利,但是如果我们拥有root权限,则我们自己做):
* / 1 * * * *〜/ Rabbitmq-main / bin / check_and_run使用重新组装的兔子的第二点是原木的旋转。
由于我们不依赖于logrotate系统,因此我们使用开发人员提供的功能:init.d中的
Rabbitmq-server脚本(对于3.6版)
通过对
rotate_logs_rabbitmq()进行小的更改
添加:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
使用关键的rotate-logs运行rabbitmq-server脚本的结果:日志由gzip压缩,并且仅存储最近30天。
http_api-兔子放置日志的路径http-在配置文件中配置:
{rabbitmq_management,[{rates_mode,详细},{http_log_dir,path_to_logs / http_api“}]}同时,我特别注意
{rates_mode, 详细的 } -该选项稍微增加了负载,但是它使您可以查看有关在WEB界面上的EXCHENGE中发布消息的用户的信息(并相应地通过API获取)。 信息是非常必要的,因为 所有连接都通过平衡器-我们只会看到平衡器本身的IP。 并且,如果您迷惑了所有与兔子一起工作的子系统,以便它们在与兔子的连接属性中填写“客户端属性”参数,那么就有可能在连接级别上获得详细的信息,确切地,在哪里以及以何种强度发布消息。
随着新版本3.7的发布,
init.d中的
rabbimq-server脚本被完全拒绝。 为了简化操作(无论兔子的版本如何,控制命令的一致性)以及版本之间的平滑过渡,在重新组装的兔子中,我们继续使用此脚本。 事实再次是:我们
将对一下
rotate_logs_rabbitmq()进行一些更改,因为旋转后命名日志的机制已在3.7中更改:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
现在只剩下将日志轮换任务添加到crontab了-例如,每天23:00:
00 23 * * *〜/ rabbitmq-main / init.d / rabbitmq-server旋转日志让我们继续进行“兔子农场”操作框架中需要解决的任务:
- 使用兔子实体进行操作-创建/删除兔子实体:ekschendzhey,队列,绑定,铲子,用户,策略。 为此,在所有群集群集上都完全相同。
- 从备份群集切换到备份群集后,需要将保留在其上的消息传输到当前群集。
- 创建所有电路的所有集群的配置的备份副本
- 轮廓内群集配置的完全同步
- 停止/开始兔子
- 要分析当前的数据流,请执行以下操作:所有消息都走了,如果走了,那么走到哪里?
- 通过任何条件查找和捕获传递的消息
通过提供的常规
rabbitmq_management插件可以操作我们的动物园并解决问题,但非常不便,这就是为什么开发并实施了一个外壳来
控制所有种类的兔子的原因 。