
我在Odnoklassniki平台团队中工作,今天我将讨论音乐分发服务的体系结构,设计和实现细节。
本文是Joker 2018上该报告的笔录。
一些统计
首先,关于OK的几句话。 这是一项庞大的服务,已有超过7,000万用户使用。 它们由4个数据中心的7,000辆汽车提供服务。 最近,我们在不考虑众多CDN站点的情况下突破了2 Tb / s的流量标记。 我们最大限度地利用了硬件,负载最大的服务每秒可从四核节点处理多达100,000个请求。 而且,几乎所有服务都是用Java编写的。
OK中有很多部分,其中最受欢迎的部分是“音乐”。 在其中,用户可以上传曲目,购买和下载不同质量的音乐。 该部分有一个很棒的目录,推荐系统,广播等等。 但是,该服务的主要目的当然是播放音乐。
音乐发行人负责将数据传输到用户播放器和移动应用程序。 如果查看对musicd.mycdn.me域的请求,则可以在Web检查器中捕获它。 分发器API非常简单。 它响应
GET HTTP请求并发出请求的跟踪范围。
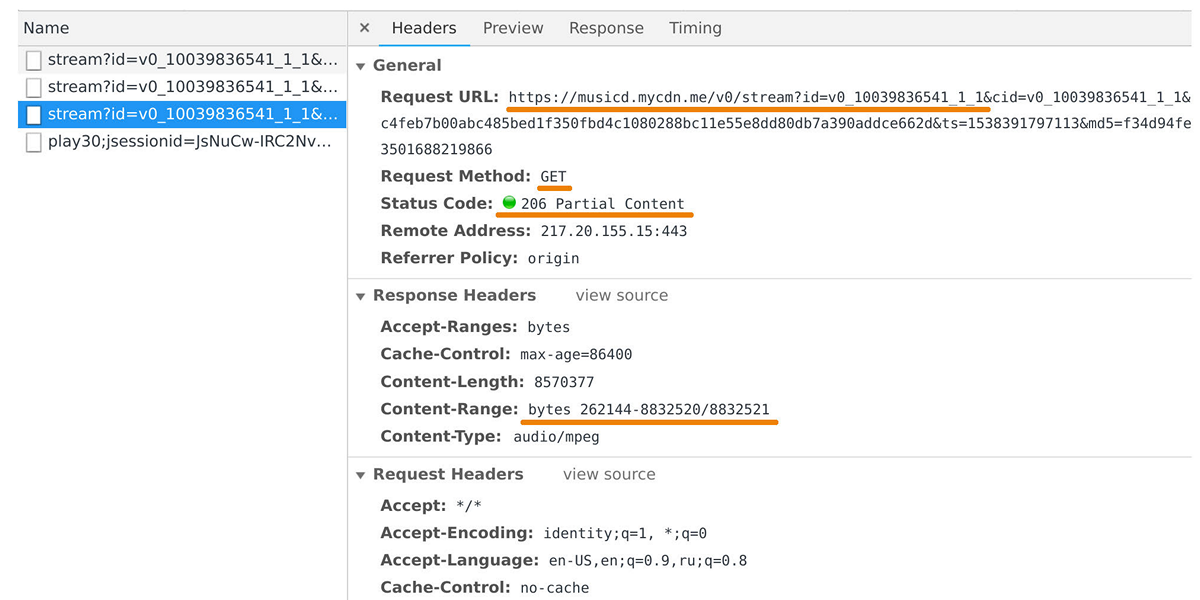
高峰时,通过500万个连接,负载达到100 Gb / s。 实际上,音乐分发器是位于我们内部轨道存储库前面的缓存前端,该内部存储库基于
One Blob存储和
One Cold Storage并包含PB级数据。
既然我已经讨论过缓存,那么让我们看一下回放统计信息。 我们看到了明显的TOP。
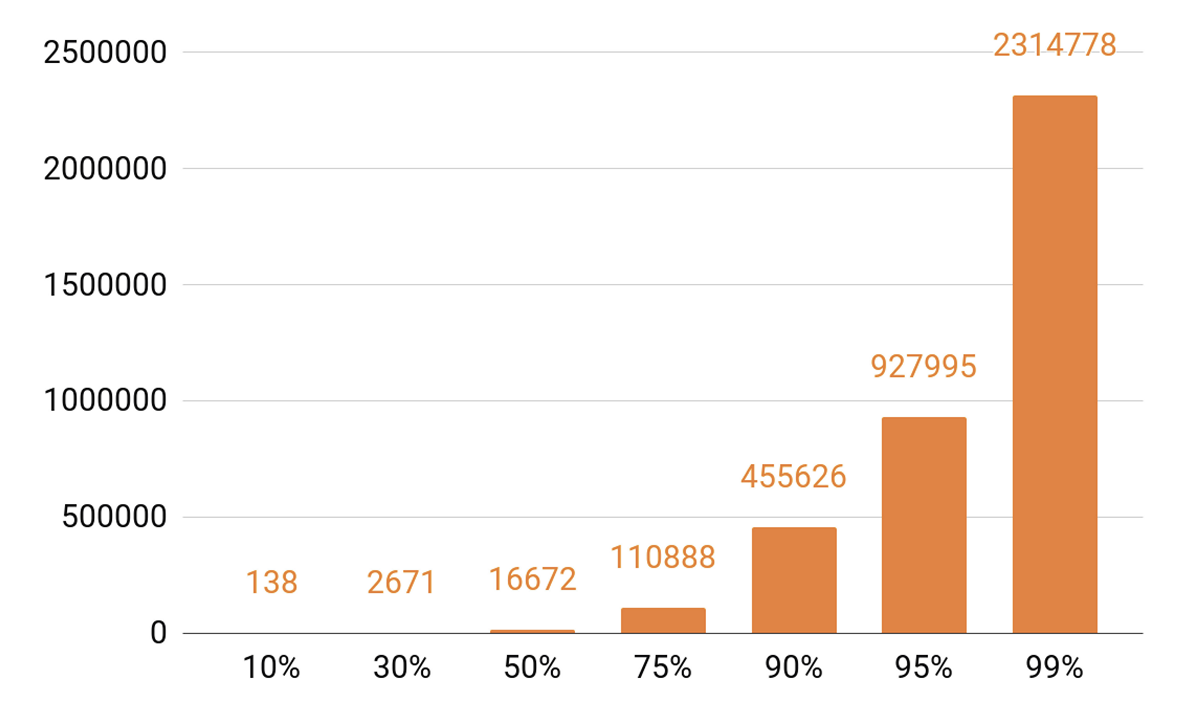
每天大约有140首曲目覆盖全部播放的10%。 如果我们希望我们的缓存服务器的缓存命中率至少达到90%,那么我们就需要50万条轨道来容纳它。 95%-接近一百万首曲目。
发行人要求
在开发下一代发行版时,我们为自己设定了哪些目标?
我们希望一个节点能够容纳10万个连接。 这些都是缓慢的客户端连接:网络上速度不一的一堆浏览器和移动应用程序。 同时,与我们所有的系统一样,该服务必须是可扩展的并且具有容错能力。
首先,我们需要扩展群集的带宽,以跟上服务的日益普及并能够提供越来越多的流量。 还必须能够扩展群集缓存的总容量,因为缓存命中率和落入磁道存储中的请求百分比将直接取决于它。
如今,必须能够水平扩展任何分布式系统,即添加计算机和数据中心。 但是我们也想实现垂直扩展。 我们典型的现代服务器包含56个核心,0.5-1 TB的RAM,10或40 Gb的网络接口和十几个SSD磁盘。
说到水平可伸缩性,会产生一个有趣的效果:当您有成千上万的服务器和成千上万的磁盘时,某些东西会不断崩溃。 磁盘故障是很常见的事情,我们每周更换20-30件。 服务器故障不会使任何人感到惊讶;每天要更换2-3辆汽车。 我还必须处理数据中心故障,例如,在2018年发生了三起此类故障,这可能不是最后一次了。
我怎么都这样 设计任何系统时,我们都知道它们迟早会损坏。 因此,我们总是
仔细研究所有系统组件
的故障情况。 处理故障的主要方法是通过数据复制:数个数据副本存储在不同的节点上。
我们还保留网络带宽。 这很重要,因为如果系统的某个组件发生故障,则无法允许其余组件上的负载崩溃。
平衡
首先,您需要学习如何在数据中心之间平衡用户查询并自动进行。 这是在您需要进行网络工作或数据中心发生故障的情况下。 但是,数据中心内部也需要平衡。 而且我们希望在节点之间分配请求不是随机的,而是权重。 例如,当我们上载服务的新版本并希望平滑地输入新节点进行轮换时。 权重在压力测试中也有很大帮助:我们增加了权重并在节点上施加了更大的负载,以了解其功能的局限性。 当节点在负载下发生故障时,我们会迅速将重量归零,并使用平衡机制将其从旋转中移除。
从用户到节点的请求路径是什么样的,将考虑平衡的情况返回数据?

用户通过网站或移动应用程序登录并接收曲目的URL:
musicd.mycdn.me/v0/stream?id=...为了从URL中的主机名获取IP地址,客户端与我们的GSLB DNS联系,该GSLB DNS知道我们所有的数据中心和CDN站点。 GSLB DNS为客户端提供数据中心之一的平衡器的IP地址,然后客户端与其建立连接。 平衡器了解数据中心内的所有节点及其权重。 它代表用户建立与节点之一的连接。 我们
使用基于N4Ware的L4平衡器 。 Noda绕过平衡器直接提供用户数据。 在像分销商这样的服务中,传出流量明显高于传入流量。
如果数据中心崩溃,则GSLB DNS会检测到该问题并迅速将其从循环中删除:它将不再向用户提供此数据中心平衡器的IP地址。 如果数据中心中的节点发生故障,则其权重将重置,数据中心内的平衡器将停止向其发送请求。
现在考虑按数据中心内的节点平衡轨道。 我们将数据中心视为独立的自治单位,即使其他所有中心都死亡,它们每个都可以生活和工作。 磁道需要在整个计算机上均匀地平衡,以确保没有负载失真,并将它们复制到不同的节点。 如果一个节点发生故障,则应在其余节点之间平均分配负载。
这个问题可以用
不同的方法解决 。 我们决定采用
一致的散列 。 我们将轨道标识符的散列的整个可能范围包装在一个环中,然后将每个轨道显示在该环上的某个点。 然后,我们将环的范围或多或少均匀地分布在集群中的节点之间。 通过将磁道散列到环上的某个点并顺时针移动,可以选择将存储磁道的节点。
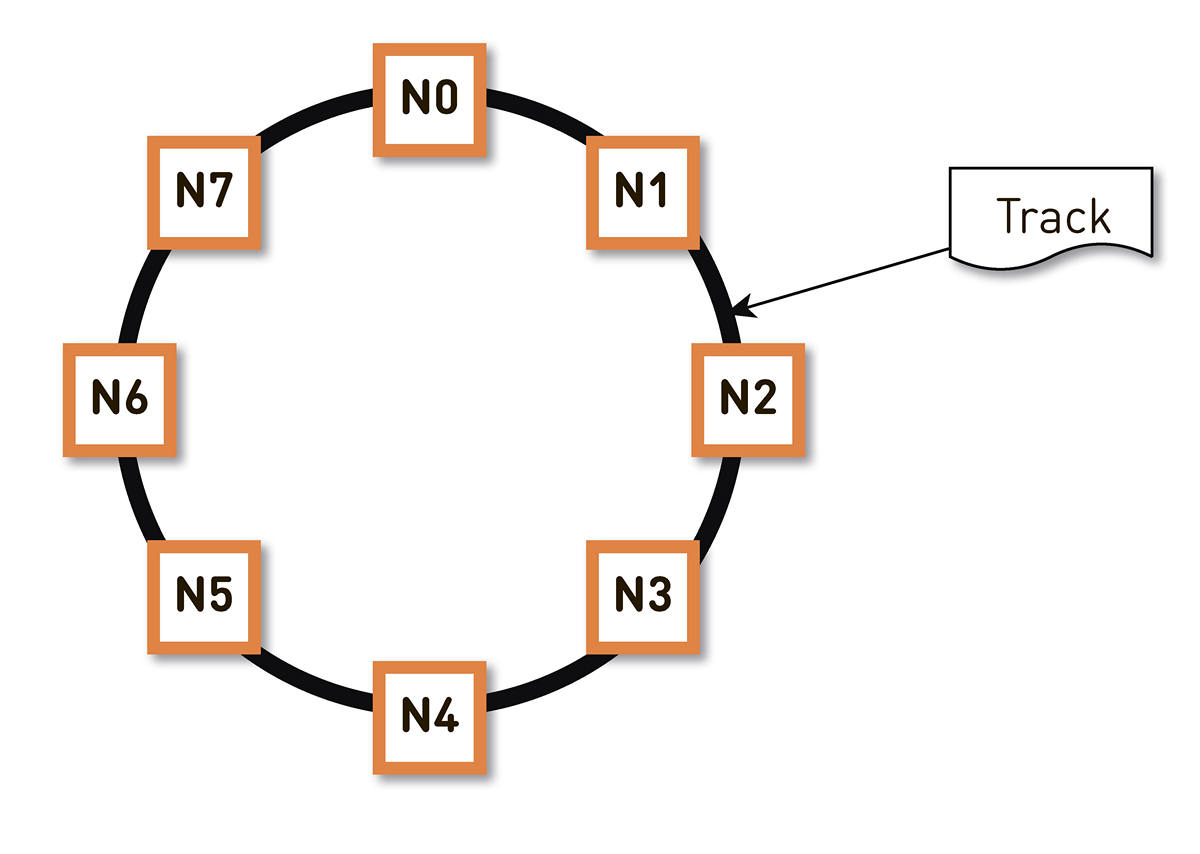
但是这种方案有一个缺点:例如,在节点N2发生故障的情况下,其整个负载将落在环中的下一个副本-N3上。 而且,如果它的性能没有双倍的余量-并且从经济上讲还不合理-那么第二个节点很可能也会遇到糟糕的时间。 N3出现的可能性很高,负载将达到N4,依此类推-整个环上都会发生级联故障。
可以通过增加副本数来解决此问题,但是环中群集的总可用容量会减少。 因此,我们不这样做。 在相同数量的节点的情况下,将环划分为大量随机分布在环周围的范围。 根据上述算法选择轨道的副本。

在上面的示例中,每个节点负责两个范围。 如果其中一个节点发生故障,则其整个负载将不会位于环网中的下一个节点上,而是会在群集的其他两个节点之间分配。
环是根据算法中的一小部分参数计算得出的,并在每个节点上确定。 也就是说,我们不将其存储在某种配置中。 我们在生产中有十万多个这样的范围,并且在任何节点发生故障的情况下,负载在所有其他活动节点之间绝对均匀地分布。
在具有一致哈希的系统中,返回给用户的轨迹是什么样的?
用户通过L4平衡器到达随机节点。 节点选择是随机的,因为平衡器对拓扑一无所知。 但是,集群中的每个副本都知道这一点。 收到请求的节点将确定它是否是所请求轨道的副本。 如果不是,它将使用其中一个副本切换到代理模式,并与其建立连接,然后在其本地存储中搜索数据。 如果轨道不存在,则副本将其从轨道存储中拉出,将其保存到本地存储中并提供代理,该代理会将数据重定向到用户。
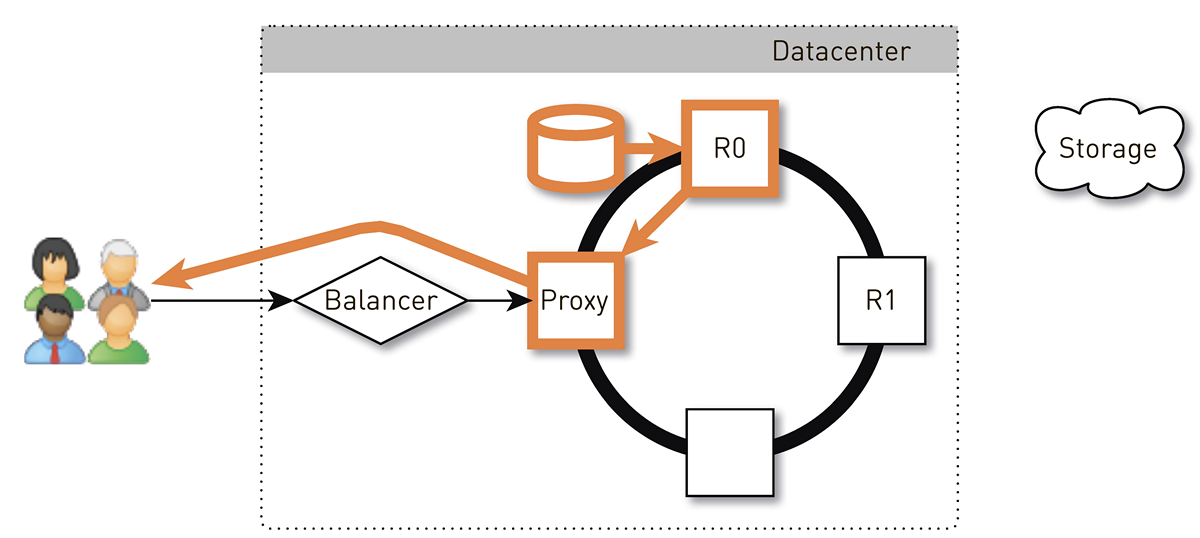
如果副本中的驱动器发生故障,则来自存储的数据将直接传输给用户。 如果该副本失败,则代理会知道该轨道的所有其他副本,它将与另一个活动副本建立连接并从中接收数据。 因此,我们保证,如果用户请求一个曲目并且至少有一个副本处于活动状态,那么他将收到响应。
节点如何工作?
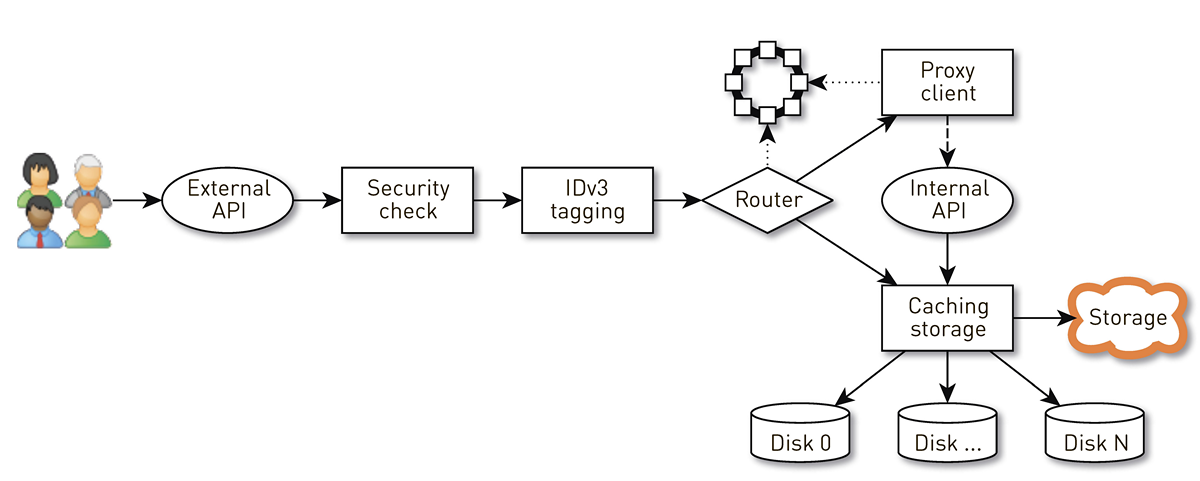
节点是用户请求经过的一组阶段中的管道。 首先,请求转到外部API(我们通过HTTPS发送所有内容)。 然后验证请求-验证签名。 然后,如有必要,例如在购买曲目时,将构造IDv3标签。 请求进入路由阶段,在此阶段根据群集拓扑确定如何返回数据:当前节点是该轨道的副本,还是我们将从另一个节点进行代理。 在第二种情况下,节点通过代理客户端通过内部HTTP API建立与副本的连接,而无需验证签名。 副本会在本地存储中搜索数据,如果找到了磁道,则会从磁盘上将其提供给副本。 如果没有,它将从存储中提取曲目,缓存并提供。
节点负载
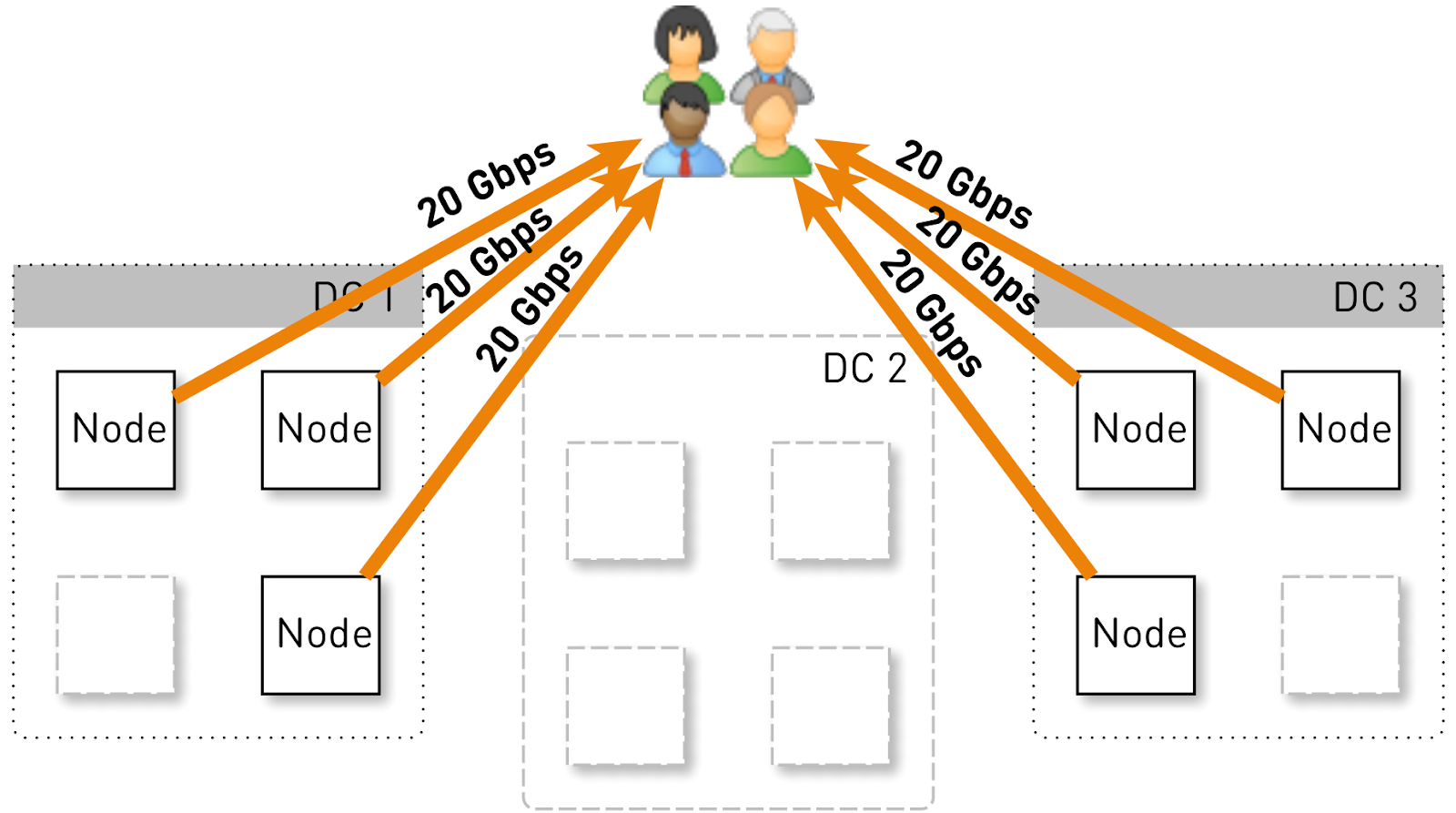
让我们估计一个节点在此配置中应承担的负载。 让我们有三个分别有四个节点的数据中心。

整个服务应服务于120 Gbit / s,即每个数据中心40 Gbit / s。 假设网络管理员进行了操作或发生了事故,并且剩下两个数据中心DC1和DC3。 现在它们每个都应该提供60 Gbit / s。 但是,这取决于开发人员进行一些更新,在每个数据中心中还剩3个活动节点,每个活动节点应提供20 Gbit / s的速度。
但是最初在每个数据中心中有4个节点。 如果我们在数据中心中存储两个副本,则概率为50%,接收到请求的节点将不是所请求轨道的副本,而是将代理数据。 也就是说,代理了数据中心内部一半的流量。
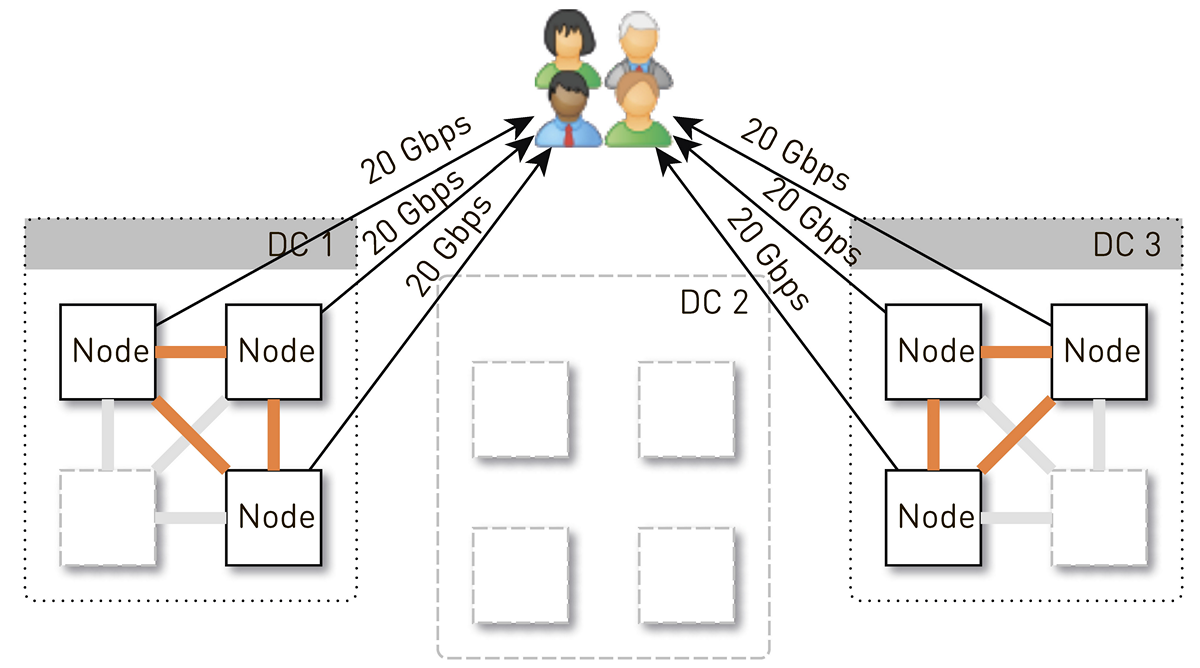
因此,一个节点应为用户提供20 Gb / s。 其中,它从数据中心的邻居那里拉出10 Gb / s。 但是该方案是对称的:节点向数据中心的邻居提供相同的10 Gb / s。 事实证明,有30 Gbit / s的数据从节点中流出,其中20 Gbit / s本身应提供服务,因为它是所请求数据的副本。 此外,数据将来自磁盘或RAM,RAM包含约5万条“热”磁道。 根据我们的播放统计信息,这使您可以从磁盘上删除60-70%的负载,并且将保持大约8 Gb / s的速度。 该线程有能力交付十几个SSD。
节点上的数据存储
如果将每个轨道放在单独的文件中,那么管理这些文件的开销将是巨大的。 即使重新启动节点并扫描磁盘上的数据,也要花费数分钟甚至数十分钟。
这种方案的局限性不太明显。 例如,您只能从一开始就加载曲目。 而且,如果用户要求从中间播放并丢失了缓存,那么在将数据从轨道存储库加载到所需位置之前,我们将无法发送单个字节。 而且,即使它们是在第三分钟内退出收听的巨型有声读物,我们也只能存储整个轨道。 它将继续使磁盘承受自重,浪费昂贵的空间并减少该节点的缓存命中率。
因此,我们以完全不同的方式执行此操作:将磁道分为256 KB的块,因为这与SSD中的块大小相关,并且我们已经在使用这些块。 1 TB的磁盘包含400万个块。 节点中的每个磁盘都是一个独立的存储,并且每个磁道的所有块都分布在所有磁盘上。
我们没有立即采用这种方案,起初,一个磁道的所有块都放在一个磁盘上。 但这导致磁盘之间的负载严重失真,因为如果流行磁道碰到了其中一个磁盘,则所有对其数据的请求都将到达一个磁盘。 为避免这种情况,我们将每个磁道的块分布在所有磁盘上,以平衡负载。
此外,我们不会忘记我们拥有大量的RAM,但是我们决定不进行语义缓存,因为我们在Linux中拥有出色的页面缓存。
如何在磁盘上存储块?
首先,我们决定获取一个只有磁盘大小的巨型XFS文件,并将所有块放入其中。 然后这个想法就可以直接与块设备一起使用。 我们实现了这两种选择,并进行了比较,结果表明,直接与块设备一起使用时,记录速度提高了1.5倍,响应时间降低了2-3倍,系统总负载降低了2倍。
索引
但这还不足以存储块;您需要维护从音乐曲目块到磁盘上块的索引。

事实证明,它非常紧凑,一个索引条目仅占用29个字节。 对于10 TB的存储,索引略大于1 GB。
这里有一个有趣的观点。 在每个这样的记录中,您必须存储整个轨道的总大小。 这是反规范化的经典示例。 原因是,根据HTTP范围响应中的规范,我们必须返回资源的总大小,并形成Content-length标头。 如果不是这样,那么一切将更加紧凑。
我们对索引提出了一些要求:要快速工作(最好存储在RAM中),要紧凑且不占用页面缓存空间。 另一个索引应该是持久的。 如果丢失它,我们将丢失有关磁盘上哪个位置存储了哪个磁道的信息,这无异于清洁磁盘。 总的来说,我希望以某种方式取代长时间未使用的旧街区,以便为更流行的曲目腾出空间。 我们选择了
LRU拥挤策略 :每分钟强制删除一次块,我们保留1%的空闲块。 当然,索引结构必须是线程安全的,因为每个节点有10万个连接。 从我们的
one-nio开源库中的
SharedMemoryFixedMap可以理想地满足所有这些条件。
我们将索引放在
tmpfs ,它可以快速运行,但是有细微差别。 机器重新启动时,
tmpfs上的所有内容(包括索引)都将丢失。 另外,如果由于
sun.misc.Unsafe而使我们的进程崩溃,则尚不清楚该索引处于什么状态。 因此,我们每小时进行一次演员表投放。 但这还不够:由于我们使用块拉伸,因此我们必须支持
WAL ,在其中可以编写有关拉伸块的信息。 在恢复期间,需要以某种方式对有关强制转换和WAL中的块的条目进行排序。 为此,我们使用生成块。 它扮演全局事务计数器的角色,并在每次索引更改时递增。 让我们看一个例子。
取得一个包含三个条目的索引:两个磁道1块和一个磁道2块。
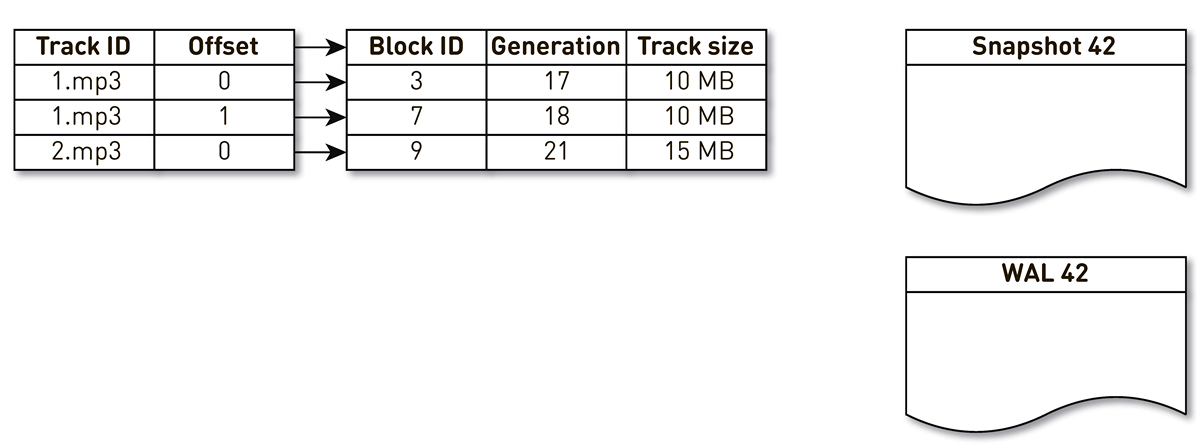
创建索引的流被此索引唤醒和迭代:第一个和第二个元组落入该索引。 然后,拥挤的流程转向索引,意识到很长一段时间未访问第七个块,并决定将其用于其他用途。 该过程将阻止该块,并将记录写入WAL。 他进入第9街区,看到他已经很长时间没有联系了,并且还把他标记为拥挤。 用户在这里访问系统,发生缓存未命中-请求我们没有的跟踪。 我们将此轨道的块保存在我们的存储库中,覆盖块9。 在这种情况下,世代增加并等于22。接下来,创建模具的过程被激活,该过程尚未完成其工作,到达最后一条记录并将其写入模具。 结果,索引中有两个实时记录,演员表和WAL。
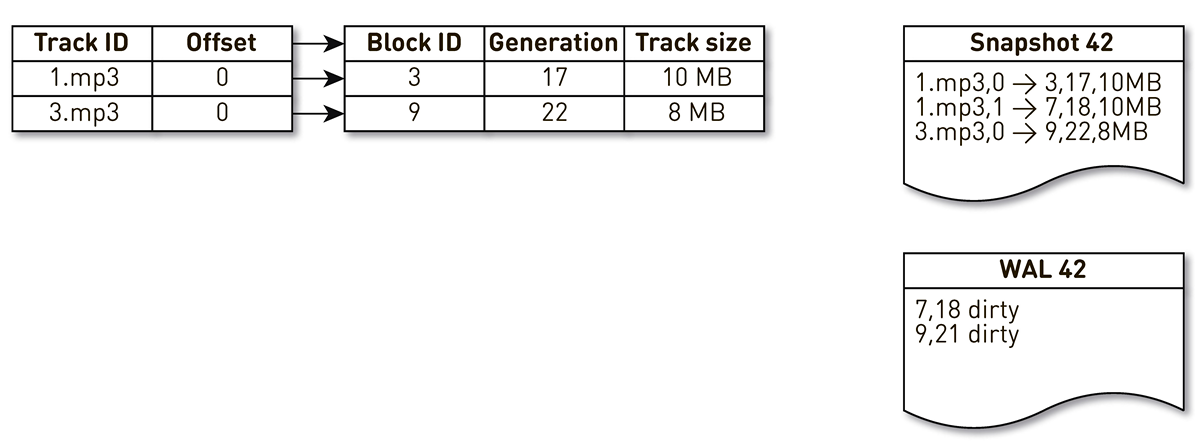
当前节点掉落时,它将恢复索引的初始状态,如下所示。 首先,扫描WAL并构建脏块图。 该卡存储从该块编号到该块被替换时的代的映射。
之后,我们开始使用地图作为过滤器遍历模具。 我们看一下演员表的第一条记录,它与3号区块有关。 肮脏的人中没有提到他,这意味着他还活着并进入了指数。 我们在第18代中到达了第7块,但是肮脏的块图告诉我们,仅在第18代中,该块就被挤出了。 因此,它不属于索引。 我们到达最后一条记录,该记录描述了22代的块9的内容。 脏块图中提到了此块,但之前已将其替换。 因此,它可用于新数据并进入索引。 目标已实现。
最佳化
但这还不是全部,我们会深入探讨。
让我们从页面缓存开始。 我们最初指望它,但是当我们开始对第一个版本进行负载测试时,
事实证明页面缓存命中率未达到20%。 他们建议先解决该问题:在服务一堆连接的同时,我们不存储文件,而是存储块,在这种配置下,使用磁盘的效率是随机的。 我们几乎从不顺序阅读任何内容。 幸运的是,在Linux中,有一个
posix_fadvise调用可以让您告诉内核我们将如何使用文件描述符-特别是,我们可以说不需要传递
POSIX_FADV_RANDOM标志来进行
POSIX_FADV_RANDOM读。 该系统调用可通过
one-nio进行 。 在操作中,我们的缓存命中率为70-80%。 从磁盘读取的物理数据减少了2倍以上,HTTP响应延迟减少了20%。
让我们走得更远。该服务具有相当大的堆大小。为了简化处理器的TLB缓存,我们决定在Java流程中加入“大页面”。结果,我们在垃圾回收时间上获得了可观的利润(GC时间/安全点总时间减少了20-30%),内核加载变得更加均匀,但是对HTTP延迟图没有任何影响。突发事件
服务启动后不久,发生了唯一(到目前为止)事件。工作日结束后的一个晚上,有关播放音乐的抱怨得到了支持。用户写道,他们包括了自己喜欢的曲目,但是每隔几秒钟就会听到其他时间和其他民族发出的奇怪音乐,而播放器告诉他们这首曲是他们喜欢的曲目。很快,搜索范围缩小到了一辆车,这给了它一些奇怪的东西。我们从日志中发现它是最近重新启动的。为简化起见,我们有两个磁盘和索引来描述块的内容。一个索引指出,Daft Punk轨道的第四个块位于sdc磁盘的第2块中,而Stas Mikhailov轨道的零块位于sdd磁盘的零个块中。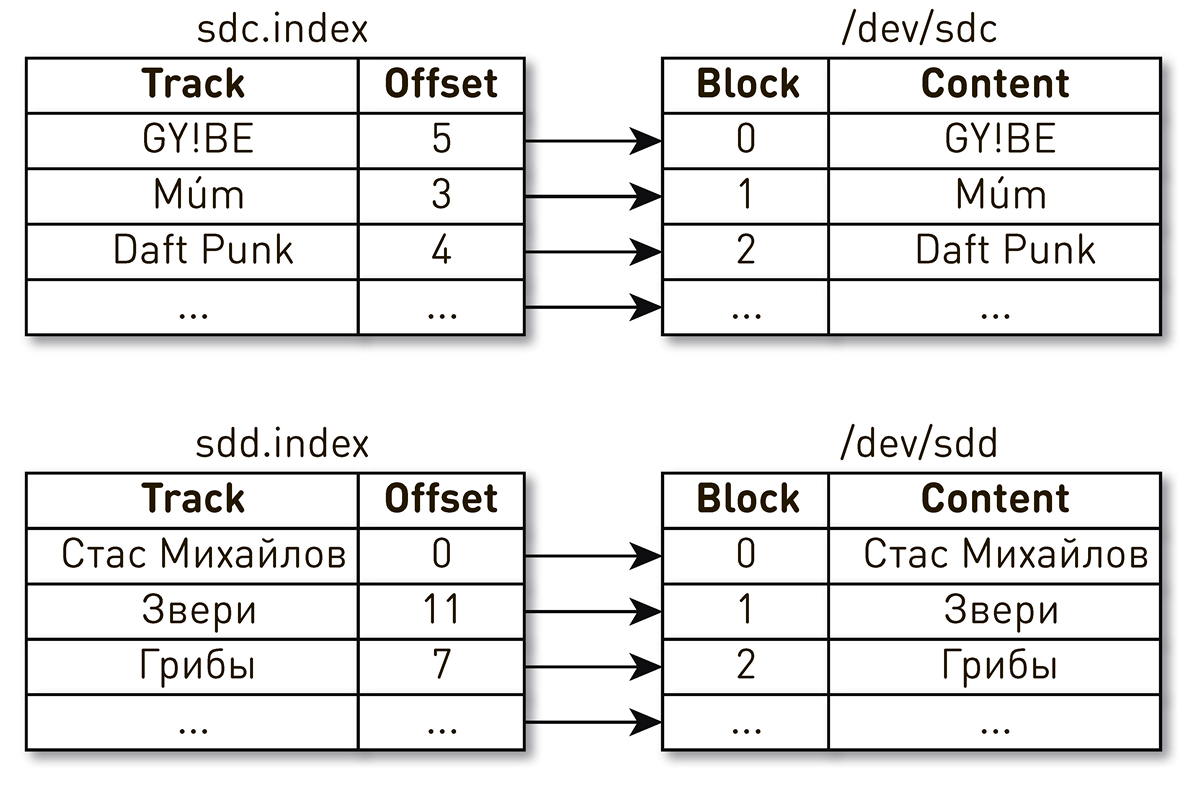 事实证明,重新启动计算机后,驱动器名称更改了位置,并随之而来。此问题在Linux中是众所周知的:如果服务器中有多个磁盘控制器,则不能保证磁盘的命名顺序。
事实证明,重新启动计算机后,驱动器名称更改了位置,并随之而来。此问题在Linux中是众所周知的:如果服务器中有多个磁盘控制器,则不能保证磁盘的命名顺序。 解决方法很简单。磁盘有几种不同类型的永久性ID。我们根据磁盘的序列号使用WWN,并使用它们来识别索引,快照和WAL。这并不排除磁盘本身的改组,但是无论它们如何改组,都不会违反磁盘上的索引映射,并且我们将始终提供正确的数据。
解决方法很简单。磁盘有几种不同类型的永久性ID。我们根据磁盘的序列号使用WWN,并使用它们来识别索引,快照和WAL。这并不排除磁盘本身的改组,但是无论它们如何改组,都不会违反磁盘上的索引映射,并且我们将始终提供正确的数据。事件分析
在这样的分布式系统中,问题的分析是困难的,因为用户请求经历了许多阶段并且跨越了节点的边界。对于CDN,一切都会变得更加复杂,因为对于CDN,上游是家庭数据中心。会有很多这样的希望。而且,该系统为数十万个用户连接提供服务。很难理解在哪个阶段处理特定用户的请求时会出现问题。我们这样简化了我们的生活。在登录时,我们用类似于Open Tracing和Zipkin的标签标记所有请求。标签包括用户的标识符,请求和请求的轨道。流水线内的此标记与所有与当前连接有关的数据和请求一起发送,并且在节点之间作为HTTP头发送,并由接收方恢复。当我们需要解决问题时,我们将打开调试,记录标记,查找与特定用户相关的所有记录或进行跟踪,进行汇总并找出整个集群如何处理请求。传送资料
考虑从磁盘向套接字发送数据的典型方案。似乎没有什么复杂的事情:选择缓冲区,从磁盘读取缓冲区,然后将缓冲区发送到套接字。 ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
这种方法的问题之一是此处隐藏了两个隐藏的数据副本:FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
幸运的是,Linux sendfile()中有一个调用,使您可以要求内核直接从特定偏移量将文件中的数据发送到套接字,而无需复制到用户空间。当然,可以通过one-nio进行此调用。在负载测试中,我们在一个节点上启动了用户流量,并从相邻节点强制代理,它们仅通过以下方式发送数据:使用sendfile()时10 Gb / s的处理器负载sendfile()接近于0,但是对于用户空间SSL套接字,我们无法利用优势sendfile(),我们别无选择,只能通过缓冲区从文件发送数据。在这里,我们还有另一个惊喜。如果您深入研究源SocketChannel和FileChannel,或使用Async Profiler而在这样的返回数据的过程poprofilirovat系统,迟早你到了类sun.nio.ch.IOUtil,其归结所有呼叫read(),并write()在这些通道上。这样的代码隐藏在那里。 ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
这是本地缓冲区的池。当从堆中的文件中ByteBuffer读取数据时,标准库首先从该池中获取一个缓冲区,将数据读入其中,然后将其复制到您的堆中ByteBuffer,然后将本机缓冲区返回到该池中。写入套接字时,会发生相同的事情。有争议的方案。在这里,一位尼奥再次来营救。我们创建一个分配器MallocMT-实际上,这是一个内存池。如果我们有SSL,并且我们被迫通过缓冲区发送数据,则选择Java堆之外的缓冲区,将其包装ByteBuffer,从FileChannel该缓冲区读取而不进行额外复制,然后写入套接字。然后,我们将缓冲区返回给分配器。 final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
每个节点100,000个连接
但是,在较低级别上的合理实施并不能保证系统的成功。这里还有另一个问题。每个节点上的传送器最多可服务10万个同时连接。如何在这样的系统中组织计算?首先想到的是为每个客户端或连接创建执行线程,然后在其中依次执行管道阶段。如有必要,请阻塞,然后继续前进。但是,使用这种方案,上下文切换和流堆栈的成本将过高,因为我们正在谈论分发者,并且有很多流。因此,我们走了另一条路。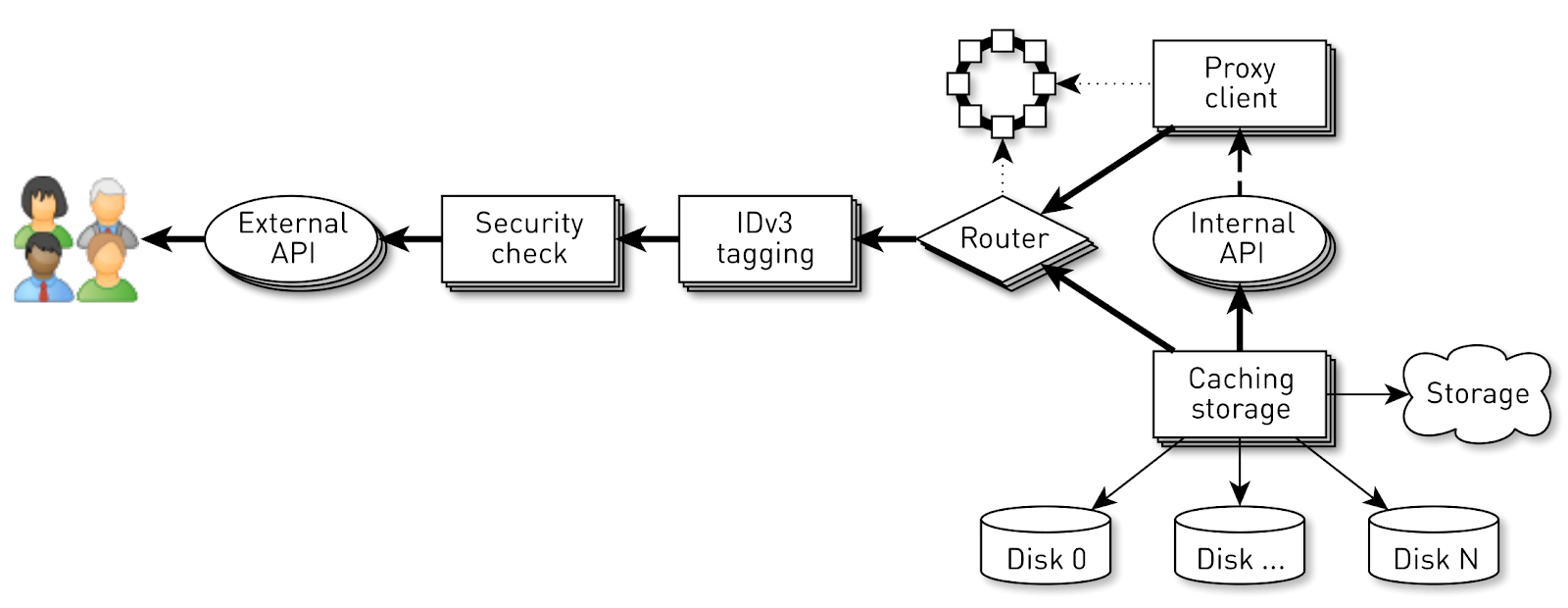 为每个连接创建一个逻辑管道,该逻辑管道包括彼此异步交互的各个阶段。每个阶段都有一个转弯,用于存储传入的请求。对于阶段的执行,使用小型公共线程池。如果您需要处理请求队列中的消息,我们将从池中获取一个流,处理该消息,然后将流返回到池中。使用此方案,数据从存储推送到客户端。但是这样的方案并非没有缺陷。后端比用户连接快得多。当数据通过管道时,它以最慢的速度累积,即在将块写入客户端连接套接字的阶段。迟早,这将导致系统崩溃。如果您尝试在这些阶段限制队列,那么所有内容都会立即停止,因为到用户套接字的链中的管道将被阻塞。并且由于它们使用共享线程池,因此它们将阻塞其中的所有线程。需要背压。为此,我们使用喷射流。该方法的本质是订阅者使用需求来控制来自发布者的数据速度。需求是指订户准备处理多少数据以及已经发出信号的先前需求。发布者有权发送数据,但目前不超过已累积的总需求减去已发送的数据。因此,系统在推拉模式之间动态切换。在推送模式下,订阅者比发布者快,这意味着发布者始终对订阅者的需求不满意,但没有数据。数据一出现,他就立即将其发送给订户。当发布者比订阅者快时,将出现拉模式。也就是说,发布者乐于发送数据,只有需求为零。订阅者说准备好进行更多处理后,发布者会立即向其发送一部分数据,作为需求的一部分。我们的输送机变成喷射流。每个阶段都将成为上一个阶段的发布者和下一个阶段的订阅者。射流的界面看起来非常简单。
为每个连接创建一个逻辑管道,该逻辑管道包括彼此异步交互的各个阶段。每个阶段都有一个转弯,用于存储传入的请求。对于阶段的执行,使用小型公共线程池。如果您需要处理请求队列中的消息,我们将从池中获取一个流,处理该消息,然后将流返回到池中。使用此方案,数据从存储推送到客户端。但是这样的方案并非没有缺陷。后端比用户连接快得多。当数据通过管道时,它以最慢的速度累积,即在将块写入客户端连接套接字的阶段。迟早,这将导致系统崩溃。如果您尝试在这些阶段限制队列,那么所有内容都会立即停止,因为到用户套接字的链中的管道将被阻塞。并且由于它们使用共享线程池,因此它们将阻塞其中的所有线程。需要背压。为此,我们使用喷射流。该方法的本质是订阅者使用需求来控制来自发布者的数据速度。需求是指订户准备处理多少数据以及已经发出信号的先前需求。发布者有权发送数据,但目前不超过已累积的总需求减去已发送的数据。因此,系统在推拉模式之间动态切换。在推送模式下,订阅者比发布者快,这意味着发布者始终对订阅者的需求不满意,但没有数据。数据一出现,他就立即将其发送给订户。当发布者比订阅者快时,将出现拉模式。也就是说,发布者乐于发送数据,只有需求为零。订阅者说准备好进行更多处理后,发布者会立即向其发送一部分数据,作为需求的一部分。我们的输送机变成喷射流。每个阶段都将成为上一个阶段的发布者和下一个阶段的订阅者。射流的界面看起来非常简单。Publisher让我们签名Subscriber ,他只应实现四个处理程序: interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription 使您可以发出需求信号并取消订阅。 没有地方比这容易。
作为数据元素,我们不传递字节数组,而是传递诸如块的抽象。我们这样做是为了尽可能不拖出堆中的数据。块是具有非常有限的接口的数据链接,仅允许您将数据读入ByteBuffer,写入套接字或文件。 interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
块有许多实现:- 最流行的一种实现是在top上,在发生高速缓存命中以及从磁盘发送数据时使用
RandomAccessFile。块仅包含文件链接,此文件中的偏移量和数据大小。它遍历整个管道,到达用户连接套接字,然后在那里变成call sendfile()。也就是说,根本不消耗内存。 - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
尽管此API简单,但按规范它应该是线程安全的,并且大多数方法应该是非阻塞的。我们从官方演员流存储库中的示例中汲取灵感,选择了类型演员模型的精神来选择这条道路。为了使方法调用成为非阻塞方法,在调用方法时,我们将获取所有参数,将其包装在消息中,将其放入队列中以执行,然后返回控制权。来自队列的消息将严格按顺序处理。 没有同步,代码简单明了。状态仅由三个字段描述。每个发布者或订阅者都有一个收集传入消息的邮箱,以及一个在这种类型的所有阶段之间划分的执行程序。AtomicBoolean提供在连续的唤醒之间发生。
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
我们得到了一个完全非阻塞的实现。代码简单而一致的,没有volatile,Atomic*,争,等等。在我们的整个系统中,总共有200个线程可以服务100,000个连接。最后
在生产中,我们有12台机器,而带宽却超过了两倍。正常模式下,每台计算机通过数十万个连接可提供高达10 Gbit / s的速度。我们提供了可伸缩性和弹性。一切都用Java和one-nio编写。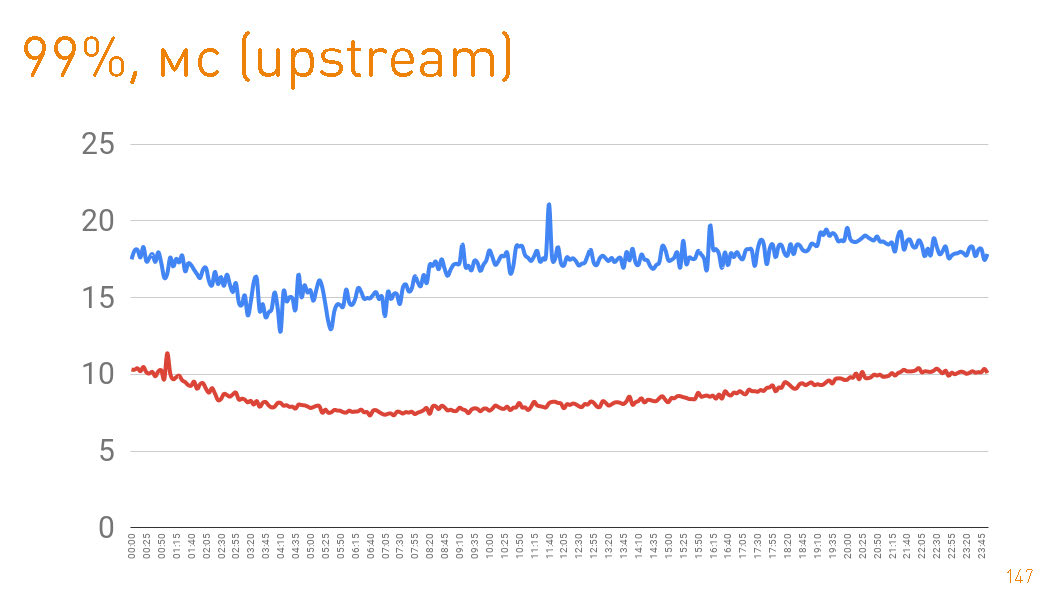 这是一个图形,直到从服务器端给用户的第一个字节为止。 99%小于20 ms。蓝色图是HTTPS数据返回给用户的信息。红色图是通过
这是一个图形,直到从服务器端给用户的第一个字节为止。 99%小于20 ms。蓝色图是HTTPS数据返回给用户的信息。红色图是通过sendfile()HTTP 从副本到代理的数据返回。实际上,生产中的高速缓存命中率为97%,因此这些图描述了跟踪存储库的延迟,考虑到PB的数据量,在高速缓存未命中的情况下我们从中提取数据,这也不错。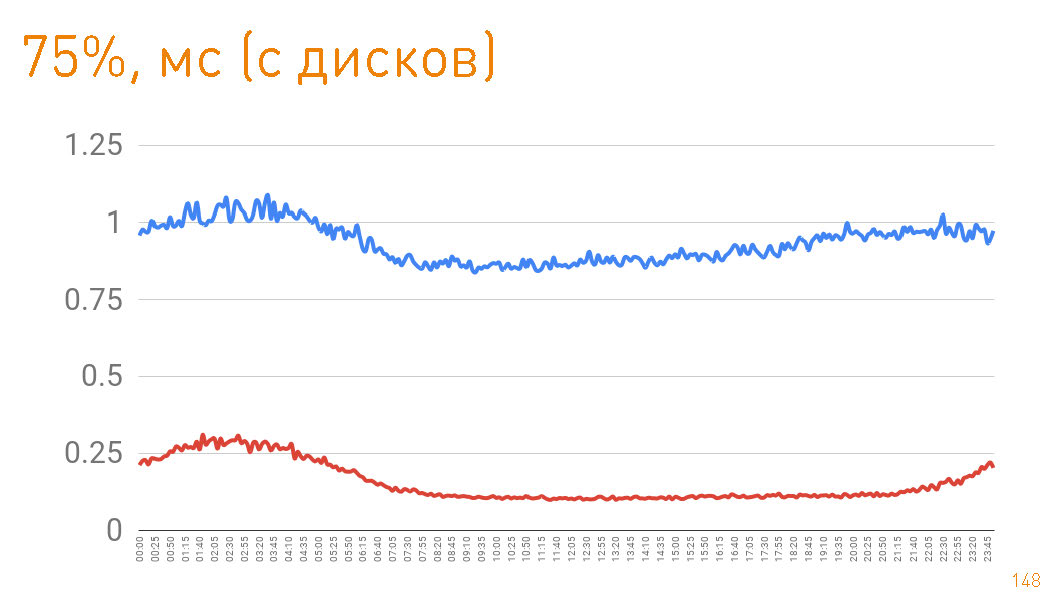 如果从磁盘返回时查看第75个百分位数,则第一个字节将在1毫秒后飞向用户。集群内部的副本以更高的速度通信-它们负责300μs。
如果从磁盘返回时查看第75个百分位数,则第一个字节将在1毫秒后飞向用户。集群内部的副本以更高的速度通信-它们负责300μs。即
代理成本为0.7毫秒。在本文中,我们想演示如何构建可扩展的,高负载的系统,该系统既具有高速又具有出色的容错能力。希望我们成功。