最近,我们
谈到了如何在Google实习。 除了Google之外,我们的学生还可以尝试JetBrains,Yandex,Acronis和其他公司。
在本文中,我将分享我在
JetBrains Research的实习经验,讨论他们在那儿解决的任务,并详细介绍机器学习如何查找程序代码中的错误。

关于我自己
我叫Egor Bogomolov,我是圣彼得堡HSE应用数学和计算机科学本科学位课程的四年级学生。 在最初的三年中,我和同学一样,在学术大学学习,自9月以来,我们与整个系一起搬到了高等经济学院。
第2年后,我在Google苏黎世进行了暑期实习。 我在那里度过了三个月的Android日历团队工作,大部分时间都在做frontend'om和一些UX研究。 我的工作中最有趣的部分是研究日历界面在未来的外观。 事实证明,在实习结束之前我所做的几乎所有工作都最终都在应用程序的主版本中完成了,真是令人高兴。 但是Google的实习主题在上一篇文章中有很好的介绍,因此,我将谈论今年夏天的工作。
什么是JB Research?
JetBrains Research是在各个领域工作的一组实验室:编程语言,应用数学,机器学习,机器人技术等。 在每个领域内都有几个科学小组。 根据我的指导,我最了解机器学习领域中的小组活动。 他们每个人每周举办一次研讨会,小组成员或受邀嘉宾谈论他们在该领域的工作或有趣的文章。 来自HSE的许多学生参加了这些研讨会,因为他们从圣彼得堡HSE校园的主楼穿过马路。
在我们的学士课程中,我们必须从事研究工作(R&D),并每年两次提出研究结果。 通常,这项工作逐渐发展为夏季实习。 我的研究工作也发生了这种情况:今年夏天,我与研究主管Timofey Bryksin在“软件工程中的机器学习方法”实验室实习。 该实验室正在处理的任务包括自动重构建议,为程序员分析代码样式,代码完成以及搜索程序代码中的错误。
我的实习期持续了两个月(7月和8月),秋天,我继续从事研究框架中分配的任务。 我在多个领域工作,我认为其中最有趣的是自动搜索代码中的错误,我想谈一谈。 起点是
Michael Pradel的文章 。
自动错误搜索
现在如何搜索错误?
为什么寻找错误或多或少很清楚。 让我们看看他们现在怎么样。 现代的漏洞检测器主要基于静态代码分析。 对于每种类型的错误,请查找以前发现的可用来确定错误的模式。 然后,为了减少误报的数量,发明了启发式方法,并针对每个个案进行了发明。 既可以在由代码构造的抽象语法树(AST)中,也可以在控制流或数据的图形中搜索模式。
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
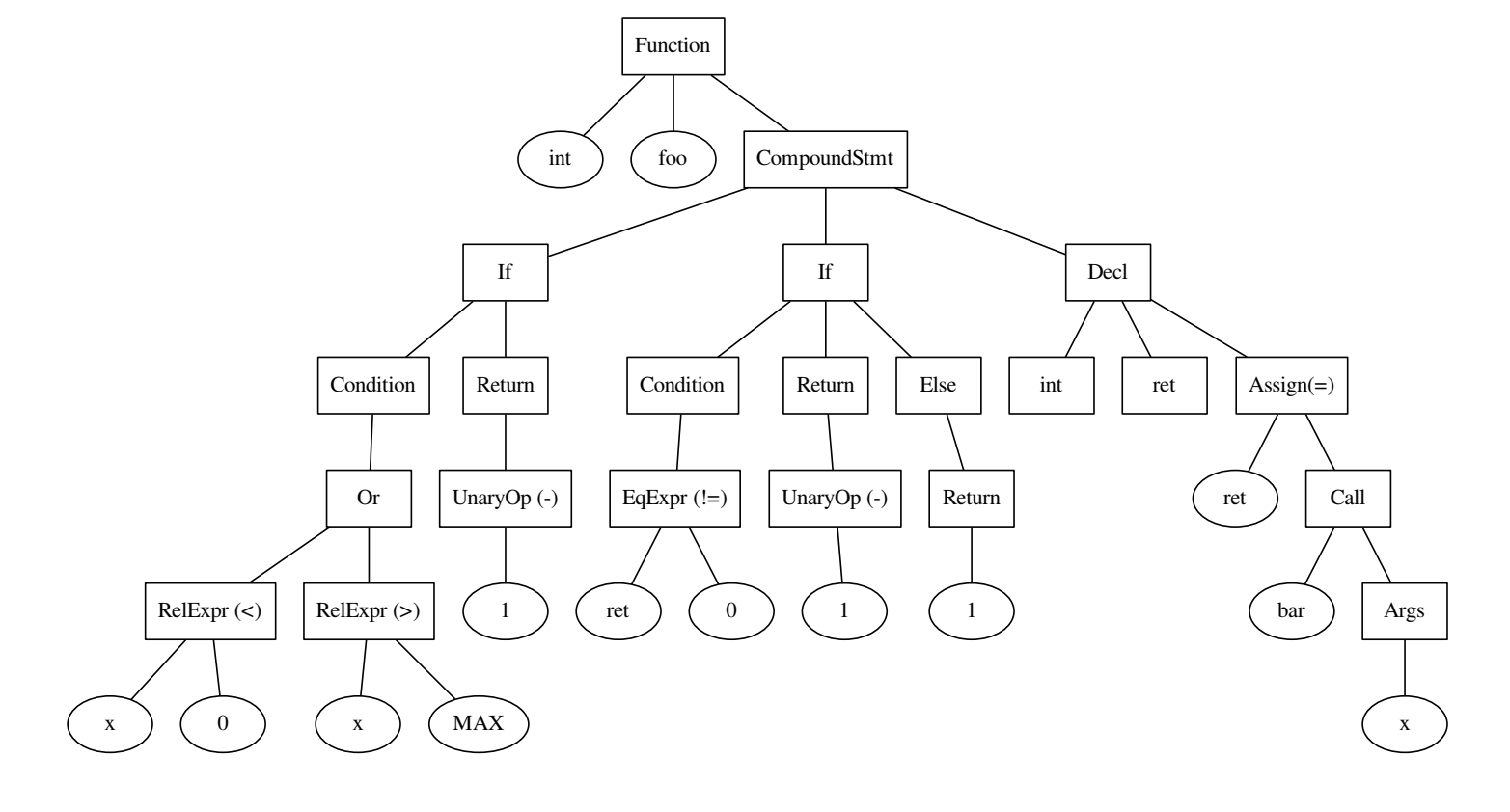
代码和基于它的树。
要了解其工作原理,请考虑一个示例。 错误的种类可以是在C ++中使用=代替==。 让我们看一下下面的代码:
int value = 0; … if (value = 1) { ... } else { … }
条件表达式中有一个错误,而将值赋给变量的第一个=是正确的。 模式来自此处:如果在if条件中使用赋值,则可能是一个错误。 在AST中寻找这种模式,我们可以检测到错误并进行纠正。
int value = 0; … if (value == 1) { ... } else { … }
在更一般的情况下,我们将无法如此轻松地找到一种描述错误的方法。 假设我们要确定操作数的正确顺序。 再次,查看代码片段:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
在第一种情况下,使用1-i是错误的,在第二种情况下,它是完全正确的,这从上下文中可以明显看出。 但是如何以模式的形式描述它呢? 由于错误类型的复杂性,我们必须考虑更大的代码部分并分析越来越多的个别情况。
最后一个激励的例子:有用的信息也包含在方法和变量的名称中。 用某些手动指定的条件来表达甚至更加困难。
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
一个人理解,函数调用中的参数很可能是混杂在一起的,因为我们知道x更像xDim而不是yDim。 但是如何将此报告给检测器呢? 您可以添加某种形式的试探法,例如“变量名是参数名的前缀”,但是假设x通常是宽度而不是高度,因此不再表达。
底线:现代发现错误的方法的问题在于您必须动手做很多工作:确定模式,添加试探法,因此,在检测器中添加对新型错误的支持变得很耗时。 另外,很难使用开发人员在代码中留下的重要信息部分:变量和方法的名称。
机器学习如何提供帮助?
您可能已经注意到,在许多示例中,错误对于人类是可见的,但是很难正式描述。 在这种情况下,机器学习方法通常可以提供帮助。 让我们停止在函数调用中寻找重新排列的参数,并了解我们需要使用机器学习来寻找它们的条件:
- 大量没有错误的示例代码
- 具有给定类型错误的大量代码
- 矢量化代码片段的方法
- 我们将教授的模型可以区分有无错误的代码
我们可以希望,在公共领域中布置的大多数代码中,函数调用中的参数按正确的顺序排列。 因此,对于没有错误的示例代码,您可以获取一些大数据集。 就原始文章的作者而言,它是JS 150K(Java语言中有15万个文件),在我们的案例中是类似的Python数据集。
查找带有错误的代码要困难得多。 但是我们不能寻找别人的错误,而是自己动手! 对于错误类型,您需要指定一个函数,根据正确的代码片段,该函数将使其损坏。 在我们的例子中,重新排列函数调用中的参数。
如何向量化代码?
有了很多好的和坏的代码,我们几乎准备教一些东西。 在此之前,我们仍然需要回答以下问题:如何显示代码片段?
函数调用可以表示为方法名称,方法名称,传递给变量的参数名称和类型的元组。 如果我们学习如何向量化单个标记(变量和方法的名称,在代码中找到的所有“单词”),我们可以将我们感兴趣的标记的向量连接起来,并获得所需的片段向量。
为了使标记向量化,让我们看一下普通文本中的单词如何向量化。 最成功和最受欢迎的方法之一是在2013年提出的word2vec。
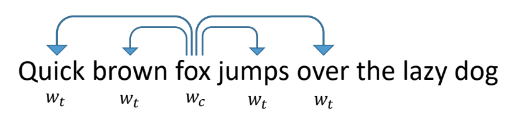
它的工作方式如下:我们教网络预测单词旁边出现的其他单词。 在这种情况下,网络看起来就像是字典大小的输入层,是我们要接收的矢量化大小的隐藏层,而输出层也是字典的大小。 在训练过程中,向网络提供了一个输入单位向量,其中一个单位代替了所讨论的单词(fox),在输出处我们希望获得出现在该单词周围的窗口内的单词(快速,棕色,跳跃,跳过)。 在这种情况下,网络首先将所有单词转换为隐藏层上的向量,然后进行预测。
各个单词的所得向量具有良好的属性。 例如,具有相似含义的词向量彼此接近,向量的和与差是词的“含义”的加法和差。
为了在代码中对令牌进行类似的矢量化处理,您需要以某种方式设置将要预测的环境。 它们可能是来自AST的信息:顶点的类型,遇到的标记,树中的位置。
收到矢量化后,您可以看到哪些标记彼此相似。 为此,计算它们之间的余弦距离。 结果,为Javascript获得了以下相邻向量(数字为余弦距离):
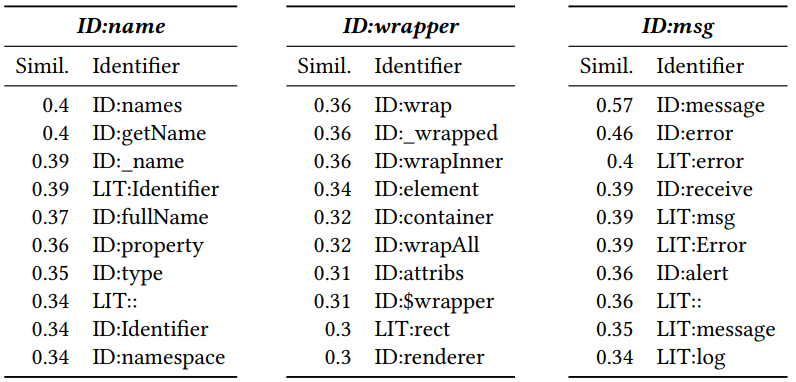
在开头添加的ID和LIT指示令牌是标识符(变量名,方法名)还是文字(常量)。 可以看出,接近是有意义的。
分类器培训
收到单个令牌的矢量化之后,查看具有潜在错误的一段代码非常简单:这是对令牌分类很重要的矢量的串联。 使用ReLU作为激活函数并通过代码删除来训练两层感知器,以减少过度拟合。 学习迅速收敛,生成的模型很小,可以每秒预测数百个示例。 这使您可以实时使用它,稍后将进行讨论。
结果
所得分类器的质量评估分为两部分:对大量人工生成的示例进行评估,以及对少数具有最高预测概率的示例(每个检测器50个)进行人工验证。 三个检测器的结果(重新排列的参数,二进制运算符和二进制操作数的正确性)如下:
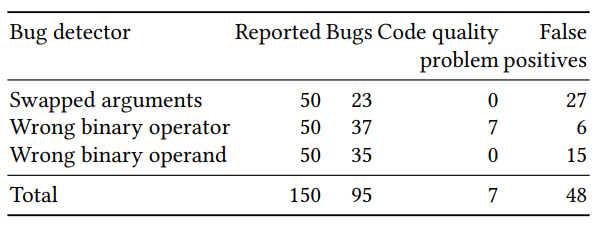
用传统的搜索方法很难找到一些预测的错误。 在对p.done的调用中重新排列了res和err的示例:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
也有没有错误的示例,但是应重命名变量,以免误导试图弄清楚代码的人。 例如,增加宽度和每个宽度似乎不是一个好主意,尽管事实证明这并不是一个错误:
var cw = cs[i].width + each;
Python移植
我参与了将Michael Pradel的工作从js移植到python,然后为PyCharm创建一个插件,该插件基于上述方法实现检查。 我们使用了
Python 150K数据集(GitHub上有15万个Python文件)。
首先,事实证明,在Python中,比javascript中的令牌更多。 对于js,最流行的10,000个令牌占所有遇到的令牌的90%以上,而对于Python,则有必要使用大约40,000个令牌,这导致矢量中令牌的大小增加,这使得移植到插件变得困难。
其次,为Python实现了在函数调用中搜索错误参数并手动查看结果的错误率,我的错误率超过90%,这与js的结果不一致。 在了解了原因之后,事实证明,在javascript中,更多函数与它们的调用在同一文件中声明。 我按照本文作者的示例,最初不允许从其他文件中声明函数,这导致了较差的结果。
在8月底,我完成了Python的实现并编写了插件的基础。 该插件将继续开发,现在我们实验室的学生Anastasia Tuchina正在从事此工作。
您可以找到在存储库Wiki上尝试插件工作方式的步骤。
github上的链接:
带有python实现的存储库带插件的存储库