在本文中,我们使用TLA +模拟和检查了两阶段提交协议。
两阶段提交协议是实用的,如今已在许多分布式系统中使用。 但是,它很短。 因此,我们可以快速对其建模并学到很多东西。 实际上,通过此示例,我们将说明在分布式系统中哪个结果
根本上是
不可能的 。
双阶段提交问题
交易通过
资源管理器(RM) 。 所有RM必须就交易是
完成还是
中止达成一致。
事务管理器(TM)做出最终决定:
commit或
cancel 。 提交的条件是愿意提交所有RM。 否则,该交易应被取消。
建模注意事项
为简单起见,我们在共享内存模型中而不是在消息传递系统中执行仿真。 它还提供了快速的模型验证。 但是我们将非原子性添加到“从邻居节点读取并更新状态”的动作中,以捕获发送消息时的有趣行为。
RM只能读取TM状态并读取/更新其自己的状态。 它无法读取其他资源管理器的状态。 TM可以读取所有RM节点的状态并读取/更新其自己的状态。
定义

第9-10
rmState每个RM的初始
rmState设置为
working ,将TM设置为
init 。
如果所有RM已“准备好”(准备提交),则
canCommit谓词为
true 。 如果RM以结束状态存在,则
canAbort谓词变为
canAbort 。

建模TM很简单。 事务管理器检查提交或取消的可能性-并相应地更新
tmState 。
TM仅在将模型验证开始之前将
TMMAYFAIL常量设置为
true ,TM可能无法使
tmState “不可访问”。 在TLA +标签中,确定原子度,即其粒度。 通过标签F1和F2,我们表示相对于先前的运算符,非原子地(在一段不确定的时间之后)执行了相应的运算符。
RM模型

RM模型也很简单。 由于“工作”状态和“准备状态”是非最终状态,因此RM不确定地在操作之间进行选择,直到达到最终状态为止。 “工作” RM可以进入“中断”或“准备”状态。 “ Prepared” RM期望从TM提交/取消-并采取相应的措施。 下图显示了一个RM的可能状态转换。 但是请注意,我们有几个RM,每个RM都以自己的步调经过其状态,而不知道其他RM的状态。
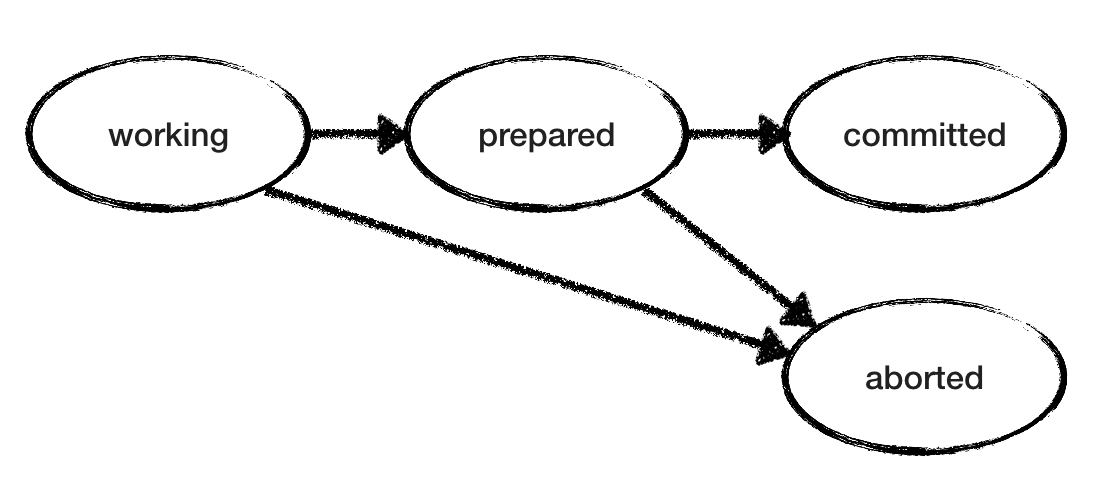
两阶段提交模型

我们需要检查两阶段提交的一致性:这样就不会有不同的RM,其中一个RM表示“ commit”,另一个表示“ abortion”。
Completed谓词可验证协议不会永远挂起:最后,每个RM都达到
committed或
aborted的最终状态。
现在我们准备测试协议模型。 最初,我们设置
TMMAYFAIL=FALSE, RM=1..3 ,以三个RM和一个TM来启动该协议,也就是说,以可靠的配置。 测试模型需要15秒,并表示没有错误。 对于RM动作和TM动作的任何交替,任何可能的协议执行都会满足“
Consistency和“
Completed要求。

现在设置
TMMAYFAIL=TRUE并重新开始检查。 该程序很快产生相反的结果,RM停滞不前,等待来自不可用TM的响应。

我们看到,在
State=4转换RM2被中断,在
State=7转换RM3被中断,在
State=8 TM进入“挂起”状态并下降到
State=9 。 在
State=10系统冻结,因为RM1永远保持在准备状态,等待下降的TM做出决定。
BTM模拟
为避免事务冻结,我们添加了一个备份TM(BTM),如果主TM不可用,该备份可快速控制。 BTM使用与TM相同的逻辑进行决策。 为了简单起见,我们假设BTM不会崩溃。

当我们使用添加的BTM流程测试模型时,会收到一条新的错误消息。

BTM无法接受提交,因为我们的原始条件
canCommit声明必须“准备”所有
RMstates ,并且没有考虑到某些RM在TMB采取控制之前已经从原始TM接收到提交决定的条件。 考虑到这种情况,有必要重写
canCommit的条件。

成功! 当我们测试模型时,我们实现了一致性和完整性,因为BTM可以控制并在TM下降时完成交易。
这是TLA +中的2PCwithBTM模型 (BTM和canCommit的第二行最初没有注释)和
相应的pdf 。
如果RM也失败怎么办?
我们认为RM是可靠的。 现在取消此条件,并查看RM失败时协议的行为。 将“无法访问”状态添加到故障模型。 为了调查行为并模拟间歇性的可用性损失,请让紧急RM恢复并通过从日志中读取其状态来继续工作。 这是另一个RM状态转换图,其中添加了“不可访问”状态,并且转换标记为红色。 下面是RM的修订模型。
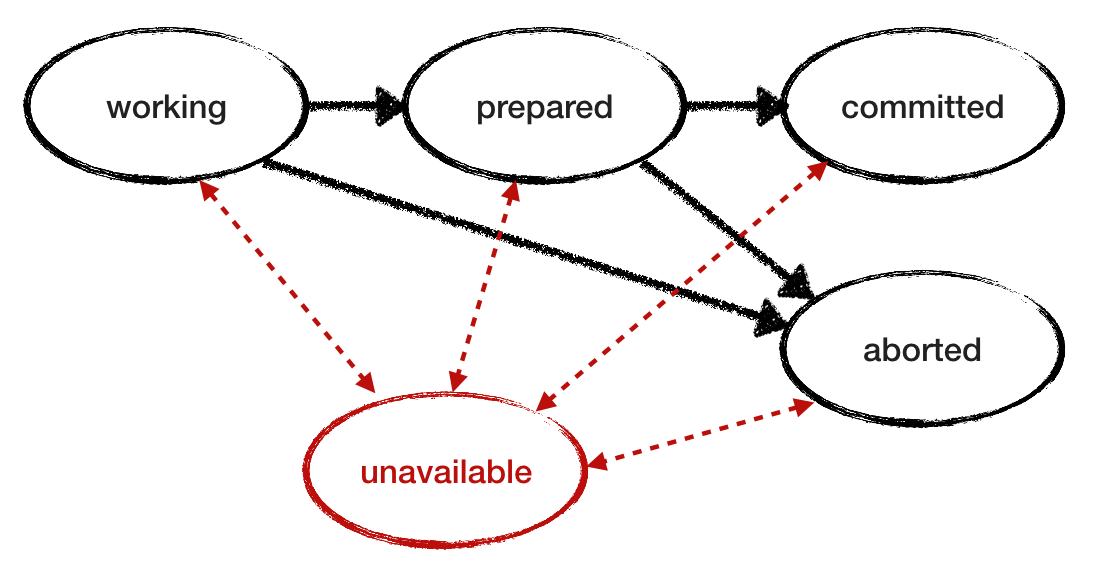

还必须考虑到不可用状态来优化
canAbort 。 如果任何服务处于中断或无法访问状态,TM可以做出“挂断”决定。 如果忽略此条件,则下降且未恢复的RM将中断事务的处理。 当然,同样,您应该考虑RM,RM是从源TM那里学习完成交易的决定的。
模型检查
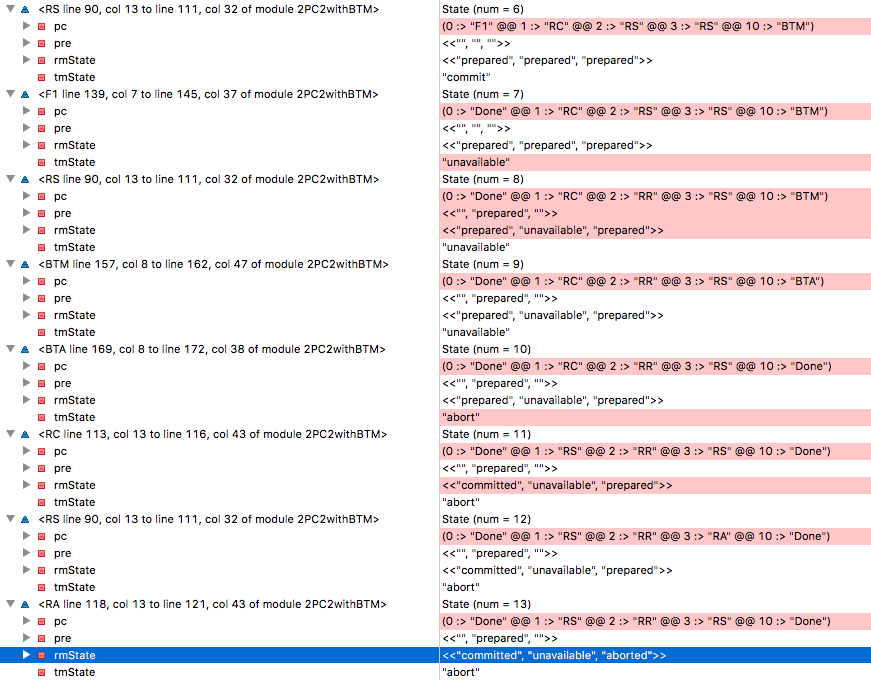
当我们测试模型时,会出现不一致的问题! 怎么会这样 我们追踪痕迹。
在
State=6所有RM都处于准备状态,TM做出完成交易的决定,RM1看到此决定并切换到RC标签,这意味着准备将其状态更改为“完成”。 (记住RM1,这把枪会在最后一幕开火)。 不幸的是,TM在
State=7下降,而RM2在
State=8时不可用。 在第九步中,备用BTM进行控制并读取三个RM的状态为“已准备,不可访问,已准备”-并在第十步中决定取消交易。 还记得RM1吗? 他决定完成交易,因为他收到了原始TM的此类决定,并在步骤11进入了
committed状态。 在
State=13 RM3完成了从BTM中止交易的决定,并进入
aborted状态-现在我们已经失去了与RM1的一致性。
在这种情况下,BTM做出了违反
一致性的决定。 另一方面,如果让BTM等待RM离开不可访问状态,则在节点发生事故时BTM可能永远冻结,这将违反
实现 (进度)条件。
可在此处获得更新的TLA +模型文件以及
相应的pdf 。
不可能FLP
那怎么了 我们偶然地发现了
费希尔,林奇,帕特森(FLP)的
定理,即在具有故障的异步系统中不可能达成共识。
在我们的示例中,BTM无法正确确定RM2是否处于失败状态-并且错误地决定中止事务。 如果仅由原始TM做出决定,那么在识别故障方面的这种不准确性将不是问题。 RM将遵守TM的任何决定,以便保持一致性和进度。
问题是我们有两个决策对象:TM和BTM,它们在不同时间查看RM的状态并做出不同的决策。 信息的这种不对称是分布式系统中所有邪恶的根源。
即使扩展到三相提交,问题也不会消失。
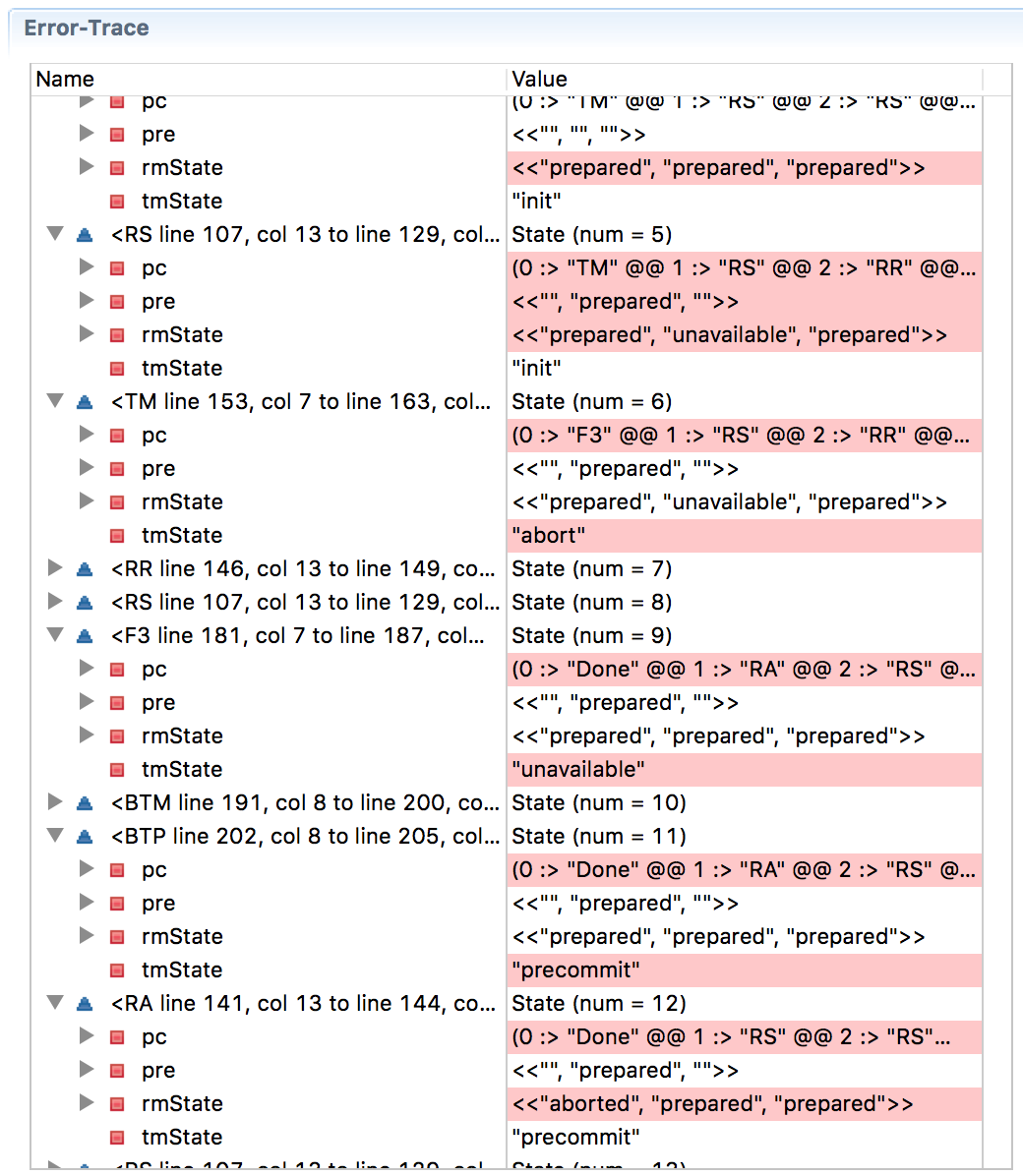
这是一个以TLA + (
pdf版本 )
建模的三阶段提交 ,下面是一个错误跟踪,显示这次违反了进度(在
Wikipedia页面上有关三阶段提交的描述,描述了一种情况,当RM1在提交之前收到决定后冻结,而RM2和RM3提交提交,这会违反一致性)。
Paxos试图使世界变得更美好。

但是,并非一切都丢失了,希望没有死。
我们有Paxos 。 它在FLP定理的框架内巧妙地起作用。 Paxos的创新之处在于,它
始终是
安全的 (即使检测器不准确,异步执行和失败),并且在可能达成共识时
最终完成交易 。
您可以在具有三个Paxos节点的群集上模拟TM,这将解决TM / BTM不一致问题。 或者,正如Gray和Lampport在
有关事务提交共识的
科学文章中所显示的那样,如果RM使用Paxos容器在TM响应的同时存储其决策,那么这将消除标准协议算法中的一个额外步骤。