与任何大公司一样,在Rostelecom中,有一个公司数据仓库(WCD)。 我们的WCD不断增长和扩展,我们在其上构建有用的店面,报表和数据多维数据集。 在某些时候,我们面临这样一个事实,那就是在构建窗口显示时,劣质数据会干扰我们,导致生成的单位无法与源系统的单位融合,从而导致对业务的了解不足。 例如,外键(外键)中具有Null值的数据未连接到其他表中的数据。
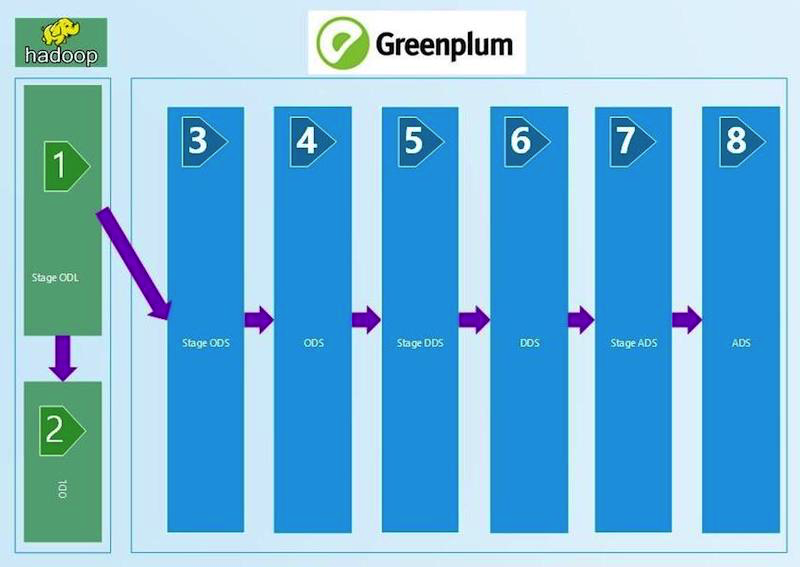
WCD的简图:
我们了解,为了确保对数据质量的信心,我们需要定期进行对帐流程。 当然,它是自动化的,并允许每个技术级别在垂直和水平方向上都确保数据的质量及其融合。 结果,我们同时审查了三个现成的平台来管理来自各个供应商的对帐,并编写了我们自己的平台。 我们在这篇文章中分享我们的经验。
成品平台的缺点是众所周知的:价格,有限的灵活性,缺乏添加和修复功能的能力。 优点-mdm零件(黄金数据等),培训和支持也已关闭。 在意识到这一点之后,我们很快就忘记了购买,而专注于开发我们的解决方案。
我们系统的核心是用Python编写的,用于存储,记录和存储结果的元数据数据库是用Oracle编写的。 Python有很多库,我们为Hive(pyhive),GreenPlum(pgdb),Oracle(cx_Oracle)连接使用了必要的最小值。 连接其他类型的源也应该不是问题。
我们将生成的数据集(结果集)放入生成的Oracle表中,可以随时评估对帐的状态(SUCCESS / ERROR)。 在生成结果可视化的结果表上配置了APEX,便于维护和管理。
要在存储库中运行检查,将使用Informatica乐团,该乐团下载数据。 收到下载成功状态后,此数据将自动开始进行验证。 查询参数化和WCD元数据的使用允许对表集使用查询协调模板。
现在介绍在此平台上实现的对帐。
我们从技术对帐开始,该对帐将WCD的输入和层上的数据量与某些过滤器的应用进行比较。 我们获取WCD输入中的ctl文件,从中读取记录数,并将其与Stage ODL和/或Stage ODS上的表(图中的1、2、3)进行比较。 验证标准以记录数(计数)的相等性定义。 如果数量收敛,则结果为SUCCESS(成功),否-ERROR(错误)并手动分析错误。
与记录数相比,这种技术对帐链扩展到了ADS层(图中为8)。 过滤器在层之间进行更改,这取决于加载类型-DIM(参考书),HDIM(历史参考书),FACT(实际应计表)等-以及SCD和层的版本控制。 离显示层越近,我们使用的过滤算法就越复杂。
还对Python中的输入进行了技术检查,以检测关键字段中的重复项。 在我们的GreenPlum中,数据库系统工具不保护关键字段(PK)免受重复。 因此,我们编写了一个Python脚本,该脚本从PK元数据中读取已加载表的字段,并生成一个SQL脚本,以检查是否缺少这些字段。 这种方法的灵活性使我们可以使用由一个或几个字段组成的PK,这非常方便。 这种对帐扩展到STG ADS层。
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
唯一性对帐python代码示例。 调用,连接参数的传输以及将结果放入结果表中都是由Python中的控制模块执行的。缺少NULL值的对帐与上一个类似,在Python中也是如此。 我们从不能包含空(NULL)值的加载元数据字段中读取内容,并检查其填充性。 在DDS层之前使用对帐(第一个图中的6)。
在存储的入口处,还对到达输入的数据包进行趋势分析。 新包到达时接收的数据量将输入到历史表中。 随着数据量的重大变化,负责表和SI(源系统)的人员会通过邮件(按计划)收到通知,在数据包进入仓库之前发现APEX中的错误,并通过SI找出原因。
在STG(STAGE)_ODS和ODS(操作数据层)(图中的3和4)之间,出现技术删除字段(删除指示符= Deleted_ind),我们还通过SQL查询检查其正确性。 缺少的输入应在ODS中标记为已删除。
预计对帐脚本的结果将显示零错误。 在给出的对帐示例中,参数〜#PKG_ID#〜通过Python控制块传递,类型〜P_JOIN_CONDITION〜和〜PERIOD_COL〜的参数从表元数据,表名称本身〜TABLE〜从启动参数填充。
以下是参数化对帐。 HDIM类型的STG_ODS和ODS之间的示例SQL协调代码:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~
用于HDIM类型的STG_ODS和ODS之间的SQL协调代码示例,其参数替换为:
从ODS开始,历史记录保存在目录中,因此,必须检查历史记录是否存在交叉点和间隙。 这是通过计算历史记录中错误值的数量并将错误的结果数量写入结果表来完成的。 如果表中有历史记录错误,则必须手动搜索它们。 核对取决于下载的类型-首先是HDIM(历史参考指南)。 我们对直到ADS层的目录的历史正确性进行核对。
在DDS层(第一个图中的6)上,将不同的SI(源系统)组合到一个表中;出现了HUB表,用于生成用于链接来自不同源系统的数据的代理键。 我们通过类似于stage-layer的python-check检查它们的唯一性。
在DDS层上,您需要检查与HUB表组合后,键字段中是否没有出现类型0,-1,-2的值,这意味着表连接不正确,数据不足。 它们可能在HUB表中缺少必要数据的情况下出现。 这是手动解析的错误。
ADS窗口层(第一个图中的8)数据的最复杂调节。 为了完全放心所获得的结果的收敛性,此处部署了使用源系统进行费用汇总的验证。 一方面,有一类指标包括应计总额。 我们从WCD的窗户收集它们一个月。 另一方面,我们从源系统中收取相同费用的汇总。 允许偏差不超过1%或某个商定的绝对值。 通过对帐获得的结果集被放入接收Oracle表的特殊创建的数据集中。 数据比较是在Oracle视图中完成的。 APEX中结果的可视化。 整套数据(结果集)的存在使我们能够在存在错误的情况下更深入地分析结果的详细数据,找到发生差异的特定文章,并找出其原因。
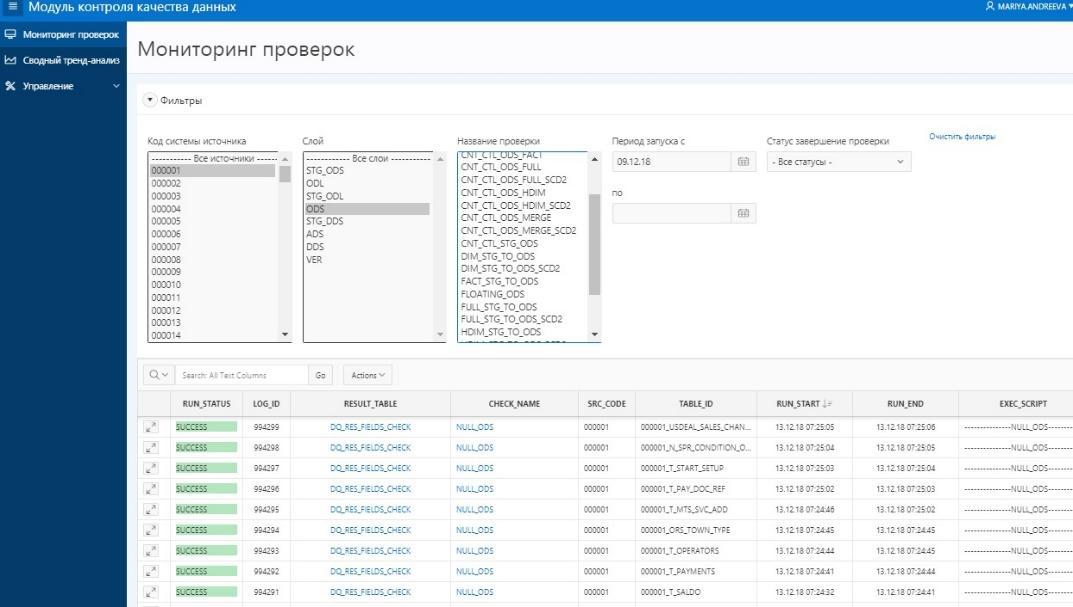 在APEX中向用户显示对帐结果
在APEX中向用户显示对帐结果目前,我们已经获得了一个可行且活跃使用的应用程序,用于对帐数据。 当然,我们有计划进一步开发对帐的数量和质量,以及平台本身的开发。 自己的开发使我们能够足够快地更改和修改功能。
本文由Rostelecom数据管理团队编写