同事们好!

在即将到来的一年的最后一期出版物中,我们想提到强化学习-我们已经将其翻译成
书的主题。
自己做个判断:Medium上有一篇基本文章,概述了问题的背景,描述了最简单的算法及其在Python中的实现。 这篇文章有几种gif图像。 在未来的一年中,激励,奖励和选择成功道路上的正确策略对我们每个人都将非常有用。
祝您阅读愉快!
强化学习是机器学习的一种形式,其中,代理学习在环境中行动,执行动作并由此发展直觉,然后观察行为的结果。 在本文中,我将告诉您如何理解和阐述强化学习的问题,然后在Python中解决它。
最近,我们已经习惯了计算机与人类玩游戏的事实-在多人游戏中作为机器人,或者在一对一游戏中作为竞争对手:例如在Dota2,PUB-G和Mario中。 研究公司
Deepmind在2016年的AlphaGo计划在2016年击败韩国冠军
后就对此消息
大惊小怪 。 如果您是一名狂热的游戏玩家,您可能会听说过Dota 2 OpenAI Five的五场比赛,在那场比赛中,汽车与人作战并在Dota2中击败了最佳玩家。 (如果您对细节感兴趣,可以在
此处详细分析该算法,并检查机器的运行方式)。

最新版本的OpenAI Five
采用Roshan 。
因此,让我们从核心问题开始。 为什么我们需要加强培训? 它仅在游戏中使用,还是在解决应用问题的现实场景中适用? 如果这是您第一次阅读强化训练,则根本无法想象这些问题的答案。 实际上,强化学习是人工智能领域中使用最广泛且发展最快的技术之一。
以下是一些特别需要强化学习系统的学科领域:
- 无人驾驶车
- 游戏产业
- 机器人技术
- 推荐系统
- 广告及行销
强化学习的概述和背景那么,当我们拥有如此众多的机器学习和深度学习方法时,强化学习现象是如何形成的呢? “他是由Rich Sutton和Rich的研究主管Andrew Barto发明的,他们帮助他准备了博士学位。” 该范式最初于1980年代形成,然后是过时的。 随后,里奇认为她拥有美好的未来,并且最终将获得认可。
强化学习支持在部署环境中的自动化。 机器学习和深度学习都以大致相同的方式运行-它们在策略上的排列方式不同,但是两种范例都支持自动化。 那么,为什么要进行强化训练?
这很自然地让人联想到自然学习过程,其中过程/模型起作用并收到有关她如何应付任务的反馈:好与不好。
机器和深度学习也是训练的选择,但是,它们更适合于识别可用数据中的模式。 另一方面,在强化学习中,这种经验是通过反复试验获得的。 系统逐渐找到正确的选项或全局最优。 强化学习的另一个重要优势是,在这种情况下,不需要像教师指导那样提供广泛的培训数据。 几个小片段就足够了。
强化学习的概念想象一下教您的猫新技巧; 但是,不幸的是,猫不懂人类的语言,因此您无法接受并告诉它们您将与它们一起玩什么。 因此,您将采取不同的行动:模仿情况,猫就会尝试以一种或另一种方式做出响应。 如果猫按照您想要的方式做出反应,则向其中倒牛奶。 您知道接下来会发生什么吗? 再一次,在类似的情况下,猫将再次以更大的热情执行所需的动作,希望它能得到更好的喂养。 这是通过一个积极的例子进行学习的方式。 但是,例如,如果您尝试用负面奖励来“教育”一只猫,请严格地看着它并皱眉,那么在这种情况下它通常是不会学习的。
强化学习的工作原理与此类似。 我们告诉机器一些输入和动作,然后根据输出奖励机器。 我们的最终目标是最大化回报。 现在让我们看一下如何通过强化学习来重新构造上述问题。
- 猫是暴露于“环境”的“媒介”。
- 根据您在教猫的方式,环境是一个家庭或娱乐场所。
- 培训产生的情况称为“状态”。 对于猫来说,条件的例子是猫“奔跑”或“在床下爬行”。
- 代理通过执行动作并从一种“状态”转移到另一种状态来做出反应。
- 状态更改后,代理将根据其采取的行动获得“奖励”或“罚款”。
- “策略”是一种选择行动以获得最佳结果的方法。
现在我们已经弄清楚了强化学习是什么,让我们详细讨论强化学习和带强化的深度学习的起源和演变,讨论这种范式如何使我们解决在有或没有老师的情况下都不可能学习的问题,并注意以下几点奇怪的事实:目前,Google的搜索引擎已使用强化学习算法进行了优化。
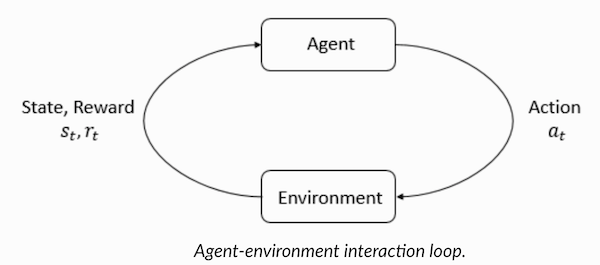
了解强化学习术语Agent和Environment在强化学习算法中起着关键作用。 环境是代理必须生存的世界。 此外,Agent从环境(奖励)接收加强信号:这是一个数字,表示可以考虑当前世界状况的好坏。 代理的目的是使总奖励最大化,即所谓的“收益”。 在编写我们的第一个强化学习算法之前,您需要了解以下术语。

- 状态:状态是一个世界的完整描述,在这个世界中,没有一个表征该世界的信息片段缺失。 它可以是固定或动态的头寸。 通常,这些状态以数组,矩阵或高阶张量的形式编写。
- 行动 :该行动通常取决于环境条件,并且在不同的环境中,代理将采取不同的行动。 许多有效的代理动作记录在称为“动作空间”的空间中。 通常,空间中的动作数是有限的。
- 环境 :这是代理程序存在的地方以及与之交互的地方。 不同类型的奖励,策略等用于不同的环境。
- 奖励和奖金 :在进行增援训练时,您需要不断监控奖励功能R。 在设置算法,优化算法以及停止学习时,这一点至关重要。 这取决于当前的世界状态,刚刚采取的行动以及下一世界的状态。
- 策略 :策略是代理根据其选择下一个动作的规则。 这套策略也称为代理的“大脑”。
现在我们已经熟悉了强化学习术语,让我们使用适当的算法解决问题。 在此之前,您需要了解如何提出这样的问题,并且在解决此问题时,请依靠强化训练的术语。
出租车解决方案因此,我们继续使用增强算法来解决问题。
假设我们有一个无人出租车的训练区,我们训练该训练区将乘客运送到四个不同的位置(
R,G,Y,B )。 在此之前,您需要了解并设置我们开始使用Python进行编程的环境。 如果您刚刚开始学习Python,那么我
为您推荐
这篇文章 。
可以使用OpenAI的
Gym来配置解决出租车问题的环境-这是通过强化培训解决问题的最受欢迎的库之一。 好吧,在使用Gym之前,您需要将其安装在计算机上,而名为pip的Python软件包管理器对此非常方便。 以下是安装命令。
pip install gym接下来,让我们看看如何显示环境。 此任务的所有模型和接口均已在健身房中配置,并以
Taxi-V2命名。 下面的代码段用于显示此环境。
“我们有4个地点(用不同的字母表示); 我们的任务是在某一地点接客,然后在另一地点下车。 成功的乘客降落,我们获得+20积分,而每花一步,我们就损失1积分。 对于旅客的每一次意外登机和下车,也将处以10分的罚款。” (来源:
gym.openai.com/envs/Taxi-v2 )
这是我们将在控制台中看到的输出:

出租车V2 ENV
太好了,
env是OpenAi Gym的心脏,它是一个统一的环境界面。 以下是我们认为有用的env方法:
env.reset :重置环境并返回随机的初始状态。
env.step(action) :及时推动环境
env.step(action)发展。
env.step(action) :返回以下变量
observation :观察环境。reward : reward您的行动是否有益。done :表示我们是否设法正确地接送乘客,也称为“一个情节”。info :调试所需的其他信息,例如性能和延迟。env.render :显示环境的一帧(用于渲染)
因此,在检查了环境之后,让我们尝试更好地理解问题。 出租车是这个停车场内唯一的汽车。 停车场可以分为
5x5网格,在那里我们可以找到25个可能的出租车位置。 这25个值是我们状态空间的元素之一。 请注意:目前,我们的出租车位于坐标(3,1)的点。
允许乘客上车的环境有4个点:
R, G, Y, B或坐标(
[(0,0), (0,4), (4,0), (4,3)] (水平;垂直)),如果可以用笛卡尔坐标解释上述环境。 如果您还考虑了另一种(1)乘客状态:在出租车内,您可以将乘客位置及其目的地的所有组合用于计算我们的出租车培训环境中的州总数:我们有四(4)个目的地和五(4+ 1)乘客位置。
因此,在我们乘坐出租车的环境中,有5×5×5×4 = 500种可能的状态。 代理处理500个条件之一并采取行动。 在我们的情况下,选项如下:沿一个方向或另一个方向移动,或决定接送乘客的决定。 换句话说,我们有六种可能的行动可供使用:
上车,下车,北,东,南,西(最后四个值是出租车可以行驶的方向。)
这是
action space :代理在给定状态下可以执行的所有动作的集合。
从上图可以清楚地看到,出租车在某些情况下无法执行某些操作(墙壁会干扰)。 在描述环境的代码中,我们简单地为墙上的每一次撞击分配-1的罚款,而出租车与墙壁碰撞。 因此,这些罚款将累积起来,因此出租车将尽量不撞墙。
奖励表:在创建出租车环境时,还可以创建一个称为P的主要奖励表,您可以将其视为一个矩阵,其中状态数与行数相对应,动作数与列数相对应。 也就是说,我们正在谈论
states × actions矩阵。
由于绝对所有条件都记录在此矩阵中,因此您可以查看分配给我们选择说明的状态的默认奖励值:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
该词典的结构如下:
{action: [(probability, nextstate, reward, done)]} 。
- 值0-5对应于出租车在图示的当前状态下可以执行的动作(南,北,东,西,上,下车)。
- done让您判断我们何时在期望的地点成功下车。
要在不进行任何强化训练的情况下解决此问题,可以设置目标状态,选择空格,然后,如果可以在一定数量的迭代中达到目标状态,则假定此时刻对应于最大奖励。 在其他状态下,如果程序正确执行(接近目标),则奖励的价值接近最大值;如果程序出错,则奖励罚款。 而且,罚款的价值不能低于-10。
让我们编写代码来解决此问题,而无需加强培训。
由于我们有一个P表,每个州都有默认的奖励值,因此我们可以尝试仅基于此表来组织出租车的导航。
我们创建一个无限循环,滚动直到乘客到达目的地(一个情节),或者换句话说,直到奖励率达到
env.action_space.sample()方法自动从所有可用动作集中选择一个随机动作。 考虑会发生什么:
import gym from time import sleep
结论:
积分:OpenAI
该问题已解决,但尚未优化,或者此算法在所有情况下均不起作用。 我们需要一个合适的交互代理,以便机器/算法解决问题所花费的迭代次数保持最小。 此处的Q学习算法将为我们提供帮助,我们将在下一部分中介绍其实现方法。
引入Q学习以下是最流行且最简单的强化学习算法之一。 环境奖励代理商进行逐步培训,并奖励他在特定状态下采取最佳步骤的事实。 在上面讨论的实现中,我们有一个奖励表“ P”,我们的代理将根据该表进行学习。 根据奖励表,他根据其作用来选择下一个动作,然后更新另一个值,称为Q值。 结果,创建了一个新表,称为Q表,显示在组合上(状态,操作)。 如果Q值更好,那么我们可以获得更多优化的回报。
例如,如果出租车处于乘客与出租车在同一地点的状态,则“提车”动作的Q值极有可能高于其他动作,例如“下车乘客”或“往北走”的Q值”。
Q值使用随机值初始化,并且当代理与环境交互并通过执行某些操作获得各种奖励时,Q值将根据以下公式更新:

这就提出了一个问题:如何初始化Q值以及如何计算它们。 执行动作时,将在此方程式中执行Q值。
在此,Alpha和Gamma是Q学习算法的参数。 阿尔法是学习的步伐,而伽玛是折扣因素。 这两个值的范围从0到1,有时等于1。 Gamma可以等于零,但alpha不能等于零,因为必须补偿更新过程中的损耗值(学习率是正数)。 此处的Alpha值与与老师教书时相同。 Gamma决定了我们希望给予将来等待我们的回报的重要性。
该算法总结如下:
- 步骤1:初始化Q表,并用零填充,并为Q值设置任意常数。
- 步骤2:现在,让代理响应环境并尝试其他操作。 对于每个状态更改,我们选择此状态(S)中所有可能的动作之一。
- 步骤3:根据上一个操作(a)的结果转到下一个状态(S')。
- 步骤4:对于状态(S')中的所有可能动作,请选择一个具有最高Q值的动作。
- 步骤5:根据上述公式更新Q表的值。
- 步骤6:将下一个状态转换为当前状态。
- 步骤7:如果达到目标状态,我们将完成该过程,然后重复。
Python中的Q学习 import gym import numpy as np import random from IPython.display import clear_output
太好了,现在您所有的值都将存储在
q_table变量中。
因此,您的模型在环境条件下进行了训练,现在知道如何更准确地选择乘客。 并且您熟悉了强化学习的现象,并且可以对该算法进行编程以解决新问题。
其他强化学习技巧:
- 马尔可夫决策过程(MDP)和Bellman方程
- 动态编程:基于模型的RL,策略迭代和值迭代
- 深度Q训练
- 策略梯度下降法
- 莎莎
此练习的代码位于:
vihar / python-强化学习