 上一次,
上一次,我们考虑了为步进电机生成脉冲的选项,该脉冲已从软件中部分移除到固件级别。 在完全成功的情况下,这保证不需要处理频率高达40 KHz的中断。 但是该选项有许多明显的缺陷。 首先,那里不支持加速。 其次,该解决方案中允许的步进频率的粒度为数百赫兹(例如,可以生成40,000 Hz和39966 Hz的频率,但是不可能生成这两个值之间的幅度的频率)。
加速实施
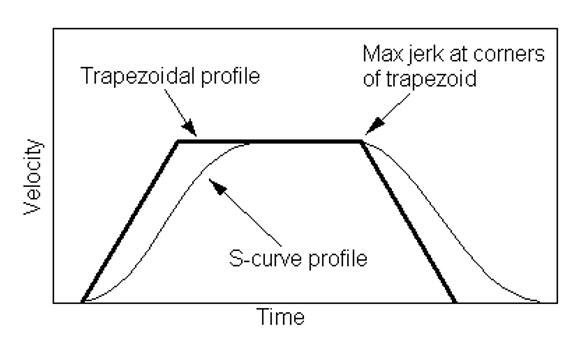
是否可以使用相同的UDB工具消除所指出的缺点而不会使系统复杂化? 让我们做对。 让我们从最困难的地方开始-加速。 在路径的开头和结尾添加了加速度。 首先,如果立即将高频脉冲施加到步进电机上,将需要更大的电流才能开始运行。 高允许电流会产生热量和噪声,因此最好对其进行限制。 但是随后引擎可以在开始时跳过步骤。 因此最好是平稳地加速引擎。 其次,如果沉重的头部突然停止,那么它将经历与惯性相关的瞬变。 波浪在塑料上可见。 因此,平滑地不仅需要分散,而且还需要使头部停止。 经典地,发动机速度的图表以梯形形式呈现。 这是Marlin固件的源代码片段:

我什至不会尝试弄清楚是否可以使用UDB来实现。 这是由于以下事实:另一种加速方式正在流行:不是梯形,而是S曲线。 他们的时间表如下:
这绝对不是UDB的。 放弃吗 一点都不! 我已经注意到,UDB并没有实现硬件接口,而只是允许您将部分代码从软件转移到固件级别。 让该配置文件计算中央处理器,并且步进脉冲的形成仍然执行UDB。 中央处理器有很多时间进行计算。 消除频繁中断的任务将继续非常优雅地解决,并且没有人计划将这一过程完全升级到固件级别。
当然,将需要在内存中准备配置文件,UDB将使用DMA从那里获取数据。 但是需要多少内存? 一毫米需要200步。 现在采用24位编码,这是每1毫米头移动600字节! 再一次,还记得不是那么频繁,而是仍然不断地中断以片段形式传输所有内容吗? 真的不是! 事实是,PSoC的DMA机制基于描述符。 从一个描述符执行任务后,DMA控制器将继续执行下一个描述符。 因此,沿着链,您可以使用很多描述符。 我们用官方文档中的一些图来说明这一点:

实际上,也可以通过构造三个描述符链来使用此机制:
| 不行 | 解说 |
|---|
| 1个 | 从存储器到FIFO,地址递增。 指示具有加速度曲线的部分。 |
| 2 | 从存储器到FIFO,不增加地址。 将所有时间始终发送到内存中的相同单词以保持恒定速度。 |
| 3 | 从存储器到FIFO,地址递增。 指示具有制动曲线的部分。
|
事实证明,主要路径在步骤2中进行了描述,并且在物理上使用了相同的词来设置恒定速度。 内存消耗不大。 实际上,第二描述符可以在物理上由两个或三个描述符表示。 这是因为根据TRM,最大泵送长度可以为64 KB(修正值会更低)。 即32,767个单词。 每毫米200步的距离将对应163毫米的路径。 您可能需要将引擎分为两部分或三部分,具体取决于一次引擎可以行驶的最大距离。
不过,为了节省内存(并减少UDB块的开销),我建议放弃24位DatapPath块,改用更经济的16位块。
这样啊 第一个修订提案。
在内存中准备了可对步骤持续时间进行编码的数组。 此外,此信息将使用DMA发送到UDB。 直线段由一个元素的数组编码,DMA块不增加地址,始终选择相同的元素。 加速,直线和制动部分通过DMA控制器中可用的方法连接。微调中音
现在我们将考虑如何克服频率粒度的问题。 当然,将无法进行精确设置。 但是,实际上,原始的“固件”也无法做到这一点。 相反,他们使用Bresenham算法。 一种措施的延迟被添加到某些步骤。 结果,平均频率在较小值和较大值之间变为中间。 通过调整定期周期和延长周期的比率,可以平滑地更改平均频率。 如果现在不通过数据寄存器设置速度,而是通过FIFO传输速度,并且通常通过DMA传输的字数来设置脉冲数,则UDB中的两个数据寄存器都将释放。 此外,还释放了其中一个计数脉冲数的电池。 在这里,我们将在它们上建立一定的PWM。
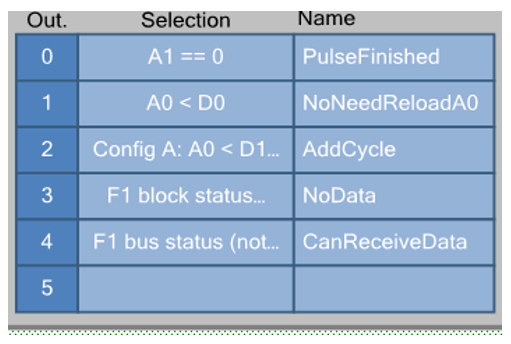
通常,ALU比较并分配具有相同索引的寄存器。 当一个寄存器的索引为0而另一个寄存器的索引为1时,则无法实现该操作的每个版本。 但是我设法将寄存器中的纸牌放在一起,可以完成PWM。 原来如图所示。

当条件A0 <D1满足时,我们将在给定的脉冲长度上增加一个额外的心跳。 当条件不满足时,我们将不会。
正常情况下的球形马
因此,考虑到新架构,我们开始修改为UDB开发的模块。 替换数据路径位深度:
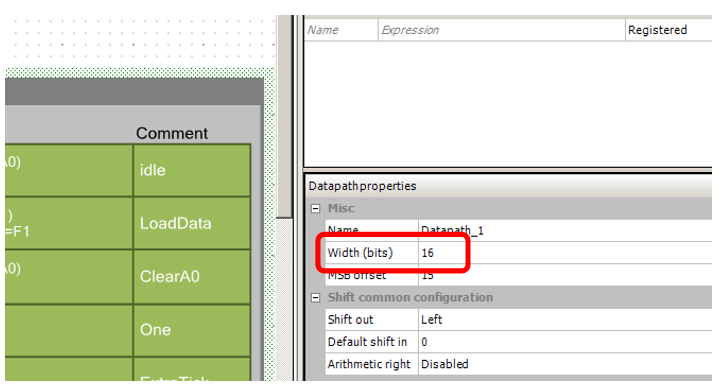
与上一次相比,我们需要从Datapath退出的次数更多。
双击它们,我们看到详细信息:
 State
State变量还有更多数字,不要忘记连接较旧的数字! 在旧版本中,常数为0。
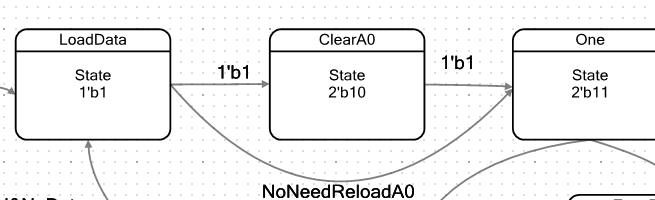
我得到的自动机的过渡图是这样的:

FIFO1为空时,我们处于
空闲状态。 顺便说一下,使用FIFO1而不是FIFO0是纸牌形成的结果。 寄存器A0用于实现PWM,因此脉冲宽度由寄存器A1确定。 而且我只能从FIFO1下载它(也许还有其他秘密方法,但是我不知道它们是什么)。 因此,DMA完全将数据上载到FIFO1,并且退出
空闲状态的正是FIFO1的
“非空”状态。
处于
IDLE状态的ALU使寄存器A0无效:

这是必要的,以便在PWM操作开始时始终从头开始工作。
但是数据进入了FIFO。 机器进入
LoadData状态:
在这种状态下,ALU将FIFO中的下一个字加载到寄存器A1中。 在此过程中,为了不产生不必要的状态,增加了用于PWM的计数器A0的值:

如果计数器A0尚未达到值D0(也就是说,条件A0 <D0被触发,使标志
NoNeedReloadA0翘起),则进入状态
One 。 否则,状态为
ClearA0 。
在
ClearA0状态下
, ALU只是将A0的值
清零,从而开始一个新的PWM周期:

之后,机器也进入“
一”状态,仅一拍后。
我们从旧版本的机器中就熟悉了这一点。 其中的ALU不执行任何功能。
如此-在此状态下,会在
Out_Step的输出处生成一个单元(此处,当根据条件生成该单元时,优化程序会更好地工作,这是凭经验检测到的)。
我们一直处于这种状态,直到我们已经知道的七位计数器重置为零为止。 但是,如果早些时候我们沿着一条路径摆脱了这种状态,那么现在可以有两条路径:直接和延迟。
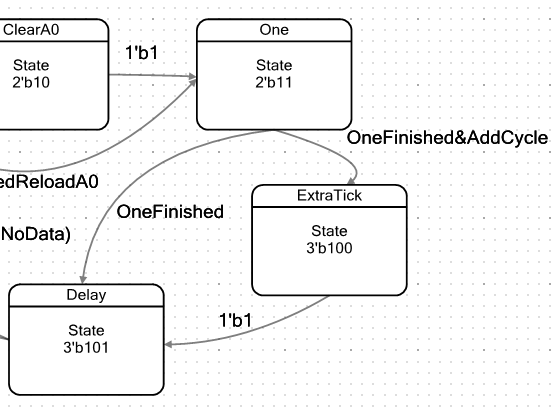
如果
设置了
AddCycle标志以满足条件A0 <D1,我们将进入ExtraTick状态。 在这种状态下,ALU不会执行任何有益的操作。 只是周期要多花1拍。 此外,所有路径都以“
延迟”状态收敛。
此条件测量脉冲的持续时间。 减少寄存器A1(仍在
加载状态时
加载 )直到达到零。

此外,根据FIFO中是否有其他数据,机器将切换为在
装入状态或
空闲状态下获取下一部分。 让我们不在图中查看(有长箭头,所有内容都会很小),而是以表格的形式,双击
Delay状态:
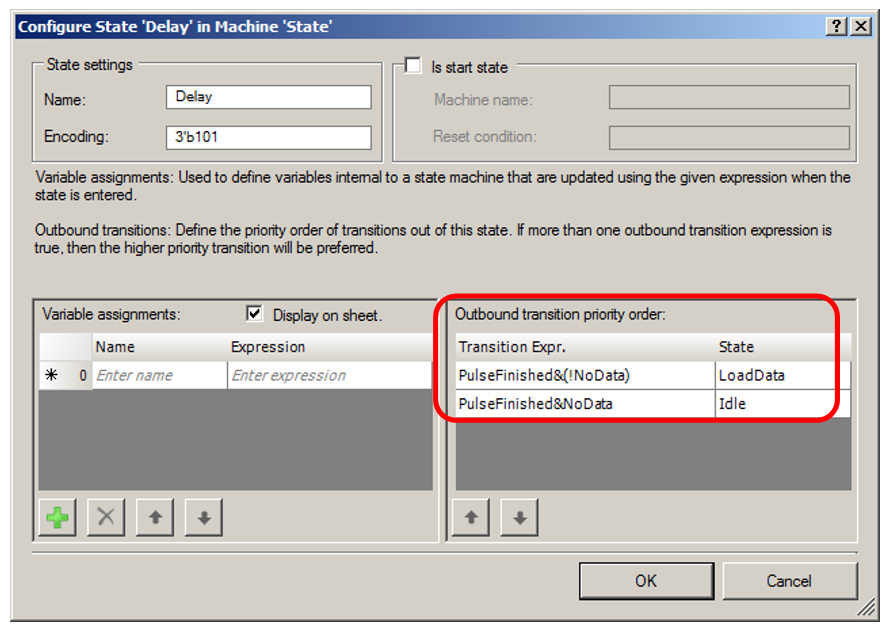
现在从UDB退出。 我将处于
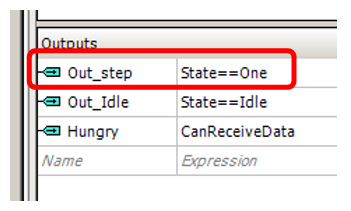
空闲状态的标志转换为异步比较(在以前的版本中,有一个触发器已在各种状态下翘起并重置),因为对于它,优化器显示了最佳结果。 另外,添加了
饥饿标志,向DMA单元发送信号,表明它已准备好接收数据。 它被缠绕在标志
“ FIFO1未被拥挤”上 。 由于不拥挤,DMA可以在其中加载另一个数据字。
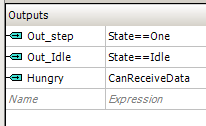
在自动部分-就是这样。
将DMA块添加到主项目图中。 暂时,我开始中断DMA终止标志,但事实并非如此。 当直接访问内存的过程完成时,您可以启动与该段相关的新进程,但是无法开始填写有关该新段的信息。 FIFO仍然具有三到四个元素。 此时,仍然不可能基于UDB对块的寄存器D0和D1进行重新编程,但仍需要对其进行操作。 因此,以后可能会添加基于
Out_Idle输出的中断。 但是该厨房将不再与UDB块编程相关,因此我们只会顺带提及。
软件实验
由于现在还不了解所有内容,因此我们不会编写任何特殊功能。 所有检查都将在“额头上”进行。 然后,基于成功的实验,可以编写API函数。 这样啊 我们使
main()函数最小化。 它仅设置系统并调用选定的测试。
int main(void) { CyGlobalIntEnable;
让我们尝试通过调用一个函数来发送脉冲包,检查是否插入了另一个脉冲。 函数调用很简单:
TestShortSteps();
但是身体需要解释。
我将首先介绍整个功能 void TestShortSteps() { // , // // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
现在考虑其重要部分。
如果脉冲的正部分的长度等于92个时钟周期,则示波器将无法辨别负部分是否存在单周期插入。 比例将不同。 有必要使正部分尽可能短,以使总脉冲的大小与插入的节拍相当。 因此,我强行更改了设置脉冲正部分持续时间的计数器的周期:
// , // // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6);
但是为什么要采取六项整体措施? 为什么不三个? 为什么不两个? 毕竟为什么不是一个? 这是一个可悲的故事。 如果正脉冲短于6个周期,则系统不工作。 在示波器上进行长时间调试,将测试线输出到外部,这表明DMA并不是一件快速的事情。 如果机器的运行时间少于一定的持续时间,则在其
离开“延迟”状态时,FIFO通常仍然为空。 它可能尚未放置一个新的数据字! 而且只有当脉冲的正向部分具有6个周期的持续时间时,FIFO才能保证有时间加载...
延迟离题
我想到的另一个解决办法是RTOS MAX内核某些功能的硬件加速。 但是,a,关于这些相同的延迟,我所有的最佳想法都被打破了。
在一个案例中,我研究了Cyclone V SoC的Bare Metal应用程序的开发。 但是事实证明,使用单个FPGA寄存器(交替写入它们,然后从它们读取)会减少数百倍的内核操作。 你没听错。 数以百计。 而且,所有这些文档的记录都很少,但是起初我是内向的,然后从文档中的一些短语中证明,当通过一堆桥传递请求时,延迟是有罪的。 如果您需要驱逐一个大型阵列,那么也会有延迟,但是就一个泵浦的词而言,这并不重要。 当请求是单个请求时(而OS内核的硬件加速就暗示了这些请求),则减速度恰好进行了数百次。 当程序以疯狂的速度通过缓存使用主内存时,以纯编程方式完成所有操作的速度将大大提高。
在PSoC上,我也有一些计划。 在外观上,您可以使用DMA和UDB在数组中寻找数据。 到底有什么! 由于DMA描述符结构,这些控制器可以在链接列表中进行完全的硬件搜索! 但是收到上述插件后,我意识到它也与延迟有关。 在此,此延迟在文档中进行了详细描述。 在TRM系列和单独的文档
AN84810-PSoC 3和PSoC 5LP Advanced DMA Topics中均是如此 。 在那里3.2节专门讨论了这一点。 因此,下一次硬件加速被取消。 可惜 但是,正如Semyon Semyonovich Gorbunkov所说:“我们将进行搜索。”
持续的软件实验
接下来,我设置Bresenham算法的参数:
// // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2);
好了,然后是常规代码,该代码通过DMA将字数组传输到引擎控制单元X的FIFO1。
结果需要一些解释。 这是:

当机器处于“
一”状态时,计数器A0的值以红色显示。 绿色星号表示由于机器处于
ExtraTick状态而插入延迟的情况。 还有一些条由于
ClearA0状态而导致延迟,它们用蓝色网格标记。
如您所见,当您第一次输入时,第一个延迟就消失了。 这是由于A0处于
空闲状态时会被重置,而当它进入
LoadData时会增加。 因此,从分析的角度来看(从
One的状态退出),它已经等于1。 该帐户从她开始。 但这通常不会影响中频。 只需要记住它。 应当牢记的是,复位A0时还将插入时钟。 计算平均频率时必须考虑到这一点。
但总的来说,脉冲数是正确的。 他们的持续时间也是可以相信的。
让我们尝试编写更真实的描述符链,
由加速,线性运动和制动阶段组成。 void TestWithPacking(int countOnLinearStage) { // , // . // , DMA !!! // , !!! StepperController_X_SingleVibrator_WritePeriod (6); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // static const uint16 accelerate[] = {0x0010,0x0008,0x0004}; // static const uint16 deccelerate[] = {0x004,0x0008,0x0010}; // . . static const uint16 steps[] = {0x0001}; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // uint8 tdDeccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdDeccelerate, sizeof(deccelerate), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdDeccelerate, LO16((uint32)deccelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // uint8 tdSteps = CyDmaTdAllocate(); // !!! // !!! CyDmaTdSetConfiguration(tdSteps, countOnLinearStage, tdDeccelerate, /*TD_INC_SRC_ADR |*/ TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdSteps, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // // !!! uint8 tdAccelerate = CyDmaTdAllocate(); CyDmaTdSetConfiguration(tdAccelerate, sizeof(accelerate), tdSteps, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); CyDmaTdSetAddress(tdAccelerate, LO16((uint32)accelerate), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, tdAccelerate); // CyDmaChEnable(channel, 1); }
首先,调用相同的十个步骤(在DMA中,实际需要20个字节):
TestWithPacking (20);
结果是预期的。 一开始,加速度是可见的。 从最后一个脉冲到
IDLE (蓝光)的出口会延迟很长时间,然后最后一个步骤完全完成,其值大约等于第一个值。
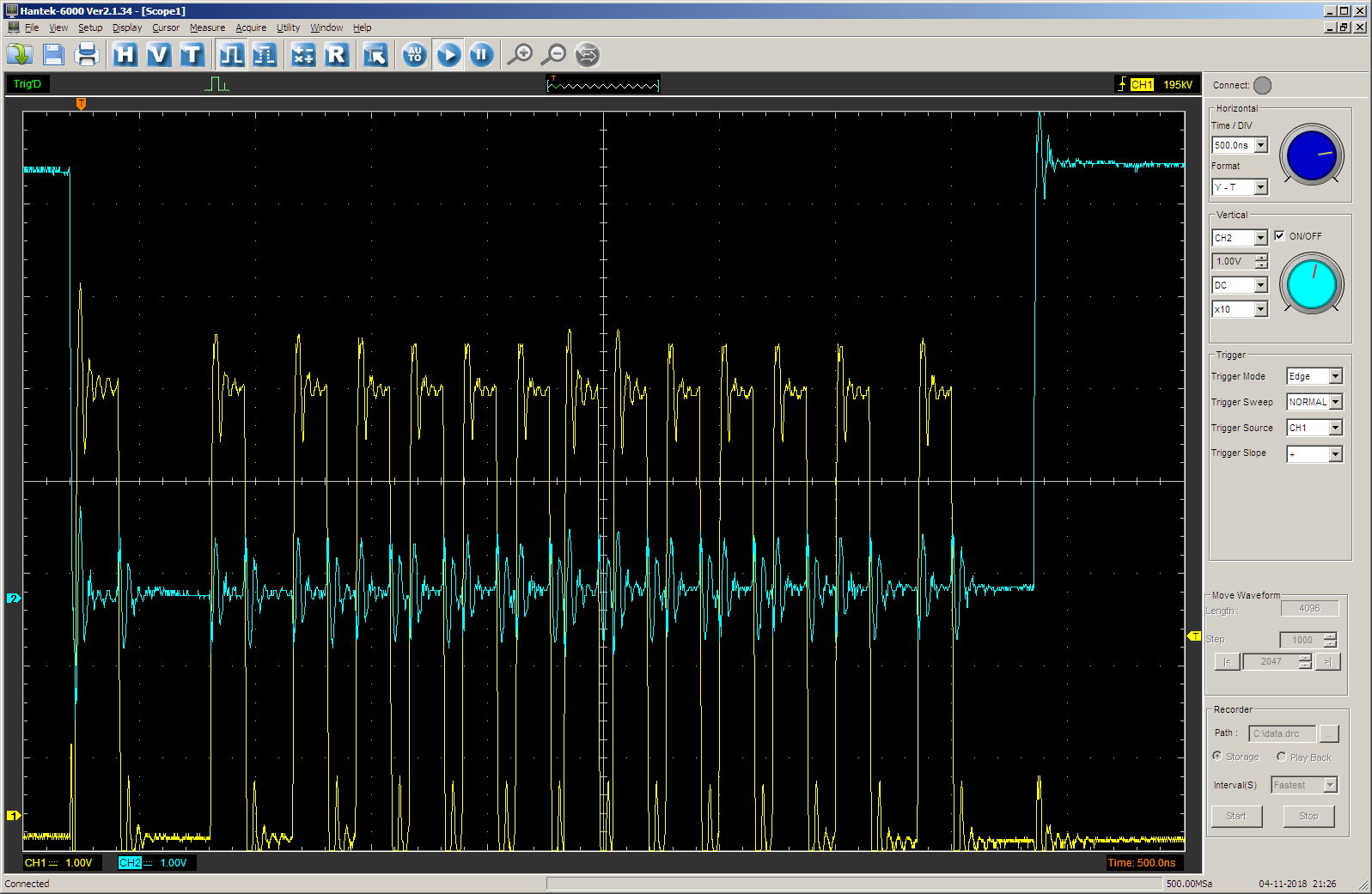
正常条件下的真马
改造设备时,我以某种方式著名地从24位脉冲宽度跳到了16位作业。 但是我们发现这是不可能做到的:最小脉冲频率将太高。 我是故意的。 事实是,用于扩展16位计数器的位容量的技术是如此复杂,以至于如果我开始与主机一起描述它,它将转移所有的注意力。 因此,我们将其分开考虑。
我们有一个16位电池。 我决定将7位计数器标准实体添加到高位。 这个七位计数器是什么? 这是每个UDB块中都可用的设计(基本UDB块具有所有8位寄存器的位宽,位深度的增加由组中块的组合确定)。 使用相同的资源,可以实现
控制/状态寄存器。 现在,我们只有一个计数器,而不是用于16位数据的单个“
控制/状态”对。 因此,向系统添加另一个计数器,我们将不会延迟额外的资源。 我们只是拿已经分配给我们的东西。 太好了! 通过这种机制,我们使脉冲宽度计数器的高字节,并获得等于23位的脉冲宽度计数器的总宽度。
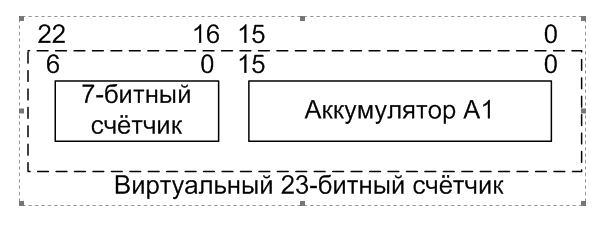
首先,我会说我的想法。 我以为退出
延迟状态后,我将检查此附加计数器的计数是否完成。 如果他还没有完成计数,我将减小其值,然后再次切换到“
延迟”状态。 如果计算在内,逻辑将保持不变,而无需增加额外的周期。
此外,此柜台的文档说我是对的。 从字面上说:
期间
定义初始周期寄存器值。 对于N个时钟周期,周期值应设置为N-1。 计数器将从N-1向下计数到0,这将导致N个时钟周期。 不支持周期寄存器值0,这将使端子计数输出保持在恒定的高电平状态。
生活表明,一切都不同。 我推导出了示波器上
终端计数线的状态,并在
期间和程序加载期间以预加载的零值观察了它的值。 las,嗯。 没有
持续的高状态 !
通过反复试验,我设法使系统正常工作,但是要做到这一点,必须从计数器中减去至少一个! 新的
“减法”状态不在一边。 必须将其插入所需的路径。 它位于
Delay状态的前面,称为
Next65536 。
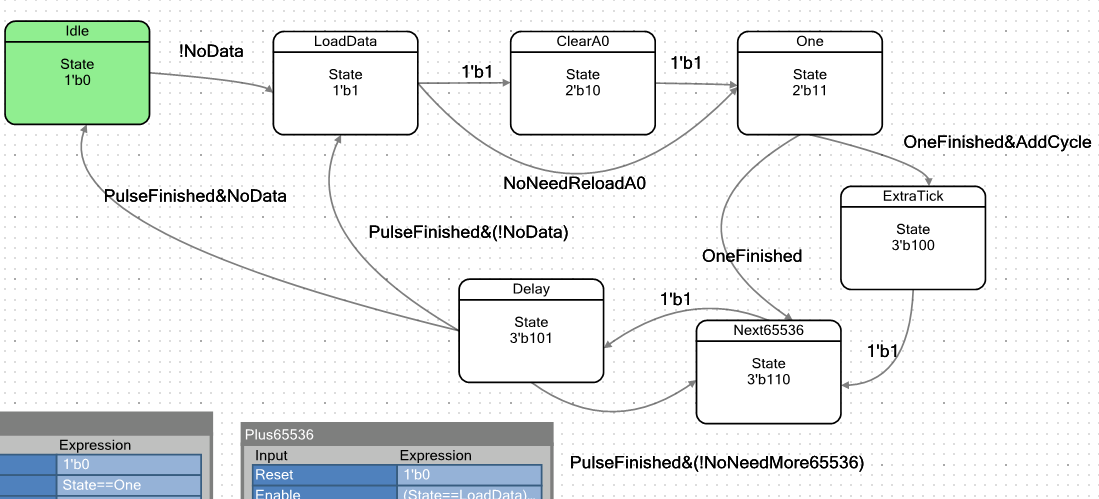
在这种状态下,ALU不会执行任何有用的操作。 实际上,只有新的计数器会对处于这种状态的事实做出反应。 它在图中:

以下是其属性的详细信息:
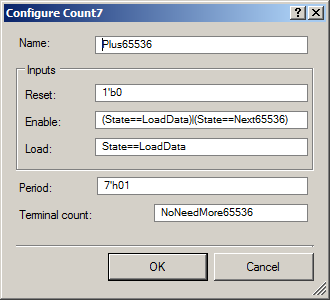
通常,考虑到以前的文章,此计数器的本质很明显。 仅
启用行受苦。 同样,我不完全理解为什么当机器处于
LoadData状态时应将其打开(然后计数器重新加载周期值)。 我从控制LED的计数器的属性中借用了这个技巧,该属性取自那些LED的控制单元的英文作者。 没有它,周期的零值将不起作用。 她和她一起工作。
在API代码中,我们添加了一个新计数器的初始化。 现在启动函数如下所示:
void `$INSTANCE_NAME`_Start() { `$INSTANCE_NAME`_SingleVibrator_Start(); //"One" Generator start `$INSTANCE_NAME`_Plus65536_Start(); }
让我们检查一下新系统。 这是测试的功能代码
(其中只有第一行与已知行不同): void JustTest(int extra65536s) { // 65536 StepperController_X_Plus65536_WritePeriod((uint8) extra65536s); // // — CY_SET_REG16(StepperController_X_Datapath_1_D0_PTR, 4); CY_SET_REG16(StepperController_X_Datapath_1_D1_PTR, 2); // . // static const uint16 steps[] = { 0x1000,0x1000,0x1000,0x1000 }; // DMA , uint8 channel = DMA_X_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(StepperController_X_Datapath_1_F1_PTR)); CyDmaChRoundRobin (channel,true); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR | TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)StepperController_X_Datapath_1_F1_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
我们这样称呼它:
JustTest(0);
在示波器上,我们看到以下内容(黄色光束-STEP输出,蓝色-用于过程控制的计数器TC输出的值)。 脉冲持续时间由
步长数组设置。 在每个步骤中,持续时间为0x1000小节。
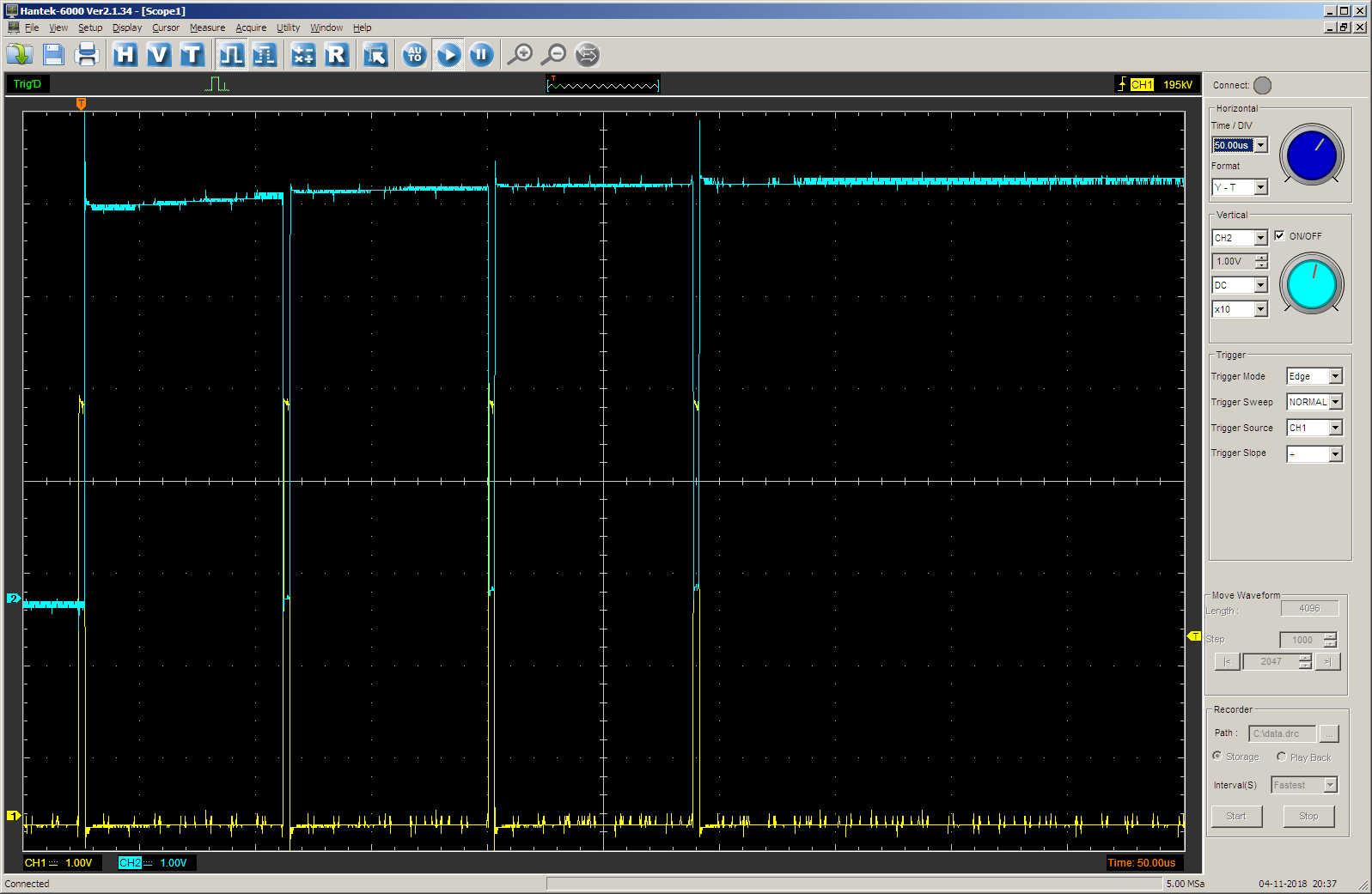
切换到另一扫描,以便不同结果之间具有兼容性:
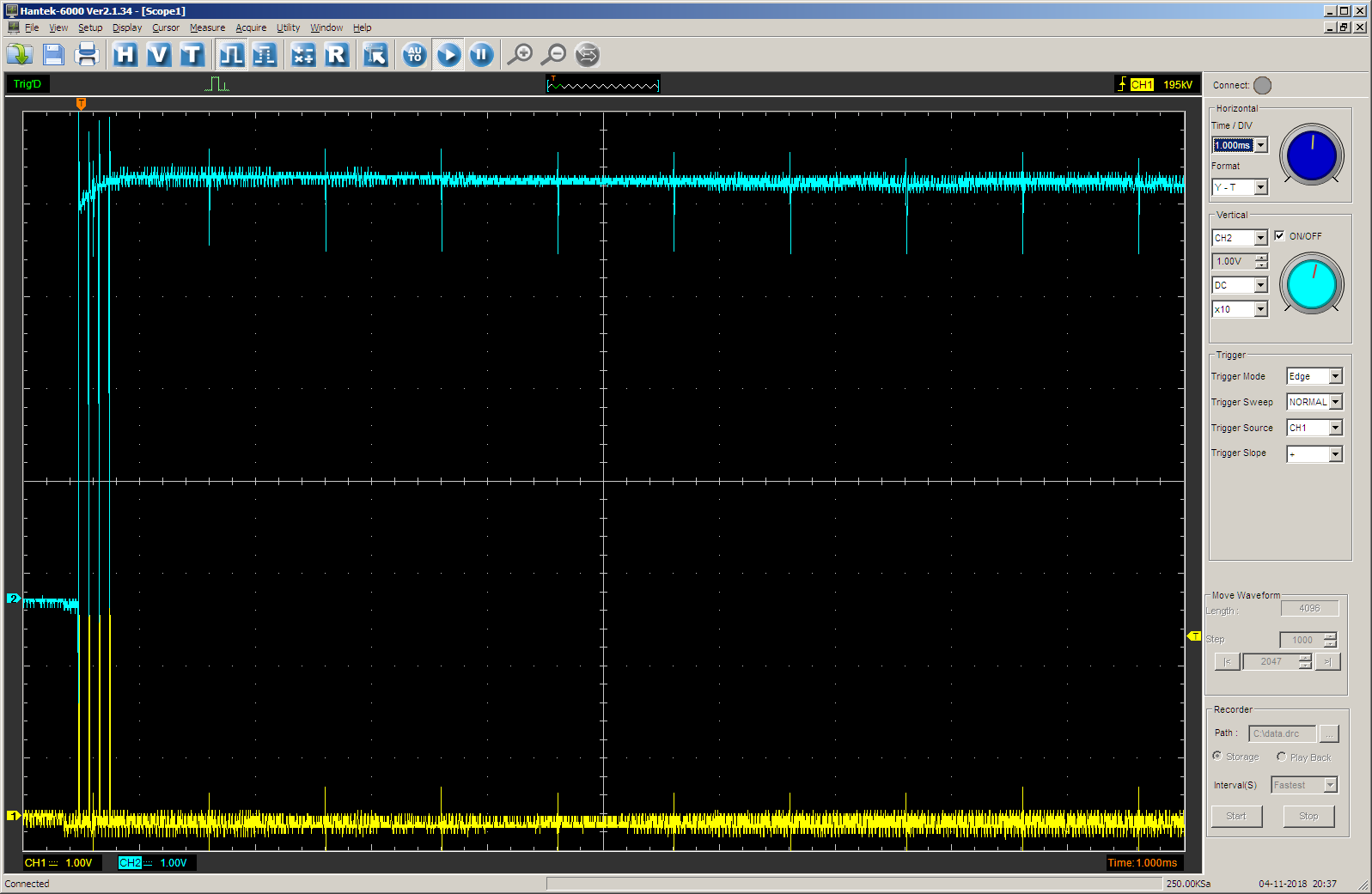
将函数调用更改为:
JustTest(1);
结果是预期的。 首先,对于0x1000周期,TC输出为零,然后-对于0x10000(65536d)周期为一个单位。 我们在文章的最后部分发现,频率大约等于700赫兹,因此一切正常。

好吧,让我们尝试一个演绎:
JustTest(2);
我们得到:
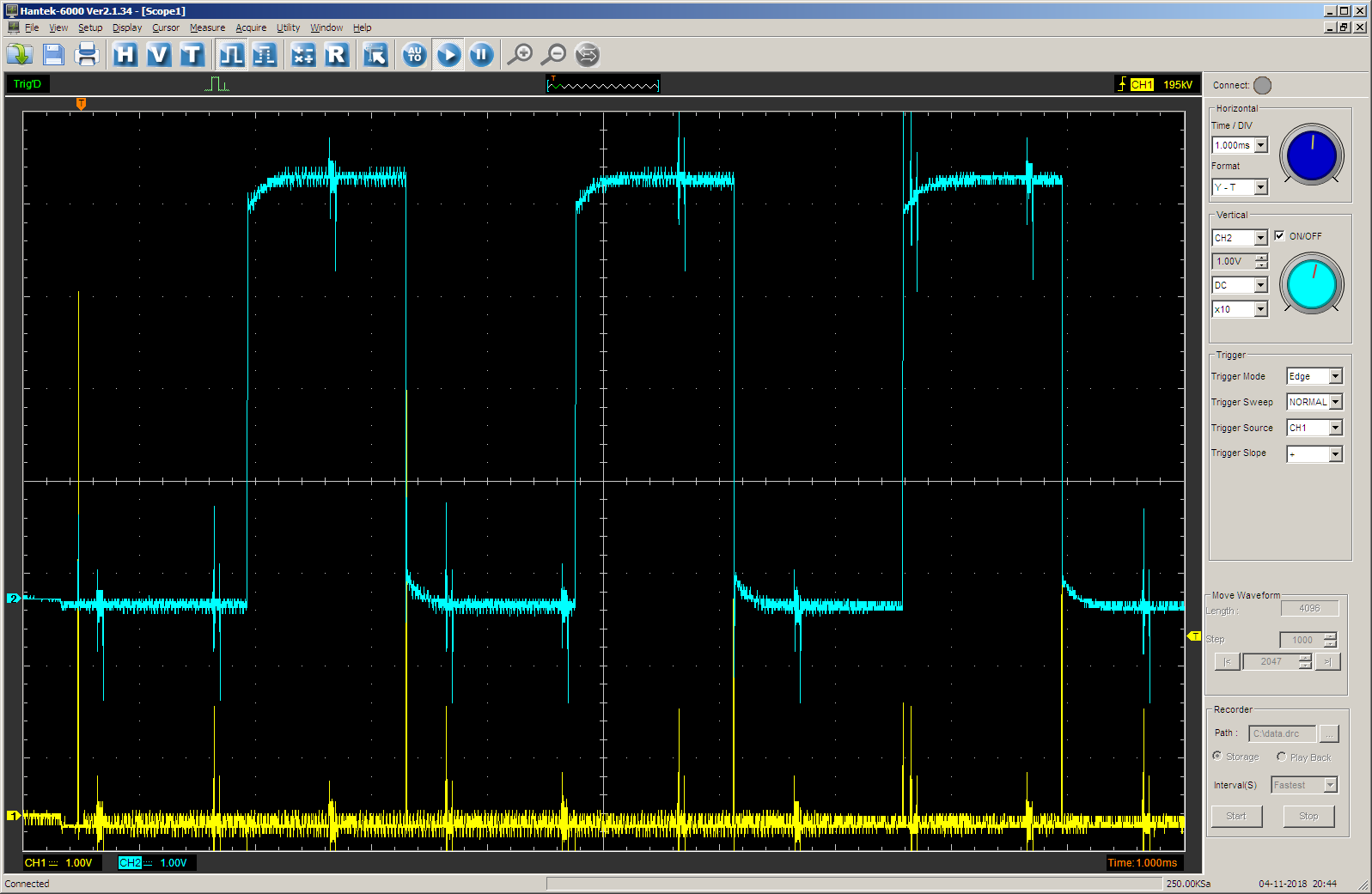
没错 在最后的65536个时钟周期内,TC输出翻转为1。 在此之前,他在0x1000 + 0x10000周期为零。
当然,采用这种方法,所有脉冲应与新计数器的值相同。 不可能在加速过程中产生一个具有最高字节的脉冲,比如说3,然后是1,然后是0。但是实际上,在如此低的频率(小于700赫兹)下,加速没有物理意义,因此可以忽略此问题。 以这个频率,您可以线性使用引擎。
美中不足
PSoC5LP系列的TRM文档指出:
每笔交易的大小为1到64 KB
但是在已经提到的AN84810中有这样一个短语:
1.如何使用DMA缓冲超过4095字节?
TD的最大传输计数限制为4095字节。 如果需要使用单个DMA通道传输多个4095字节,请使用多个TD并将它们链接起来,如示例5所示。
谁是对的? 如果您进行实验,结果将倾向于最坏的陈述,但是行为将是完全无法理解的。 整个错误是在API中进行的检查:
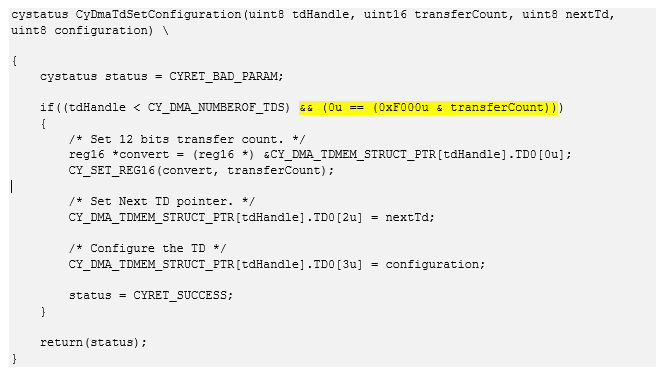
相同的文字。 cystatus CyDmaTdSetConfiguration(uint8 tdHandle, uint16 transferCount, uint8 nextTd, uint8 configuration) \ { cystatus status = CYRET_BAD_PARAM; if((tdHandle < CY_DMA_NUMBEROF_TDS) && (0u == (0xF000u & transferCount))) { /* Set 12 bits transfer count. */ reg16 *convert = (reg16 *) &CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[0u]; CY_SET_REG16(convert, transferCount); /* Set Next TD pointer. */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[2u] = nextTd; /* Configure the TD */ CY_DMA_TDMEM_STRUCT_PTR[tdHandle].TD0[3u] = configuration; status = CYRET_SUCCESS; } return(status); }
如果指定的事务长于4095字节,则将使用以前的设置。 是的,我没有想到要检查错误代码...
实验表明,如果取消此检查,将使用掩码0xfff(4096= 0x1000)截断实际长度。 las,嗯。 一份愉快工作的所有希望都破灭了。 您当然可以在4K中建立相关描述符的链。 但是,说64K是16个链。 三个主动引擎(挤出机的步数减少)-48个链条。 在最坏的情况下,应该在每个段之前填充太多内容。 也许在时间上是可以接受的。 至少有127个描述符可用,因此肯定会有足够的内存。
您可以根据需要发送丢失的数据。 由于DMA通道已完成工作,因此出现中断,我们正在向其转移另一个网段。 在这种情况下,不需要计算,段已经形成,一切都会很快。 而且没有性能要求:发出中断请求时,FIFO中将有4个以上的元素,每个元素将被服务数百个甚至数千个时钟周期。 也就是说,一切都是真实的。 在实际工作中,更容易选择特定策略。 但是文档(TRM)中的错误破坏了整个工作环境。 如果事先知道,也许我不会检查方法。
结论
在外观上,开发的辅助固件工具变得可以接受,因此可以在其基础上制作“固件”的版本,例如Marlin,该版本并不总是出现在步进电机的中断处理程序中。 据我所知,对于Delta打印机尤其如此,那里对计算资源的需求非常高。 也许这可以消除在头部停止的地方在我的三角洲上出现的潮水。 在这些相同位置的MZ3D上,未观察到大量涌入。 无论是真的还是假的,时间都会证明一切,关于此的报告将需要发布在一个完全不同的分支中。
同时,我们已经看到,在UDB块上,尽管非常简单,但很可能实现与主处理器协同工作并允许其卸载的协处理器。 当这些单元很多时,协处理器可以并行工作。
DMA控制器文档中的错误使结果模糊。 尽管如此,还是需要中断,但是中断的频率和原始版本的时间要求不同。 因此,这种情绪被破坏了,但是与纯软件工作相比,基于UDB的“协处理器”的使用仍然带来了可观的收益。
在此过程中,发现DMA的工作速度相当低。 结果,在PSoC5LP和STM32上都进行了一些测量。 结果引出另一篇文章。 如果这个话题很有趣,也许有一天我会做。
实验的结果是一次获得了两个测试项目。 第一个更容易理解。 你可以在
这里拿。 第二个继承自第一个,但是在添加七位计数器和关联的逻辑时感到困惑。 你可以在
这里拿。 当然,这些示例仅是测试示例。 尚无空闲时间可以嵌入到真正的“固件”中。 但是在这些文章的框架内,实践与UDB的合作更为重要。