
曾几何时,当天空是蓝色时,草变得更绿,恐龙在地球上漫游……不,算了一下恐龙。 好吧,总的来说,很久以前,这个想法浮现在脑海,分散了对标准Web编程的注意力,并做了一些更疯狂的事情。 当然可以,但是选择只能由您自己编写解释器。 我能说什么...
永远不要编写自己的编程语言 。 但是我从这一切中获得了一些经验,因此我决定分享一下。 让我们从最基础的词法分析器开始。
前言
在您开始了解哪种动物“词法分析器”之前,有必要弄清楚YaP的构成。
在现代世界中,每个编译器/解释器/编译器/类似的东西(让我们简称为“编译器”,不区分类型)分为两部分。 在聪明的叔叔的术语中,这些片段称为“前端”和“后端”。 不,这根本不是什么,在使用网络时,我们习惯于调用的内容,并且前端不是用带有HTML的JS编写的。 虽然...好吧。
前端的第一个任务是获取
文本并将其转换为
AST (抽象语法树),并在途中检查语法(有时还包括语义)。 第二个后端的任务是使其全部正常工作。 如果代码在解释器中汇编,则AST为虚拟处理器(虚拟机)创建一组指令,如果为编译器,则为真实处理器创建一组指令。 在生活中,所有事情都更加复杂,可能无法完全实现。 例如,在使用GCC编译器的情况下,所有东西都混在一起,但是Clang已经规范化了,LLVM是编译器“后端”的典型代表。
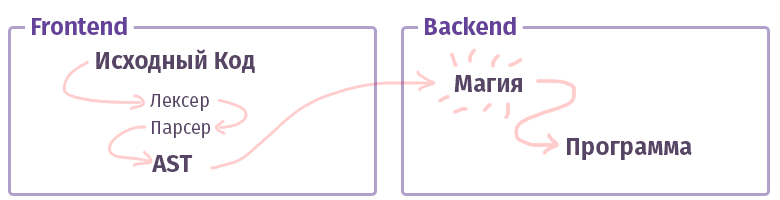
现在,让我们了解一个称为前端的部分。
词法分析
词法分析器的任务和词法分析的阶段是在入口处获得很多字母,并将它们分为某些类别-“令牌”。 因此,词法分析也称为“令牌化”。 这是每个现有编译器生成的文本处理的第一阶段。
像这样:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
顺便说一句,这里我们已经写了很多工具来使生活更轻松。 我们用来解析文本的
preg函数完全
可以完成此任务。 但是,有更方便的工具可以解决此问题:
好吧,很明显,有很多小玩意儿可以用记号分隔文本,也许我什至忘了一些东西,例如
Doctrine lexer。 但是接下来呢?
词法分析器的类型
和往常一样,一切都不像看起来那么简单。 词法分析器至少有两种不同的类别。 您可以套用规则,这是很琐碎的通常选择,它已经将所有内容划分为令牌。 其配置与我上面显示的示例没有太大不同。 但是,还有另一个选项称为
multistate 。 这样的词法分析器有点难以理解,因此,我想再谈一些。
多状态词法分析器的任务是根据先前的状态显示各种标记。 好吧,例如,在PHP中,使用<?Php +?>标签,内部行,注释和
HEREDOC /
NOWDOC构造来形成这种“过渡”状态。
还记得上面带有4个令牌的示例吗? 让我们对其进行一些修改以了解这些状态是什么:
class Example {
在这种情况下,如果我们拥有最简单的词法分析器,却不具备PCRE的广泛功能,那么我们将获得以下标记集:
var_dump(lex(...));
如您所见,我们对元素3-5的使用完全是平庸的:注释是出乎意料的,并且被分成了标记,尽管它应该被视为一个整体。
当然,借助PCRE功能,可以借助简单的规则“
// [^ \ n] * \ n ”来撕掉这样的令牌,但是如果不是这样的话? 好吧,还是我们要用手给它加气? 简而言之,在多状态词法分析器的情况下-我们可以说所有令牌都应该在
No1组中,一旦找到“
// ”令牌,就应该过渡到
No2组。 在第二组内部,如果找到了标记“
\ n ”,则反向转换-返回到第一组的转换。
像这样:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
我认为现在如何解析某些HEREDOC变得越来越清楚,因为即使具有PCRE的全部功能,鉴于这种HEREDOC语法支持变量插值,编写这种情况的规则仍然非常麻烦。 只需尝试使用内置的
token_get_all函数(note> 12 token)来解析这样的内容:
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
好吧,看来我们已经准备好开始练习。
练习
让我们记住在PHP中用于此类事情的东西吗? 好吧,当然是preg_match! 好吧,下来 基于preg_match的算法在
Hoa 中实现,并
在Phelxy的此实现中实现 。 它的任务很简单:
- 我们手头上有源文本和一系列常规。
- 我们匹配直到找到合适的东西。
- 找到一块后,将其从文本中切出并进一步匹配。
在代码形式中,它将看起来像这样:
代码表 <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
使用代码表 $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
这种方法非常简单,并且允许几次键盘按下操作来修改next()方法区域中的词法分析器,从而在状态之间添加过渡并将手淫的这种划分变成原始的多状态词法分析器。 在
$ this->令牌区域中,只需添加类似
$ this->令牌[$ this-> state]的内容 。
但是,除了原始主义本身之外,还有另一个缺点,虽然可能不会致命,但仍然...这样的实现速度非常慢。 在i7 7600k上,我碰巧是它的所有者-一种类似的算法每秒处理大约400个令牌,并且随着它们的变化(即,我们传递给构造函数的定义)的增加,它会减慢俄罗斯更换总统的速度...对不起 当然,我想说的是它将
非常缓慢地工作。
好的,我们该怎么办? 对于初学者,您可以了解问题所在。 事实是,每当我们在该语言的内部使用
preg_match时 ,带有JIT的编译器PCRE就会出现(在PHP 7.3中,PCRE2已经存在)。 每次他自己解析常客并为他们收集一个解析器时,我们将使用该解析器解析文本以创建标记。 听起来有些奇怪和重言。 但简而言之,每个令牌都需要从1到N个常规编译,其中N是这些令牌的定义数。 同时,值得注意的是,即使应用了“
S ”标志和在构造器中使用“
\ G ”进行优化(生成标记的正则表达式)也无济于事。
摆脱这种情况只有一种方法-您需要一次性解析所有这些文本,即 通过仅执行一个
preg_match函数。 仍然需要解决两个问题:
- 如何指示正则表达式N1的结果对应于标记N2? 即 例如,如何指示“ \ w + ”是T_CONST 。
- 结果如何确定令牌的顺序。 如您所知, preg_match或preg_match_all的结果将包含所有混合的内容。 即使有了作为第四个参数传递的标志的帮助,情况也不会改变。
在这里您可以停下来思考一下。 好吧
第一个问题的解决方案
称为PCRE组 ,也称为“子掩码”。 使用规则:“
(?<T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) ”通过将它们与它们的名称进行比较,可以一次性获得所有令牌。 匹配的结果将形成一个关联数组,该数组由对
[[TOKEN_NAME => TOKEN_VALUE]]组成 。
第二个比较复杂。 但是,您可以在此处应用战术技巧并使用
preg_replace_callback函数。 它的特殊之处在于,对于每个标记,从第一个到最后一个,将严格按顺序调用作为第二个参数传递的匿名。
为了不使人烦恼,实现如下:
另一段代码 class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
并且它的使用与以前的版本没有什么不同。 同时,工作速度从每秒
400个令牌增加到
57,000个令牌。 我
在实现中应用的就是这种算法,它负责重写Hoa源代码。 顺便说一句,如果您使用Parle,则每秒最多可以压缩
600,000个令牌。 总体情况如下所示(在PHP 7.1中启用了XDebug,因此数字较低,但是可以大致表示比率)。
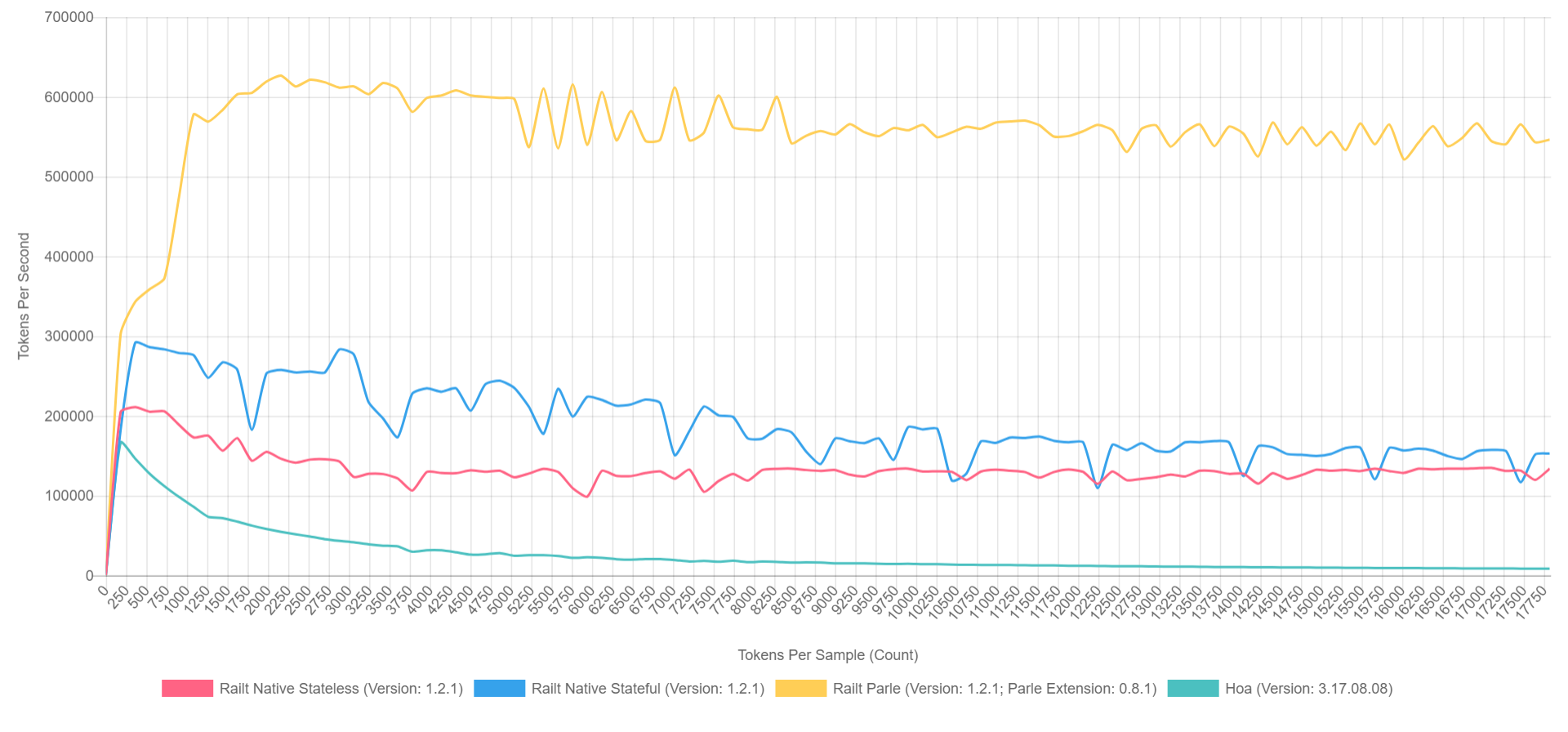
- 黄色是Parle的本机扩展。
- 蓝色-通过preg_replace_callback使用预组装的常规函数实现。
- 红色-相同,但在调用preg_replace_callback期间具有生成的规律性 。
- 绿色-通过preg_match实现。
怎么了
好吧,所有这些当然是很棒的,但是那些不耐烦的人很想问这个问题:“谁根本需要这个?” 在PHP的抽象世界中,“ fig-fig-and-site-ready”的原则占主导地位-不需要此类库,我们会坦白地说。 但是,如果我们讨论整个生态系统,那么我们可以回想一下臭名昭著的库,例如
symfony / yaml或
Doctrine 。 Symfony中的注释与PHP中的子语言相同,需要分别的词汇和语法解析。 此外,甚至还没有多少用PHP编写的知名CoffeeScript,Less和Scss / Sass编译器。 好吧,或者是,并基于它进行
预处理 。 我什至不会提到像phpmd或phpcs这样的代码分析工具。 而且像phpDocumentnor或Sami这样的文档生成器非常简单。 这些项目中的每个项目在解析文本/代码的第一阶段都采用了词法分析。
这不是一个完整的项目清单,也许我希望我的故事能够帮助您发现新事物并加以补充。
后记
展望未来,如果有人对解析器和编译器感兴趣,那么会有一些有关此主题的有趣报告,尤其是来自JetBrains的专家:
当然,仍然可以在大量YouTube上找到Andrei Breslav(
abreslav )的大部分表演-我建议您观看。
好吧,对于小说迷来说,
有这样一种资源对我个人非常有用。
发布后脚本。 如果您被史诗般的广阔空间所包围,那么您可以安全地以任何方便的方式通知作者。
另外,我想举
一个简单的PHP词法分析器的示例 ,现在看来它并不那么令人恐惧,现在甚至可以清楚地知道它是做什么的,对吗? 尽管我在欺骗谁,但常客们的眼睛在流血。 =)
谢谢你