在本文中,我将描述Spring Data的用法。
Spring Data是与数据库实体进行交互,在存储库中组织它们,检索数据,更改(在某些情况下)的另一种方便的机制,为此,在其中不执行即可声明接口和方法就足够了。
内容:
- 春季仓库
- 从方法名称请求方法
- 配置和设置
- 特殊参数处理
- 自定义存储库实现
- 自定义基础存储库
- 查询方法- 查询
1. Spring存储库
Spring Data中的基本概念是存储库。 这些是使用JPA实体与其进行交互的多个接口。 例如一个界面
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID>提供用于搜索,保存,删除数据的基本操作(CRUD操作)
T save(T entity); Optional findById(ID primaryKey); void delete(T entity);
和其他操作。
还有其他抽象,例如PagingAndSortingRepository。
即 如果接口提供的列表足以与实体进行交互,则可以直接扩展实体的基本接口,并用查询方法补充基本接口并执行操作。 现在,我将简要展示最简单的情况所需的那些步骤(到目前为止,不会被配置,ORM和数据库分散注意力)。
1.创建一个实体
@Entity @Table(name = "EMPLOYEES") public class Employees { private Long employeeId; private String firstName; private String lastName; private String email;
2.继承自Spring Data接口之一,例如,继承自CrudRepository
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>
3.在客户端(服务)中使用新界面进行数据操作
@Service public class EmployeesDataService { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Transactional public void testEmployeesCrudRepository() { Optional<Employees> employeesOptional = employeesCrudRepository.findById(127L);
在这里,我使用了现成的
findById方法。 即 如此快速,轻松,无需执行,我们就可以从CrudRepository获得现成的操作列表:
S save(S var1); Iterable<S> saveAll(Iterable<S> var1); Optional<T> findById(ID var1); boolean existsById(ID var1); Iterable<T> findAll(); Iterable<T> findAllById(Iterable<ID> var1); long count(); void deleteById(ID var1); void delete(T var1); void deleteAll(Iterable<? extends T> var1); void deleteAll();
显然,此列表很可能不足以与实体进行交互,因此您可以在此处使用其他查询方法来扩展界面。
2.从方法名称中查询方法
可以直接从方法名称构建对实体的请求。 为此,使用...前缀,从...读取,通过...,通过查询...通过,计数...通过和获取...通过前缀,从方法前缀开始,它开始解析其余部分。 介绍性句子可能包含其他表达,例如Distinct。 接下来,第一个By用作分隔符,以指示实际标准的开始。 您可以定义实体属性的条件,并使用And和Or组合它们。 例子
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long> {
该文档定义了整个列表以及编写方法的规则。 结果可以是实体T,可选,列表,流。 在诸如Idea的开发环境中,存在用于编写查询方法的提示。
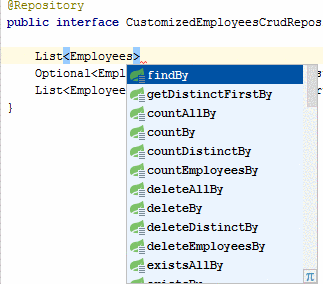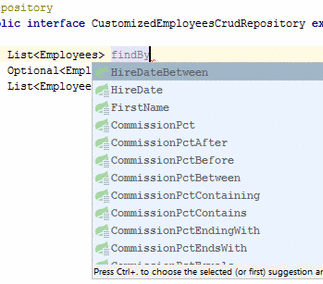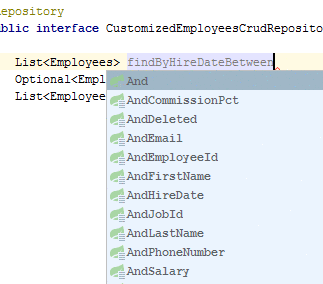
以这种方式定义方法就足够了,而无需实现,Spring会为该实体准备一个请求。
@SpringBootTest public class DemoSpringDataApplicationTests { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Test @Transactional public void testFindByFirstNameAndLastName() { Optional<Employees> employeesOptional = employeesCrudRepository.findByFirstNameAndLastName("Alex", "Ivanov");
3.配置和设置
整个项目可在github上找到
github DemoSpringData在这里,我仅涉及一些功能。
TransactionManager,dataSource和EntityManagerFactory Bean在context.xml中定义。 重要的是在其中也要指出
<jpa:repositories base-package="com.example.demoSpringData.repositories"/>
定义存储库的路径。
EntityManagerFactory配置为可与Hibernate ORM一起使用,而后者又与Oracle XE数据库一起使用,这里的其他选项也是可能的,在context.xml中所有这些都是可见的。 pom文件具有所有依赖性。
4.特殊处理参数
在查询方法的参数中,可以使用特殊参数Pageable,Sort以及限制Top和First。
例如,这样,您可以获取第二页(索引为-0),三个元素的大小并按firstName排序,在存储库方法中指定Pageable参数后,还将使用方法名称中的条件-“以%„开头的FirstName搜索
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long> { List<Employees> findByFirstNameStartsWith(String firstNameStartsWith, Pageable page);
5.存储库的定制实现
假设您在存储库中需要一个无法用方法名称描述的方法,那么您可以使用自己的接口及其实现类来实现它。 在下面的示例中,我将向存储库添加一种获取最高薪水的员工的方法。
声明界面
public interface CustomizedEmployees<T> { List<T> getEmployeesMaxSalary(); }
实现接口。 使用HQL(SQL),我可以获得最高薪水的员工,其他实现也是可能的。
public class CustomizedEmployeesImpl implements CustomizedEmployees { @PersistenceContext private EntityManager em; @Override public List getEmployeesMaxSalary() { return em.createQuery("from Employees where salary = (select max(salary) from Employees )", Employees.class) .getResultList(); } }
并通过CustomizedEmployees扩展Crud Repository员工。
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>, CustomizedEmployees<Employees>
这里有一个重要功能。 类实现接口应在
Impl上结束(后缀),或在需要放置后缀的配置中结束
<repositories base-package="com.repository" repository-impl-postfix="MyPostfix" />
通过存储库检查此方法的操作
public class DemoSpringDataApplicationTests { @Autowired private CustomizedEmployeesCrudRepository employeesCrudRepository; @Test @Transactional public void testMaxSalaryEmployees() { List<Employees> employees = employeesCrudRepository.getEmployeesMaxSalary(); employees.stream() .forEach(e -> System.out.println(e.getFirstName() + " " + e.getLastName() + " " + e.getSalary())); }
另一种情况是,有必要在Spring接口中
更改现有方法的行为时 ,例如,在CrudRepository中删除,我需要设置一个删除标志,而不是从数据库中删除。 技术完全相同。 下面是一个示例:
public interface CustomizedEmployees<T> { void delete(T entity);
现在,如果您在employeeCrudRepository中调用
delete ,则该对象将仅被标记为已删除。
6.用户库
在上一个示例中,我展示了如何在Crud中重新定义实体的删除存储库,但是如果您需要对所有项目实体都进行此操作,则使自己的接口对每个对象都不太好...然后在Spring数据中您可以配置基本存储库。 为此:
声明了一个接口,并在其中声明了一个重写方法(或对所有项目实体都通用)。 在这里,对于我所有的实体,我都介绍了我的
BaseEntity接口(这不是必需的),为了方便调用通用方法,其方法与实体的方法一致。
public interface BaseEntity { Boolean getDeleted(); void setDeleted(Boolean deleted); }
在配置中,您需要指定此基础存储库,这对于所有项目存储库都是通用的
<jpa:repositories base-package="com.example.demoSpringData.repositories" base-class="com.example.demoSpringData.BaseRepositoryImpl"/>
现在,Employees Repository(及其他)必须从BaseRepository扩展,并已在客户端中使用。
public interface EmployeesBaseRepository extends BaseRepository <Employees, Long> {
检查EmployeesBaseRepository
public class DemoSpringDataApplicationTests { @Resource private EmployeesBaseRepository employeesBaseRepository; @Test @Transactional @Commit public void testBaseRepository() { Employees employees = new Employees(); employees.setLastName("Ivanov");
现在,与以前一样,该对象将被标记为已删除,并且将对扩展BaseRepository接口的所有实体执行此操作。 在该示例中,使用了搜索方法-
按示例查询(QBE) ,在此不再赘述,该示例说明了它的功能,既简单又方便。
7.查询方法- 查询
先前,我写道,如果您需要使用方法名称无法描述的特定方法或其实现,则可以通过一些Customized接口(CustomizedEmployees)并进行计算实现。 您还可以通过指示查询(HQL或SQL)来选择如何计算此函数的方法。
在我的getEmployeesMaxSalary示例中,此实现选项更加简单。 我将用薪金输入参数使其复杂化。 即 在接口中声明计算方法和请求就足够了。
@Repository public interface CustomizedEmployeesCrudRepository extends CrudRepository<Employees, Long>, CustomizedEmployees<Employees> { @Query("select e from Employees e where e.salary > :salary") List<Employees> findEmployeesWithMoreThanSalary(@Param("salary") Long salary, Sort sort);
检查中
@Test @Transactional public void testFindEmployeesWithMoreThanSalary() { List<Employees> employees = employeesCrudRepository.findEmployeesWithMoreThanSalary(10000L, Sort.by("lastName"));
我只会提到可以修改的请求,为此会向它们添加一个额外的
@Modifying注释
@Modifying @Query("update Employees e set e.firstName = ?1 where e.employeeId = ?2") int setFirstnameFor(String firstName, String employeeId);
Query批注的另一个重要功能是通过SpEL表达式使用模板
#{# EntityName
}将实体域类型替换为查询。
因此,例如,在我的假设示例中,当我需要为所有实体使用“已删除”符号时,我将使用一种获取带有“已删除”或“活动”符号的对象列表的方法来构成基本界面
@NoRepositoryBean public interface ParentEntityRepository<T> extends Repository<T, Long> { @Query("select t from #{#entityName} t where t.deleted = ?1") List<T> findMarked(Boolean deleted); }
此外,实体的所有存储库都可以从中扩展。 不是存储库,但是位于“基本软件包”配置文件夹中的接口,对@NoRepositoryBean进行注释。
员工资料库
@Repository public interface EmployeesEntityRepository extends ParentEntityRepository <Employees> { }
现在,当执行请求时,实体名称
T将替换为请求主体中的特定存储库,该存储库将扩展ParentEntityRepository(在本例中为Employees)。
检查一下
@SpringBootTest public class DemoSpringDataApplicationTests { @Autowired private EmployeesEntityRepository employeesEntityRepository; @Test @Transactional public void testEntityName() { List<Employees> employeesMarked = employeesEntityRepository.findMarked(true);
用料
Spring Data JPA-参考文档在github上的项目 。