TL 博士
我们提高了集群,以使用ingress , letsencrypt服务无状态 Web应用程序,而无需使用kubespray,kubeadm等自动化工具。
阅读时间:〜45-60分钟,播放时间:3小时起。
前言
我需要自己的Kubernetes集群进行实验,提示我写一篇文章。 在我的情况下,开源自动安装和配置解决方案不起作用,因为我使用了非主流Linux发行版。 在IPONWEB中与kubernetes进行深入的合作会鼓励您拥有这样一个平台,以舒适的方式解决您的任务,包括用于家庭项目。
组成部分
以下组件将出现在文章中:
- 您最喜欢的 Linux-我使用了Gentoo(node-1:systemd / node-2:openrc),Ubuntu 18.04.1。
-Kubernetes服务器 -kube-apiserver,kube-controller-manager,kube-scheduler,kubelet,kube-proxy
- 容器 + CNI插件(0.7.4) -为了进行容器化,我们将使用容器+ CNI代替docker(尽管最初整个配置都已上传到docker,所以在必要时不会阻止任何使用)。
-CoreDNS-用于组织在kubernetes集群中工作的组件的服务发现。 推荐使用不低于1.2.5的版本,因为此版本对coredns起到了健全的支持,使其可以在集群外部运行。
- 法兰绒 -用于组织网络堆栈,在彼此之间通信炉床和容器。
- 您最喜欢的数据库。

局限性和假设
- 本文不讨论市场上vps / vds解决方案的成本,也不考虑在这些服务上部署计算机的可能性。 假定您已经进行了扩展,或者您可以自己进行扩展。 此外,如果需要,还不会涵盖您喜欢的数据库和私有Docker存储库的安装/配置。
- 我们可以同时使用容器+ cni插件和docker。 本文不考虑将Docker用作容器化工具。 如果要使用docker,您自己可以相应地配置法兰绒 ,此外,您还需要配置kubelet,即删除与containerd相关的所有选项。 如我的实验所示,将docker和container放置在不同的节点上,因为容器可以正常工作。
- 我们无法将
host-gw后端用于法兰绒,请阅读“ 法兰绒配置”部分以获取更多详细信息 - 我们将不会使用任何东西来监视,备份,保存用户文件(状态),存储配置文件和应用程序代码(git / hg / svn /等)
引言
在工作过程中,我使用了大量资源,但我想分别提及一个相当详尽的Kubernetes困难方法指南,该指南涵盖了其集群基本配置的90%。 如果您已经阅读了本手册,则可以安全地直接进入“ Flannel Configuration”部分。
名称术语/词汇表
- api-server-物理或虚拟机,用于运行和正确运行kubernetes kube-apiserver的一组应用程序位于其中。 出于本文的目的,它是etcd,kube-apiserver,kube-controller-manager,kube-scheduler。
- master-专用工作站或VPS安装,是api-server的同义词。
- node-X-专用工作站或VPS安装,
X表示工作站的序列号。 在本文中,所有数字都是唯一的,是理解的关键:
- vCPU-虚拟CPU,处理器核心。 该数目与内核数相对应:1vCPU-一个内核,2vCPU-两个,依此类推。
- 用户-用户或用户空间。 在命令行指令中使用
user$时,该术语指的是任何客户端计算机。 - worker-将在其上执行直接计算的工作节点,与
node-X - 资源是Kubernetes集群所基于的实体。 Kubernetes资源包括大量相关实体 。
网络架构解决方案
在提高集群的过程中,我没有将优化铁资源的任务设置为适合每月20美元的预算。 只需要组装一个至少包含两个工作节点(节点)的工作集群。 因此,群集最初看起来像这样:
- 具有2个vCPU / 4G RAM的计算机:api服务器+节点1 [20 $]
- 带2个vCPU / 4G RAM的计算机:node-2 [$ 20]
在集群的第一个版本工作之后,我决定对其进行重建,以便区分负责在集群中运行应用程序的节点(工作节点,它们也是工作节点)和主服务器的API。
结果,我得到了以下问题的答案:“如果我不想在其中放置最厚的应用程序,那么如何获得一个或多或少便宜但运行良好的群集。”
$ 20决定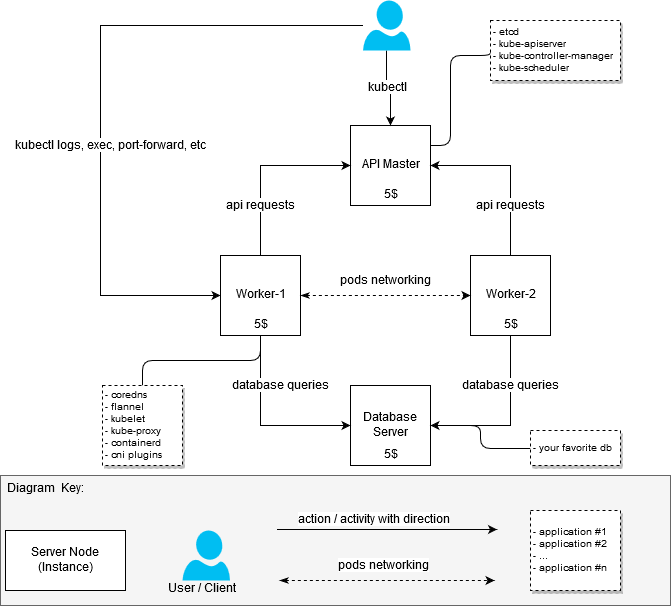
(计划是这样)
Kubernetes Architecture一般信息
(如果某人突然仍然不知道或没有看到,则从互联网上窃取)
组件及其性能
第一步是了解我需要多少资源才能运行与群集直接相关的软件包。 搜索“硬件需求”并没有给出具体结果,因此我不得不从实际的角度来解决这个任务。 作为对MEM和CPU的度量,我从systemd那里获得了统计数据-我们可以假设测量是以非常业余的方式进行的,但是我没有获得准确值的任务,因为我仍然找不到每实例5美元以下的更便宜的选择。
为什么要5美元呢?在俄罗斯或独联体国家/地区托管服务器时,可能会发现VPS / VDS便宜,但与ILV及其行动有关的悲惨故事带来了一定的风险,并自然而然地希望避免这种情况。
因此:
- 主服务器/服务器配置(主节点):
- etcd(3.2.17):80-100M,指标是在随机选择的时间获得的。 Etcd平均内存消耗不超过300M;
- kube-apiserver(1.12.x-1.13.0):237.6M〜300M;
- kube-controller-manager(1.12.x-1.13.0):大约9000万,没有超过100M;
- kube-scheduler(1.12.x-1.13.0):大约20M,超过30-50M的消耗量是固定的。
- 工作服务器配置(工作节点):
- kubelet(1.12.3-1.13.1):大约35 Mb,50M以上的消耗量不是固定的;
- kube-proxy(1.12.3-1.13.1):大约7.5-10M;
- 法兰绒(0.10.0):大约15-20M;
- coredns(1.3.0):约2500万;
- containerd(1.2.1):容器使用率很低,但统计数据还显示守护程序启动的容器进程。
主节点上是否需要容器/泊坞窗?不,不需要 。 主节点不需要docker或容器本身,尽管Internet上有大量手册出于某些目的或其他目的包括使用环境进行容器化。 在有问题的配置中,有意从依赖项列表中关闭了containerd,但是,我没有强调这种方法的任何明显优势。
上面提供的配置很小,足以启动集群。 除非您要添加任何内容,否则不需要其他操作/组件。
要构建用于家庭项目的测试群集或群集,主节点可以正常运行1vCPU / 1G RAM。 当然,主节点上的负载将根据所涉及的工作程序数量以及向api服务器发送的第三方请求的可用性和数量而有所不同。
我按如下所示分解了主配置和工作配置:
- 1个具有已安装组件的Master:etcd,kube-apiserver,kube-controller-manager,kube-scheduler
- 2x具有已安装组件的工作者:容器,coredns,法兰绒,kubelet,kube-proxy
构型
要配置向导,需要以下组件:
etcd-用于存储api服务器以及法兰绒的数据;
kube-apiserver-实际上是api-server;
kube-controller-manager-用于生成和处理事件;
kube-scheduler-用于分配通过api服务器注册的资源-例如, hearth 。
对于主力配置,需要以下组件:
kubelet-运行炉膛,配置网络设置;
kube-proxy-用于组织kubernetes 服务的路由/平衡;
coredns-用于在正在运行的容器中发现服务;
法兰绒-用于组织在不同节点上运行的容器的网络访问,以及用于在群集节点(kubernetes节点)之间动态分配网络。
核心域名这里应该做个小题外话:coredns也可以在主服务器上启动。 除了coredns.service配置的细微差别外,没有其他限制会迫使coredns在工作节点上运行,该配置细微差别是由于与systemd-resolved服务冲突而根本无法在标准/未修改的Ubuntu服务器上启动。 我没有尝试解决此问题,因为位于工作节点上的2 ns服务器对我很满意。
为了不浪费时间现在熟悉组件配置过程的所有细节,我建议您在Kubernetes困难方法指南中熟悉它们。 我将重点介绍配置选项的独特功能。
档案
为了方便起见,所有用于向导和工作节点的集群组件运行的文件都放在/ var / lib / kubernetes /中。 如有必要,可以用其他方式放置它们。
资质认证
生成证书的基础仍然是Kubernetes的艰辛方式 ,实际上没有明显差异。 为了重新生成从属证书,围绕cfssl应用程序编写了简单的bash脚本-这在调试过程中非常有用。
您可以使用下面的脚本, Kubernetes的硬方法或其他合适的工具来生成满足您需求的证书。
使用bash脚本生成证书您可以在此处获取脚本: kubernetes bootstrap 。 开始之前,编辑文件certs / env.sh ,指定设置。 一个例子:
$ cd certs
如果您使用env.sh并正确指定了所有参数,则无需触摸生成的证书。 如果您在某个时候犯了一个错误,那么可以分部分地重新生成证书。 上面的bash脚本很简单,将它们整理出来并不困难。
重要说明-您不应该经常重新创建ca.pem和ca-key.pem证书,因为它们是所有后续证书的根证书,换句话说,您将必须重新创建所有附带的证书,并将它们交付给所有计算机和所有必要的目录。
大师
在主节点上启动服务所需的证书应放在/var/lib/kubernetes/ :
- kubernetes-key.pem-保留在主服务器上。
- service-account.pem-仅kube-controller-manager守护程序需要。
- service-account-key.pem-类似。
工作单位
- ca.pem-工作节点上涉及的所有服务(kubelet,kube-proxy)以及法兰绒,coredns所需的。 其中,使用kubectl生成时,其内容包含在kubeconfig文件中。
- kubernetes-key.pem-仅用于法兰绒和coredns连接到位于api主节点上的etcd。
- kubernetes.pem-与前一个类似,仅法兰绒和coredns才需要。
- kubelet / node-1.pem-授权节点1的密钥。
- kubelet / node-1-key.pem-授权节点1的密钥。
重要! 如果您有多个节点,则每个节点将在kubelet中包含node-X-key.pem , node-X.pem和node-X.kubeconfig文件。
证书调试证书调试
有时您可能需要查看证书的配置方式,以找出用于生成证书的IP / DNS主机。 cfssl-certinfo -cert <cert>命令将帮助我们解决此问题。 例如,我们了解有关node-1.pem :
$ cfssl-certinfo -cert node-1.pem
{ "subject": { "common_name": "system:node:node-1", "country": "RU", "organization": "system:nodes", "organizational_unit": "Infrastructure Unit", "locality": "Moscow", "province": "Moscow", "names": [ "RU", "Moscow", "Moscow", "system:nodes", "Infrastructure Unit", "system:node:node-1" ] }, "issuer": { "common_name": "Kubernetes", "country": "RU", "organization": "Kubernetes", "organizational_unit": "Infrastructure", "locality": "Moscow", "province": "Moscow", "names": [ "RU", "Moscow", "Moscow", "Kubernetes", "Infrastructure", "Kubernetes" ] }, "serial_number": "161113741562559533299282037709313751074033027073", "sans": [ "w40k.net", "node-1", "178.79.168.130", "192.168.164.230" ], "not_before": "2019-01-04T14:24:00Z", "not_after": "2029-01-01T14:24:00Z", "sigalg": "SHA256WithRSA", "authority_key_id": "6:C8:94:67:59:55:19:82:AD:ED:6D:50:F1:89:B:8D:46:78:FD:9A", "subject_key_id": "A1:5E:B3:3C:45:14:3D:C6:C:A:97:82:1:D5:2B:75:1A:A6:9D:B0", "pem": "<pem content>" }
kubelet和kube-proxy的所有其他证书直接嵌入到相应的kubeconfig中。
kubeconfig
所有必需的kubeconfig都可以使用Kubernetes艰难地完成 ,但是,这里有些区别开始了。 该手册使用kubedns和cni bridge配置,还涵盖了coredns和法兰绒 。 这两个服务依次使用kubeconfig到集群。
$ cd certs
大师
对于该向导,需要以下kubeconfig文件(如上所述,生成后可以在certs/kubeconfig ):
master /var/lib/kubernetes/$ tree -L 2 . +-- kube-controller-manager.kubeconfig L-- kube-scheduler L-- kube-scheduler.kubeconfig
这些文件是运行每个服务组件所必需的。
工作单位
对于工作节点,需要以下kubeconfig文件:
node-1 /var/lib/kubernetes/$ tree -L 2 . +-- coredns ¦ L-- coredns.kubeconfig +-- flanneld ¦ L-- flanneld.kubeconfig +-- kubelet ¦ L-- node-1.kubeconfig L-- kube-proxy L-- kube-proxy.kubeconfig
服务启动
服务项目尽管我的工作节点使用不同的初始化系统,但是示例和存储库使用systemd提供了选项。 在他们的帮助下,最容易理解您需要启动哪个过程和哪个参数,此外,在研究带有目标标志的服务时,它们不会引起大问题。
要启动服务,您需要将service-name.service复制到/lib/systemd/system/或systemd服务所在的任何其他目录,然后打开并启动该服务。 kube-apiserver的示例:
$ systemctl enable kube-apiserver.service $ systemctl start kube-apiserver.service
当然,所有服务都必须是绿色的 (即运行和运行中)。 如果遇到错误, journalct -xe或journal -f -t kube-apiserver将帮助您了解到底出了什么问题。
不要急于立即启动所有服务器,因为启动足以启用etcd和kube-apiserver。 如果一切顺利,并且您立即获得了该向导的所有四项服务,则可以将向导启动视为成功。
大师
您可以使用systemd设置或为正在使用的配置生成初始化脚本。 如前所述,对于母版,您需要:
-systemd / etcd
-systemd / kube-apiserver
-systemd / kube-controller-manager
-systemd / kube-scheduler
工作单位
- 系统化/容器化
-systemd / kubelet
-systemd / kube-proxy
-systemd / coredns
- 系统/法兰绒
顾客
为了使客户端正常工作,只需在${HOME}/.kube/config certs/kubeconfig/admin.kubeconfig复制certs/kubeconfig/admin.kubeconfig (在生成或自己编写后) ${HOME}/.kube/config
下载kubectl并检查kube-apiserver的操作。 让我再次提醒您,在此阶段,为了使kube-apiserver正常工作,只有etcd应该起作用。 稍后,群集的全部操作将需要其余组件。
检查kube-apiserver和kubectl是否工作:
$ kubectl version Client Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.0", "extra info": "..."} Server Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.0", "extra info": "..."}
绒布配置
作为法兰绒配置,我选择了vxlan后端。 在此处阅读有关后端的更多信息。
host-gw,以及为什么它不起作用我必须马上说,在VPS上运行kubernetes集群可能会限制您使用host-gw后端。 由于不是经验丰富的网络工程师,我花了大约两天的时间进行调试,以了解在流行的VDS / VPS提供商上使用它时出现的问题。
Linode.com和digitalocean已经过测试。 问题的实质是提供商没有为专用网络提供诚实的L2。 反过来,这使得在这种配置下无法在节点之间移动网络流量:
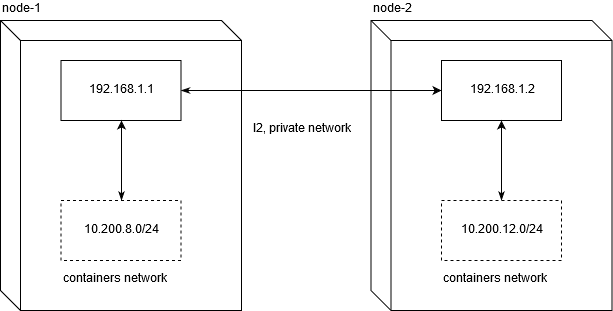
为了使网络流量能够在节点之间工作,正常的路由就足够了。 不要忘记将net.ipv4.ip_forward设置为1,并且过滤器表中的FORWARD链不应包含节点的禁止规则。
node1$ ip route add 10.200.12.0/24 via 192.168.1.2 node2$ ip route add 10.200.8.0/24 via 192.168.1.1
[10.200.80.23 container-1]->[192.168.1.1 node-1]->[192.168.1.2 node-2]->[10.200.12.5 container-2]
这恰恰对指示的VPS / VDS(并且很可能通常对所有VDS / VDS)不起作用。
因此,如果在节点之间配置具有较高网络性能的解决方案对您来说很重要,那么您仍然必须花费20多美元来组织集群。
您可以从etc / flannel使用set-flannel-config.sh来设置所需的绒布配置。 重要的是要记住 :如果决定更改后端,则需要删除etcd中的配置并重新启动所有节点上的所有法兰绒守护程序,因此请明智地选择它。 默认值为vxlan。
master$ export ETCDCTL_CA_FILE='/var/lib/kubernetes/ca.pem' master$ export ETCDCTL_CERT_FILE='/var/lib/kubernetes/kubernetes.pem' master$ export ETCDCTL_KEY_FILE='/var/lib/kubernetes/kubernetes-key.pem' master$ export ETCDCTL_ENDPOINTS='https://127.0.0.1:2379' master$ etcdctl ls /coreos.com/network/subnets/ /coreos.com/network/subnets/10.200.8.0-24 /coreos.com/network/subnets/10.200.12.0-24 master$ etcdctl get /coreos.com/network/subnets/10.200.8.0-24 {"PublicIP":"178.79.168.130","BackendType":"vxlan","BackendData":{"VtepMAC":"22:ca:ac:15:71:59"}}
在etcd中注册所需的配置后,您需要配置服务以在每个工作节点上运行它。
法兰绒服务
可以在此处使用该服务的示例: systemd / flannel
法兰绒服务 [Unit] Description=Flanneld overlay address etcd agent After=network.target [Service] Type=notify #: current host ip. don't change if ip have not changed Environment=PUBLIC_IP=178.79.168.130 Environment=FLANNEL_ETCD=https://192.168.153.60:2379 ExecStart=/usr/bin/flanneld \ -etcd-endpoints=${FLANNEL_ETCD} -etcd-prefix=${FLANNEL_ETCD_KEY} \ -etcd-cafile=/var/lib/kubernetes/ca.pem \ -etcd-certfile=/var/lib/kubernetes/kubernetes.pem \ -etcd-keyfile=/var/lib/kubernetes/kubernetes-key.pem \ -etcd-prefix=/coreos.com/network \ -healthz-ip=127.0.0.1 \ -subnet-file=/run/flannel/subnet.env \ -public-ip=${PUBLIC_IP} \ -kubeconfig-file=/var/lib/kubernetes/config/kubeconfig/flanneld.kubeconfig \ $FLANNEL_OPTIONS ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker Restart=on-failure RestartSec=5 [Install] RequiredBy=docker.service
客制化
如前所述,我们需要ca.pem,kubernetes.pem和kubernetes-key.pem文件在etcd中进行授权。 所有其他参数不具有任何神圣含义。 真正重要的唯一事情是配置全局IP地址,网络数据包将通过该IP地址在网络之间传递:
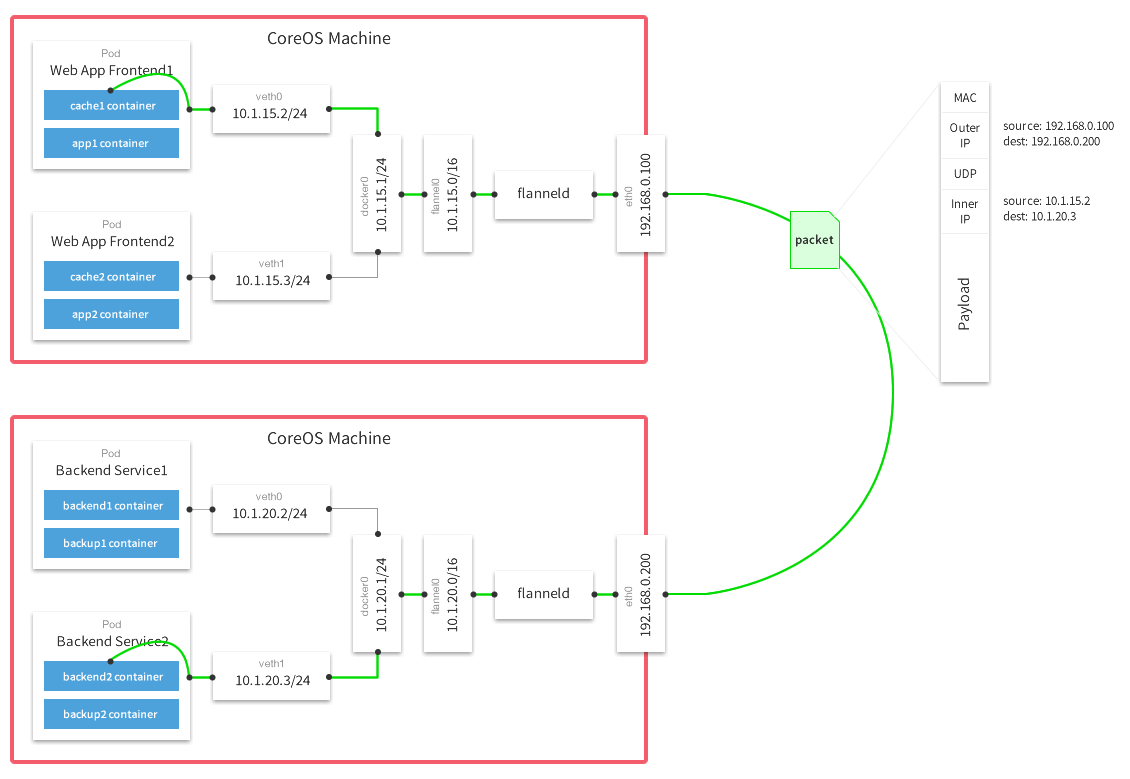
( 带法兰绒的多主机网络覆盖 )
成功启动法兰绒后,您应该在系统上找到flannel.N网络接口:
node-1$ ifconfig flannel.100: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450 inet 10.200.8.0 netmask 255.255.255.255 broadcast 0.0.0.0 inet6 fe80::20ca:acff:fe15:7159 prefixlen 64 scopeid 0x20<link> ether 22:ca:ac:15:71:59 txqueuelen 0 (Ethernet) RX packets 18853 bytes 1077085 (1.0 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 11856 bytes 264331154 (252.0 MiB) TX errors 0 dropped 47 overruns 0 carrier 0 collisions 0
检查您的接口在所有节点上是否正常工作非常简单。 在我的情况下,节点1和节点2分别具有10.200.8.0/24和10.200.12.0/24网络,因此对于常规icmp请求,我们检查其可用性:
#: node-2 node-1 node-1 $ ping -c 1 10.200.12.0 PING 10.200.12.0 (10.200.12.0) 56(84) bytes of data. 64 bytes from 10.200.12.0: icmp_seq=1 ttl=64 time=4.58 ms #: node-1 node-2 node-2 $ ping -c 1 10.200.8.0 PING 10.200.8.0 (10.200.8.0) 56(84) bytes of data. 64 bytes from 10.200.8.0: icmp_seq=1 ttl=64 time=1.44 ms
如果出现任何问题,建议检查主机之间基于UDP的iptables中是否存在任何剪切规则。
容器配置
将etc / containerded / config.toml放在/etc/containerd/config.toml或您方便的任何地方,主要要记住要更改服务中配置文件的路径(containerd.service,如下所述)。
对标准进行一些修改的配置。 如果您不了解执行此操作的原因,请不要将 enable_tls_streaming = true 设置为重要 。 否则, kubectl exec将停止工作,并给出错误消息,表明该证书是由未知方签名的。
containerd.service
containerd.service [Unit] Description=containerd container runtime Documentation=https://containerd.io After=network.target [Service] ; uncomment this if your overlay module are built as module ; ExecStartPre=/sbin/modprobe overlay ExecStart=/usr/bin/containerd \ -c /etc/containerd/config.toml Restart=always RestartSec=5 Delegate=yes KillMode=process OOMScoreAdjust=-999 LimitNOFILE=1048576 LimitNPROC=infinity LimitCORE=infinity [Install] WantedBy=multi-user.target
客制化
, , cri-tools .
etc/crictl.yaml /etc/crictl.yaml . :
node-1$ CONTAINERD_NAMESPACE=k8s.io crictl ps CONTAINER ID IMAGE CREATED STATE NAME ATTEMPT POD ID
, - kubernetes , crictl , , .
CNI Plugins
CNI , , , .
客制化
cni plugins /opt/cni/bin/
/etc/cni/net.d :
/etc/cni/net.d/10-flannel.conflist { "cniVersion": "0.3.0", "name": "cbr0", "plugins": [ { "type": "flannel", "name": "kubenet", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true }, "externalSetMarkChain": "KUBE-MARK-MASQ" } ] }
/etc/cni/net.d/99-loopback.conf { "cniVersion": "0.3.0", "type": "loopback" }
, . , , Red Hat Docker Podman , Intro to Podman
Kubelet
kubelet ( cni) — . kubelet hostname. , "" kubectl logs , kubectl exec , kubectl port-forward .
kubelet-config.yaml, etc/kubelet-config.yaml , , . :
systemReserved: cpu: 200m memory: 600Mi
, GO kubernetes, , . . 0.2 vCPU 600 MB .
, , kubelet, kube-proxy, coredns, flannel . , — 2 vCPU / 4G ram, , kubernetes + postgresql .
- (micro nodes) .
kubelet.service
service : systemd/kubelet
kubelet.service [Unit] Description=Kubernetes Kubelet Documentation=https://github.com/kubernetes/kubernetes Requires=containerd.service [Service] #Environment=NODE_IP=192.168.164.230 Environment=NODE_IP=178.79.168.130 #: node name given by env Environment=NODE_NAME=w40k.net ExecStart=kubelet \ --allow-privileged \ --root-dir=/var/lib/kubernetes/kubelet \ --config=/var/lib/kubernetes/kubelet/kubelet-config.yaml \ --kubeconfig=/var/lib/kubernetes/kubelet/node-1.kubeconfig \ --cni-bin-dir=/opt/cni/bin \ --cni-conf-dir=/etc/cni/net.d/ \ --network-plugin=cni \ --container-runtime=remote \ --container-runtime-endpoint=unix:///var/run/containerd/containerd.sock \ --image-pull-progress-deadline=10m \ --node-ip=${NODE_IP} \ --hostname-override=${NODE_NAME} \ --v=1 Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
客制化
, RBAC , kubelet.
etc/kubelet-default-rbac.yaml , kubelet :
user$ kubectl apply -f etc/kubelet-default-rbac.yaml
, , .
, api :
$ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME w40k.net Ready <none> 5m v1.13.1 178.79.168.130 <none> Gentoo/Linux 4.18.16-x86_64-linode118 containerd://1.2.1
Kube Proxy
: systemd/kubelet . , , kube-proxy-config.yaml : etc/kube-proxy
kube-proxy.service
kube-proxy.service [Unit] Description=Kubernetes Proxy Documentation=https://github.com/kubernetes/kubernetes After=network.target [Service] ExecStart=kube-proxy \ --config=/var/lib/kubernetes/kube-proxy/kube-proxy-config.yaml Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
客制化
kube-proxy "" iptables, , - kubernetes (- ). .
CoreDNS
Corefile : etc/coredns/Corefile , :
/etc/coredns/Corefile .:53 { errors log stdout health :8081 kubernetes cluster.local 10.200.0.0/16 { endpoint https://178.79.148.185:6443 tls /var/lib/kubernetes/kubernetes.pem /var/lib/kubernetes/kubernetes-key.pem /var/lib/kubernetes/ca.pem pods verified upstream /etc/resolv.conf kubeconfig /var/lib/kubernetes/config/kubeconfig/coredns.kubeconfig default } proxy . /etc/resolv.conf cache 30 }
coredns.kubeconfig pem- ( ) worker . , coredns systemd-resolved. , Ubuntu , , , , . .
coredns.service
coredns.service [Unit] Description=CoreDNS Documentation=https://coredns.io/ After=network.target [Service] ExecStart=/usr/bin/coredns -conf /etc/coredns/Corefile Restart=on-failure RestartSec=5 [Install] WantedBy=multi-user.target
客制化
, , :
node-1$ dig kubernetes.default.svc.cluster.local @127.0.0.1 #: ;kubernetes.default.svc.cluster.local. IN A ;; ANSWER SECTION: kubernetes.default.svc.cluster.local. 5 IN A 10.32.0.1
, coredns ip kubernetes .
, kubernetes.default kube-controller-manager, :
$ kubectl get svc -n default NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.32.0.1 <none> 443/TCP 26h
nginx-ingress & cert-manager
, . nginx-ingress cert-manager.
— nginx kubernetes ingress (master), :
user$ git clone https://github.com/nginxinc/kubernetes-ingress.git user$ cd kubernetes-ingress/deployments user$ kubectl apply -f common/ns-and-sa.yaml user$ kubectl apply -f common/nginx-config.yaml user$ kubectl apply -f common/default-server-secret.yaml user$ kubectl apply -f daemon-set/nginx-ingress.yaml user$ kubectl apply -f rbac/rbac.yaml
— cert manager (v0.5.2)
user$ git clone https://github.com/jetstack/cert-manager.git user$ cd cert-manager && git co v0.5.2 user$ cd contrib/manifests/cert-manager user$ kubectl apply -f with-rbac.yaml
, , , :
NAMESPACE NAME READY STATUS RESTARTS AGE cert-manager cert-manager-554c76fbb7-t9762 1/1 Running 0 3h38m nginx-ingress nginx-ingress-sdztf 1/1 Running 0 10h nginx-ingress nginx-ingress-vrf85 1/1 Running 0 10h
cert-manager nginx-ingress running state, , . , Running . .
, . , kubernetes resource : app/k8s
user$ kube apply -f ns-and-sa.yaml user$ kube apply -f configmap.yaml
, - . , ( kubernetes-example.w40k.net), , , cert-manager nginx-ingress . , ingress tls/ssl.
:
, - . - , , .
参考文献
, , :
— Kubernetes the hard way
— Multi-Host Networking Overlay with Flannel
— Intro to Podman
— Stateless Applications
— What is ingress
:
— Kubernetes Networking: Behind the scenes ( )
— A Guide to the Kubernetes Networking Model
— Understanding kubernetes networking: services ( )
Q&A
<tbd>, .
, , . , , - , , .
Api Server
kube-apiserver.service , api-server' curl http . - .
admin.kubeconfig ${HOME}/.kube/config, kubectl api-server (kube-apiserver).
( ) HTTP 200 OK + , api-server :
curl -H "Authorization: Bearer e5qXNAtwwCHUUwyLilZmAoFPozrQwUpw" -k -L https://<api-server-address>:6443/api/v1/
Kube Controller Manager
, controller manager api , . , service account' :
$ kubectl get sa NAME SECRETS AGE default 1 19h
, , kube-controller-manager .
Kube Scheduler
. , , debug/job.yaml kubectl describe <type/resource> .
, kube controller manager .
#: job user$ kubectl apply -f debug/job.yaml job.batch/app created #: , job user$ kubectl get pods -l job-name=app NAME READY STATUS RESTARTS AGE app-9kr9z 0/1 Completed 0 54s #: , #: user$ kubectl describe pods app-9kr9z # ... ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 12s default-scheduler Successfully assigned example/app-9kr9z to w40k.net
, default-scheduler pod w40k.net. - , — .
. , , , — "". systemd .
kube scheduler
Kubelet
Kubelet kubernetes . kubelet . kubernetes event ( kubectl get events -o wide ) .
( )
Kube Proxy
kube-proxy :
- ( Flannel , );
- iptables, filter nat .
, 10.32.0.0/24 "". , . iptables, , , - +. icmp , ping' . , .
, kube-proxy, :
#: user$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE backend ClusterIP 10.32.0.195 <none> 80/TCP 5m #: user$ kubectl get pods -o wide #: ' NAME READY STATUS RESTARTS AGE IP NODE backend-896584448-4r94s 1/1 Running 0 11h 10.200.8.105 w40k.net backend-896584448-np992 1/1 Running 0 11h 10.200.12.68 docker.grart.net #: 10 /status/ endpoint , #: node-1$ for i in `seq 10`; do curl -L http://10.32.0.195/status/; done okokokokokokokokokok node-1$ conntrack -L -d 10.32.0.195 tcp 6 62 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62158 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62158 [ASSURED] mark=0 use=1 tcp 6 60 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62144 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62144 [ASSURED] mark=0 use=1 tcp 6 58 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62122 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62122 [ASSURED] mark=0 use=1 tcp 6 59 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62142 dport=80 src=10.200.8.105 dst=10.200.8.1 sport=8000 dport=62142 [ASSURED] mark=0 use=1 tcp 6 58 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62130 dport=80 src=10.200.8.105 dst=10.200.8.1 sport=8000 dport=62130 [ASSURED] mark=0 use=1 tcp 6 61 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62150 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62150 [ASSURED] mark=0 use=1 tcp 6 56 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62116 dport=80 src=10.200.8.105 dst=10.200.8.1 sport=8000 dport=62116 [ASSURED] mark=0 use=1 tcp 6 57 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62118 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62118 [ASSURED] mark=0 use=1 tcp 6 59 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62132 dport=80 src=10.200.12.68 dst=10.200.8.0 sport=8000 dport=62132 [ASSURED] mark=0 use=1 tcp 6 56 TIME_WAIT src=178.79.168.130 dst=10.32.0.195 sport=62114 dport=80 src=10.200.8.105 dst=10.200.8.1 sport=8000 dport=62114 [ASSURED] mark=0 use=1
src/dst (9 10 ). , src :
, . , - ( , ) . .
, , conntrack , , kube-proxy. , nat :
node-1$ iptables -t nat -vnL
.
. , , . , . - , , .