2018年4月。 当时我14岁。我和我的朋友们随后参加了VKontakte上非常受欢迎的在线测验“ Clover”。 我们中的一个人(通常是我)总是在笔记本电脑后面,试图快速搜索Google问题并浏览搜索结果以获取正确答案。 但是突然间,我意识到自己每次都在做同样的事情,因此决定尝试用Python 3编写它,那时我对它不了解。
步骤0。这是怎么回事?
首先,我将在您的记忆中刷新“三叶草”的原理。
每个人的游戏同时开始-莫斯科时间13:00和20:00。 要播放,您需要此时进入应用程序并连接到直播。 游戏持续15分钟,在此期间,问题会
同时通过电话发送给参与者。 答案是
10秒。 然后宣布正确答案。 所有猜到的人都走得更远。 共有12个问题,如果您回答所有问题,您将获得现金奖励。
事实证明,我们的任务是立即从三叶草服务器中捕获新问题,通过搜索引擎对其进行处理,并根据搜索结果确定正确答案。 决定将答案输出到电报机器人中,以便在比赛期间直接在电话上弹出来自该机器人的通知。 由于响应时间非常有限,因此所有这些操作都需要在几秒钟内完成。 如果您想看看一个相当简单而又有效的代码(对于初学者来说很有用)如何帮助我们击败了Clover,欢迎您切入。
步骤1.从服务器获取问题
起初,这似乎是最困难的阶段。 我已经深吸了一口气,准备好像计算机视觉,拦截流量或对应用程序进行反编译一样疯狂……当突然出现一个惊喜等待着我时-Clover拥有开放的API! 它没有记录在任何地方,但是如果在游戏过程中,一旦所有玩家被问到一个问题,就在api.vk.com上提出一个请求,然后作为回报,我们将以JSON的形式获得所问的问题和答案选项:
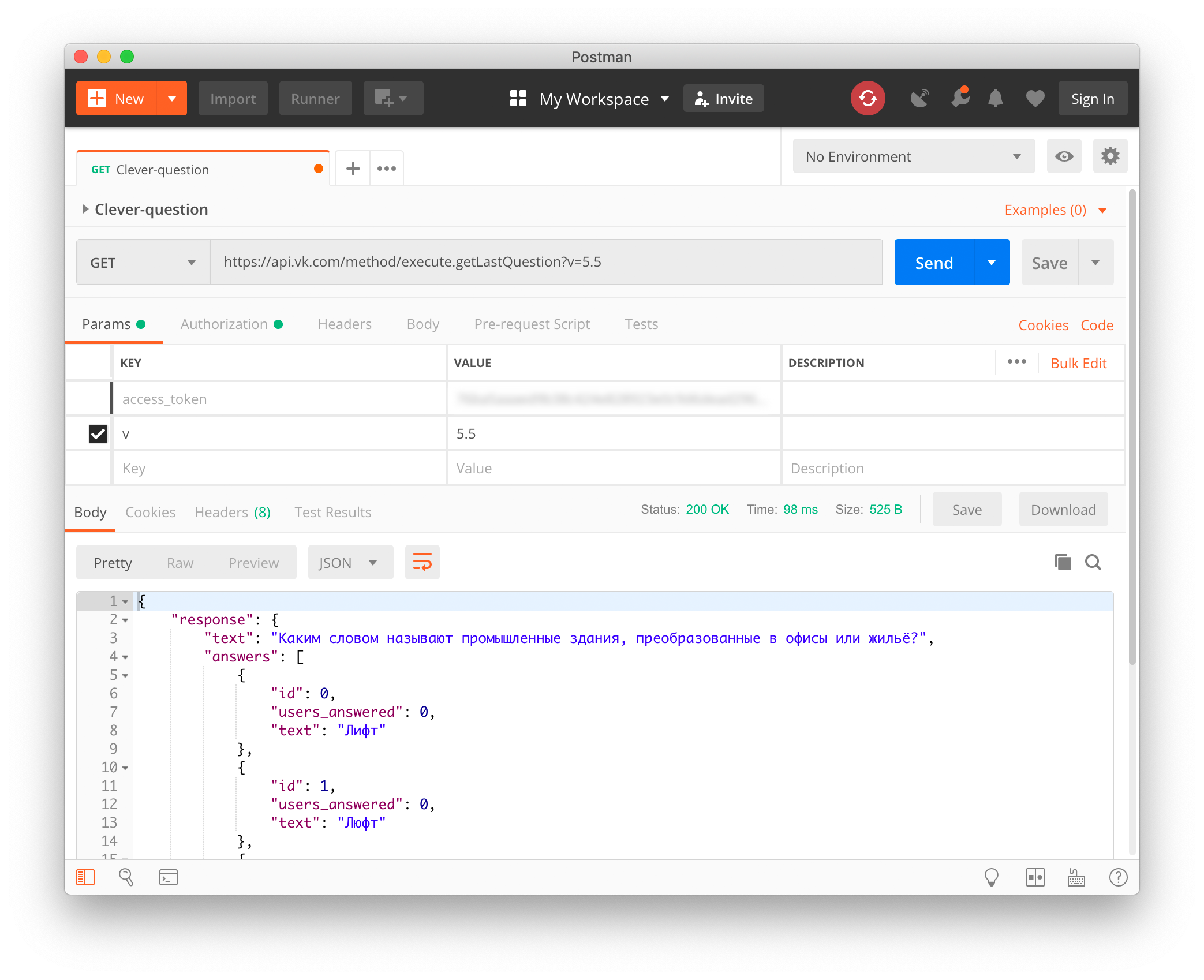
https://api.vk.com/method/execute.getLastQuestion?v=5.5&access_token=VK_USER_TOKEN
作为access_token,有必要转移任何VKontakte用户的API令牌,但重要的是它最初是专门为Clover发行的。 他的app_id是6334949。
第2步。我们通过搜索引擎处理问题
有两种选择:使用正式的搜索引擎API或将搜索参数直接添加到地址栏,然后解析结果。 最初,我尝试了第二个,但是有时我不但会捕获验证码,而且还浪费了很多时间,因为页面平均加载时间为2秒。 我想提醒您,我们最好在这两秒钟内见面。 好吧,最重要的是-我没有从搜索引擎上获得关于必要主题的大而结构化的文本,因为在搜索页面上只有一小部分必要的材料(称为
摘要)挂着:

因此,我开始寻找API。 Google不合适-他们的解决方案非常有限,返回的数据很少。
事实证明,
Yandex.XML是最慷慨的-它允许您每天发送10,000个请求,而不是每秒发送5个,并非常快速地返回数据。 对它的请求可选地是页数(最多100页)和段落数-用于形成摘要的特殊值。 我们以XML获取数据。 但是,这些都是相同的片段。
为了让您熟悉和体验Yandex的回报,以下是一个查询示例的回答示例:“视频系列“塞尔达传说”中主要对手的名字是什么?:
Yandex。 驱动器 。
我很幸运,事实证明,在pypi中,已经存在一个单独的
yandex-search模块。 因此,我尝试从服务器上获取问题,在Yandex中找到问题,从摘要中提取一个大文本并将其分解为句子:
import requests as req import yandex_search import json apiurl = "https://api.vk.com/method/execute.getLastQuestion?access_token=VK_USER_TOKEN&v=5.5" clever_response = (json.loads(req.get(apiurl).content))["response"]
步骤3.搜索答案
最初,根据代码片段准确识别答案的任务对我来说似乎是不切实际的(我想提醒您,在编写代码时,我是绝对的初学者)。 因此,我决定首先简化通过手动搜索执行的任务。
将我们的问题带入搜索引擎时,我和我的朋友做了什么? 他们开始迅速通过眼睛寻找结果的答案。 这种方法有什么问题? 在
多字母形式中,有很多不必要的内容,其中不包含有关答案和建议的信息。 有时用我的眼睛进行搜索需要很长时间。 因此,我决定要做的第一件事是选择所有提及任何答案的句子并显示它们,以便我们在很小的文本中寻找答案,该文本准确地包含了我们所需要的信息。
hint = []
似乎可以得到正确的报价,阅读并正确回答。 但是,如果我们找不到一个句子怎么办? 在这种情况下,我决定修剪单词以免在其他情况下漏掉它们。 并捕获从源头形成的那些。 简而言之,我只是将它们的结尾修剪成两个字符:
if len(hint) == 0: def cut(string): if len(string) > 2: return string[0:-2] else: return string short_ans1, short_ans2, short_ans3 = cut(ans1), cut(ans2), cut(ans3) for pred in itemslist:
但是即使有了这样的安全网,仍然有一些提示仍然为空的情况,仅仅是因为结果并不总是触及答案。 说到问题
“这些作家中有谁有一个故事,就像第2组的歌曲一样命名?” 找不到确切答案。 在这种情况下,我采取了相反的方法-我询问了答案,并根据结果中提到问题的单词的频率推导出了选择。
if len(hint) == 0: questionlist = question.split(" ") blacklist = ["", "", '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', ''] for w in questionlist: if w in blacklist: questionlist.remove(w) yandex_ans1 = yandexfind(ans1) yandex_ans2 = yandexfind(ans2) yandex_ans3 = yandexfind(ans3)
至此,脚本获得了基本功能。 而现在,在四叶草发布仅一个半星期之后,我们就坐在那里并且已经在玩这种自制的“骗子”。 当我们第一次
赢得比赛时,应该通过阅读命令行上的建议就像魔术一样,看到了我们与朋友的面孔!
步骤4.显示明确答案
但是很快这种格式很累。 首先,每场比赛您都必须坐在笔记本电脑前。 其次,我的朋友们要求提供脚本,我厌倦了向所有人解释如何插入其VKontakte令牌,如何配置Yandex.XML(它与IP绑定,即必须为脚本的每个用户创建一个帐户)以及如何在计算机上安装python。
如果在比赛期间在手机的推送通知中弹出答案,那就更好了! 只需查看屏幕顶部并回答推送通知中的内容即可! 如果您为脚本创建电报频道,则可以为每个人组织此活动! 太好了!
但是,仅以电报显示相同的句子是不可行的。 从手机读取它们非常不方便。 因此,我必须自己学习脚本以了解哪个答案是正确的。
我们导入
telebot并将所有
print()函数更改为
send_tg()和
notsure() ,我们将在最后一种方法中使用它们,因为它比其他方法更容易丢失:
def send_tg(ans): bot.send_message("@autoclever", str(ans).capitalize()) print(str(ans)) return def notsure(ans): send_tg(ans.capitalize() + ". !") hint.append("WE TRIED!")
在那一刻,我意识到摘要比长篇文章要好得多! 因为搜索引擎非常努力地为我们的请求
提供答案 ,而不仅仅是查找单词匹配项。 他成功了-片段通常包含正确的答案,而不是错误的答案,也就是说,无需分析文本。 而且我实际上不知道如何。
因此,我们很容易计算结果中单词的提及:
anscounts = { ans1: 0, ans2: 0, ans3: 0 } for s in hint: for a in [ans1, ans2, ans3]: anscounts[a] += s.count(a) right = (max(anscounts, key=anscounts.get)) send_tg(right)
结果是什么:

进一步的命运
公平地说,我必须说我没有在死亡机器上获得成功。 平均而言,机器人在12个问题中仅正确回答了9-10个问题。 这是可以理解的,因为有些棘手的人没有屈服于Yandex搜索的解析。 我和我的朋友们厌倦了不断地提出一些问题并等待成功的游戏,机器人最终将正确回答所有问题。 奇迹没有发生,我真的不想再修改脚本了,然后,由于不再希望获得轻松的胜利,我们放弃了游戏。
随着时间的流逝,我的想法开始渗入其他年轻开发人员的头脑。 到2018年日落时,至少有10个机器人和站点对三叶草中的问题进行了猜测。 任务不是那么困难。 但是令人惊讶的是,他们中没有一个人每场比赛都能碰到9-10个问题,后来像我的机器人一样,所有问题都降到了7-8个问题。 显然,问题的编辑者清楚地说明了如何构成问题,从而使搜索引擎的工作无关紧要。
不幸的是,该机器人无法最终确定下来,因为12月31日,四叶草花了最后的广播,而且我没有任何疑问。 但是,对于新手程序员而言,这是一次很棒的经验。 当然,高级用户肯定会面临巨大挑战-想象一下word2vec和text2vec二重奏,同时向Yandex,Google和Wikipedia发送异步请求,高级问题分类器以及在出现故障的情况下重新格式化问题的算法……嗯! 也许,对于这样的机会,我更喜欢这款游戏,而不是游戏本身。