以每秒超过10亿帧的速度,可以说这是世界上最快的8位控制台集群。
 分布式俄罗斯方块(1989)
分布式俄罗斯方块(1989)如何建立这样的计算机?
食谱
掌握少量硅材料,进行强化培训,体验超级计算机,对计算机体系结构充满热情,多加汗水和眼泪,搅拌1000小时直至沸腾-瞧。
为什么有人需要这样的计算机?
简而言之:走向增强人工智能。
 用于实验的48个IBM神经计算机板之一
用于实验的48个IBM神经计算机板之一这是更详细的版本
2016年 深度学习无处不在。 借助卷积神经网络,可以将图像识别视为已解决的任务,我的研究兴趣是寻求具有记忆力和增强学习能力的神经网络。
具体来说,在谷歌Deepmind的作者著作中,证明了使用Deep Q神经网络支持的简单学习算法,可以在Atari 2600(家用游戏机,于1977年发布)的各种游戏中达到人的水平甚至超越人的水平。 所有这一切仅在查看游戏玩法时发生。 它引起了我的注意。
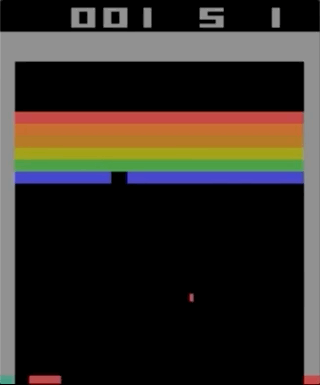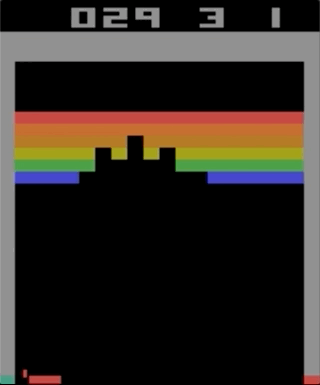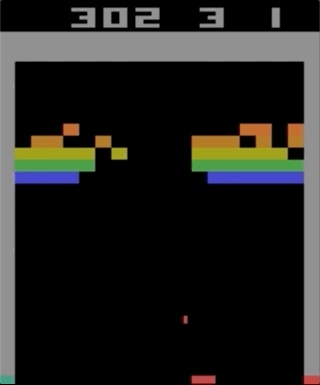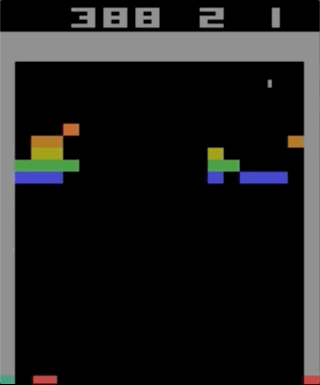 Atari 2600的其中一款游戏Breakout。 使用简单的强化学习算法对机器进行了培训。 经过数百万次迭代,计算机开始比人类玩得更好。
Atari 2600的其中一款游戏Breakout。 使用简单的强化学习算法对机器进行了培训。 经过数百万次迭代,计算机开始比人类玩得更好。我开始尝试使用Atari 2600游戏,虽然突破令人印象深刻,但不能称其为复杂。 难度可以根据您的动作(游戏杆)和结果(点)的难度来确定。 当效果需要等待很长时间时,会出现问题。
 以更复杂的游戏为例说明问题。 左-Breakout(ATARI 2600)[作者输入错误,这是一个Pong游戏/大约。 跨]],因此响应速度非常快,反馈也很快。 正确-Mario Land(任天堂游戏男孩)没有提供有关动作效果的即时信息;在两个重要事件之间可能会出现长时间无关的观察。
以更复杂的游戏为例说明问题。 左-Breakout(ATARI 2600)[作者输入错误,这是一个Pong游戏/大约。 跨]],因此响应速度非常快,反馈也很快。 正确-Mario Land(任天堂游戏男孩)没有提供有关动作效果的即时信息;在两个重要事件之间可能会出现长时间无关的观察。为了使学习更有效,人们可以想象尝试从更简单的游戏中转移一些知识的尝试。 该任务现在仍未解决,并且是研究的活跃主题。 OpenAI最近发布的
一项任务正在尝试对此进行衡量。
传递知识的能力不仅会加快培训的速度-我认为,如果缺少基础知识,则根本无法解决某些学习问题。 我们需要数据效率。 以游戏波斯王子:

没有明显的要点。
完成游戏需要60分钟。

是否可以采用在Atari 2600上编写作品时使用的相同方法? 通过按随机键结束的可能性有多大?
这个问题促使我为社区做出贡献,这包括尝试解决这个问题。 实际上,我们有鸡和鸡蛋的任务-我们需要一种更好的算法来允许我们传输消息,但这需要进行研究,并且实验耗时,因为我们没有更有效的算法。
 知识转移的一个示例:假设我们首先学会玩简单的游戏,例如左边的游戏。 然后我们保存诸如“竞赛”,“汽车”,“赛道”,“获胜”之类的概念,并学习颜色或三维模型。 我们认为,通用概念可以在游戏之间“延续”。 游戏的相似性可以通过它们之间传递的知识数量来确定。 例如,俄罗斯方块和F1游戏将不会相似。
知识转移的一个示例:假设我们首先学会玩简单的游戏,例如左边的游戏。 然后我们保存诸如“竞赛”,“汽车”,“赛道”,“获胜”之类的概念,并学习颜色或三维模型。 我们认为,通用概念可以在游戏之间“延续”。 游戏的相似性可以通过它们之间传递的知识数量来确定。 例如,俄罗斯方块和F1游戏将不会相似。因此,我决定使用第二种理想方法,避免了最初的速度下降,从而极大地加快了系统速度。 我的目标是:
-加速的环境(假设波斯王子可以完成100倍的完成速度),并同时启动100,000款游戏。
-更适合研究的环境(我们专注于任务,而不是初步计算,我们可以使用各种游戏)。
最初,我认为性能瓶颈可能某种程度上取决于仿真器代码的复杂性(例如,Stella代码库很大,并且它依赖于C ++抽象,而不是仿真器的最佳选择)。
游戏机

总的来说,我在多个平台上工作,从有史以来最早的一款游戏(以及Pong游戏)开始,这些游戏是Arcade Space Invaders,Atari 2600,NES和Game Boy。 所有这些都是用C编写的。
我设法达到每秒2000-3000的最大帧速率。 要开始获得实验结果,我们需要数百万或数十亿个帧,因此差距很大。
 Space Invaders在FPGA中工作-低速调试模式。 FPGA计数器显示已过去的时钟周期数。
Space Invaders在FPGA中工作-低速调试模式。 FPGA计数器显示已过去的时钟周期数。然后我想-如果我们可以用铁加速正确的环境呢? 例如,原始的太空侵略者以1 MHz的频率进入8080 CPU。 我设法在3 GHz Xeon处理器上模拟了8080 40 MHz CPU。 不错,但是在我将所有这些都放到FPGA中之后,频率上升到了400 MHz。 这意味着从一个流中获得24,000 FPS,相当于30 GHz Xeon! 我是否提到过您可以将100个8080处理器塞入一个普通的FPGA中? 这已经产生了240万FPS。
 太空侵略者具有100 MHz的硬件加速,是全速的四分之一
太空侵略者具有100 MHz的硬件加速,是全速的四分之一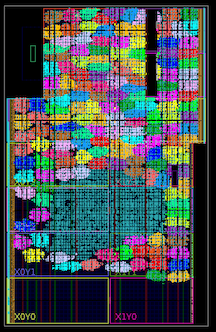 Xilinx Kintex 7045 FPGA内部有一百多个内核(以鲜艳的颜色表示;中间的蓝色斑点是演示的一般逻辑)。
Xilinx Kintex 7045 FPGA内部有一百多个内核(以鲜艳的颜色表示;中间的蓝色斑点是演示的一般逻辑)。 执行路径不均
执行路径不均您可能会问,GPU呢? 简而言之,我们需要像
MIMD这样的并发性,而不是
SIMD 。 作为一名学生,我花了一段时间在GPU上
实现蒙特卡罗树搜索(AlphaGo中使用了这种搜索)。
那时,我花了无数的时间试图使GPU和其他硬件按照SIMD原理(IBM Cell,Xeon Phi,AVX CPU)运行以执行类似的代码,但是却一无所获。 几年前,我开始认为能够独立开发专门为解决与强化训练有关的问题而设计的硬件会很好。
 MIMD并发
MIMD并发ATARI 2600,NES还是Game Boy?
在8080,我实施了《太空侵略者》,《 NES》,《 2600》和《 Game Boy》。 以下是有关它们以及它们各自的好处的一些事实。
 NES吃豆人
NES吃豆人太空侵略者只是热身。 我们设法让他们开始工作,但是那只是一场比赛,所以结果不是很有用。
Atari 2600实际上是强化学习研究的标准。 MOS 6507处理器是著名的6502的简化版本,其设计比8080更为优雅和高效。我之所以选择2600,不仅是因为与游戏及其图形有关的某些限制。
我还实现了NES(任天堂娱乐系统),它与2600共享CPU。那里的游戏要比2600好得多。但是两个控制台都面临着过于复杂的图形处理流程和需要支持的几种卡盒格式。
同时,我重新发现了Nintendo Game Boy。 那就是我想要的。
为什么Game Boy如此酷?
 1049个经典游戏和576个Game Boy Color游戏
1049个经典游戏和576个Game Boy Color游戏总共有1000多种游戏,种类繁多,质量高,其中有些非常复杂(王子),可以对游戏进行分组并分配复杂性,以研究知识的传授和训练(例如,俄罗斯方块,赛车游戏,马里奥游戏有多种选择)。 要解决波斯王子游戏,您可能需要从其他一些类似的游戏中转移知识,这些游戏中要清楚地指出要点(在王子里不是)。
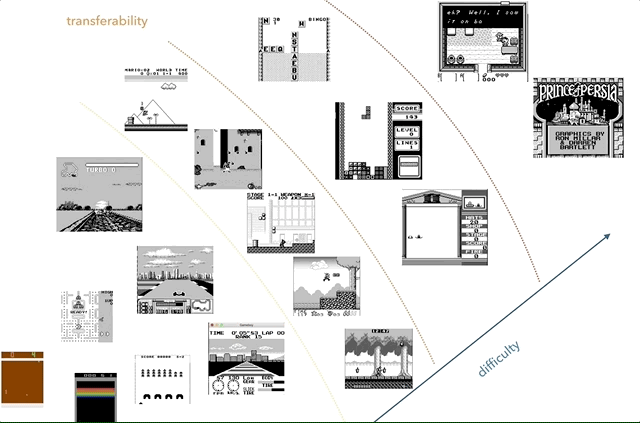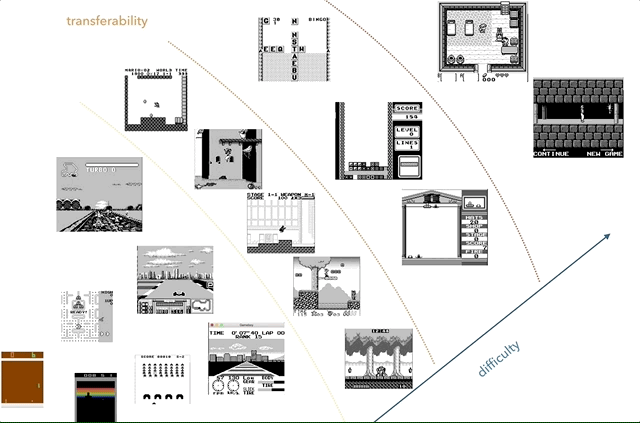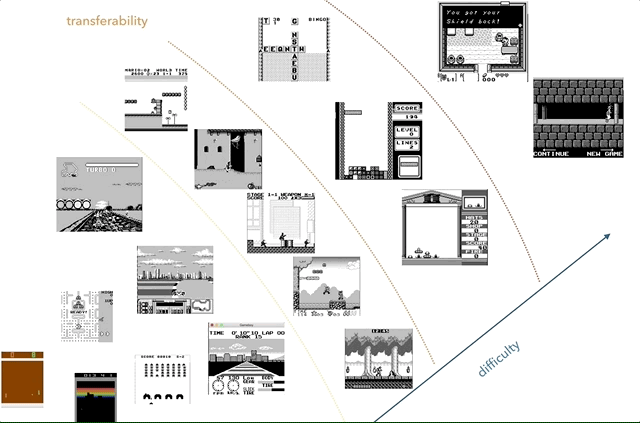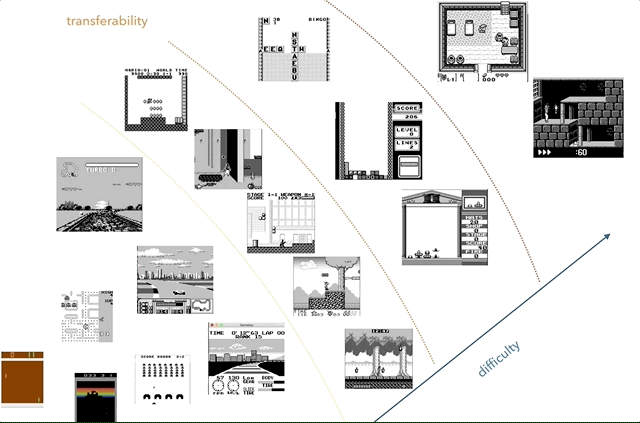 任天堂Game Boy是我最喜欢的知识转移研究平台。 在图表上,我尝试根据复杂性(主观)和相似性(比赛,跳跃,射击,俄罗斯方块等各种游戏;有人玩HATRIS吗?)的概念对游戏进行分组。
任天堂Game Boy是我最喜欢的知识转移研究平台。 在图表上,我尝试根据复杂性(主观)和相似性(比赛,跳跃,射击,俄罗斯方块等各种游戏;有人玩HATRIS吗?)的概念对游戏进行分组。经典的Game Boy屏幕非常简单(160x144,2位彩色),因此预处理变得很简单,您可以专注于重要的事情。 在2600,即使是简单的游戏也有许多颜色。 另外,在Game Boy上的对象展示得更好,没有闪烁,也不需要最多拍摄两个连续的帧。

没有像NES或2600这样疯狂的内存布局。大多数游戏都可以与2-3个映射器一起使用。
紧凑的代码-我设法用不超过700行的代码将整个仿真器装入C中,而我的Verilog实现则使用了500行。
有一个与街机游戏一样简单的《太空侵略者》版本。
在这里,他就是我的1989点矩阵游戏男孩和可通过HDMI在4K屏幕上工作的FPGA版本。

这是我的旧游戏男孩无法做到的:
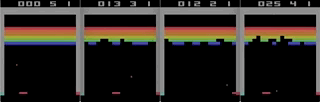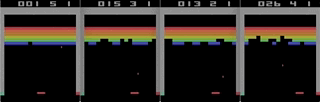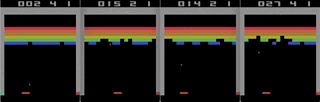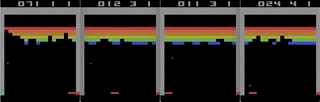
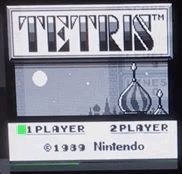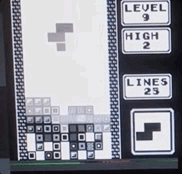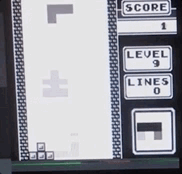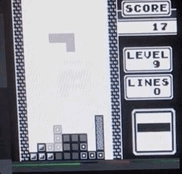 俄罗斯方块通过铁加速-从屏幕实时记录,速度是最大速度的1/4。
俄罗斯方块通过铁加速-从屏幕实时记录,速度是最大速度的1/4。这有什么真正的好处吗?
是的,有。 到目前为止,我已经在简单的条件下测试了该系统,并使用了与各个Game Boy交互的外部规则网络。 更具体地说,我使用了A3C(优势演员评论家)算法,并计划在另一篇文章中对其进行描述。 我的同事将其连接到FPGA上的卷积网络,并且可以正常工作。
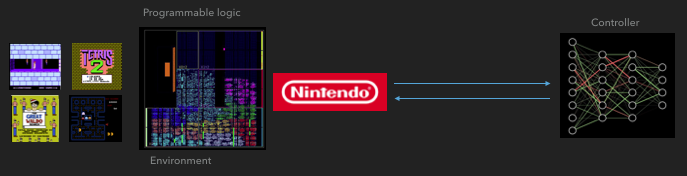 FGPA如何与神经网络通信
FGPA如何与神经网络通信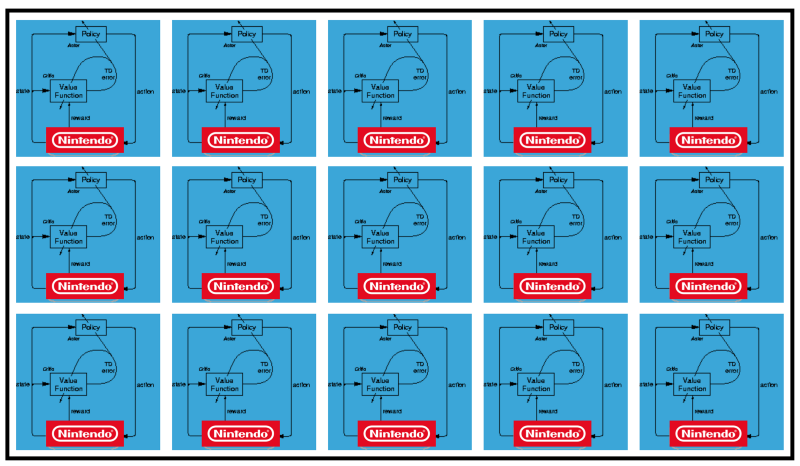 分布式A3C
分布式A3C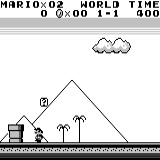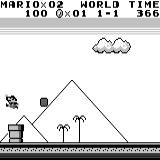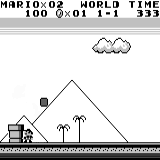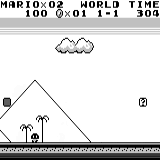 马里奥土地:初始条件。 随机按键不会使我们走得更远。 右上角显示剩余时间。 如果幸运的话,我们将在触摸树胶后立即结束游戏。 否则,将需要400秒才能“消失”。
马里奥土地:初始条件。 随机按键不会使我们走得更远。 右上角显示剩余时间。 如果幸运的话,我们将在触摸树胶后立即结束游戏。 否则,将需要400秒才能“消失”。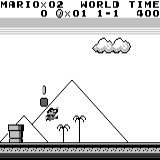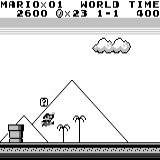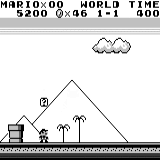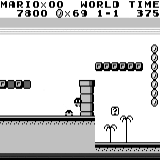 马里奥之地:玩了一个小时之后,马里奥学会了奔跑,跳跃甚至打开了一个秘密房间,爬进了烟斗。
马里奥之地:玩了一个小时之后,马里奥学会了奔跑,跳跃甚至打开了一个秘密房间,爬进了烟斗。 吃豆人:经过大约一个小时的训练,神经网络甚至能够一次完成整个游戏(吃光了所有积分)。
吃豆人:经过大约一个小时的训练,神经网络甚至能够一次完成整个游戏(吃光了所有积分)。结论
我想,下一个十年将是超级计算和AI相互发现的时期。 我想要一种硬件,使我可以将自己设置为一定水平,以适应所需的AI算法。
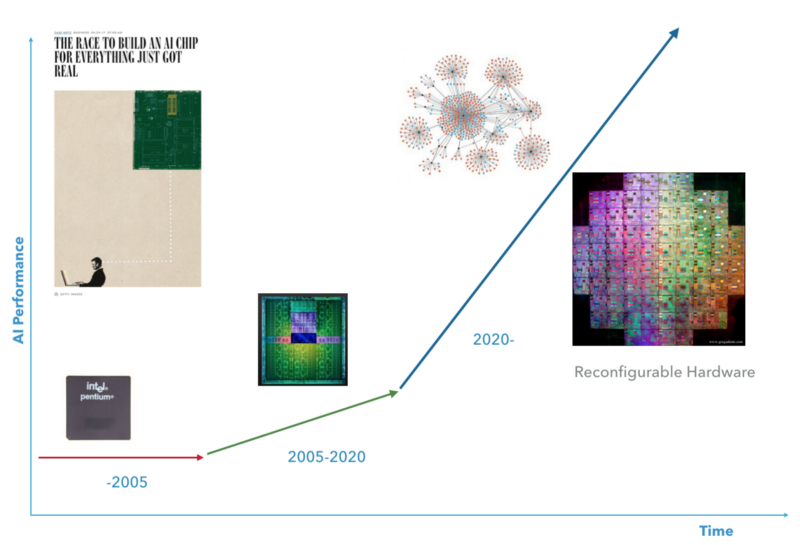 未来十年C语言中的Game Boy代码
未来十年C语言中的Game Boy代码侦错
人们经常问我:最困难的是什么? 就是这样-整个项目非常痛苦。 对于初学者,没有Game Boy的规范。 我们学到的一切,都归功于逆向工程,也就是说,我们启动了一个中间任务,例如游戏,并观察了它是如何执行的。 这与标准软件调试非常不同,因为在这里我们调试运行程序的硬件。 我必须想出不同的方法来实现这一目标。 我谈到了以100 MHz的频率运行时监视一个过程有多困难? 哦,那里没有printf。
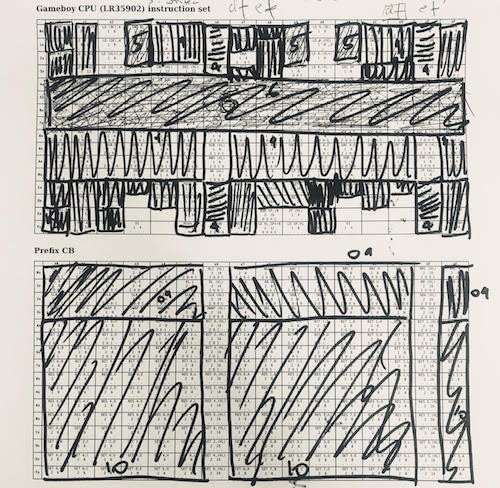 一种实现CPU的方法是将指令按功能分组。 使用6502会容易得多。 LR35092塞满了所有“随机”废话,并且有许多例外。 我在与CPU Game Boy一起工作时使用了这张桌子。 我使用了一个贪婪的策略-我接受了最大的指令,执行并删除了它们,然后重复执行。 指令的1/4是ALU,1/4是寄存器加载,可以很快实现。 在频谱的另一端,有各种不同的东西,例如“从HL到带标志的SP的上载”,必须分别处理。
一种实现CPU的方法是将指令按功能分组。 使用6502会容易得多。 LR35092塞满了所有“随机”废话,并且有许多例外。 我在与CPU Game Boy一起工作时使用了这张桌子。 我使用了一个贪婪的策略-我接受了最大的指令,执行并删除了它们,然后重复执行。 指令的1/4是ALU,1/4是寄存器加载,可以很快实现。 在频谱的另一端,有各种不同的东西,例如“从HL到带标志的SP的上载”,必须分别处理。 调试:在要调试的硬件上运行代码,记下实现日志和其他信息(这显示了左侧Verilog代码与右侧C仿真器的比较)。 然后对日志运行diff来发现不一致(蓝色)。 使用自动化的原因之一是,在许多情况下,当单个CPU标志引起滚雪球效应时,我在数百万次执行周期后发现了问题。 我尝试了几种方法,结果证明这是最有效的。
调试:在要调试的硬件上运行代码,记下实现日志和其他信息(这显示了左侧Verilog代码与右侧C仿真器的比较)。 然后对日志运行diff来发现不一致(蓝色)。 使用自动化的原因之一是,在许多情况下,当单个CPU标志引起滚雪球效应时,我在数百万次执行周期后发现了问题。 我尝试了几种方法,结果证明这是最有效的。 您将需要大量咖啡!
您将需要大量咖啡! 这些书已有40年历史了。 翻遍它们,并当时以这些用户的眼光看待计算机世界,真是太神奇了-我感觉自己像是来自未来的客人。
这些书已有40年历史了。 翻遍它们,并当时以这些用户的眼光看待计算机世界,真是太神奇了-我感觉自己像是来自未来的客人。OpenAI研究要求
最初,我想在内存方面使用游戏,如OpenAI的
帖子所述。
出乎意料的是,使Q学习在代表内存状态的输入上正常工作是出乎意料的困难。
该项目可能没有解决方案。 出乎意料的是,发现Q学习将永远无法成功完成Atari中的内存工作,但有可能该任务将非常困难。
考虑到Atari上的游戏仅使用128 b的内存,因此处理这些128 b而不是全屏帧似乎非常吸引人。 我得到的结果参差不齐,所以我开始弄清楚。
尽管我不能证明不可能从记忆中学习,但我可以证明记忆反映了整个游戏状态的假设是错误的。 Atari 2600 CPU(6507)使用128 b的内存,但仍可以访问位于单独电路(TIA,电视适配器,GPU之类)上的其他寄存器。 这些寄存器用于存储和处理有关物体(球拍,火箭,球,碰撞)的信息。 换句话说,如果仅考虑内存,则将无法访问它们。 NES和Game Boy还具有用于控制屏幕和滚动的其他寄存器。 只有一个内存不能反映游戏的完整状态。
只有8080直接将数据存储在视频内存中,这使您可以提取游戏的完整状态。 在其他情况下,“ GPU”寄存器连接在CPU和屏幕缓冲区之间,而在RAM外部。
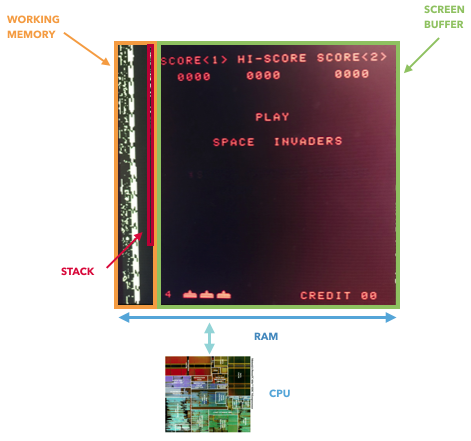
一个有趣的事实:如果您对GPU的历史进行研究,那么8080可能是第一个“图形加速器”-它具有一个外部移位寄存器,允许您使用单个命令移动空间入侵者,从而减轻CPU的负担。

of