在2018年中,
发表了关于大鼠脑电生理的研究
成果 ,并公开提供了一个
独特的数据集 。 该数据集的独特之处在于,它使用新的高密度
Neuropixels电极(探针或探针)和来自靠近样品的细胞的贴片电极同时记录局部场电势。 对此类记录的兴趣不仅是基本的,而且也得到了应用,因为它使您可以验证用于分析现代样本记录的神经元活动的模型。 而这又直接关系到新的神经假体的发展。 基本的新颖性是什么,以及为什么这个数据集如此重要-我会告诉大家。
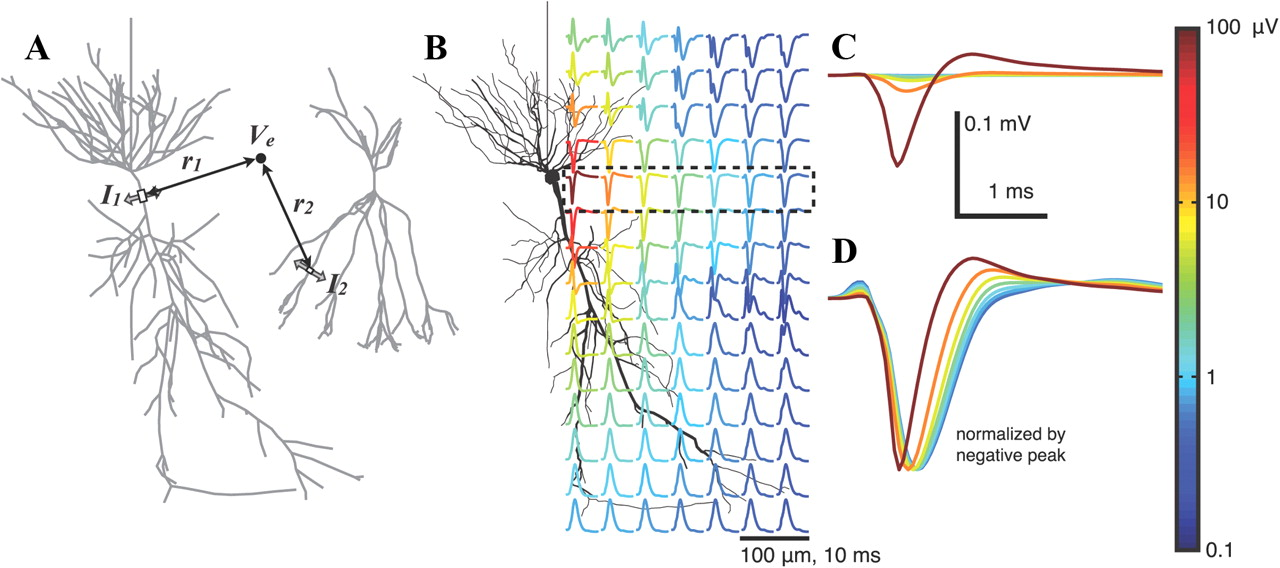 KDPV:在动作电位( 来源 )生成过程中对一个神经元附近的细胞外电位进行建模的结果。 颜色表示电势的幅度。 该插图对于进一步理解很重要。用于研究
KDPV:在动作电位( 来源 )生成过程中对一个神经元附近的细胞外电位进行建模的结果。 颜色表示电势的幅度。 该插图对于进一步理解很重要。用于研究大脑的
电生理方法基于记录大脑的电势。 它们可以分为非侵入性的-主要是脑电图(EEG)-和侵入性的,例如,脑电图(ECoG),膜片钳(patch-clamp)或局部场电位的配准(LPP =局部场电位,LFP) 。 对于后者,将大小为10-100微米的小电极直接注入大脑,并记录其电位。 为了研究哺乳动物大脑在细胞水平上的活性,即测量单个细胞的活性,不能使用可用的非侵入性方法,因为一个细胞的电势会在空间中迅速衰减,实际上是在100μm处衰减(参见KDPV)。 因此,在任何动物模型以及人类中,非侵入性方法仅提供有关神经元和工作的集体活动的信息,很可能是在组织水平上的信息,而不是单个神经元的信息。
但是用侵入性方法并不是那么简单。 为了记录一个神经元的活动,有必要使电极非常靠近神经元,理想地将其放置在细胞内(如在膜片钳中所做的那样),或者使用
锋利的电极 ,这在实践中非常困难,非常困难。 另一方面,由于神经元的高密度和细胞外溶液的高离子电导率,任何大小约为10μm的细胞外电极都将记录5-10个细胞周围的动作电位。 因此,通过增加位于细胞附近的电极的密度,从技术上解决了注册单个细胞的任务。 在这方面,现代电生理学正朝着增加电极密度,增加电极数量和减小尺寸的方向发展。 在这些要求中,有必要将信号放大到更靠近配准位置以减少噪声,并放置一个多路复用器以减小尺寸。 因此,它于2016年在预印本中宣布,并于2017年在《自然》杂志上发表,并于2018
年在市场上出现
,它是由CMOS技术制成的一种新的高密度Neuropixels样品,在960个电极上,其中384个电极均可同时记录。 一个注册位点的大小为12微米。 样品的厚度为24微米。 此外,使用高密度电极以及主动放大功能,人们已经开始工作了很长时间,但是Neuropixels是第一个进入生产和销售阶段的产品,因此在不久的将来,这种特殊的测试方法将越来越多地出现在文章中。
 图 Neuropixels方案。 在单片硅基板上,有960个位置,以及用于384个通道的完整多路复用器和AD接口。
图 Neuropixels方案。 在单片硅基板上,有960个位置,以及用于384个通道的完整多路复用器和AD接口。资料结构
除了负责组同步的经典
活动节奏 (α,β,γ等)外,使用此类样本获得的数据还包含单个细胞的动作电位(AP =动作电位,AP,峰值,粘附) ,在记录上看起来像短峰,持续时间约1 ms。
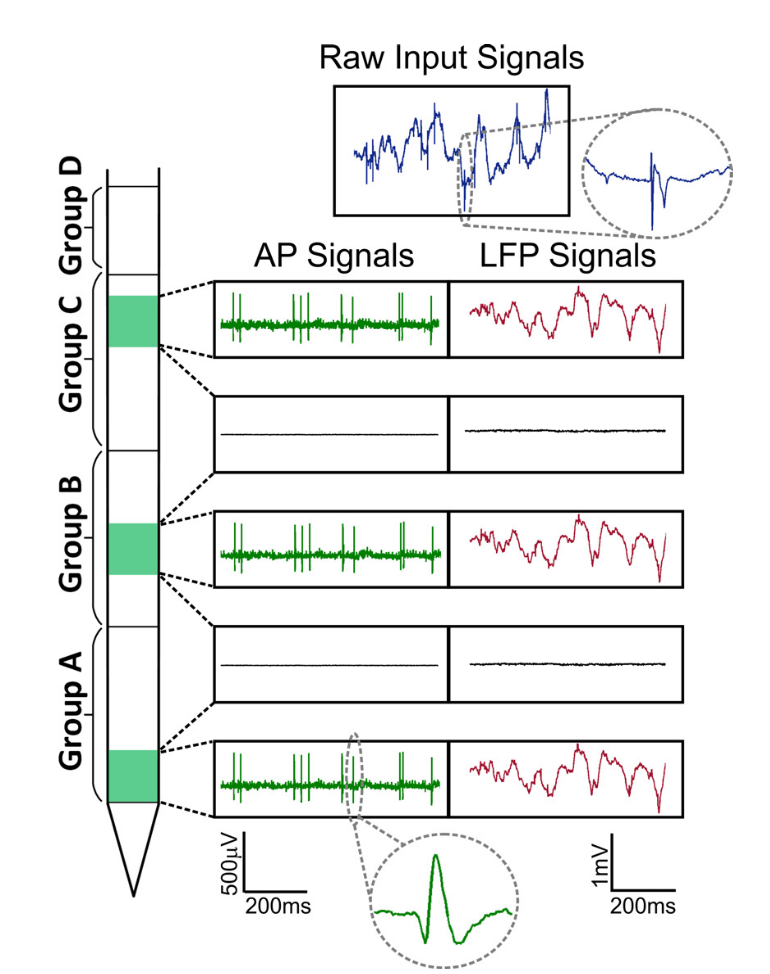 图 信号神经像素。 信号分为两个部分:局部电场电势(高达300 Hz的LFP)和细胞活动(300 Hz起的AP)。
图 信号神经像素。 信号分为两个部分:局部电场电势(高达300 Hz的LFP)和细胞活动(300 Hz起的AP)。此外,如果通常在振荡框架内分析低频局部场电势,并且像在EEG中一样使用频谱或小波分析,则细胞活动包含单个细胞的动作电势,它由针对噪声背景的离散事件组成。 当应该从发言人组中区分出一个单独的发言人时,隔离单个单元格活动的任务正式减少到鸡尾酒会问题的任务。 当我们评估一个样本中的数据流时,就会出现大数据。 为了分析尖峰,采样以30–40 kHz的频率进行,每点16位(uint16)进行数字化处理,因此,在1秒内记录100个电极的重量为8 MB。 同时,实验通常持续数小时,从一个工作日开始就达到数百GB,对于完整的研究(例如,从10个这样的记录开始)。 因此,此样本的潜力也强烈取决于用于数据分析的机器学习算法。
机器学习与细胞活动
通常,用于细胞活性分析的管线由预处理,峰分割和聚类组成。 研究的这一部分通常称为聚类分析或峰值分类。 作为预处理,通常使用低通滤波(> 300 Hz),因为据信在300 Hz以上没有其他生理节律,仅保留有关单个细胞活动的信息。 同样,在密集样本的预处理过程中,可以减少相关的噪声,例如50 Hz的拾取。 分割通常被视为简单的阈值,例如,高于5个标准噪声偏差的任何事件都可以视为事件。 碰巧使用具有软阈值和硬阈值的两阈值分割来区分时空相关事件,就像在分水岭
分割算法中一样,仅在群集聚类中,标记传播才考虑样本拓扑。 分割后,在每个事件的中心附近获取一个持续1-2 ms的窗口,并且该窗口中从所有通道收集的信号成为样本,用于进一步聚类。 该样本称为尖峰波形。 不同的单元以及它们与配准位置的距离不同,导致它们的波形会变化(请参阅KDPV)。 波形聚类算法本身使用EM,模板匹配搜索,深度学习和许多变体(
github上的主题 )。 唯一的要求是在没有老师的情况下进行培训。 但是有一个问题。 没有人能确定要为管道使用什么样的参数,才能使分析最有效。 通常,在聚类后,分析人员会手动查看结果并自行决定进行更改。 因此,分析结果可以包括算法错误和人为错误。 因此,客观验证的问题可能尚未解决。
有几种验证管道的方法。 首先,改变研究对象的外部条件。 例如,在实验期间,如果您研究皮质的视觉部分,则可以更改图像的纹理,颜色和亮度。 如果分析中有一个单元根据刺激改变其活动,那么您很幸运。 其次,您可以在药理上增强或降低特定类型细胞的活性,例如,使用某些通道阻滞剂。 然后,您的单元格的活动将增加/减少,您将看到聚类中的差异。 但是,这种活动度的调制也将导致波形变化,因为时间上动作电位的分布完全由离子通道的动力学决定。 第三,您可以通过光遗传学方法或使用移液器测量或诱导某些细胞的活性,如本数据集所示。 由于大的信噪比和贴片电极的稳定性,您将完全相信单个细胞的活性。 从概念上讲,该出版物专门致力于使用膜片钳组装验证数据集。
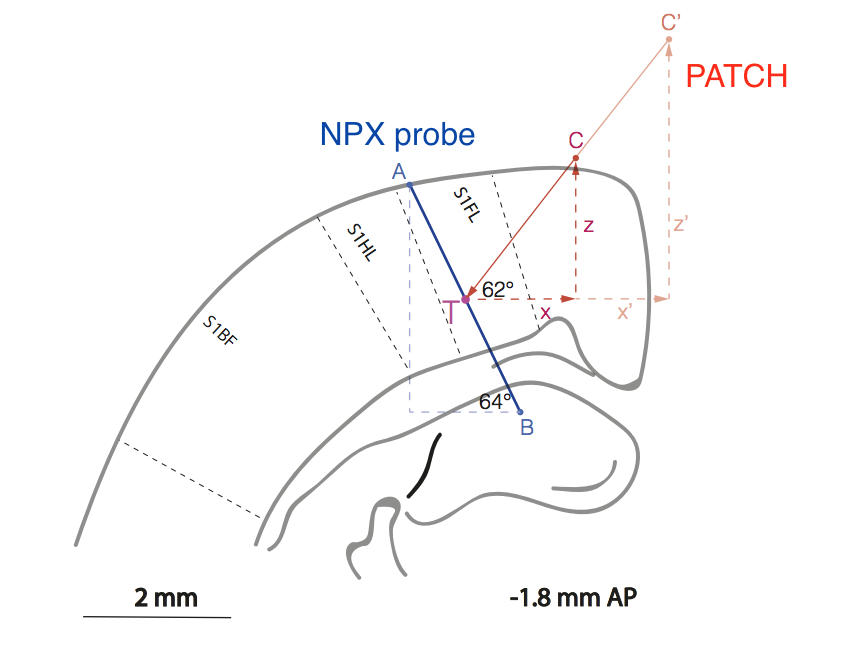 图 大鼠皮层区域中样品(AB线)和补片移液器(C'CT线)的相对位置的示意图,负责处理来自前爪的感觉信息(S1FL =感觉皮层1前肢)。
图 大鼠皮层区域中样品(AB线)和补片移液器(C'CT线)的相对位置的示意图,负责处理来自前爪的感觉信息(S1FL =感觉皮层1前肢)。不用说,方法上的工作非常困难,因为实验人员不得不开发一种无需视觉控制就能在大脑皮层中将两个电极相互排列的方法,精度约为10μm。
电极密度对峰值聚集的影响
为什么增加注册站点的密度如此重要? 打个比方,我们认为EEG研究人员知道的一个事实是,从某个阈值开始,帽中电极数量的增加不会导致接收到的信息显着增加,即来自电极的信号与来自相邻电极的信号的线性插值略有不同。 有人说这个阈值已经达到30,有人50,有人100电极。 那些与EEG进行过详细合作的人可以得到纠正。 但是,在细胞活动的情况下,一个样品上的注册位点密度的阈值尚不清楚,因此高密度样品的竞争仍在继续。 为此,坎普夫实验室团队将继续处理5x5μm2站点的样本,并为此发布了
初步数据 。 使用密集电极的专家分享了他们的经验,出乎意料的是,可以从相同区域的样本中分离出的单个细胞的特定数目更高,而登记位点的密度更高。 同一作者的
另一项研究很好地说明了这种效果,他们从tSNE转换为波形尖峰的PCA值后,人为地从稠密样本中仅选择了一部分位点,并通过视觉评估了所得簇的质量。 这不是集群的标准,但对于说明依赖性很有用。 作为测试,Neuroseeker作用于128个通道,总大小为700x70μm2,位置为20x20μm2。
 图 PCNE上的TSNE在原始波形上绘制图,同时人为地降低了样本上位点的密度。 在每个图的顶部示意性地显示了工作地点。 清楚地显示出,随着站点密度的增加,隔离簇的数量将如何精确地增长,A为最佳,F为最差。
图 PCNE上的TSNE在原始波形上绘制图,同时人为地降低了样本上位点的密度。 在每个图的顶部示意性地显示了工作地点。 清楚地显示出,随着站点密度的增加,隔离簇的数量将如何精确地增长,A为最佳,F为最差。工作的实质是什么
在Marques-Smith等人的数据中。 同时记录膜片钳和样品。 利用膜片钳数据,科学家发现了动作电位的瞬间,并利用这些瞬间对样本上已经存在的波形进行分段和平均。 结果,他们能够在整个样本区域内在时间和空间上建立动作电位的非常高质量的分布。
 图 在左侧,膜片夹(黑色)和最近的Neuropixels通道(蓝色)同时显示了细胞活动的痕迹。 在中间-500个单独的样本及其平均值。 右边是动作电位在样本区域内的空间分布和时间分布。
图 在左侧,膜片夹(黑色)和最近的Neuropixels通道(蓝色)同时显示了细胞活动的痕迹。 在中间-500个单独的样本及其平均值。 右边是动作电位在样本区域内的空间分布和时间分布。接下来,提出了关于尖峰到尖峰之间的细胞外波形变化的问题-是的,这是显而易见的,必须予以考虑。 然后他们表明,使用它们的致密电极从根本上可以追踪动作电位沿着细胞膜的分布,但这已经在其他小组的工作中得到了证明。 总之,他们为潜在的合作者提供了神经生理学的一些基本问题,您可以尝试在他们的数据集的帮助下回答这些问题,还可以使用数据集来验证用于聚类细胞活性的管道。 后者听起来是一个大胆的挑战,因为现在有很多聚类算法,并且这些方法之间的竞争非常激烈。 首先,并非每种方法都可以使用如此大量的渠道,其次,并不是每个人都能客观地提供高质量的聚类。
接下来是什么
首先,也正在使用CMOS技术的1300个通道上的
Neuroseeker的新版本正在接近,初步数据
已经可用 。
其次,我们正在等待另一个来自艾伦脑科学研究所的数据集,该数据集是在2018年FENS会议上宣布的。 它将同时使用4个(!)Neuropixels样本来研究具有各种视觉刺激的小鼠皮质的视觉部分。 他们承诺将在2018年底在双光子数据(也是一个非常强大的数据集)旁边
在此处发布,但到目前为止没有任何内容。
第三,从记录细胞外电位开始聚集细胞的任务在我看来看起来很美。 它融合了微电子学,神经生理学和机器学习的方法。 另外,它具有很大的基础和应用价值。 我想哈伯族的读者将有兴趣了解电生理学的技术知识,即有关聚类算法的知识,因为在该领域已经建立了自己的动物园。 反过来,我已经为这些算法积累了几个问题,并且不能跳过这样的数据集。 因此,在下一部分中,我们将继续对一些算法进行分析,首先从规范的Klustakwik开始,再到模板方法Kilosort或Spyking Circus,再到YASS,YASS强烈地
宣称自己工作得比其他人更快,更好,这是因为DL并且因为它可以。 在github上的主题,
这里有一些集群器的列表。 预料到一些问题,我看不出开发自己的算法的意义,因为竞争已经非常激烈,并且许多想法已经被其他人实施和测试。 但是,如果有胆子,我会很乐意贡献。
建议和愿望被接受。 感谢您的关注!