你好 我是Dima,并且我已经在Python中坐了一段时间了。 今天,我想向您展示两个异步框架-Tornado和Aiohttp之间的区别。 我将讲讲项目中各个框架之间的选择,Tornado和AsyncIO中的协程如何不同的故事,我将展示一些基准测试,并提供一些有用的技巧,帮助您了解如何进入框架的框架并成功地摆脱困境。

如您所知,Avito是一个相当大的广告服务。 我们拥有大量的数据和负载,每月有3500万用户,每天有4500万个活动广告。 我是推荐开发小组的技术顾问。 我的团队写微服务,现在我们大约有二十个。 所有的负载都堆积在上面-例如5k RPS。
选择一个异步框架
首先,我将告诉您我们如何最终实现现在的状态。 在2015年,我们需要选择一个异步框架,因为我们知道:
- 您必须向其他微服务发出很多请求:http,json,rpc;
- 您将一直需要从不同来源收集数据:Redis,Postgres,MongoDB。
因此,我们有很多网络任务,而应用程序主要是输入/输出。 当时的python当前版本为3.4,async和await尚未出现。 Aiohttp也是-版本0.x。 Facebook的异步龙卷风出现在2010年。 我们为他编写了许多数据库驱动程序。 龙卷风在基准测试中显示出稳定的结果。 然后我们停止了对该框架的选择。
三年后,我们了解了很多。
首先,Python 3.5推出了异步/等待机制。 我们弄清了产量与产量之间的区别,以及龙卷风与等待之间的一致性(破坏者:不是很好)。
其次,即使CPU未被完全占用,在调度程序中使用大量协程也会遇到奇怪的性能问题。
第三,我们发现在执行对其他Tornado服务的大量http请求时,您需要特别与异步dns解析器友好,它不考虑建立连接和发送我们指定的请求的超时。 通常,在Tornado中发出http请求的最佳方法是curl,这本身就很奇怪。
安德烈·斯维特洛夫
( Andrei Svetlov)
在2018年俄罗斯PyCon大会上的
演讲中说:“如果要编写某种异步Web应用程序,请编写异步,等待。 事件循环,也许您很快将不再需要它。 不要陷入框架的混乱之中,以免感到困惑。 不要使用低级原语,一切都会好起来的……”。 不幸的是,在过去的三年中,我们不得不经常爬进龙卷风内部,从那里学到很多有趣的东西,并看到30-40次通话的巨大回弹。
产量与来自的产量
在异步python中要理解的最大问题之一是yield from和yield之间的区别。
Guido Van Rossum写了更多有关此的内容。 随函附上简短的缩写。
我多次被问到为什么PEP 3156坚持使用yield-from而不是yield,这排除了在Python 3.2甚至2.7中进行反向移植的可能性。
(...)
每当您想要将来的结果时,就使用yield。
这实现如下。 包含yield的函数(显然)是一个生成器,因此必须有某种迭代代码。 我们称他为规划师。 实际上,调度程序并没有在经典意义上“迭代”(使用for循环);而是通过循环来实现。 相反,它支持两个将来的集合。
我将第一个集合称为“可执行”序列。 这是未来,其结果是可用的。 当此列表不为空时,调度程序将选择一项并采取一个迭代步骤。 此步骤使用将来的结果(可能是刚从套接字读取的数据)调用.send()生成器方法。 在生成器中,此结果显示为yield表达式的返回值。 当send()返回结果或完成结果时,调度程序将分析结果(可能是StopIteration,另一个异常或某种对象)。
(如果您感到困惑,则可能应该阅读有关生成器如何工作的信息,尤其是.send()方法。也许PEP 342是一个很好的起点)。
(...)
调度程序支持的第二个Future集合包括Future,它们仍在等待I / O。 它们以某种方式传递给select / poll / shell等。 当文件描述符准备好用于I / O时,它将提供一个回调。 回调实际上执行Future所请求的I / O操作,将结果Future值设置为I / O操作的结果,并将Future移至执行队列。
(...)
现在我们到达了最有趣的地方。 假设您正在编写一个复杂的协议。 在协议内部,您可以使用recv()方法从套接字读取字节。 这些字节到达缓冲区。 recv()方法包装在异步外壳程序中,该外壳程序设置I / O并返回Future(在I / O完成时执行),如前所述。 现在,假设您的代码的其他部分希望一次从缓冲区中读取一行数据。 假设您使用了readline()方法。 如果缓冲区的大小大于平均行长度,则您的readline()方法可以简单地从缓冲区中获取下一行而不会阻塞; 但有时缓冲区不包含整行,而readline()依次在套接字上调用recv()。
问题:readline()是否应该返回未来? 如果他有时返回一个字节字符串,有时返回将来,从而迫使调用者执行类型检查和条件屈服,那将不是很好。 因此答案是readline()应该总是返回future。 调用readline()时,它将检查缓冲区,如果在缓冲区中找到至少整行,则会创建一个future,设置从缓冲区中提取的一行的future结果,然后返回future。 如果缓冲区没有整行,它会启动I / O并期望它,当I / O完成时,它将重新开始。
(...)
但是现在我们正在创建许多将来的请求,它们不需要I / O阻塞,但仍会强制调用调度程序,因为readline()返回的是Future,需要调用者提供yield,这意味着调用调度程序。
如果调度程序看到显示已完成的将来,则可以将控制权直接传递到协程,或者可以将将来返回到执行队列。 后者将大大减慢工作速度(假设有多个可执行协程),因为不仅需要在队列末尾等待,而且内存的位置(如果存在)也可能丢失。
(...)
所有这些的最终结果是协程作者需要了解产量的未来,因此在将复杂代码重组为可读性更高的协程中存在更大的心理障碍-比现有抵抗力要强得多,因为Python中的函数调用非常慢。 而且我还记得与Glyph的对话中,速度对于典型的异步I / O结构很重要。
现在,让我们将其与yield-from进行比较。
(...)
您可能已经听说“ S的收益”大致等于“ S中的i:收益i”。 在最简单的情况下,这是正确的,但这不足以了解协程。 考虑以下因素(暂时不要考虑异步I / O):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
此代码打印包含“ okay”和“ 42”的两行(然后生成未处理的StopIteration,您可以通过在gen1的末尾添加yield来抑制它)。 您可以在链接上的pythontutor.com上查看此代码的运行情况。
现在考虑以下几点:
def gen2(): yield from gen1() driver(gen2())
它的工作方式完全相同 。 现在想想。 如何运作? 在此不能使用for循环中的简单yield-from扩展,因为在这种情况下,代码将返回None。 (尝试一下) 。 Yield-from充当驱动程序和gen1之间的“透明通道”。 也就是说,当gen1给出值“ okay”时,它将通过yield-from退出gen2到驱动程序,并且当驱动程序将42发送回gen2时,该值再次通过yield-from返回gen1(在这里它成为yield的结果) )
如果驱动程序向生成器中抛出错误,也会发生同样的事情:该错误通过yield-from到处理该错误的内部生成器。 例如:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
该代码将给出“ okay”和“ bah”,以及以下代码:
def gen2(): yield from gen1()
(请参见此处: goo.gl/8tnjk )
现在,我想介绍简单的(ASCII)图形,以便能够讨论这种代码。 我用[f1-> f2-> ...-> fN)表示堆栈,底部是f1(最旧的调用框架),顶部是fN(最新的调用框架),其中列表中的每个项目都是生成器,而->是yield-from 。 第一个示例,驱动程序(gen1())没有yield-from,但是它具有gen1生成器,因此它看起来像这样:
[ gen1 )
在第二个示例中,gen2使用yield-from调用gen1,因此如下所示:
[ gen2 -> gen1 )
我使用半开间隔[...]的数学符号来表示,当最右边的生成器使用yield-from调用另一个生成器时,可以将另一帧添加到右侧,而左端则或多或少是固定的。 左端是驾驶员看到的(即调度程序)。
现在,我准备返回readline()示例。 我们可以将readline()重写为一个调用read()的生成器,另一个使用yield-from的生成器; 后者依次调用recv(),它从套接字执行实际的输入/输出。 左侧是应用程序,我们也将其视为再次使用yield-from调用readline()的生成器。 该方案如下:
[ app -> readline -> read -> recv )
现在,recv()生成器设置I / O,将其绑定到将来,然后使用* yield *(而不是yield-from!)将其传递给调度程序。 Future沿调度程序中的两个yield-from箭头(位于“ [”的左侧)向左移动。 注意,调度程序不知道它包含一堆生成器。 他所知道的只是他拥有最左边的发电机,并且他刚刚发布了一个未来。 I / O完成后,调度程序将设置将来的结果并将其发送回生成器; 结果沿着两个yiled-from箭头向右移动到recv生成器,该接收器接收它想要从套接字读取的字节作为yield结果。
换句话说,yield-from框架调度程序处理I / O操作,就像我之前描述的基于yield的框架调度程序一样。 *但是:*他不必担心将来已经执行时的优化,因为调度程序不参与readline()和read()之间或read()和recv()之间的控制权转移,反之亦然。 因此,当app()调用readline()时,调度程序根本不参与,并且readline()可以满足来自缓冲区的请求(无需调用read())-在这种情况下,app()和readline()之间的交互完全由字节码解释器处理巨蟒 调度程序可以更简单,并且调度程序创建和管理的将来的数目更少,因为没有协同程序的每次调用都创建和销毁的将来的数目。 唯一需要的将来就是代表实际I / O的那些,例如,由recv()创建的。
如果您到目前为止已读完书,则应得到奖励。 我省略了许多实现细节,但是上面的图示基本上可以正确反映出图片。
我想指出的另一件事。 *您可以*使代码的一部分使用yield-from,另一部分使用yield。 但是产量要求链中的每个环节都有前途,而不仅仅是协程。 由于使用yield-from有很多优点,我希望用户不必记住何时使用yield和何时yield-from,始终使用yield-from会更容易。 一个简单的解决方案甚至允许recv()使用yield-from将将来的I / O传递给调度程序:__iter__方法实际上是将来发出的生成器。
(...)
还有一件事。 收益回报率是多少? 事实证明,这是* external *生成器的返回值。
(...)
因此,尽管箭头将左右框架绑定到*产生目标,但它们也以通常的方式传递通常的返回值,一次返回一个堆栈帧。 异常的移动方式相同。 当然,在每个级别上,尝试/除外都是必须的。
原来的收益与等待差不多。
vs异步的收益
def coro()^ y =来自a的收益 | async def async_coro(): y =等待a |
| 0个load_global | 0个load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4个load_const | 4个load_const |
| 6 yield_from | 6 yield_from |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
新旧学校的两个协程只有一个微小的区别-从迭代获得收益与等待收益。
为什么这一切呢? 龙卷风使用简单的收益率。 在版本5之前,它通过yield连接整个呼叫链,这与来自/ await范式的新的冷静yield不兼容。
最简单的异步基准
很难找到一个真正好的框架,仅根据综合测试来选择它。 在现实生活中,很多事情都会出错。
我使用了Aiohttp版本3.4.4,Tornado 5.1.1,uvloop 0.11,并使用了Intel Xeon服务器处理器,CPU E5 v4、3.6 GHz,并使用Python 3.6.5在其上开始检查Web服务器的竞争力。
我们在微服务的帮助下解决的且在异步模式下工作的典型问题如下所示。 我们将收到请求。 对于它们中的每一个,我们将向某个微服务发出一个请求,从那里获取数据,然后异步地转到另外两个或三个微服务,然后将数据写到数据库中并返回结果。 事实证明,我们将等待很多点。
我们执行更简单的操作。 我们打开服务器,使其休眠50毫秒。 创建一个协程并完成它。 由于许多协程会同时在竞争服务器上运行,因此我们不会有一个可以接受的延迟的非常大的RPS(它可能与完全合成的基准测试中的数量级不相近)。
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
加载-GET http请求。 持续时间-300秒,1秒-预热,负载5次重复。
 服务响应时间百分比的结果。
服务响应时间百分比的结果。什么是百分位数?你有很多数字。 第95个百分位数X表示此样本中95%的值小于X。以5%的概率,您的数字将大于X。
我们看到Aiohttp在如此简单的测试中以1000 RPS表现出色。 到目前为止,都没有
uvloop 。
将龙卷风与旧(合格)和新(异步)学校的协程进行比较。 作者强烈建议使用异步。 我们可以确保它们确实更快。
以1200 RPS的速度运行,甚至带有新式协程的龙卷风已经开始放弃,而带有旧式协程的龙卷风已被完全摧毁。 如果我们睡眠50毫秒,而微服务负责80毫秒-这根本不会进入任何大门。
龙卷风的新学校以1500 RPS的价格完全放弃了,而Aiohttp仍然没有达到3,000 RPS的上限。 最有趣的是尚未到来。
Pyflame,对工作中的微服务进行概要分析
让我们看看处理器当前正在发生什么。

当我们弄清楚Python异步微服务如何在生产中工作时,我们试图了解它们的全部内容。 在大多数情况下,问题出在CPU或描述符上。 在Uber中创建了一个很棒的配置工具
Pyflame profiler,它基于ptrace系统调用。
我们开始在容器中进行一些服务,并开始对其施加战斗力。 通常,这并不是一件非常琐碎的任务-创建正在运行的负载,因为经常会在负载测试,外观上运行综合测试,并且一切正常。 您将战斗负担推到他身上,微服务就开始变得钝了。
在操作过程中,此探查器为我们创建调用堆栈的快照。 您根本无法更改服务,只需在附近运行pyflame。 它将在特定时间段内收集一次堆栈跟踪,然后进行很酷的可视化。 该分析器的开销很小,特别是与cProfile相比。 Pyflame还支持多线程程序。 我们直接在产品中启动了该功能,并且性能并未降低太多。
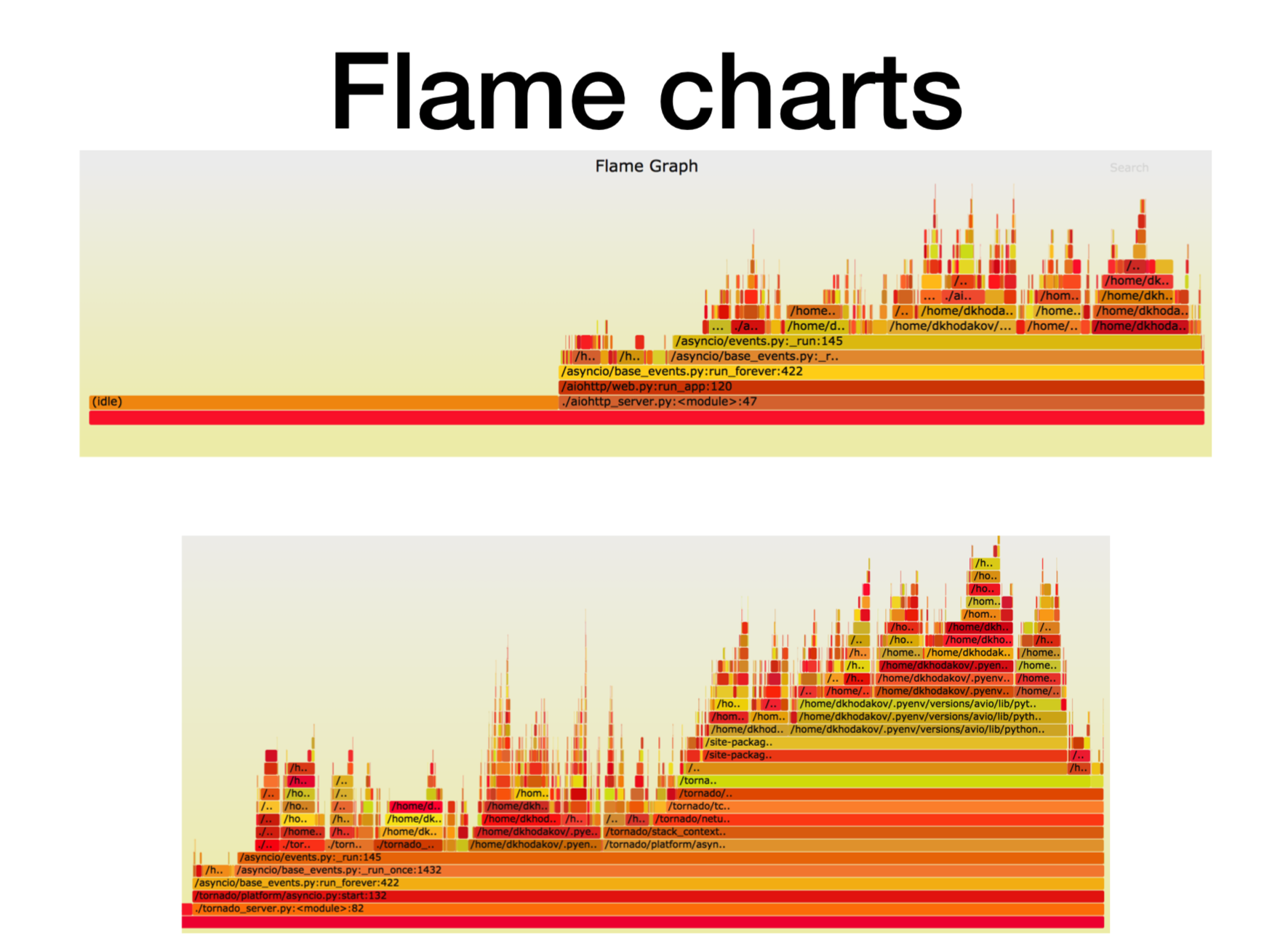
这里,X轴是当堆栈框架位于所有Python堆栈框架列表中时的时间,即调用次数。 这是我们在堆栈的该特定帧中花费的处理器时间的大约数量。
如您所见,aiohttp中的大部分时间都处于空闲状态。 很好:这是我们希望从异步服务中获得的东西,以便它大部分时间都可以处理网络调用。 在这种情况下,堆栈的深度约为15帧。
在具有相同负载的龙卷风(第二张图片)中,空闲时间花费的时间少得多,在这种情况下,堆栈深度约为30帧。
这是
svg的
链接 ,您可以改变自己。
更复杂的异步基准
async def work():
预期运行时间为125毫秒。

带有uvloop的龙卷风效果更好。 但是Aiohttp uvloop可以提供更多帮助。 Aiohttp在2300-2400 RPS上开始表现不佳,使用uvloop可以大大扩展负载范围。 一条进口线,现在您可以得到更高效率的服务。
总结
我将总结我今天想传达给您的内容。
- 首先,我启动了一个特定的人工基准,其中有相当数量的长协程。 在我们的测试中,Aiohttp的性能比Tornado好2.5倍。
- 第二个事实。 Uvloop非常有助于提高Aiohttp的性能(优于Tornado)。
- 我告诉过您有关Pyflame的信息,我们经常通过它在生产中直接分析应用程序。
- 而且,我们还谈到了(等待)收益与收益的关系。
由于有了这些基准测试,我们的建议团队(以及其他一些建议)几乎与Tornado一起完全移交给了Aiohttp,以用于生产中的Python微服务。
- 对于战斗服务,CPU消耗下降了两倍多。
- 我们开始考虑http请求的超时。
- 延迟服务下降了2到5倍。
这是
基准测试的
链接 。 如果有兴趣,可以重复。 谢谢大家的关注。 提出问题,我将尽力回答。