在圣彼得堡HSE的上一篇文章中,我们展示了机器学习如何查找程序代码中的错误。 在这篇文章中,我们将讨论我们与JetBrains Research一起如何尝试在实际的实际问题和模型示例中使用机器学习中最有趣,现代且发展最快的部分之一-强化学习。

关于我自己
我叫Nikita Sazanovich。 直到2018年6月,我在SPbAU学习了三年,然后与其他同学一起转移到圣彼得堡HSE,在那里我正在完成本科学习。 最近,我还在JetBrains Research担任研究员。 在进入大学之前,我喜欢体育节目,并为白俄罗斯国家队效力。
强化训练
强化学习是机器学习的一个分支,其中与环境交互的主体以积极或消极奖励的形式接受强化(因此得名)。 根据这些提示,代理会更改其行为。 此过程的最终目标是获得最大可能的回报,或者以另一种方式实现代理所设定的行动。
代理根据条件进行操作并选择操作。 例如,在退出迷宫的问题中,我们的状态将是x和y坐标,并且动作将是上/下/左/右。 总体方案如下所示:
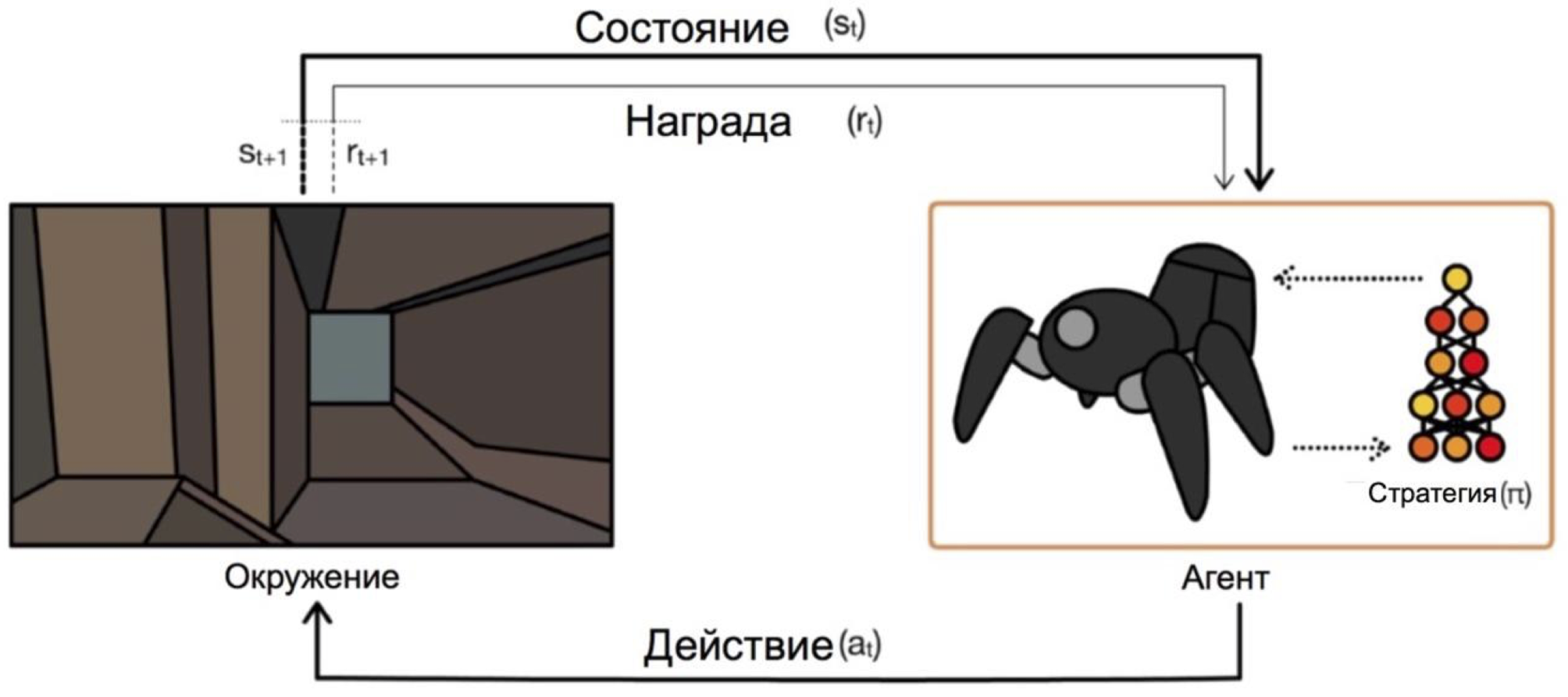
从虚构/简单任务(例如相同的迷宫)到真实/实际任务的过渡中的主要问题是:此类问题的回报通常非常罕见。 例如,如果我们想要一个代理商在城市地图上递送比萨饼,那么他将理解自己做得很好,仅通过将订单递送至门口就可以了,只有当您执行了较长且正确的操作序列后,这种情况才会发生。
可以通过在开始时为坐席提供如何“玩耍”的示例(所谓的专家演示)来解决此问题。
学习任务
本文中将讨论的模型问题是Dota 2。
Dota 2是一种流行的MOBA游戏,其中五个英雄的团队必须通过摧毁其“堡垒”来击败对立的团队。 Dota 2被认为是一款相当复杂的游戏,它在电子竞技比赛中的总奖金为2500万美元 。
您可能听说过OpenAI在Dota 2中的近期成功。首先,他们创建了一个一对一的机器人并击败了职业玩家 ,然后他们切换到5x5游戏,并在今年夏天取得了令人印象深刻的成绩 ,尽管他们输给了职业团队。

唯一的问题是, 据他们称 , 他们在Azure云上的60,000 CPU和256 K80 GPU上训练了代理的一对一游戏。 他们当然有机会订购如此多的电源。 但是,如果功率较小,则必须使用技巧。 其中一种技巧是使用人们已经玩过的游戏。
游戏中的演示
在大多数情况下,演示都是人为记录的:您只需完成任务/玩游戏,并以某种方式收集您已采取的行动。 因此,您收集了一些可以以各种方式嵌入到培训中的数据。 到目前为止,我已经这样做了,但是如何做到的-在与游戏客户端交互的方案部分结束后,这一点将很明显。
一个更大,更冒险的目标是从开放访问中获取更多数据。 选择Dota 2加快学习速度的原因之一就是dotabuff之类的资源。 收集了有关游戏的不同统计信息,但更重要的是,有完整的游戏重播信息。 并且可以按等级对它们进行排序。
到目前为止,我还没有尝试过与几集节目相比,千兆字节的此类数据将如何极大地帮助您。 实现数据收集非常简单:您可以获得dotabuff游戏的链接,下载游戏并使用Dota 2游戏解析器 。
与游戏的客户捆绑在一起进行培训
我们有一个Dota 2游戏,其客户端位于Windows,Linux和macOS平台下。 但是,尽管如此,通常培训还是以某种python脚本进行的,并在其中创建环境,无论是迷宫, 爬上山坡的机器还是类似的东西。 但是Dota 2没有环境。 因此,我本人必须创建这个包装,这在技术上非常有趣。 事实证明是这样的:
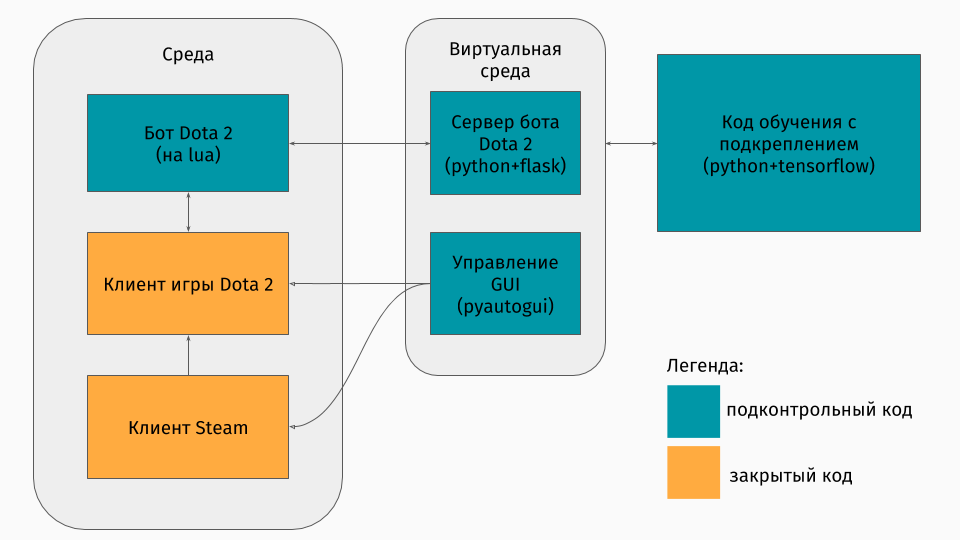
第一部分是用于与游戏客户端通信的脚本。 幸运的是,对于Dota 2,有一个用于创建机器人的官方API: Dota Bot Scripting 。 它被实现为Lua语言中的插入,事实证明,Lua语言在游戏开发中很流行。 机器人脚本与游戏客户端进行交互,在适当的时间提取我们感兴趣的信息(例如,地图上的坐标,对手的位置),并将其与json发送到服务器。
第二部分是包装器本身。 它被设计为服务器,用于处理启动Steam,Dota以及从游戏内部脚本接收json的所有逻辑。 通过pyautogui来管理启动游戏和客户端的管理,并且通过Flask服务器与游戏中的lua插入进行通信。
第三部分包括学习算法本身。 该算法选择动作,从服务器接收以下状态和奖励,在其后隐藏与游戏的所有通信并改善其行为。
向专家学习
该算法本身在本文中并不是特别重要,因为这些技术可以与任何算法一起使用。 我们使用了DQN(您可以在hub上了解到 )。 本质上,这是一种深度神经网络+ Q学习算法。 是的,这正是DeepMind为玩Atari游戏而创建的DQN。
谈论如何使用以前的游戏也更有趣。 我尝试了两种方法:基于潜力的奖励塑造和行动建议。
这些方法的总体思想是,代理不仅会因任务目标(例如,在迷宫尽头或爬山)而获得奖励,而且还会在每步训练中获得奖励。 这笔额外的报酬将显示代理人为实现最终目标所做的工作。 当然,我想自动问她,而不选择规则/条件。 以下方法有助于实现这一目标。
基于势能的奖励塑形的本质是,某些状态在我们看来最初比其他状态更有希望,并且在此基础上,我们修改了算法收到的实际奖励。 我们这样做: 在哪里 -修改后的奖项, -奖励是真实的, -来自学习算法的折扣因子(对我们来说不是很重要),但是 在我们访问期间有这种情况的潜力 。 一个简单的例子就是克服迷宫。
假设有一个迷宫,我们要从其中进入单元(0,0)进入单元(5,5)。 然后,我们对于状态(x,y)的潜力可以减去从(x,y)到目标(5.5)的欧几里得距离: 。 也就是说,我们越接近终点线,该州的潜力就越大(例如, , , ) 因此,我们会以任何方式激励代理商接近目标。
对于Dota 2,想法是相同的,但是潜力设置得稍微复杂一些:

想象一下,我们只想经历与演示者相同的状态。 然后,我们通过的状态越多,潜力就越高。 如果存在与我们相近的条件,我们将根据重放完成的百分比来确定状态的潜力。 这在各种任务中具有不同的含义。 但是在Dota 2中,这意味着首先我们要让机器人到达中心(毕竟,在演示开始时只有几步到中心),然后保持人类玩家的状态(极大的健康,与对手的安全距离等)。 )
第二种方法是行动建议,摘自本文 。 其实质是现在我们建议代理人不是国家的有用,而是行动的有用。 例如,在我们的Dota 2游戏中,可能会有这样的建议:如果您附近有敌方小兵,请攻击他; 如果您尚未到达中心,请朝中心方向前进; 如果您失去健康,请撤退到您的塔楼。 本文介绍了一种无需程序员亲自思考即可自动指定此类提示的方法。
电位是根据以下原理生成的:动作电位 能够
在相关条件下增加 一样的
行动 在示威中。 上图中的进一步奖励行动
随 。
在这里值得注意的是,我们已经为各州的行动设置了潜力。
结果
首先,我注意到游戏的目标略有简化,因为我在笔记本电脑上进行了全部教学。 该代理程序的目标是施加尽可能多的攻击,这在某种程度上似乎是真实的目标。 为此,您首先需要到达地图的中心,然后攻击对手,以免死亡。 为了加快学习速度,我只录制了一些(1至3)两分钟的演示。
使用任何一种方法对代理进行培训在个人计算机上仅需20个小时(大部分时间用于渲染Dota 2游戏),而从OpenAI图形判断,在其服务器上进行培训需要数周时间。
使用基于潜力的奖励塑造方法时游戏的短暂曝光:
对于行动建议方法:
这些笔记的训练速度是x10。 仍然可以看到特工移到中心时的行为上的不正确之处,但中心的斗争仍然显示出学到的动作。 例如,身体虚弱时退缩。
您还可以看到方法的差异:通过基于潜力的奖励塑造,代理可以平稳地移动, “以潜力去”; 通过采取行动建议,该机器人在收到有关攻击的提示时,会在中心位置更加主动地进行游戏。
总结
我立即注意到有意忽略了一些要点:确切的算法,状态的表示方式以及是否有可能训练代理与真实玩家一起玩等。
首先,在本文中,我想表明,在强化训练的情况下,您不必总是在非常简单的环境(逃离迷宫)或非常高的训练成本(根据我的粗略计算得出的结果)之间进行选择,OpenAI花费了这些服务器在Azure上进行训练的费用为$ 4715每小时)。 有可以加速学习的技术,我只讲了其中一种-演示的使用。 重要的是要注意,以这种方式,您不仅要重复演示器,而且要从演示器“推下”。 重要的是,代理商必须经过进一步培训,才能超越专家。
如果您对这些细节感兴趣,那么可以在GitHub上找到培训过程代码。