Wikibook示例( 科学文章中的插图)众所周知,维基百科是有价值的信息资源。 您可以花几个小时研究一个主题,从一个链接转到另一个链接以获取感兴趣主题的上下文。 但是,如何收集关于一个常见主题的所有内容并不总是很明显。 例如,如何结合所有有关无机化学或中世纪历史的文章来总结最重要的内容? 关于这一点,来自
Wikibook-Bot机器学习程序的开发人员的以色列内盖夫(Negev)Ben-Gurion的Shahar Admati和他的同事们试图做到这一点。
维基百科和教科书是两回事。 这就是创建
Wikibooks项目的原因,人们共同尝试总结一个主题上最重要的项目。 例如,您可以找到一本超过6,000页的机器学习教科书,其中包含有关神经网络,遗传算法和机器视觉的更新部分。
Wikibook-Bot解决了一些机器学习任务。 首先,这是一个
分类任务,也就是说,您需要确定文章是否属于特定的Wikibook。 其次,您需要将选定的文章分为几章-这是
集群的任务。 它通过众所周知的算法解决。 最后,
系统化任务包括两个子任务:每个章节中文章的顺序和章节本身的顺序。
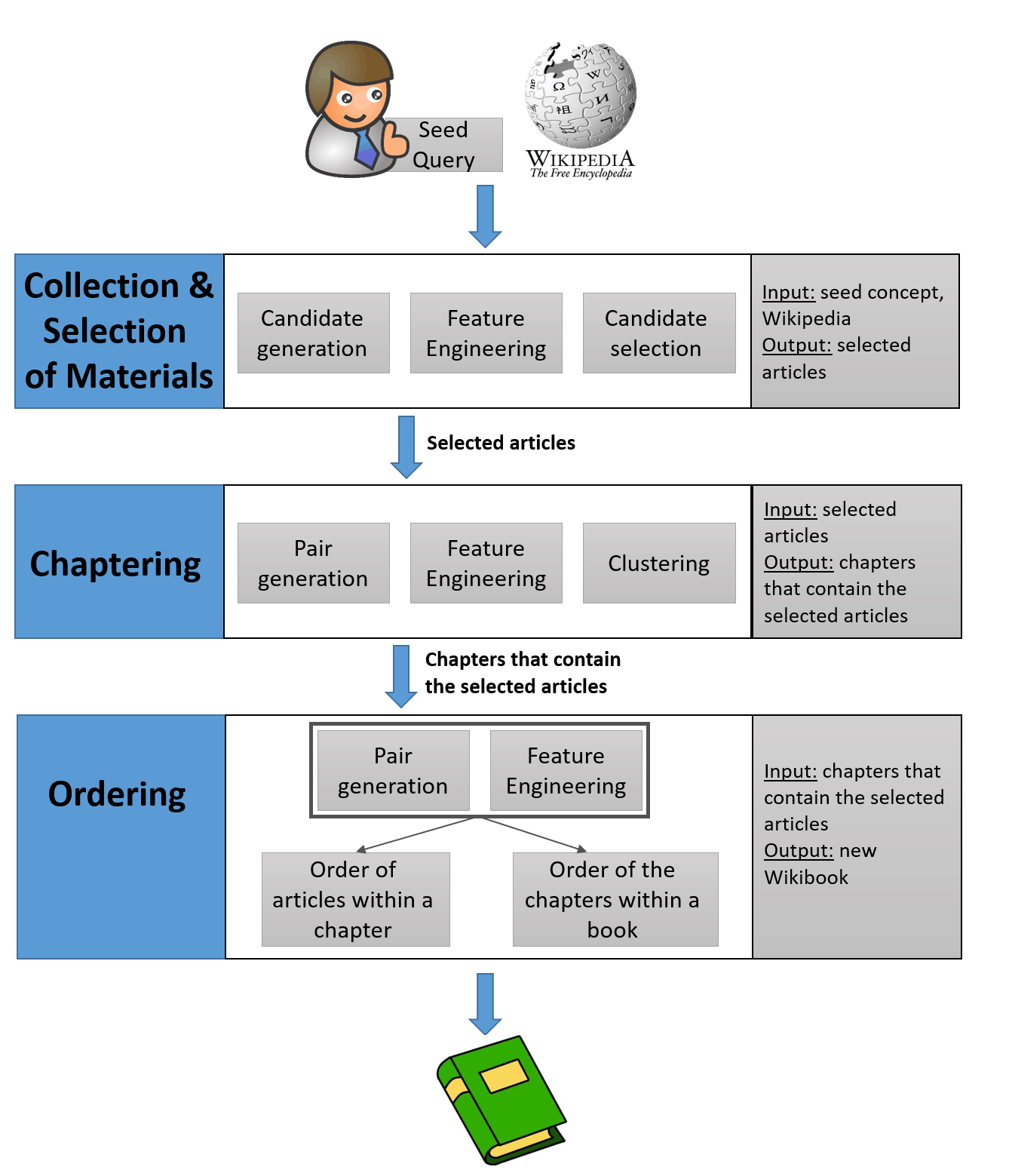
实际上,该程序的工作相对简单。 该原则对所有遇到学习神经网络的人都很清楚。 第一步是创建训练数据集。 在现有的约6700本英文Wikibook中,选择了具有1000多个视图并且有10篇或更多文章的书籍。

由于这些Wikibooks构成了培训和测试的黄金标准,因此开发人员将其视为质量标准。 在训练了神经网络之后,进一步的工作分为上面列出的几个步骤:分类,聚类和系统化。 这项工作始于人为产生的教科书标题。 该名称描述了任意概念。 例如,机器学习:完整指南。
第一项任务是对整个文章集进行排序,并确定哪些相关性足以使其包含在本主题中。 作者在科学论文中写道:“由于Wikipedia上的文章数量巨大,并且需要从数百万个可用的文章中选择最相关的文章,因此这项任务很困难。” 为了解决这个问题,他们使用了Wikipedia网络结构,因为有些文章经常链接到其他文章。 合理地假设相关文章也将与该主题相关。
因此,该工作从一小篇文章的核心开始,其中提到了给定的标题。 然后,确定距离核心最多三个过渡距离的所有商品。 但是教科书中包含多少篇文章? 这个问题的答案是由人们创建的Wikibooks给出的。 通过自动分析其内容,您可以确定教科书中包含了Wikipedia中人造书中的内容。
每个人造的Wikibook都有一个网络结构,该结构由指向其他文章的链接数量,指向页面的一定数量的链接,所包含文章的排名等定义。 所开发的算法分析给定主题的每个自动选择的文章,并回答以下问题:如果将其包括在Wikibook中,其网络结构是否会变得与某人创建的书更相似。 如果不是,则省略该文章。
主要基于训练数据和现有的机器学习方法,还可以解决其他任务。 因此,该团队能够自动生成人们已经创建的Wikibook。 通过将自动生成的书籍与407篇真正的Wikibooks进行比较,评估了该方法的有效性。 据说对于所有任务,在比较时都有可能获得较高的统计显着结果。 但是,尽管如此,在生成有关其他主题的Wikibook而不是他研究过的那些主题的Wikibook之后,才能估算出该算法的真正有效性。
该机器人的描述已在arXiv.org预印本网站上刊登为科学文章
“ Wikibook-Bot-自动生成Wikipedia图书” 。