
商业(以及非商业)服务的主要任务是始终对用户可用。 尽管每个人都崩溃了,但问题是IT团队如何最大限度地减少故障。 我们翻译了Ben Treynor,Mike Dahlin,Vivek Rau和Betsy Beyer的文章“计算服务可靠性”,其中包括以Google为例说明了为什么100%是可靠性指标的不正确参考点,什么是“四个九的规则”,以及在实践中如何通过数学方式预测服务和/或其关键组件大大小小中断的可行性-预期的停机时间,检测到故障所需的时间以及恢复服务的时间。
服务可靠性的计算
您的系统与其组件一样可靠
Ben Trainor,Mike Dalin,Vivec Rau,Betsy Beyer
如“ 网站可靠性工程:Google中的可靠性和可靠性 ”一书(以下称为SRE书)中所述,开发Google产品和服务可以在保持积极的SLO(服务水平目标,服务水平目标)的同时实现新功能的高速发布。 ),以确保高可靠性和快速响应。 SLO要求该服务几乎总是处于良好状态并且几乎总是快速。 此外,SLO还为特定服务指示“几乎始终”的确切值。 SLO基于以下观察结果:
在一般情况下,对于任何软件服务或系统,100%是可靠性指标的错误参考点,因为没有用户会注意到100%和99,999%可用性之间的差异。 在用户和服务之间,还有许多其他系统(他的笔记本电脑,家庭Wi-Fi,提供商,电源...),所有这些系统的总和不是在99.999%的情况下可用,而是更不经常使用。 因此,由于其他系统无法访问导致的随机因素,使99.999%和100%之间的差异丢失了,并且由于我们花了很多精力来实现系统可用性百分比的最后一部分,因此用户无法从中受益。 该规则的严重例外是防抱死制动器和起搏器!
有关SLO与SLI(服务级别指标)和SLA(服务级别协议)之间关系的详细讨论,请参阅SRE目标服务级别。 本章还详细描述了如何选择与特定服务或系统相关的度量,而度量又决定了为该服务或系统选择适当的SLO。
本文将SLO主题扩展为专注于服务组件。 特别是,我们将研究关键组件的可靠性如何影响服务的可靠性,以及如何设计系统以减轻影响或减少关键组件的数量。
Google提供的大多数服务旨在为用户提供99.99%(有时称为“四个九”)的可访问性。 对于某些服务,用户协议中会指定较低的数字,但是,目标99.99%被存储在公司内部。 如果SRE团队的目标1是让用户对服务感到满意,那么在用户在违反协议条款之前就抱怨服务性能的情况下,此较高的限制会带来优势。 对于许多服务而言,内部目标99.99%代表了中间立场,它平衡了成本,复杂性和可靠性。 对于其他一些,尤其是全球云服务,内部目标是99.999%。
可靠性99.99%:观察和结论
让我们看一下有关服务的设计和操作(可靠性为99.99%)的一些关键观察和结论,然后继续进行实践。
观察#1:失败的原因
发生故障的主要原因有两个:服务本身的问题和服务的关键组件的问题。 关键组件是在发生故障时会导致整个服务运行中相应故障的组件。
观察之二:可靠性数学
可靠性取决于停机的频率和持续时间。 它通过以下方式测量:
- 空闲频率或其倒数:MTTF(平均失效时间)。
- 停机时间,MTTR(平均修复时间)。 停机时间取决于用户的时间:从故障开始到恢复服务的正常运行。
因此,使用适当的单位在数学上将可靠性定义为MTTF /(MTTF + MTTR)。
结论#1:额外的规则
服务的可靠性不可能超过其所有关键组件的总和。 如果您的服务寻求确保99.99%的可用性,那么所有关键组件的可用时间都应该大大超过99.99%。
在Google内部,我们使用以下经验法则:与您所声称的服务可靠性相比,关键组件必须提供额外的九分(在上面的示例中,可用性为99.999%),因为任何服务都将具有几个关键组件以及其自身的特定问题。 这被称为“额外九人制规则”。
如果您的关键组件无法提供足够的数字(这是一个相对常见的问题!),则应最大程度地减少负面影响。
结论2:频率,检测时间和恢复时间的数学
服务的可靠性不可能超过事件发生频率以及检测和恢复时间的乘积。 例如,每年总共关闭三次,每次20分钟,总共导致60分钟的停机时间。 即使该服务在一年中的其余时间都能正常运行,也无法实现99.99%的可靠性(每年不超过53分钟的停机时间)。
这是一个简单的数学观察,但经常被忽略。
从结论1和结论2得出的结论
如果无法达到您的服务所依赖的可靠性级别,则必须努力纠正这种情况-如上所述,通过增加服务的可用性或最小化负面影响来进行纠正。 降低期望值(即声明的可靠性)也是一种选择,而且通常是最正确的选择:向依赖您的服务明确表示它必须重建系统以补偿服务可靠性中的错误,或者降低其自身的服务水平目标。 如果您自己没有消除差异,那么系统足够长的故障将不可避免地需要进行调整。
实际应用
让我们看一个目标可靠性为99.99%的服务示例,并计算出其组件和故障处理的要求。
人物
假设您的99.99%服务具有以下特征:
- 每年发生1次重大中断,而3次次中断。 这听起来很吓人,但请注意,99.99%的信任度意味着每年20-30分钟的大规模停机时间和几次短暂的部分停机。 (数学表明:a)从SLO的角度来看,一个网段的故障不视为整个系统的故障,并且b)总可靠性是由网段的可靠性之和计算得出的。)
- 其他独立服务形式的五个关键组件,具有99.999%的可靠性。
- 五个独立的部分,一个接一个地失败。
- 所有更改都是逐步进行的,一次进行一次。
可靠性的数学计算如下:
组件要求
- 一年的总错误限制是每年525,600分钟的0.01%,即53分钟(在最坏的情况下,基于365天)。
- 为关闭关键组件而分配的极限是五个独立的关键组件,每个极限为0.001%= 0.005%; 每年525,600分钟或26分钟的0.005%。
- 您服务的剩余错误限制是53-26 = 27分钟。
关机响应要求
- 预期的停机时间:4(1次完全关闭和3次关闭仅影响一个网段)
- 预期中断的累积影响:(1×100%)+(3×20%)= 1.6
- 故障检测和恢复:27 / 1.6 = 17分钟
- 分配给监视以检测故障并进行通知的时间:2分钟
- 给值班的专家开始分析警报的时间:5分钟。 (监视系统应跟踪SLO违规情况,并在每次发生系统故障时将信号发送给值班寻呼机。许多Google服务均由值班的SR轮班SR工程师提供支持,他们会响应紧急问题。)
- 有效减少不良影响的剩余时间:10分钟
结论:利用杠杆作用来提高服务可靠性
值得仔细看一下所提供的数据,因为它们强调了基本点:有三个主要杠杆可提高服务的可靠性。
- 通过发布策略,测试,对项目结构的定期评估等,减少中断的频率
- 通过细分,地理隔离,逐步降级或与客户隔离来减少平均停机时间。
- 减少恢复时间-通过监视,一键式救援操作(例如,回滚到以前的状态或增加备用电源),操作准备实践等。
您可以在这三种方法之间取得平衡,以简化容错的实现。 例如,如果很难达到17分钟的MTTR,则应着重减少平均停机时间。 本文后面将详细讨论最小化不利影响和减轻关键组件影响的策略。
澄清“嵌套规则的附加九”
随机读者可能会得出结论,依赖关系链中的每个附加链接都需要附加九个,因此二阶依赖关系需要两个附加九,三阶依赖关系需要三个附加九,等等。
这是错误的结论。 它基于以树的形式在各个级别上具有恒定分支的组件层次结构的幼稚模型。 在这样的模型中,如图 如图1所示,存在10个唯一的一阶组件,100个唯一的二阶组件,1,000个唯一的三阶组件等,即使将体系结构限制为四层,总共也有1,111个唯一的服务。 具有如此众多独立关键要素的,高度可靠的服务生态系统显然是不现实的。
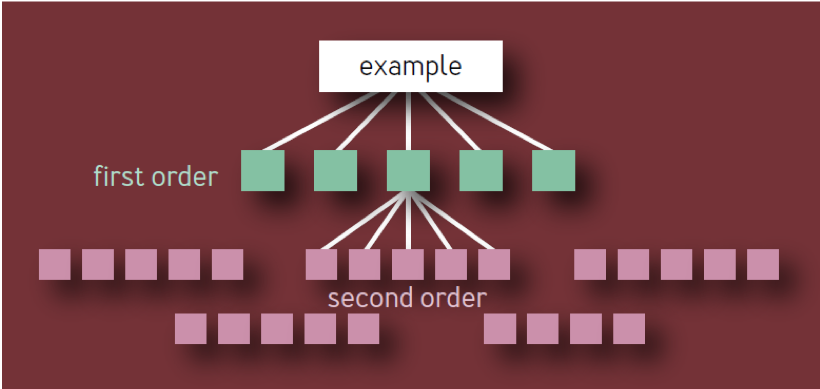
图 1-组件层次结构:无效的模型
关键组件本身可能导致整个服务(或服务段)发生故障,无论它在依赖关系树中的何处。 因此,如果将X的给定组件显示为几个一阶组件的依存关系,则X应当仅被计数一次,因为X的失败最终会导致服务失败,而不管多少中间服务也受到影响。
正确阅读规则如下:
- 如果服务具有N个唯一的关键组件,则每个组件对由该组件引起的整个服务的不可靠性都会造成1 / N的影响,无论其在组件层次结构中有多低。
- 即使每个组件在组件层次结构中出现多次,每个组件也应仅计数一次(换句话说,仅对唯一组件进行计数)。 例如,在计算图1中的服务A的组件时, 2,服务B应该只考虑一次。
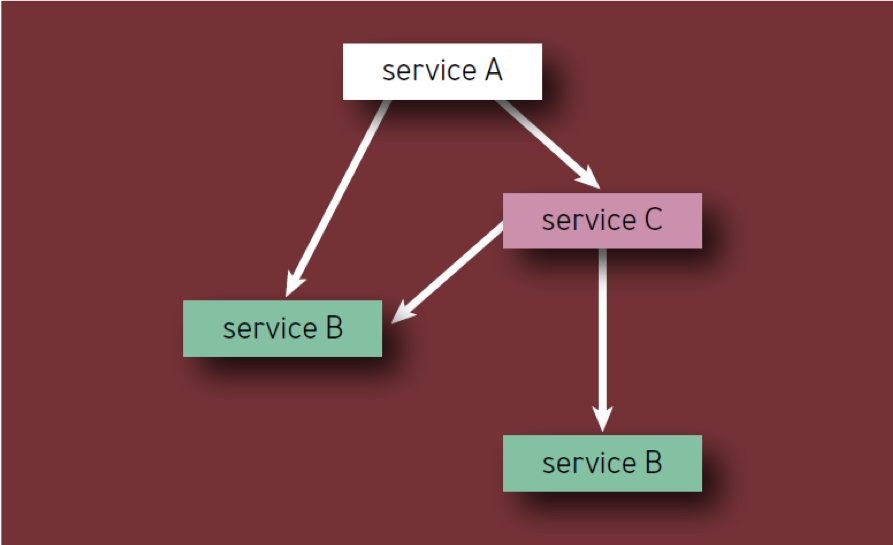
图 2-层次结构中的组件
例如,假设一个假设服务A的错误限制为0.01%。 服务所有者准备将这个限制的一半用于自己的错误和损失,另一半用于关键组件。 如果服务具有N个此类组件,则每个组件都会收到剩余错误限制的1 /N。 典型的服务通常具有5到10个关键组件,因此每个组件只能拒绝服务A的错误限制的十分之一或二十分之一。因此,通常,服务的关键部分应具有一个额外的九个可靠性。
误差极限
SRE一书中详细介绍了错误限制的概念,但在此应该提及。 Google SR工程师使用错误限制来平衡更新的可靠性和速度。 此限制确定在一定时间段(通常为一个月)内服务可接受的故障级别。 错误限制仅为1减去服务的SLO,因此先前讨论的99.99%的可用服务对可靠性的限制为0.01%。 在服务在一个月内用完错误限制之前,开发团队可以自由(有理由地)启动新功能,更新等。
如果错误限制用完,则将暂停对服务的更改(紧急安全修复和旨在首先导致违规的更改除外),直到服务在错误限制中补充储备金或直到月份更改为止。 Google的许多服务都将滑动窗口方法用于SLO,以便逐渐恢复错误限制。 对于SLO高于99.99%的严重服务,建议使用季度重置而不是每月重置一次,因为允许的停机时间很少。
错误限制消除了SR工程师和产品开发人员之间可能会出现的部门之间的紧张关系,从而为他们提供了基于数据的通用风险评估工具来启动产品。 它们还为SR工程师和开发团队提供了一个共同的目标,即开发方法和技术,使他们能够更快地进行创新并推出产品,而不会出现“预算膨胀”的情况。
关键组件减少和缓解策略
至此,在本文中,我们已经建立了所谓的“组件可靠性黄金法则”。 这意味着任何关键组件的可靠性都应比整个系统的目标可靠性水平高10倍,以便其对系统不可靠性的贡献保持在错误水平。 因此,在理想情况下,任务是使尽可能多的非关键组件成为可能。 这意味着组件可以坚持较低的可靠性,从而为开发人员提供了创新和冒险的机会。
减少关键依赖性的最简单,最明显的策略是在可能的情况下消除单点故障。 大型系统应该能够在没有任何非关键依赖或SPOF的给定组件的情况下可接受地运行。
实际上,您很可能无法摆脱所有关键的依赖关系。 但是您可以遵循一些系统设计准则来优化可靠性。 尽管这并非总是可能的,但是如果您在设计和规划阶段而不是在系统工作并影响实际用户之后才能实现可靠性,则更容易且更有效地实现系统的高可靠性。
项目结构评估
在计划新系统或服务时,或者在重新设计或改进现有系统或服务时,对体系结构或项目的审查可能会揭示出通用的基础结构以及内部和外部依赖性。
共享基础架构
如果您的服务使用共享的基础结构(例如,可供用户使用的几种产品使用的主数据库服务),请考虑是否正确使用了该基础结构。 明确将共享基础结构的所有者标识为其他项目参与者。 另外,请注意组件重载-为此,请与这些组件的所有者仔细协调启动过程。
内部和外部依赖
有时,产品或服务取决于公司控制范围之外的因素-例如,来自软件库或服务以及来自第三方的数据。 识别这些因素将最大程度地减少其使用带来的不可预期的后果。
仔细规划和设计系统
在设计系统时,请注意以下原则:
冗余和隔离
您可以尝试通过创建关键组件的几个独立实例来减少关键组件的影响。 例如,如果将数据存储在一个实例中可确保该数据具有99.9%的可用性,那么从理论上讲,将三个副本存储在三个分布广泛的副本中将提供1-0.013或9个九的可用性级别(如果实例独立于零关联而失败)。
在现实世界中,相关性永远不会为零(查看同时影响多个单元的骨干网络的故障),因此实际的可靠性永远不会接近九个九,而远远超过三个九。
同样,向同一群集中的一个服务器池发送RPC(远程过程调用)可以提供99%的结果可用性,而同时向三个不同的服务器池发送三个RPC并接受第一个响应将有助于达到可用性级别。高于三个九(见上文)。 如果服务器池与RPC发送器等距,此策略还可以缩短响应时间延迟的尾巴。 (由于同时发送三个RPC的成本很高,因此Google通常会从策略上分配这些调用的时间:我们的大多数系统在发送第二个RPC之前会分配一些时间,而在发送第三个RPC之前会花费一些时间。)
储备金及其应用
设置软件的启动和移植,以使系统在单个部件发生故障时(故障保护)继续工作,并在出现问题时隔离自身。 这里的基本原则是,当您连接人员打开备用电源时,您可能会超出错误限制。
异步性
为防止组件变得至关重要,请尽可能异步设计它们。 如果服务期望来自其非关键部分之一的RPC响应,这表明响应时间急剧下降,则这种下降将不必要地恶化父服务的性能。 将非关键组件的RPC设置为异步模式将使父服务的响应时间不受绑定到该组件的性能的影响。 尽管异步会使服务的代码和基础架构复杂化,但这种折衷还是值得的。
资源规划
确保为所有组件提供了所需的一切。 , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
结论
尽管读者可能熟悉本文中描述的一些或许多概念,但是使用它们的特定示例将帮助他们更好地理解其本质并将这些知识传递给其他人。我们的建议并不简单,但并非无法实现。许多Google服务已反复证明其可靠性超过四分之九,这不是由于超人的努力或智慧,而是由于多年来多年开发的原理和最佳实践的认真应用(请参阅SRE,附录B:《工业运营服务实用指南》)。