在我参与的一年多一点的时间里,发生了以下“对话”:
.Net App :嗨,实体框架,给我很多数据!
实体框架 :对不起,我不了解您。 什么意思
.Net App :是的,我刚刚收集了10万笔交易。 现在,我们需要快速检查那里显示的证券价格的正确性。
实体框架 :嗯,让我们尝试一下...
.Net App :这是代码:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
实体框架 :

经典版 我认为许多人都熟悉这种情况:当我真的想“美丽”并使用本地集合的JOIN和DbSet快速在数据库中进行搜索时。 通常,这种体验令人失望。
在本文(这是我其他文章的免费翻译 )中,我将进行一系列实验,并尝试各种方法来解决这一限制。 会有一个代码(不复杂),思想和诸如幸福的结局之类的东西。
引言
每个人都知道Entity Framework ,每天都有很多人使用它,并且有很多很好的文章介绍了如何正确地制作它(使用更简单的查询,使用Skip and Take中的参数,使用VIEW,仅请求必要的字段,监视查询缓存和其他),但是本地集合和DbSet的JOIN主题仍然是薄弱点。
挑战赛
假设有一个包含价格的数据库,并且有一个需要检查价格正确性的交易集合。 并假设我们有以下代码。
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
此代码根本不在Entity Framework 6中工作。 在Entity Framework Core中 -它可以工作,但是一切都将在客户端完成,并且在数据库中有数百万条记录的情况下,这不是一个选择。
正如我所说,我将尝试不同的方法来解决此问题。 从简单到复杂。 在实验中,我使用以下存储库中的代码。 使用以下代码编写代码: C# ,.Net Core , EF Core和PostgreSQL 。
我还拍摄了一些指标:花费的时间和内存消耗。 免责声明:如果测试进行了10分钟以上,我会打断它(限制来自上面)。 测试机器Intel Core i5、8 GB RAM,SSD。
数据库架构
仅3个表格: 价格 , 证券和价格来源 。 价格 -包含1000万个条目。
方法1。天真
让我们开始简单并使用以下代码:
方法1的代码 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
这个想法很简单:在一个循环中,我们一次从数据库读取一条记录,然后将其添加到结果集合中。 这段代码只有一个优点-简单。 缺点之一是速度慢:即使数据库中有索引,大多数情况下它也会与数据库服务器通信。 指标如下:
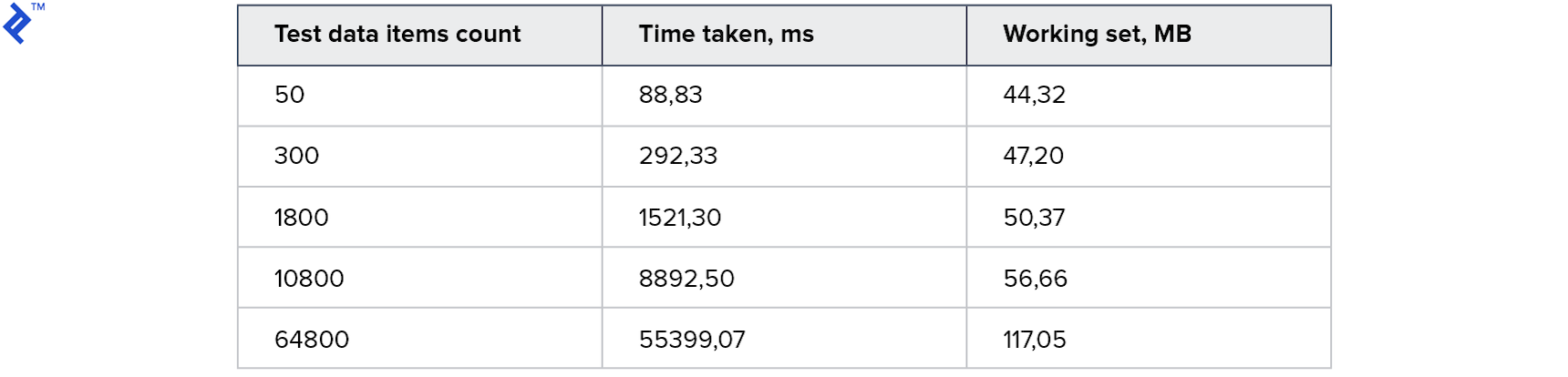
内存消耗很小。 大量收藏需要1分钟。 首先,还不错,但我希望更快。
方法2:天真并行
让我们尝试添加并行性。 这个想法是从多个线程访问数据库。
方法2的代码 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
结果:
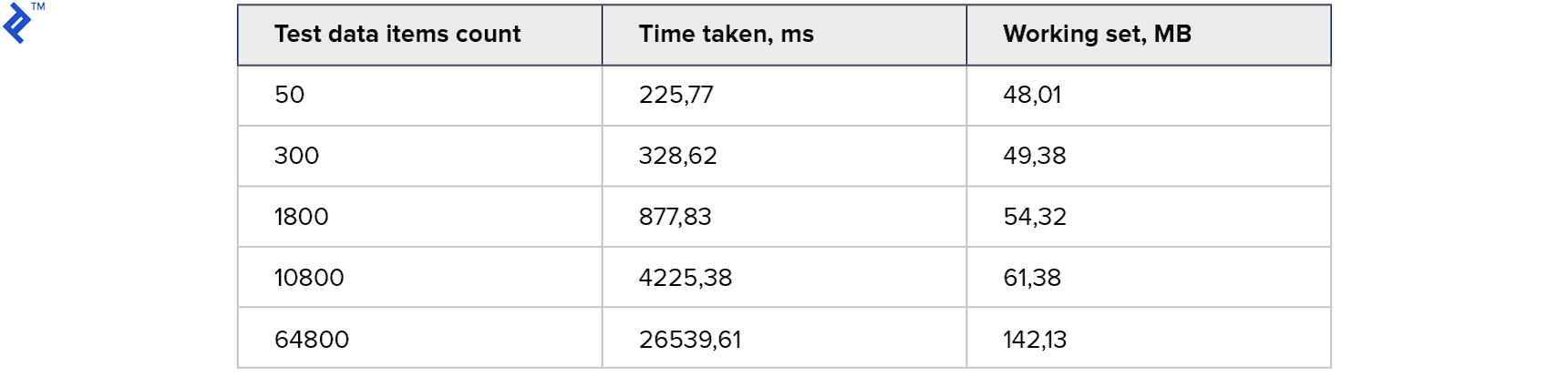
对于小型馆藏,此方法甚至比第一种方法慢。 而最大的-快2倍。 有趣的是,我的机器上生成了4个线程,但这并没有导致4倍的加速。 这表明此方法的开销很大:无论是在客户端还是在服务器端。 内存消耗增加了,但没有明显增加。
方法3:多个包含
是时候尝试其他尝试并将任务简化为一个查询了。 可以按照以下步骤完成:
- 准备3个唯一的Ticker , PriceSourceId和Date集合
- 运行请求并使用3个包含
- 在本地重新检查结果
方法3的代码 var result = new List<Price>(); using (var context = CreateContext()) {
这里的问题是执行时间和返回的数据量高度依赖于数据本身(在查询和数据库中)。 即,仅返回必要数据的集合,并且可以返回额外的记录(甚至多100倍)。
可以使用以下示例进行说明。 假设有包含数据的下表:

还假设我需要TradedOn = 2018-01-01的Ticker1和TradedOn = 2018-01-02的Ticker2的价格。
然后代码的唯一值=( Ticker1 , Ticker2 )
而且TradedOn的唯一值=( 2018-01-01,2018-01-02 )
但是,结果将返回4条记录,因为它们确实对应于这些组合。 不好的是,使用的字段越多,结果获得更多记录的机会就越大。
因此,必须在客户端另外过滤通过此方法获得的数据。 这是最大的缺点。
指标如下:
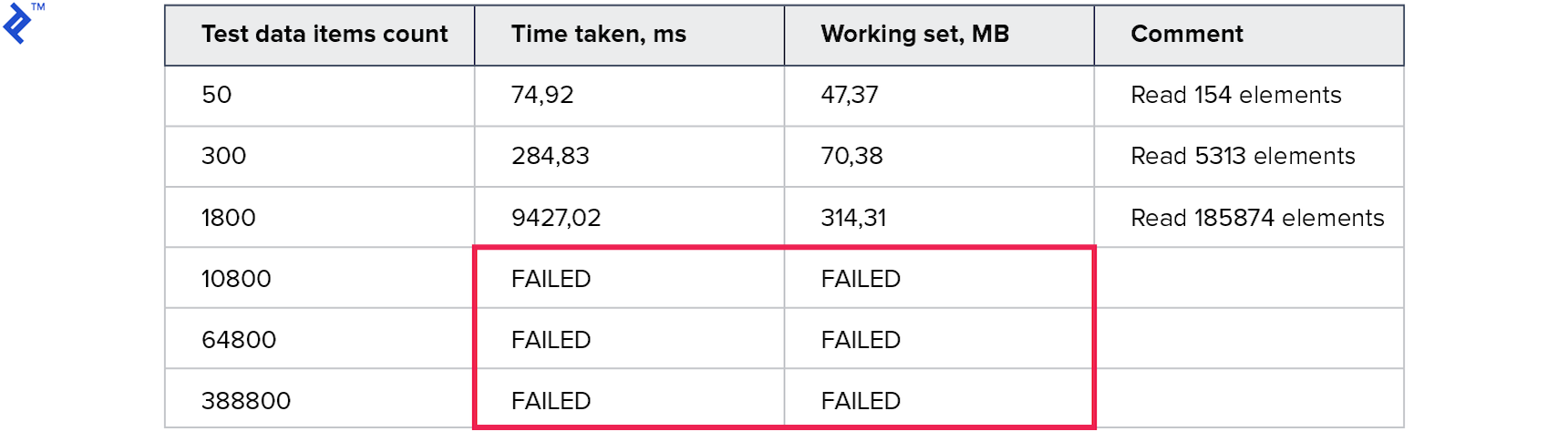
内存消耗比以前的所有方法都要糟糕。 读取的行数比请求的行数大很多倍。 大型集合的测试运行了10分钟以上,因此被中断。 这种方法不好。
方法4.谓词生成器
让我们在另一侧尝试一下:好的老式Expression 。 使用它们,您可以按照以下形式构建1个大型查询:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
这给希望建立1个请求并仅获得1个呼叫的必要数据的希望。 代码:
方法4的代码 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
事实证明,该代码比以前的方法更复杂。 手动构建Expression不是最简单,最快的操作。
指标:
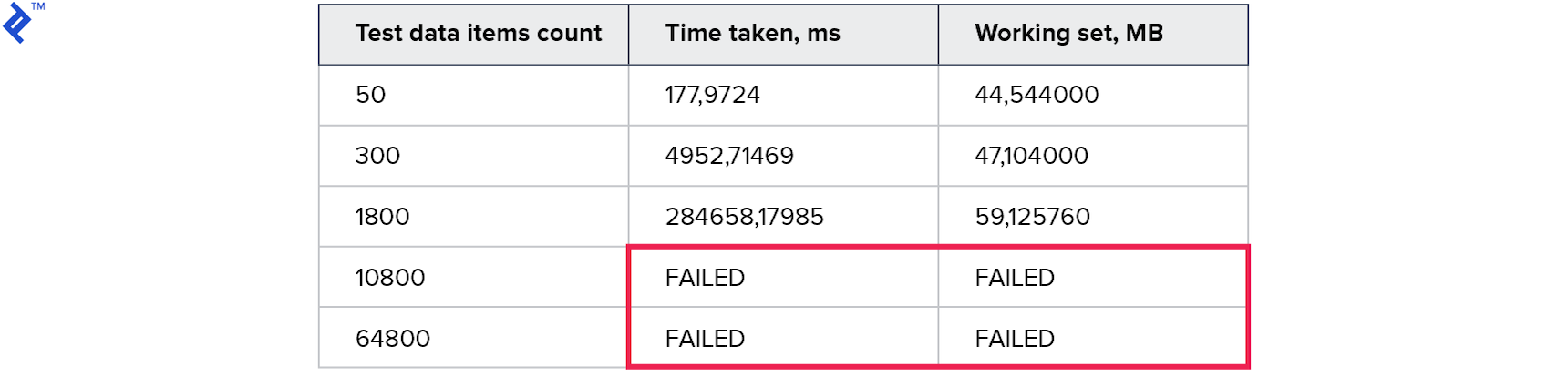
临时结果甚至比以前的方法差。 看起来,在构造过程中以及在穿过树时的开销远远大于使用一个请求所带来的收益。
方法5:共享查询数据表
让我们尝试另一个选择:
我在数据库中创建了一个新表,在其中将写入完成请求所需的数据(这意味着在上下文中我需要一个新的DbSet )。
现在,要获得结果,您需要:
- 开始交易
- 将查询数据上传到新表
- 运行查询本身(使用新表)
- 回滚事务(清除数据表以进行查询)
代码如下:
方法5的代码 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
第一指标:
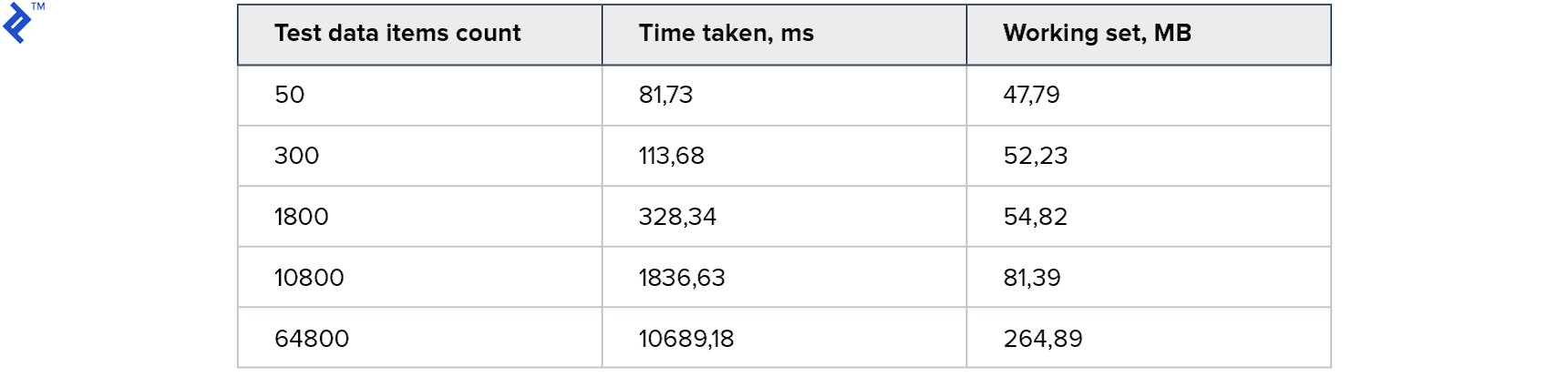
所有测试都有效并且很快! 内存消耗也是可以接受的。
因此,通过使用事务,该表可以被多个进程同时使用。 由于这是一个真实存在的表,因此我们可以使用Entity Framework的所有功能:您只需将数据加载到表中,使用JOIN生成查询并执行它。 乍一看,这是您所需要的,但是有很多缺点:
- 您必须为特定类型的查询创建表
- 有必要使用事务(并浪费事务上的DBMS资源)
- 而且,当您需要阅读时,您需要写一些东西的想法看起来很奇怪。 在只读副本上,它将无法正常工作。
其余的是或多或少可以使用的解决方案。
方法6。MemoryJoin扩展
现在,您可以尝试改进以前的方法。 这些想法是:
- 您可以使用一些通用选项来代替使用特定于一种查询类型的表。 即,创建一个具有诸如shared_query_data之类的名称的表,并向其中添加几个Guid字段,几个Long ,几个String等。 可以采用简单的名称: Guid1 , Guid2 , String1 , Long1 , Date2等。 然后,该表可用于95%的查询类型。 稍后可以使用“ 选择”透视图“调整”属性名称。
- 接下来,您需要为shared_query_data添加一个DbSet 。
- 但是,如果不是使用VALUES构造传递值,而不是将数据写入数据库,该怎么办? 也就是说,有必要在最终的SQL查询中,而不是访问shared_query_data,应该吸引VALUES 。 怎么做?
- 在Entity Framework Core中-仅使用FromSql 。
- 在Entity Framework 6中-您必须使用DbInterception-也就是说,通过在执行之前添加VALUES构造来更改生成的SQL。 这将导致限制:在一个请求中,最多只能有一个VALUES构造。 但这会起作用!
- 由于我们不打算写数据库,因此我们在第一步中创建了shared_query_data表,是否根本不需要它? 答:是的,它不是必需的,但仍然需要DbSet ,因为实体框架必须知道数据方案才能构建查询。 事实证明,对于某些通用模型,我们需要一个DbSet ,该模型在数据库中不存在,仅用于激发实体框架,它知道它在做什么。
将IEnumerable转换为IQueryable示例- 输入接收到以下类型的对象的集合:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- 我们可以使用字段String1 , String2 , Date1 , Long1 等 DbSet
- 让代码行存储在String1 , Date1的TradedOn以及Long1的PriceSourceId中( int映射为long ,以便不将int和long的字段分开)
- 然后, FromSql + VALUES将如下所示:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- 现在,您可以进行投影并使用与输入相同的类型返回一个方便的IQueryable :
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
我设法实现了这种方法,甚至将其设计为NuGet包EntityFrameworkCore.MemoryJoin ( 代码也可用)。 尽管名称中包含单词Core ,但也支持Entity Framework 6。 我将其称为MemoryJoin ,但实际上它会将本地数据发送到VALUES构造中的DBMS,并且所有工作都在此完成。
代码如下:
方法6的代码 var result = new List<Price>(); using (var context = CreateContext()) {
指标:
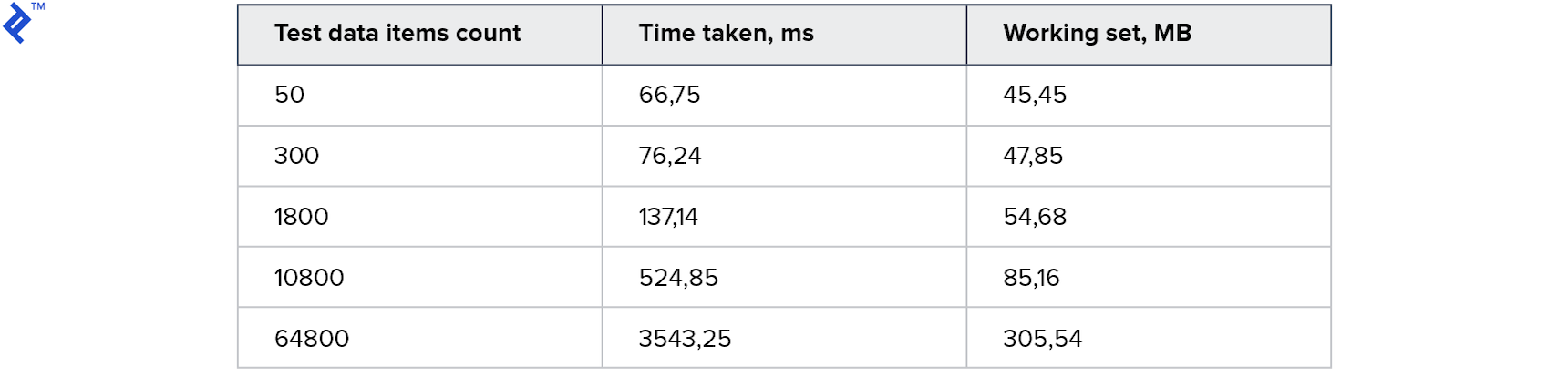
这是我尝试过的最好结果。 该代码非常简单明了,并且同时适用于只读副本。
生成的用于接收3个元素的请求的示例 SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
在这里,您还可以看到使用Select的广义模型(具有String1 , Date1 , Long1字段)如何变成代码中使用的模型(具有Ticker , TradedOn , PriceSourceId字段)。
所有工作都在SQL服务器上的1个查询中完成。 这是一个小小的幸福结局,我在开始时就谈到了。 但是,使用此方法需要了解并执行以下步骤:
- 您需要在上下文中添加一个额外的DbSet (尽管表本身可以省略 )
- 在默认情况下使用的通用模型中,声明了类型为Guid , String , Double , Long , Date等的3个字段。 对于95%的请求类型,这应该足够了。 并且,如果将具有20个字段的对象的集合传递给FromLocalList ,则将引发Exception ,表示该对象太复杂。 这是一个软限制,可以绕开-您可以声明类型并在其中添加至少100个字段。 但是,更多字段的工作速度较慢。
- 我的文章中介绍了更多技术细节。
结论
在本文中,我介绍了有关JOIN本地集合和DbSet的想法。 在我看来,使用VALUES进行开发可能会引起社区的兴趣。 当我自己解决这个问题时,至少我没有遇到这种方法。 就个人而言,这种方法可以帮助我克服当前项目中的许多性能问题,也许对您也有帮助。
有人会说MemoryJoin的使用过于“ 抽象 ”,需要进一步开发,在此之前,您不需要使用它。 这正是我非常怀疑的原因,并且近一年来我都没有写这篇文章。 我同意我希望它更轻松地工作(希望有一天能做到),但是我也要说,优化从来都不是Junior的任务。 优化始终需要了解工具的工作方式。 如果有机会获得约8倍的加速( Naive Parallel vs MemoryJoin ),那么我将掌握2分和文档。
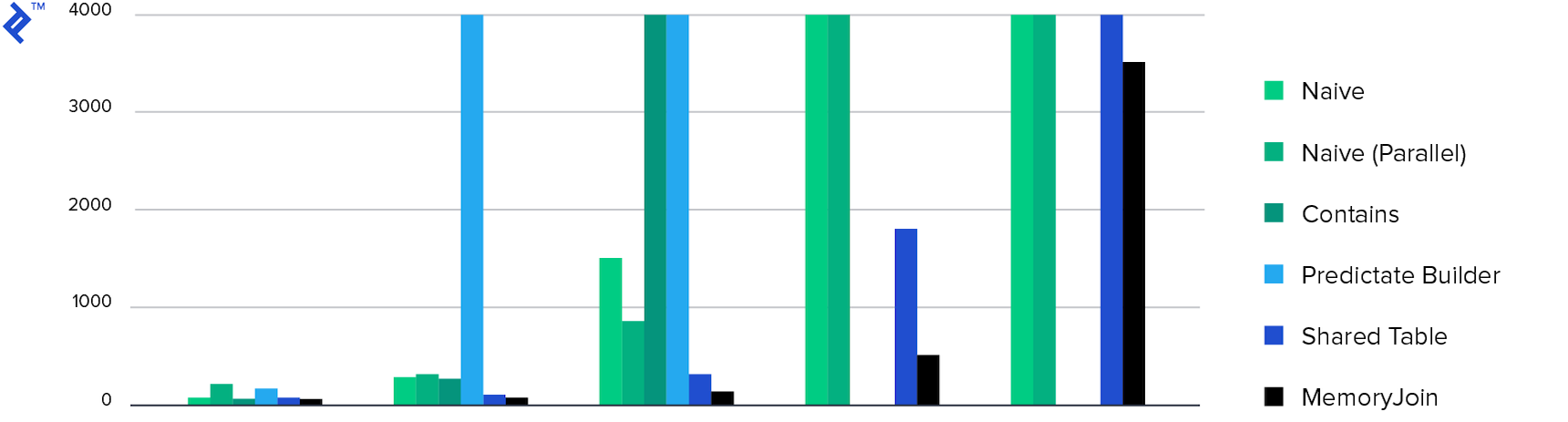
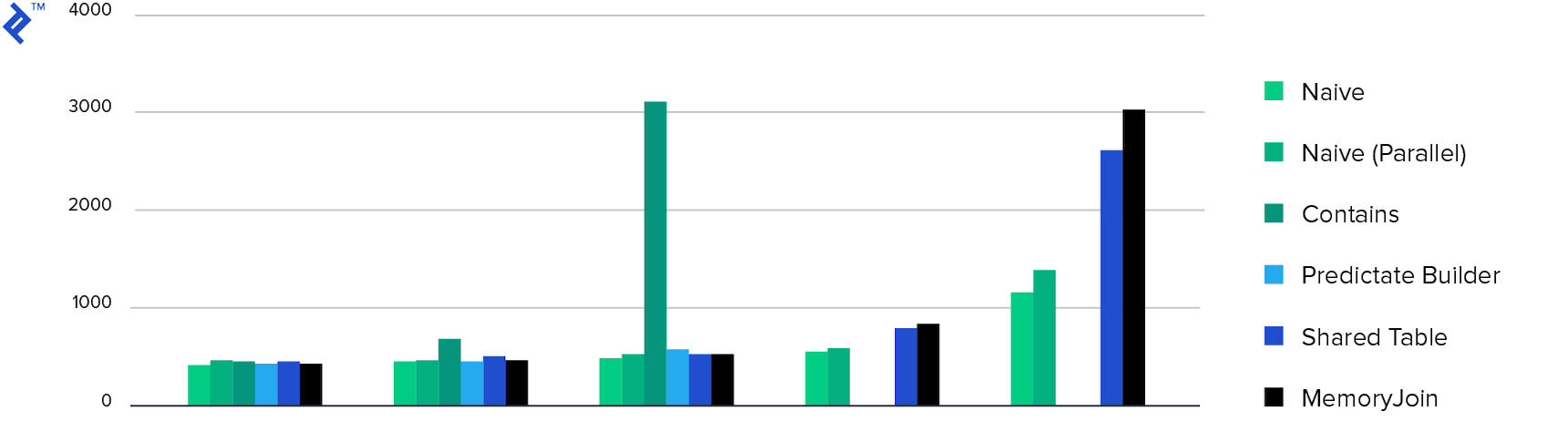
最后,这些图:
花时间。 在不到10分钟的时间内只有4种方法完成了任务,而MemoryJoin是在不到10秒的时间内完成任务的唯一方法。
内存消耗。 除了Multiple Contains之外,所有方法都显示出大致相同的内存消耗。 这是由于返回的数据量。
感谢您的阅读!