
当数据集包含文本文档并且标签用于训练文本分类器时,
文本分类是
NLP和教师培训中最常见的任务之一。
从NLP的角度来看,对文本进行分类的任务是通过使用单词嵌入在单词级别上讲授表示形式,然后训练用作分类功能的文本级别上的表示形式来完成的。
基于编码的方法的类型忽略了小的细节和分类关键字(因为通过压缩单词级别的表示来研究文本级别的一般表示)。
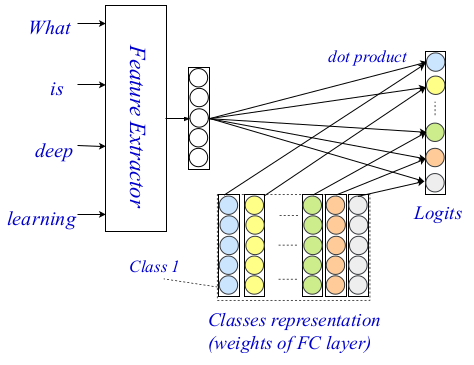 基于编码的文本级匹配文本分类方法
基于编码的文本级匹配文本分类方法考试-新的文字分类方法
山东大学和新加坡国立大学的研究人员
提出了一种新的文本分类模型 ,该
模型在文本分类任务中包括单词级匹配信号。 他们的方法使用一种交互机制将单词级别的详细提示引入分类过程。
为了解决包括更准确的词级匹配信号的问题,研究人员提出了
显式计算词与类之间的对应估计的方法 。
主要思想是从单词级别的表示形式计算交互矩阵,该表示形式将在单词级别上携带相应的键。 此矩阵中的每个条目都是对单词和特定类别之间的对应关系的评估。
提议的文本分类结构称为EXAM-EXplicit interAction Model(
GitHub ),包含三个主要组件:
这种三层体系结构使您可以使用小型和通用信号和提示对文本进行编码和分类。 下图显示了整个体系结构。
 考试架构
考试架构过去,在NLP社区中对词级编码器进行了广泛的研究,并且出现了功能强大的编码器。 作者使用sovermenny方法作为词级编码器,并且在工作中详细描述了其体系结构的其他两个组成部分:交互级别和聚合级别。
该方法的交互层,主要贡献和新颖性均基于众所周知的交互机制。 研究人员使用
训练有素的表示矩阵对每个类进行编码,以便他们以后可以计算类之间的交互估计。 根据目标词和每个班级之间的互动,使用分数积来固定最终分数。 由于计算复杂性增加,未考虑使用更复杂的功能。
 图层可视化
图层可视化最后,他们使用一个简单的,完全连接的两层MLP作为聚合层。 他们还提到,此处可以使用更复杂的聚合级别,包括CNN或LSTM。 MLP用于使用交互矩阵和单词级别编码来计算最终分类对数。 交叉熵被用作损失的函数以进行优化。
年级
为了评估建议的文本分类框架,研究人员在多类和多标签条件下进行了广泛的实验。 他们表明,他们的方法远远优于现代相关的现代方法。
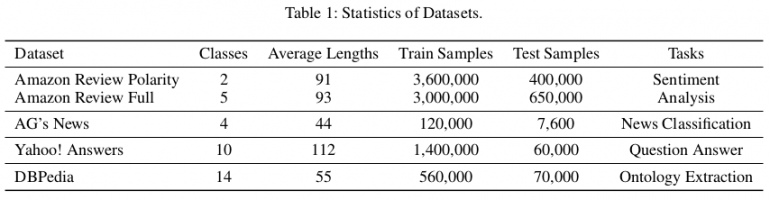 用于评估的已使用数据集的统计信息
用于评估的已使用数据集的统计信息为了进行评估,他们建立了三种不同的基本模型:
- 基于属性发展的模型;
- 基于深度角色的模型
- 基于深度词的模型。
作者使用公开可用的参考数据集(Zhang,Zhao和LeCun 2015)评估了该方法。 总共有六组分类文本数据,分别对应于分析情绪,对新闻,问题和答案进行分类以及提取本体的任务。 在本文中,他们表明EXAM在三个数据集(AG,Yah)中实现了最佳性能。 答:和DBP。 下表列出了与其他方法的评估和比较。
![多类文档分类任务上的测试集准确性[%],并与其他方法进行比较](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

结论
这项工作是对自然语言处理(NLP)领域的重要贡献。 这是在深度神经网络模型中将更准确的词级匹配提示引入文本分类的第一项工作。 所提出的模型为几个数据集提供了最新的指标。
翻译-Stanislav Litvinov