最初,对精彩文章《
理想编程语言的主观视野 》的第一条评论是
对Zig编程语言的引用。 自然地,它成为一种有趣的语言,它声称是C ++,D和Rust的利基市场。 我看了一下-语言看起来很漂亮,而且有些有趣。 类似于si的漂亮语法,错误处理的原始方法,内置的协程。 本文是对
官方文档的简要概述,并散布着自己在运行代码示例中的想法和印象。
开始使用
对于Windows,安装编译器非常简单-只需将分发包解压缩到某个文件夹中即可。 我们在同一文件夹中创建一个hello.zig文本文件,在该文件中插入代码并保存。 汇编由命令完成
zig build-exe hello.zig
之后,hello.exe出现在同一目录中。
除了汇编外,还可以使用单元测试模式,为此,在代码中使用了测试块,并且由命令执行了测试的组装和启动。
zig test hello.zig
初古怪
编译器不支持Windows换行符(\ r \ n)。 当然,每个系统(Win,Nix,Mac)中的换行符都是其自身原因,这是荒谬的,并且是过去的遗物。 但是没有什么可做的,因此,例如,只需在记事本++中选择所需的编译器格式即可。
我偶然遇到的第二个奇怪问题-代码中不支持制表符! 只有空格。 但它发生了:)
但是,这是诚实地写在文档中的-事实已经在最后。
留言
另一个奇怪的是,Zig不支持多行注释。 我记得在古老的涡轮帕斯卡程序中一切都正确完成了-支持嵌套的多行注释。 显然,自那时以来,没有一个语言开发人员已经掌握了这么简单的方法:)
但是有文献评论。 以///开头。 必须在某些地方-对应对象(变量,函数,类等)的前面。 如果它们在其他地方-编译错误。 还不错
变量声明
首先以关键词(const或var)编写,然后是名称,然后是类型,然后是初始值,以现在流行的风格(在意识形态上正确)完成。 即 自动类型推断可用。 变量必须初始化-如果您不指定初始值,则将出现编译错误。 但是,提供了一个特殊的未定义值,可以明确地使用它来指定未初始化的变量。
var i:i32 = undefined;
控制台输出
对于实验,我们需要输出到控制台-在所有示例中,这都是使用的方法。 在插件领域
const warn = std.debug.warn;
代码是这样写的:
warn("{}\n{}\n", false, "hi");
编译器存在一些错误,当尝试通过这种方式输出整数或浮点数时,会诚实地报告这些错误:
错误:编译器错误:必须对var args函数中的整数和浮点常量进行强制转换。 github.com/ziglang/zig/issues/557
资料类型
原始类型
类型名称显然取自Rust(i8,u8,... i128,u128),还有一些特殊的类型用于二进制C兼容性,有4种类型的浮点类型(f16,f32,f64,f128)。 有一个布尔型。 有一种零长度的空隙和特殊的返回,我将在后面讨论。
您还可以构造长度在1到65535之间的任何长度的整数类型。类型名称以字母i或u开头,然后写入以位为单位的长度。
// ! var j:i65535 = 0x0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF0123456789ABCDEF;
但是,我无法将此值提供给控制台-编译过程中LLVM中发生错误。
通常,这是一个有趣的解决方案,尽管模棱两可(恕我直言:在编译器级别支持完全长的数字文字是正确的,但是用这种方式命名类型不是很好,最好通过模板类型进行诚实地命名)。 为什么限制为65535? 像GMP这样的图书馆似乎没有施加这样的限制吗?
字符串文字
这些是字符数组(末尾没有尾随零)。 对于以零结尾的文字,将使用前缀“ c”。
const normal_bytes = "hello"; const null_terminated_bytes = c"hello";
与大多数语言一样,Zig支持标准的转义序列,并通过其代码插入Unicode字符(\ uNNNN,\ UNNNNNN,其中N是十六进制数字)。
多行文字是在每行的开头使用两个反斜杠形成的。 不需要引号。 也就是说,有人尝试制作原始行,但恕我直言是不成功的-原始行的优点是您可以在代码中的任何位置插入任何文本-理想情况下不做任何更改,但是在这里您必须在每行的开头添加\\。
const multiline = \\#include <stdio.h> \\ \\int main(int argc, char **argv) { \\ printf("hello world\n"); \\ return 0; \\} ;
整数文字
一切都以si式语言表达。 我很高兴,对于八进制文字,使用前缀0o,而不仅仅是C中的零。 还支持带有0b前缀的二进制文字。 浮点文字可以是十六进制的(就像在
GCC扩展中所做的那样)。
运作方式
当然,有标准的算术,逻辑和按位C操作。 支持缩写操作(+ =等)。 代替&&和|| 使用关键字and和or。 有趣的一点是,还支持具有保证的环绕语义的操作。 他们看起来像这样:
a +% b a +%= b
在这种情况下,普通算术运算不能保证溢出,并且溢出期间其结果被认为是未定义的(并且会为常量生成编译错误)。 恕我直言,这有点奇怪,但显然是出于与C语言语义兼容的一些深层考虑。
数组
数组文字如下所示:
const msg = []u8{ 'h', 'e', 'l', 'l', 'o' }; const arr = []i32{ 1, 2, 3, 4 };
字符串是字符数组,如C中所示。 带方括号的经典索引。 提供了数组的加法(连接)和乘法运算。 这是一件非常有趣的事情,如果可以通过串联将所有内容都清除了,那么可以进行乘法运算-我一直等到有人实现它之后,现在才等待:)在汇编器(!)中,有这样的dup操作,可让您生成重复的数据。 现在在Zig中:
const one = []i32{ 1, 2, 3, 4 }; const two = []i32{ 5, 6, 7, 8 }; const c = one ++ two; // { 1,2,3,4,5,6,7,8 } const pattern = "ab" ** 3; // "ababab"
指针
语法类似于C。
var x: i32 = 1234; // const x_ptr = &x; //
为了解除引用(通过指针获取值),使用了一个不寻常的后缀操作:
x_ptr.* == 5678; x_ptr.* += 1;
通过在类型名称前面设置星号来显式设置指针类型
const x_ptr : *i32 = &x;
切片(切片)
语言中内置的数据结构,使您可以引用数组或数组的一部分。 包含一个指向第一个元素和元素数量的指针。 看起来像这样:
var array = []i32{ 1, 2, 3, 4 }; const slice = array[0..array.len];
似乎不确定,它取自Go。 而且我也不确定是否值得将其嵌入一种语言中,而以任何OOP语言实现这种事情都是非常基本的。
结构体
声明结构的一种有趣方式:声明一个常量,其类型自动显示为“ type”(类型),并用作结构的名称。 并且结构本身(struct)是“无名的”。
const Point = struct { x: f32, y: f32, };
不可能在类似C的语言中以通常的方式指定名称,但是,编译器会根据某些规则显示类型名称-特别是在上述情况下,它将与“类型”常量的名称一致。
通常,该语言不能保证字段的顺序及其在内存中的对齐方式。 如果需要保证,则应使用“打包”结构。
const Point2 = packed struct { x: f32, y: f32, };
初始化-以Sishny指示符的样式:
const p = Point { .x = 0.12, .y = 0.34, };
结构可能有方法。 但是,将方法放置在结构中只是将结构用作名称空间。 与C ++不同,此参数没有隐式传递。
转账
通常,与C / C ++中的相同。 有一些访问元信息的便捷的内置方法,例如,字段的数目及其名称,是由语言中内置的语法宏实现的(在文档中称为内置函数)。
为了“与C的二进制兼容性”,提供了一些外部枚举。
为了说明枚举所依据的类型,使用以下形式
packed enum(u8)
其中u8是基本类型。
枚举可以具有类似于结构的方法(即,使用枚举名称作为名称空间)。
工会
据我了解,Zig中的并集是一个代数类型和,即 包含一个隐藏的标记字段,该字段确定哪个联合字段是“活动的”。 另一个字段的“激活”是通过重新分配整个关联来执行的。 说明文件范例
const assert = @import("std").debug.assert; const mem = @import("std").mem; const Payload = union { Int: i64, Float: f64, Bool: bool, }; test "simple union" { var payload = Payload {.Int = 1234}; // payload.Float = 12.34; // ! assert(payload.Int == 1234); // payload = Payload {.Float = 12.34}; assert(payload.Float == 12.34); }
联合还可以显式地为标签使用枚举。
// Unions can be given an enum tag type: const ComplexTypeTag = enum { Ok, NotOk }; const ComplexType = union(ComplexTypeTag) { Ok: u8, NotOk: void, };
联合,如枚举和结构,也可以为方法提供自己的名称空间。
可选类型
Zig具有内置的可选支持。 在类型名称之前添加一个问号:
const normal_int: i32 = 1234; // normal integer const optional_int: ?i32 = 5678; // optional integer
有趣的是,Zig实现了我怀疑的可能性的一件事,但不确定是否正确。 使指针与选项兼容,而无需添加额外的隐藏字段(“标记”),该隐藏字段存储值的有效性的标志; null用作无效值。 因此,在Zig中用指针表示的引用类型甚至不需要额外的内存来实现“可选性”。 同时,禁止将空值分配给常规指针。
错误类型
它们类似于可选类型,但是代替了布尔标记(“ really-invalid”),而是使用了与错误代码相对应的枚举元素。 语法类似于选项,添加了感叹号而不是问号。 因此,这些类型可以用于例如从函数返回:返回函数成功操作的对象结果,或者返回相应代码的错误。 错误类型是Zig语言错误处理系统的重要组成部分,有关更多详细信息,请参见“错误处理”部分。
输入无效
在Zig中可以使用诸如void之类的变量以及对其进行操作
var x: void = {}; var y: void = {}; x = y;
没有为此类操作生成代码; 这种类型主要用于元编程。
还有一个用于C兼容性的c_void类型。
控制运算符和功能
这些内容包括:阻止,切换,同时(如果)中断,继续。 要对代码进行分组,请使用标准大括号。 像C / C ++中一样,仅块用于限制变量的范围。 块可以视为表达式。 该语言没有goto,但是有一些标签可以与break和continue语句一起使用。 默认情况下,这些运算符使用循环;但是,如果块具有标签,则可以使用它。
var y: i32 = 123; const x = blk: { y += 1; break :blk y; // blk y };
switch语句与运算符的不同之处在于它没有“ fallthrough”,即 仅执行一个条件(条件),然后退出开关。 语法更紧凑:使用箭头“ =>”代替大小写。 开关也可以视为一个表达式。
while和if语句通常与所有类似C的语言相同。 for语句更像foreach。 所有这些都可以视为表达式。 在新功能中,while和for以及if可以有一个else块,如果没有循环迭代,则执行。
现在是时候讨论切换的一个常见功能了,而这是从foreach循环的概念中借来的-“捕获”变量。 看起来像这样:
while (eventuallyNullSequence()) |value| { sum1 += value; } if (opt_arg) |value| { assert(value == 0); } for (items[0..1]) |value| { sum += value; }
在这里,while参数是某个数据的“源”,对于数组或切片,它可以是可选的,并且位于两条垂直线之间的变量包含一个“扩展”值-即, 数组或切片的当前元素(或指向它的指针),可选类型的内部值(或指向它的指针)。
Defer和errdefer语句
从Go借来的延迟执行语句。 它的工作方式相同-在离开使用该运算符的范围时,将执行此运算符的参数。 此外,提供了errdefer运算符,如果从该函数返回了具有活动错误代码的错误类型,则会触发该操作符。 这是原始Zig错误处理系统的一部分。
接线员不可达
合同编程的元素。 一个特殊的关键字,放置在任何情况下都不应该进行管理的位置。 如果确实到达那里,则在Debug和ReleaseSafe模式下会生成恐慌,并且在ReleaseFast中,优化器会将这些分支完全抛出。
不归
从技术上讲,它是在表达式中与任何其他类型兼容的类型。 由于这种类型的对象永远不会返回,因此这是可能的。 由于运算符是Zig中的表达式,因此对于永远不会被求值的表达式,需要一种特殊的类型。 当表达式的右侧不可撤销地将控制权转移到外部某个地方时,就会发生这种情况。 要使此类语句中断,继续,返回,无法访问的无限循环和永不返回控制权的函数。 为了进行比较,对常规函数(返回控件)的调用不是noreturn运算符,因为尽管控制权已转移到外部,但迟早会返回到调用点。
因此,以下表达式变为可能:
fn foo(condition: bool, b: u32) void { const a = if (condition) b else return; @panic("do something with a"); }
变量a获取if / else语句返回的值。 为此,部件(如果不是,则均为其他)必须返回相同类型的表达式。 如果if部分返回布尔值,则else部分为noreturn类型,从技术上讲它与任何类型都兼容,因此,代码可以正确编译。
功能介绍
此类型的语言的语法是经典的:
fn add(a: i8, b: i8) i8 { return a + b; }
通常,这些功能看起来很标准。 到目前为止,我还没有注意到一流函数的迹象,但是我对这种语言的了解很肤浅,我可能是错的。 尽管也许这还没有完成。
另一个有趣的功能是,在Zig中,您只能使用_下划线明确地忽略返回的值
_ = foo();
有一个反映,您可以获取有关该功能的各种信息
const assert = @import("std").debug.assert; test "fn reflection" { assert(@typeOf(assert).ReturnType == void); // assert(@typeOf(assert).is_var_args == false); // }
编译时执行代码
Zig提供了强大的功能-在编译时执行以Zig编写的代码。 为了使代码在编译时执行,只需使用comptime关键字将其包装在一个块中即可。 可以在编译时和运行时调用同一函数,从而使您可以编写通用代码。 当然,与代码的不同上下文相关联的一些限制。 例如,在许多示例的文档中,comptime用于检查编译时间:
// array literal const message = []u8{ 'h', 'e', 'l', 'l', 'o' }; // get the size of an array comptime { assert(message.len == 5); }
但是,当然,此操作员的功能远未在此处完全公开。 因此,在语言的描述中,给出了有效使用语法宏的经典示例-实现类似于printf的函数,但是在编译阶段解析格式字符串并进行所有必要的参数类型检查。
另外,单词comptime用于表示编译时函数的参数,类似于C ++模板函数。
fn max(comptime T: type, a: T, b: T) T { return if (a > b) a else b; }
错误处理
Zig发明了与其他语言不同的原始错误处理系统。 这可以称为“显式异常”(用这种语言,显性通常是惯用法之一)。 它看起来也像Go返回代码,但是工作方式不同。
Zig错误处理系统基于用于实现自定义错误代码(错误)的特殊枚举,并基于它们的“错误类型”(代数类型和,结合返回的函数类型和错误代码)构建。
错误枚举的声明方式与常规枚举相同:
const FileOpenError = error { AccessDenied, OutOfMemory, FileNotFound, }; const AllocationError = error { OutOfMemory, };
但是,所有错误代码接收的值都大于零。 同样,如果在两个枚举中声明具有相同名称的代码,则它将收到相同的值。 但是,禁止在错误的不同枚举之间进行隐式转换。
关键字anyerror表示包含所有错误代码的枚举。
与可选类型一样,该语言支持使用特殊语法生成错误类型。 Type!U64是anyerror!U64的缩写形式,反过来意味着一个并集(选项),其中包括u64类型和anyerror类型(据我所知,代码0保留以指示没有错误和数据字段的有效性,其余代码为实际上是错误代码)。
catch关键字使您可以捕获错误并将其转换为默认值:
const number = parseU64(str, 10) catch 13;
因此,如果parseU64函数返回U64类型时发生错误,则catch将对其进行“拦截”并返回默认值13。
try关键字允许您将错误“转发”到较高级别(即,调用函数的级别)。 查看代码
fn doAThing(str: []u8) !void { const number = try parseU64(str, 10); // ... }
等效于此:
fn doAThing(str: []u8) !void { const number = parseU64(str, 10) catch |err| return err; // ... }
发生以下情况:调用parseU64(如果从中返回错误)-它被catch语句拦截,在catch语句中,使用“捕获”语法提取错误代码,该语法位于err变量中,该变量通过!Void返回给调用函数。
前面描述的Errdefer运算符也指错误处理。 仅当函数返回错误时,才会执行Errdefer参数代码。
更多可能性。 使用|| 您可以合并错误集
const A = error{ NotDir, PathNotFound, }; const B = error{ OutOfMemory, PathNotFound, }; const C = A || B;
Zig还提供诸如错误跟踪之类的功能。 这类似于堆栈跟踪,但是包含有关发生了什么错误以及错误如何沿着try链从发生的地方传播到程序的主要功能的详细信息。
因此,Zig中的错误处理系统是一个非常原始的解决方案,它看起来不像C ++中的异常或Go中的返回代码。我们可以说这样的解决方案有一定的价格-额外的4个字节,必须与每个返回值一起返回;明显的优势是绝对可见性和透明性。与C ++不同,此处的函数无法从调用链深度的某个位置引发未知异常。该函数返回的所有内容-它显式且仅显式返回。协程
Zig具有内置的协程。这些是使用async关键字创建的函数,借助这些函数可以传输分配器和deallocator的函数(据我所知,它用于附加堆栈)。 test "create a coroutine and cancel it" { const p = try async<std.debug.global_allocator> simpleAsyncFn(); comptime assert(@typeOf(p) == promise->void); cancel p; assert(x == 2); } async<*std.mem.Allocator> fn simpleAsyncFn() void { x += 1; }
async返回类型为promise-> T的特殊对象(其中T是函数的返回类型)。使用此对象,您可以控制协程。最低级别包括关键字suspend,resume和cancel。使用暂停,协程执行被暂停并传递给调用程序。可以使用suspend块的语法,该块内部的所有内容都将执行,直到协程实际被暂停为止。resume接受类型为promise-> T的参数,并从挂起的位置继续执行协程。取消释放协程存储器。此图显示了主程序(以测试的形式)和协程之间的控制转移。一切都非常简单: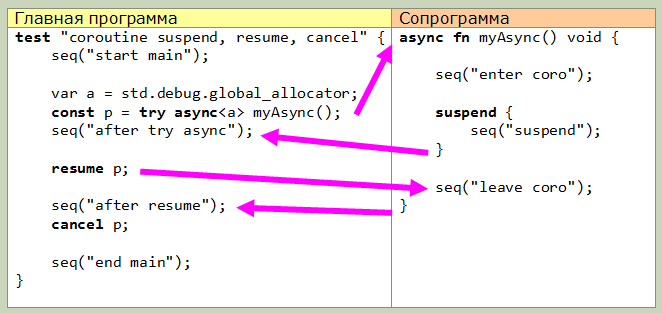 第二个(更高级别)功能是使用等待。坦白地说,这是我唯一不理解的(ala,文档仍然很匮乏)。这是文档中经过稍微修改的示例的实际控件传输图,也许这会向您解释一些内容:
第二个(更高级别)功能是使用等待。坦白地说,这是我唯一不理解的(ala,文档仍然很匮乏)。这是文档中经过稍微修改的示例的实际控件传输图,也许这会向您解释一些内容: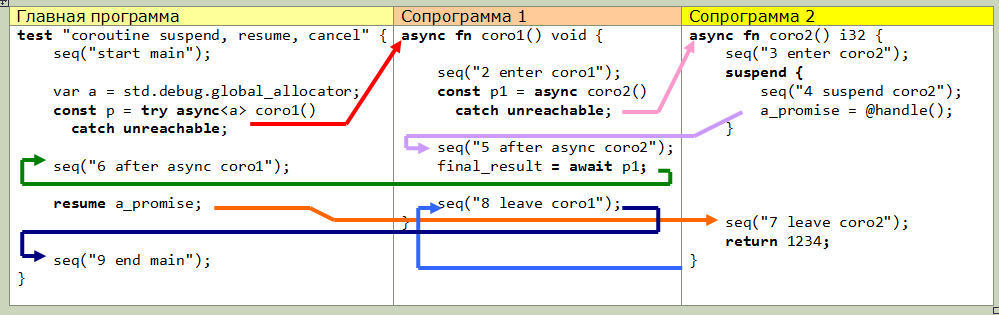
内建功能
内置函数-语言中内置的相当大的一组函数,不需要连接任何模块。也许将其中一些称为“内置语法宏”更为正确,因为许多功能远远超出了功能。内置的提供了对反射工具(sizeOf,tagName,TagType,typeInfo,typeName,typeOf)的访问,并连接了它们的帮助模块(导入)。其他的则更像是经典的内置C / C ++-它们实现低级类型转换,各种操作,例如sqrt,popCount,slhExact等。内置功能列表很可能会随着语言的发展而改变。总结
这样的项目的出现和发展是非常令人愉快的。尽管C语言对于许多人来说是方便,简洁和熟悉的,但是它仍然过时,并且由于体系结构的原因不能支持许多现代编程概念。C ++正在开发中,但在客观上进行了重新设计,每个新版本都变得越来越困难,并且出于相同的体系结构原因以及由于需要向后兼容,对此无能为力。Rust很有趣,但是进入门槛很高,并不总是合理的。D是一个很好的尝试,但是有很多小缺陷,似乎最初是在Java的影响下创建该语言的可能性更高,而后来的功能却以某种方式引入了它们,而不是应有的方式。显然,Zig是另一种尝试。语言很有趣,而且有趣的是看到它的结果。