TL; DR: GitHub:// PastorGL / AQLSelectEx 。
一次,不是在寒冷的季节,而是在冬季,特别是在几个月前,对于我正在从事的项目(基于大数据的地理空间),我需要快速的NoSQL /键值存储。
我们在Apache Spark的帮助下咀嚼了数TB的源代码,但是最终的计算结果却折叠到了可笑的数量(只有数百万条记录),需要存储在某个地方。 并且非常希望以这样一种方式进行存储:可以使用与结果的每一行关联的元数据(这是一位数字)快速找到并发送该数据(但是其中有很多)。
从这个意义上讲,Khadupov堆栈的格式用处不大,数百万条记录上的关系数据库的速度变慢,并且元数据集的固定程度不足以适应常规RDBMS的严格方案-在我们的例子中是PostgreSQL。 不,它通常支持JSON,但是在数百万条记录的索引上仍然存在问题。 索引膨胀,有必要对表进行分区,并且这样的管理麻烦开始了nafig-nafig。
从历史上看,MongoDB在项目上被用作NoSQL,但是随着时间的流逝,monga变得越来越糟(特别是在稳定性方面),因此它逐渐停用。 快速寻找更现代,更快,更少越野车以及通常更好的替代品的原因是Aerospike 。 许多大个子家伙都赞成,我决定检查一下。
测试表明,事实上,数据是直接从Spark作业中哨出来存储在故事中的,并且在数百万条记录中的搜索比在mong中更快。 而且她吃的记忆更少。 但是结果却是一个“但是”。 航空焊料的客户API纯粹是功能性的,而不是声明性的。
对于故事中的记录而言,这并不重要,因为每条结果记录的所有字段都必须在工作本身中本地确定,并且上下文不会丢失。 这里使用了功能样式,尤其是因为用其他方式编写代码将无法工作。 但是,在应该将结果上传到外界并且是普通的Spring Web应用程序的网络枪口中,从用户表单中形成标准的SQL SELECT逻辑将更加合乎逻辑,在该表单中将充满AND和OR-即谓词 ,-在WHERE子句中。
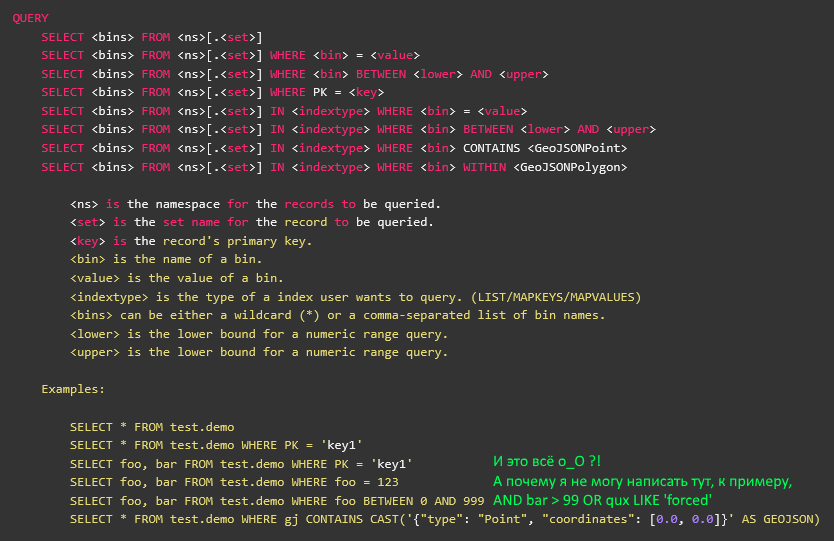
我将用这样一个综合示例来解释差异:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
-既可读又相对清晰的客户想要接收的记录。 如果直接将这样的请求直接发送到日志中,则可以稍后将其拉出以进行手动调试。 解析各种奇怪的情况时,这非常方便。
现在,让我们以一种功能风格看一下对谓词API的调用:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
这是代码的墙,甚至是波兰语的反符号 。 不,我了解从引擎本身的程序员的角度来看,堆栈计算机实现起来既简单又方便,但是可以通过客户端应用程序在RPN中困惑和编写谓词……我个人不想考虑供应商,我希望我作为该API的使用者很方便。 甚至带有供应商客户端扩展(概念上类似于Java Persistence Criteria API)的谓词编写起来也不方便。 而且查询日志中仍然没有可读的SELECT。
通常,SQL的发明是为了以一种接近自然的鸟类语言在其中编写基于条件的查询。 所以,一个奇迹,到底是什么?
等等,有些不对劲……在KDPV上,有没有从雾化官方文档中截取的屏幕截图,上面完整地描述了SELECT?
是的,描述过。 那只是AQL-这是第三方的实用程序,它是在漆黑的夜晚由左后脚编写的,并在三年前的上一版本的气雾焊机中被供应商放弃。 尽管它是在蟾蜍上编写的 ,但它与客户端库无关。
三年前的版本没有谓词API,因此在AQL中不支持谓词,而WHERE之后的所有内容实际上都是对索引(二级或主级)的调用。 好吧,那就是更接近USE或WITH之类的SQL扩展。 也就是说,您不仅可以获取AQL源,将它们分解为备件,然后在您的应用程序中将它们用于谓词调用。
另外,正如我所说,它是在漆黑的夜晚用左后脚书写的,不可能看到ANTLR4 语法 ,AQL可以毫无疑问地解析出该查询。 好吧,以我的口味。 由于某种原因,当语法的声明性定义没有与蟾蜍代码片段混合在一起并且在其中酿造非常凉爽的面条时,我喜欢它。
好吧,幸运的是,我似乎也知道如何做ANTLR。 没错,很长一段时间我没有拿起检查器,而上次我是在第三个版本下编写它的。 第四-更好,因为谁想要编写手动AST游览,如果所有内容都写在我们面前,并且有正常的访问者,那么我们开始吧。
我们以SQLite语法为基础,并尝试丢弃所有不必要的内容。 我们只需要SELECT,仅此而已。
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
嗯...对于SELECT来说太多了。 而且,如果很容易消除多余的部分,那么就所产生的变通办法的结构而言,还有另外一件不好的事情。
最终目标是使用RPN和隐式堆栈机将其转换为谓词API。 在这里,atomic expr不会以任何方式促成这种转换,因为它暗示了从左到右的正常分析。 是的,并递归定义。
也就是说,我们可以得到综合示例,但是它将完全按照所编写的示例从左到右读取:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
有一些括号确定解析的优先级(这意味着您需要在堆栈上来回晃动),并且某些运算符的行为类似于函数调用。
我们需要以下顺序:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
硼,锡,大脑阅读不良。 但是,如果没有括号,就不会有回叫和对电话顺序的误解。 我们如何将一个翻译成另一个呢?
然后,在大脑不好的情况下,就会发生胆怯! -您好,这是来自许多人的经典调车场 。 教授 迪克斯特拉! 通常,像我这样的okolobigdatovskih萨满巫师不需要算法,因为我们只是将数据撒旦主义者已经编写的原型从python转移到蟾蜍,然后获得通过纯工程(==萨满教义)方法而不是科学方法获得的解决方案的冗长乏味的性能。 。
但是随后突然变得有必要了解该算法。 或者至少是一个想法。 幸运的是,在过去的几年中,并没有忘记整个大学的课程,而且由于我还记得有关堆叠式机器的知识,所以我还可以发掘有关算法的其他信息。
好吧 在Shunting Yard强化的语法中,顶层的SELECT看起来像这样:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
也就是说,与括号相对应的标记是有效的,并且不应存在递归expr。 相反,将有一堆所有private_expr,并且都是有限的。
在蟾蜍上的代码(实现此树的访客)中,事情有点让人上瘾-严格按照算法进行计算,算法本身会处理悬挂的逻辑操作并平衡括号。 我不会摘录(您自己看一下GC ),但是我会考虑以下事项。
显而易见的是,为什么航空尖峰的作者不理会AQL中的谓词支持,而是在三年前放弃了它。 因为它是严格键入的,并且航空尖峰本身以无模式的故事形式呈现。 因此,如果没有预定的方案,就不可能从裸SQL中提取查询。 哎呀
但是,我们都很焦躁,最重要的是,傲慢自大。 我们需要一个具有字段类型的方案,因此将有一个具有字段类型的方案。 而且,客户端库已经具有所有必需的定义,只需要选择它们即可。 尽管我必须为每种类型编写很多代码(请参见第56行的同一链接)。
现在初始化...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
...和瞧,现在我们的综合查询简单明了地从气雾剂中抽搐:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
为了将表单从Web枪口转换为请求本身,我们抓取了很久以前在Web枪口中编写的大量代码...当它最终到达项目时,否则客户现在将其放在架子上。 真可惜,我花了近一个星期的时间。
我希望我能从中受益,并且AQLSelectEx库将对某人有用,并且该方法本身将比该中心处理ANTLR的其他文章更实际。