这是我的
Kubernetes企业帖子系列的第二部分。 正如我在上一篇文章中提到的那样,当转移到
“设计和实施指南”时,每个人对Kubernetes(K8s)的理解水平都非常重要。
我不想在这里使用传统方法来解释Kubernetes的体系结构和技术,但是我将通过与您作为VMware用户熟悉的vSphere平台进行比较来解释所有内容。 这将使您克服对Kubernetes的明显困惑和严重性。 我在VMware内部使用了这种方法,将Kubernetes引入了不同的听众群体,并且证明了它很好用,并且可以帮助人们更快地习惯关键概念。
开始之前的重要说明。 我不使用此比较来证明vSphere和Kubernetes之间的任何相似之处或不同之处。 从本质上讲,这两者和另一个都是分布式系统,因此应该与任何其他相似系统具有相似之处。 因此,最后,我尝试将Kubernetes这样的出色技术引入其广泛的用户社区。

一点历史
阅读这篇文章涉及了解容器。 我不会描述容器的基本概念,因为有很多资源在讨论这一点。 我经常与客户交流,我发现他们无法理解为什么容器抢占了我们的行业并在创纪录的时间内变得非常流行。 为了回答这个问题,我将谈谈我的实践经验,以了解我们行业中正在发生的变化。
在探索电信世界之前,我是一名Web开发人员(2003年)。
这是我担任网络工程师/管理员之后的第二份有薪工作(我知道我是所有行业的杰克)。 我用PHP开发。 我开发了各种应用程序,从雇主使用的小型应用程序开始,到电视节目的专业投票应用程序,甚至是与VSAT集线器和卫星系统交互的电信应用程序,都得到了开发。 生活是美好的,除了每个开发人员都知道的一个主要障碍,那就是上瘾。
最初,我使用LAMP堆栈之类的东西在笔记本电脑上开发该应用程序,当它在笔记本电脑上运行良好时,我将源代码下载到主机服务器(每个人还记得RackShack吗?)或客户的私有服务器。 您可以想象,一旦我这样做,该应用程序就会崩溃,并且无法在这些服务器上运行。 原因是成瘾。 这些服务器具有其他版本的软件(Apache,PHP,MySQL等),而不是我在笔记本电脑上使用的版本。 因此,我需要找到一种方法来更新远程服务器上的软件版本(坏主意)或重写笔记本电脑上的代码以匹配远程服务器上的版本(最坏主意)。 那是一场噩梦,有时我讨厌自己,想知道为什么这就是我的谋生方式。
10年过去了,Docker公司出现了。 作为Professional Services(2013年)的VMware顾问,我听说过Docker,并说我当时无法理解这项技术。 我继续说类似的东西:如果有虚拟机,为什么要使用容器。 为什么由于即时容器启动或消除虚拟机管理程序开销之类的怪异优势而放弃诸如vSphere HA,DRS或vMotion之类的重要技术。 毕竟,每个人都可以使用虚拟机并完美地工作。 简而言之,我从基础设施的角度对其进行了研究。
但是后来我开始仔细看,它突然出现在我身上。 与Docker有关的一切都与开发人员有关。 刚开始以开发人员的身份思考时,我立即意识到,如果我在2003年拥有这项技术,我可以打包所有依赖项。 无论使用什么服务器,我的Web应用程序都可以工作。 而且,没有必要下载源代码或进行配置。 您可以简单地将我的应用程序“打包”到一个映像中,并要求客户下载并运行该映像。 这是任何Web开发人员的梦想!
这一切都很棒。 Docker解决了巨大的交互和打包问题,但是下一步呢? 作为企业客户,我可以在扩展时管理这些应用程序吗? 我仍然想使用HA,DRS,vMotion和DR。 Docker解决了我的开发人员的问题,并为我的管理员(DevOps团队)带来了很多问题。 他们需要一个用于启动容器的平台,与用于启动虚拟机的平台相同。 然后我们又回到了开始。
但是随后Google出现了,它通过一个叫做Kubernetes的平台向全世界讲述了容器的使用多年(实际上,容器是Google发明的cgroups)以及正确的使用方法。 然后他们打开了Kubernetes的源代码。 呈现给Kubernetes社区。 那又改变了一切。
了解Kubernetes与vSphere
那么什么是Kubernetes? 简而言之,用于容器的Kubernetes与用于现代数据中心的虚拟机vSphere相同。 如果您在2000年代初使用VMware Workstation,您就会知道此解决方案已被认真考虑为数据中心解决方案。 当带有vCenter和ESXi主机的VI / vSphere出现时,虚拟机的世界发生了巨大变化。 Kubernetes在当今的容器世界中正在做同样的事情,使在生产中启动和管理容器的能力成为可能。 这就是为什么我们将开始将vSphere与Kubernetes进行比较,以解释此分布式系统的详细信息以了解其功能和技术的原因。

系统概述
与在vSphere中一样,在Kubernetes概念中也有vCenter和ESXi主机,也有主机和节点主机。 在这种情况下,K8s中的Master等效于vCenter,从某种意义上说,它是分布式系统的管理平面。 它也是管理工作负载时与之交互的API的入口点。 K8s节点以相同的方式用作计算资源,类似于ESXi主机。 在它们上运行负载(对于K8,我们称它们为Pod)。 节点可以是虚拟机或物理服务器。 当然,对于vSphere ESXi,主机必须始终为物理主机。

您会看到K8s有一个名为“ etcd”的键值存储。 此存储类似于vCenter数据库,在该数据库中保存要遵循的所需群集配置。
至于区别:在Master K8上,您还可以运行工作负载,但在vCenter上则不能。 vCenter是仅用于管理的虚拟设备。 对于K8,Master被视为一种计算资源,但是在其上运行Enterprise应用程序不是一个好主意。
那么它在现实中会是什么样子? 您将主要使用CLI与Kubernetes进行交互(但是GUI仍然是一个非常可行的选择)。 下面的屏幕截图显示,我正在使用Windows计算机通过命令行连接到我的Kubernetes集群(如果您有兴趣,请使用cmder)。 在屏幕截图中,我有一个主节点和4个节点。 它们在K8s v1.6.5的控制下工作,并且在节点上安装了操作系统(OS)Ubuntu 16.04。 在撰写本文时,我们主要生活在Linux世界中,其中Master和Node始终在运行Linux发行版。
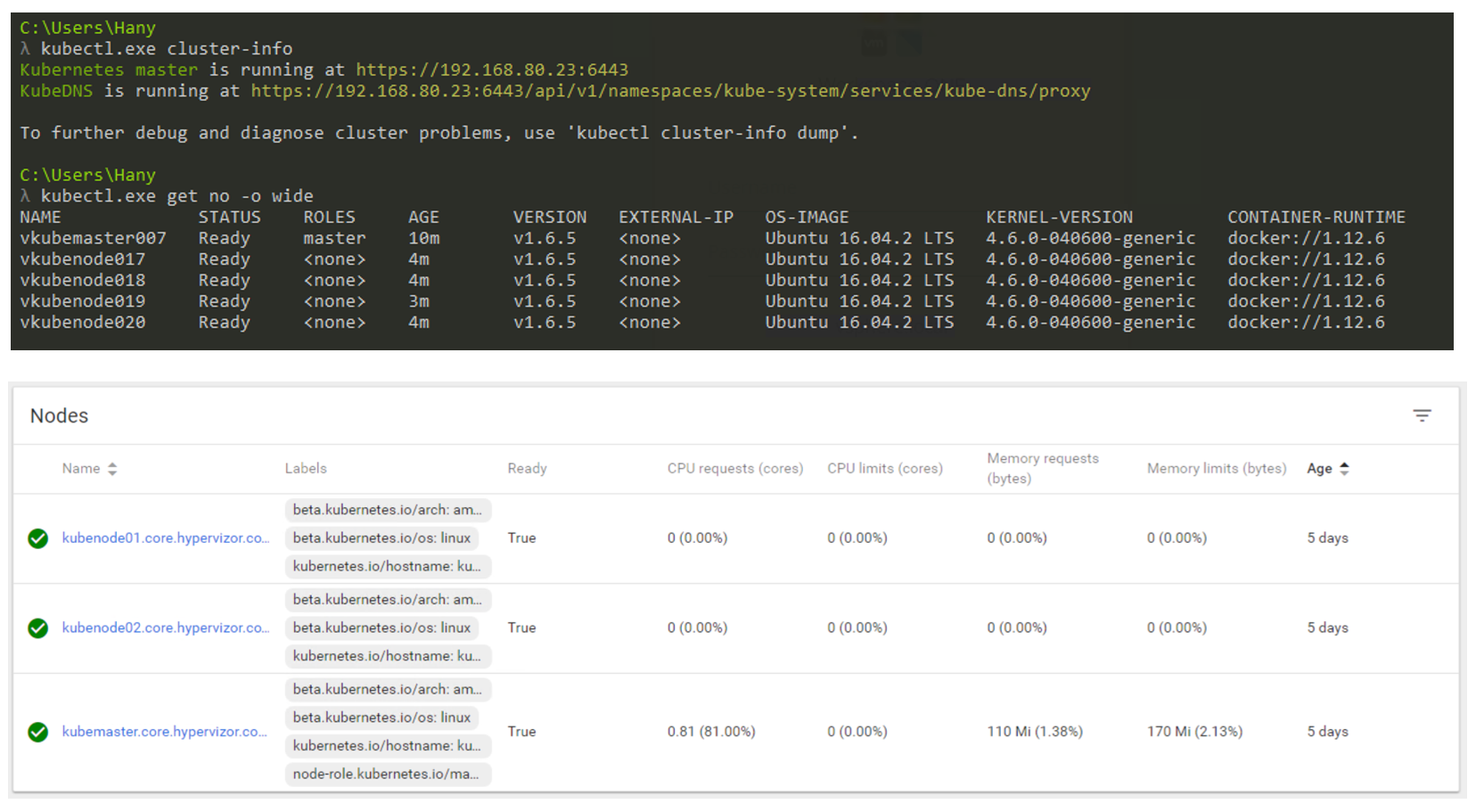 通过CLI和GUI进行K8s集群管理。
通过CLI和GUI进行K8s集群管理。工作量尺寸
在vSphere中,虚拟机是操作系统的逻辑边界。 在Kubernetes中,Pods是容器边界,就像ESXi主机一样,它可以同时运行多个虚拟机。 每个节点可以运行多个Pod。 每个Pod都会收到一个可路由的IP地址(例如虚拟机),以便Pod相互通信。
在vSphere中,应用程序在OS内运行,而在Kubernetes中,应用程序在容器内运行。 一台虚拟机一次只能使用一个OS,而Pod可以运行多个容器。
通过这种方式,您可以通过CLI使用kubectl工具在K8s集群中列出Pod,检查Pod的工作能力,使用年限,IP地址和当前正在使用的节点。

管理学
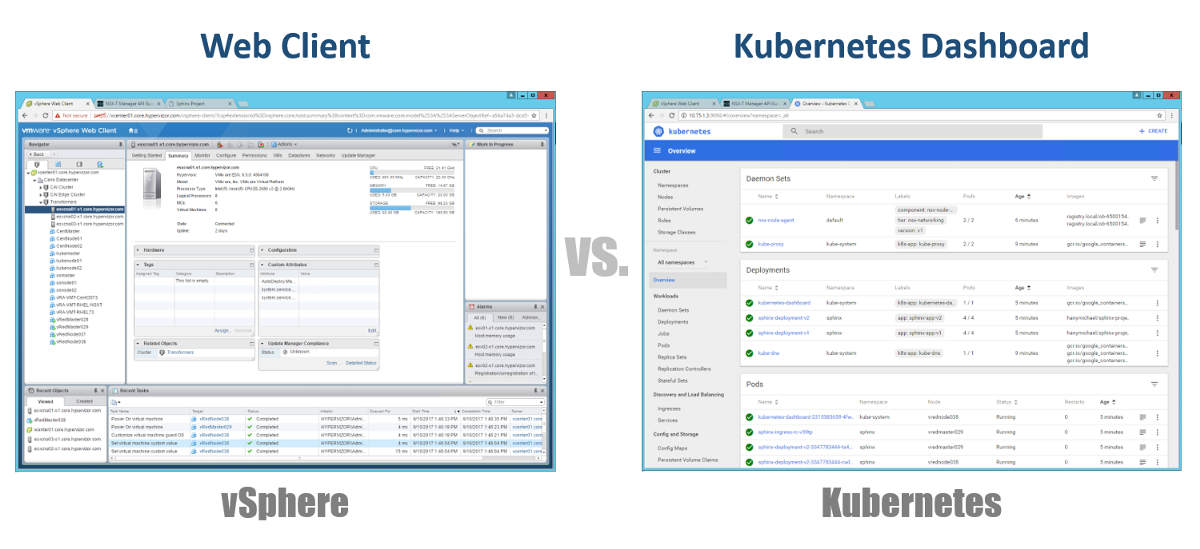
那么,我们如何管理主机,节点和吊舱? 在vSphere中,我们使用Web客户端来管理虚拟基础架构的大多数(如果不是全部)组件。 对于Kubernetes,类似地,使用仪表板。 这是一个基于GUI的良好Web门户,您可以通过浏览器以与vSphere Web Client相同的方式进行访问。 从前面的部分中,您可以看到可以使用CLI中的kubeclt命令来管理K8s集群。 在您将大部分时间花在CLI或图形仪表板上的地方,始终存在争议。 由于后者每天都变得越来越强大(您可以肯定地观看此视频)。 就我个人而言,我认为仪表板对于快速监视状态或显示各种K8s组件的详细信息非常方便,而无需在CLI中输入长命令。 您会自然地找到它们之间的平衡。
构型
Kubernetes中非常重要的概念之一是所需的配置状态。 您可以通过YAML文件声明几乎所有Kubernetes组件所需的内容,然后使用kubectl(或通过图形仪表板)创建所有所需的状态。 从现在开始,Kubernetes将始终努力使您的周围环境处于给定的运行状态。 例如,如果您希望有一个Pod的4个副本,则K8将继续监视这些Pod,并且如果其中一个Pod失效或工作的Node出现问题,K8将自动恢复并自动创建此Pod。其他地方的豆荚。
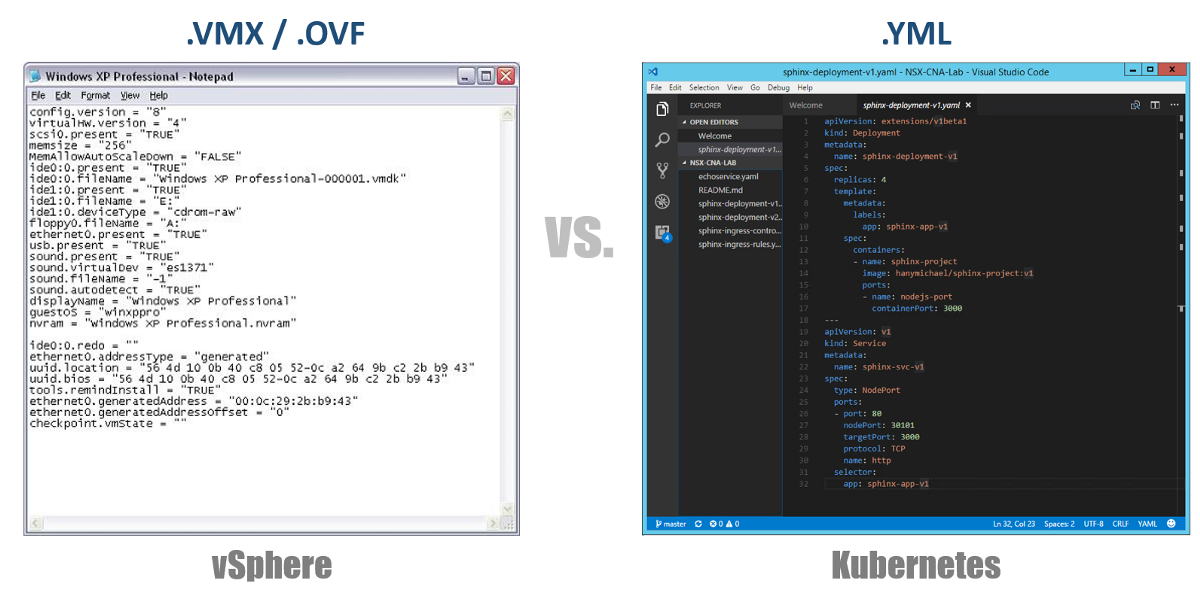
返回到我们的YAML配置文件,您可以将它们视为要部署到vSphere的虚拟机的.VMX文件或虚拟设备的.OVF描述符。 这些文件定义了要运行的工作负载/组件的配置。 与虚拟VM /设备专有的VMX / OVF文件不同,YAML配置文件用于定义任何K8s组件,例如副本集,服务,部署等。 在以下各节中考虑这一点。
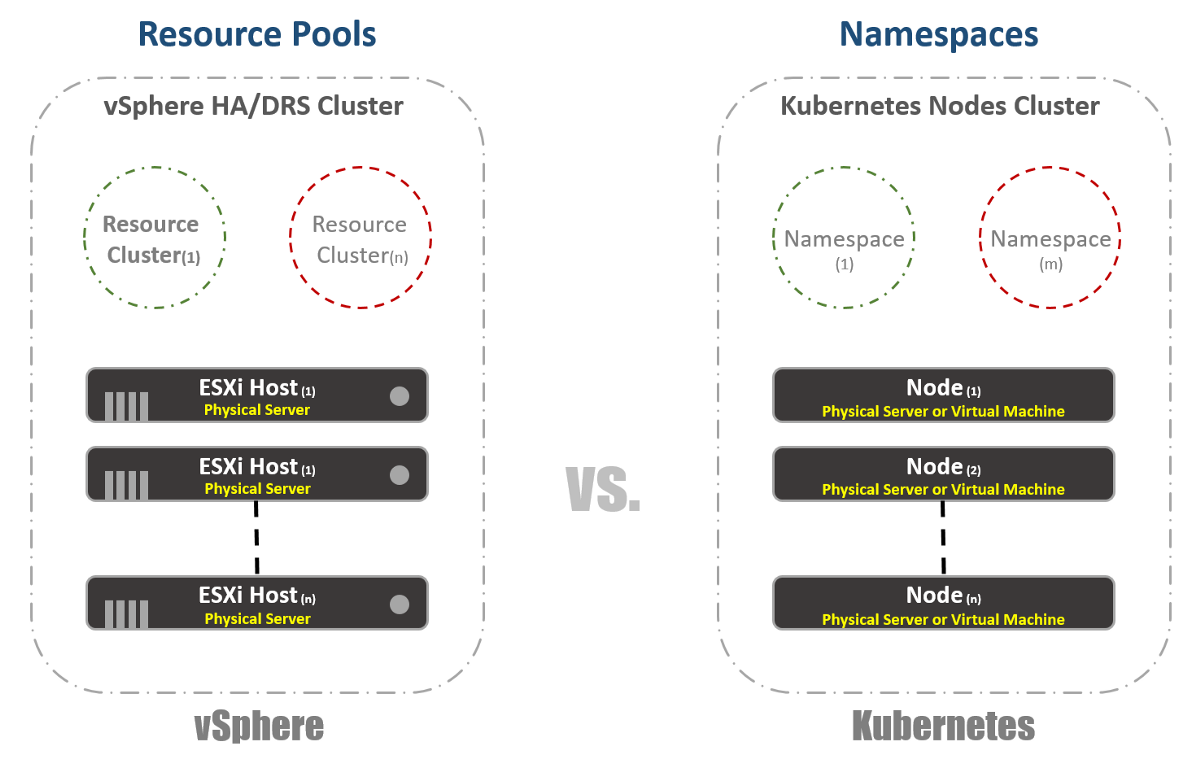
虚拟集群
在vSphere中,我们将物理ESXi主机逻辑上分组到群集中。 这些群集可以分为称为“资源池”的其他虚拟群集。 这些“池”主要用于限制资源。 在Kubernetes,我们有非常相似的东西。 我们称它们为“命名空间”,它们也可以用于提供资源限制,这将在下一部分中反映出来。 但是,大多数情况下,“名称空间”用作应用程序(或用户,如果您使用常见的K8s群集)的多租户工具。 这也是可以使用NSX-T执行网络分段的选项之一。 在以下出版物中考虑这一点。
资源管理
正如我在上一节中提到的那样,Kubernetes中的命名空间通常用作分段的手段。 命名空间的另一种用法是资源分配。 此选项称为“资源配额”。 如前几节所述,此定义发生在配置YAML文件中,在该文件中声明了所需的状态。 如下面的屏幕快照所示,在vSphere中,我们根据资源池设置来确定。

工作量识别
这非常简单,对于vSphere和Kubernetes几乎相同。 在第一种情况下,我们使用标签的概念来定义(或分组)相似的工作负载,在第二种情况下,我们使用术语“标签”。 对于Kubernetes,必须进行工作负载识别。

订座
现在为真正的乐趣。 如果像我一样曾经或曾经是vSphere FT的忠实拥护者,尽管这两种技术有所不同,您还是会喜欢Kubernetes中的此功能。 在vSphere中,它是一台虚拟机,具有在其他主机上运行的运行中的影子实例。 我们在主虚拟机上记录指令,然后在影子虚拟机上重播它们。 如果主机停止工作,则影子虚拟机将立即打开。 然后,vSphere尝试查找另一台ESXi主机以创建虚拟机的新影子实例以维护相同的冗余。 在Kubernetes,我们有非常相似的东西。 ReplicaSets是您指定用于运行Pod的多个实例的数量。 如果一个Pod发生故障,则其他实例可用于服务流量。 同时,K8会尝试在任何可用节点上启动新的Pod,以维持所需的配置状态。 您可能已经注意到,主要区别在于,对于K8,Pods始终可以工作并为流量服务。 它们不是影子工作负载。

负载均衡
尽管这可能不是vSphere中的内置功能,但在平台上运行负载平衡器非常非常有必要。 在vSphere世界中,存在虚拟或物理负载平衡器,用于在多个虚拟机之间分配网络流量。 可能有许多不同的配置模式,但让我们假设我们的意思是单臂配置。 在这种情况下,您可以平衡虚拟机上东西向流量的负载。
同样,Kubernetes具有“服务”的概念。 K8中的服务也可以在不同的配置模式下使用。 让我们选择“ ClusterIP”配置,将其与单臂负载均衡器进行比较。 在这种情况下,K8中的服务将具有一个虚拟IP地址(VIP),该地址始终是静态的并且不会更改。 该VIP将在多个Pod之间分配流量。 这在Kubernetes世界中尤为重要,因为Pod本质上是短暂的,当Pod死亡或被删除时,您会丢失其IP地址。 因此,您应始终提供静态VIP。
正如我已经提到的,服务具有许多其他配置,例如“ NodePort”,您可以在其中在节点级别分配端口,然后为Pod执行端口地址翻译转换。 还有一个“ LoadBalancer”,您可以在其中运行来自第三方或云提供商的Load Balancer实例。

Kuberentes还有另一个非常重要的负载平衡机制,称为“入口控制器”。 您可以将其视为嵌入式应用程序负载平衡器。 主要思想是,将使用从外部可见的IP地址启动Ingress Controller(以Pod形式)。 该IP地址可能具有类似通配符DNS记录的内容。 当流量使用外部IP地址到达Ingress Controller时,它将检查标头并使用您先前设置的该名称所属的Pod规则集确定。 例如:sphinx-v1.esxcloud.net将定向到服务sphinx-svc-1,sphinx-v2.esxcloud.net将定向到Service sphinx-svc2,依此类推。

存储与网络
对于Kubernetes,存储和网络是非常广泛的主题。 在介绍性帖子中简短地谈论这两个主题几乎是不可能的,但是我将很快详细讨论每个主题的不同概念和选项。 同时,让我们快速看一下网络堆栈在Kubernetes中是如何工作的,因为在下一节中将需要它。
Kubernetes具有各种网络“插件”,可用于配置节点和Pod的网络。 一种常见的插件是“ kubenet”,它目前在GCP和AWS等巨型云中使用。 在这里,我将简要介绍GCP的实现,然后展示一个在GKE中实现的实际示例。

乍一看,这似乎太复杂了,但我希望您能在本文结尾处理解所有这些内容。 首先,我们看到有两个Kubernetes节点:节点1和节点(m)。 像任何Linux机器一样,每个节点都有一个eth0接口。 在我们的示例中,此接口在10.140.0.0/24子网中具有用于外部世界的IP地址。 上游L3设备充当路由我们的流量的默认网关。 可以是数据中心中的L3交换机,也可以是云中的VPC路由器,例如GCP,我们将在后面看到。 一切都好吗?
进一步,我们看到节点内部有Bridge接口cbr0。 对于节点1,此接口是IP子网10.40.1.0/24的默认网关。该子网由Kubernetes分配给每个节点。 节点通常有一个/ 24子网,但是您可以使用NSX-T进行更改(我们将在以下文章中介绍)。 目前,该子网是我们将为Pod分配IP地址的子网。 这样,节点1内的任何Pod都会从该子网获取IP地址。 在我们的情况下,Pod 1的IP地址为10.40.1.10。 但是,您注意到此Pod中有两个嵌套容器。 我们已经说过,可以在一个Pod中启动一个或几个容器,它们在功能上紧密相关。 这就是我们在图中看到的。 容器1侦听端口80,容器2侦听端口90。两个容器都具有相同的IP地址10.40.1.10,但是它们不拥有网络命名空间。 好的,那么谁拥有这个网络堆栈? 实际上,有一个特殊的容器称为“暂停容器”。 该图显示他的IP地址是Pod的IP地址,用于与外界通信。 因此,暂停容器拥有此网络堆栈,包括IP地址10.40.1.10本身,并且当然将流量重定向到容器1到端口80,并将流量重定向到容器2到端口90。
现在,您必须询问如何将流量重定向到外部世界? 我们启用了标准Linux IP转发,以将流量从cbr0转发到eth0。 很好,但是尚不清楚L3设备如何学习如何将流量转发到目的地? 在此特定示例中,我们没有针对该网络的公告的动态路由。 因此,我们必须在L3设备上具有某种静态路由。 为了到达10.40.1.0/24子网,您需要将流量转发到节点1 IP地址(10.140.0.11)并到达10.40.2.0/24子网,下一个希望是IP地址为10.140.0.12的节点(m)。
所有这些都很棒,但这是管理网络的一种不切实际的方法。 在扩展群集时支持所有这些路由对于网络管理员来说绝对是一场噩梦。 因此,需要一些解决方案来管理网络连接,例如Kuberentes中的CNI(容器网络接口)。 NSX-T是此类解决方案之一,具有用于网络交互和安全性的非常广泛的功能。
记住,我们只看了kubenet插件,而不是CNI。 kubenet插件是Google容器引擎(GKE)所使用的插件,它们的使用方式非常有趣,因为它是完全由软件定义并在其云中自动执行的。 , GCP. .
接下来是什么?
Kuberentes. ,
.
第二部分。. .
.