
 Redmadrobot数据科学开发人员Anton Chaynikov
Redmadrobot数据科学开发人员Anton Chaynikov
哈Ha! 今天,我将讨论在聊天机器人途中遇到的困难,这为保险公司的聊天操作员的工作提供了便利。 更准确地说,我们是如何教机器人通过机器学习来区分请求的。 实验了哪些模型,哪些模型得到了结果。 如何清理和丰富体面质量数据的四种方法,以及清理质量“不体面”数据的五种方法。
挑战赛
保险公司的聊天每天会收到+100500个客户电话。 大多数问题都是简单而重复的,但操作员却并非易事,客户仍需等待五至十分钟。 如何提高服务质量并优化人工成本,从而使操作员的日常工作更少,而用户却能从快速解决问题中获得更多愉悦感?
我们将创建一个聊天机器人。 让他阅读用户消息,为简单案例提供指导,并为复杂案例提出标准问题,以获取操作员所需的信息。 现场操作员有一个脚本树-一个脚本(或流程图),它说明用户可能会问什么问题以及如何对它们做出响应。 我们会采用这种方案并将其放在聊天机器人中,但这很不好-聊天机器人不了解人类,也不知道如何将用户的问题与脚本分支联系起来。
因此,我们将在良好的旧机器学习的帮助下教他。 但是,您不能仅仅获取用户生成的数据并教给他一个不错的质量模型。 为此,您需要试验模型的架构,数据-进行清理,有时还会再次收集。
如何教机器人:
- 考虑模型选项:如何将数据集的大小,文本向量化的细节,尺寸的减小,分类器和最终精度结合在一起。
- 让我们清理体面的数据:我们将找到可以安全丢弃的类。 我们将找出为什么最近六个月的加价幅度比之前三个月要好; 确定模型的位置以及标记的位置; 了解错别字如何有用。
- 我们将清理“不良”数据:我们将找出在哪些情况下群集有用且无用,因为用户和操作员会在需要时停止痛苦并收集标记。
质感
我们有两个客户-具有在线聊天的保险公司-和聊天机器人培训项目(我们不称它们,这并不重要),其数据质量截然不同。 好吧,如果第二个项目的一半问题通过第一个问题的处理得以解决。 详细信息如下。
从技术角度来看,我们的任务是对文本进行分类。 这分两个阶段完成:首先将文本向量化(使用tf-idf,doc2vec等),然后对获得的向量(和类)训练分类模型-随机森林,SVM,神经网络等。 等等。
数据来自哪里:
- SQL上传聊天记录。 相关上传字段:消息文本; 作者(客户或运营商); 将消息分组到对话框中; 时间戳 客户联系类别(关于强制性机动车责任保险,船体保险,自愿医疗保险的问题;关于站点的问题;关于忠诚度计划的问题;关于改变保险条件的问题等)。
- 脚本树,或操作员针对具有不同请求的客户的问题和答案序列。
没有验证,当然,无处可寻。 所有模型都接受了70%的数据训练,并根据其余30%的结果进行了评估。
我们使用的模型的质量指标:
- 培训中:对数损失,以求差异化;
- 编写报告时:为了简单明了(包括针对客户),在测试样本上进行分类的准确性;
- 选择采取进一步行动的方向时:直视结果的数据科学家的直觉。
模型实验
当任务立即明确指出哪种模型可以提供最佳结果时,这种情况很少见。 所以在这里:没有实验,无处可寻。
我们将尝试向量化选项:
- tf-idf单字;
- tf-idf字符的三倍(以下为:3克);
- tf-idf分别放在2、3、4、5克上;
- 将2、3、4、5克上的tf-idf放在一起;
- 以上所有内容+将源文本中的单词还原为字典形式;
- 以上所有+通过截断SVD方法减小尺寸;
- 带有测量数量:10、30、100、300;
- doc2vec,接受有关任务文本的培训。
在这种背景下,分类选项看起来很差:SVM,XGBoost,LSTM,随机森林,朴素贝叶斯,基于SVM和XGB预测的随机森林。
尽管我们在三个独立组装的数据集及其片段上检查了结果的可重复性,但我们只能证明其广泛的适用性。
实验结果:
- 在“预处理-矢量化-降维分类”链中,每个步骤的选择效果几乎与其他步骤无关。 这非常方便,您无法针对每个新想法浏览多个选项,而无法在每个步骤中使用最知名的选项。
- tf-idf的字词减少了3克(准确度为0.72 vs 0.78)。 2、4、5克减为3克(0.75–0.76与0.78)。 {2; 5} -grams的总和要比3-grams好得多。 鉴于所需内存的急剧增加,我们决定忽略培训,以提高0.4%的准确性。
- 与所有变种的tf-idf相比,doc2vec是无助的(准确性0.4及以下)。 尝试训练他而不是训练他的军团(〜250,000篇文章),而是训练更大的一本(2.5–25百万篇文章)是值得的,但是到目前为止,您的双手还没有伸张。
- 截断的SVD没有帮助。 精度随着测量的增加而单调增加,在没有TSVD的情况下平稳地实现精度。
- 在分类器中,XGBoost以明显的优势获胜(+ 5-10%)。 最接近的竞争对手是SVM和随机森林。 朴素贝叶斯甚至都不是随机森林的竞争对手。
- LSTM的成功在很大程度上取决于数据集的大小:在100,000个对象的样本上,它能够与XGB竞争。 在6000的样本上-与贝叶斯一起滞后。
- 在SVM和XGB之上的随机森林要么总是与XGB一致,要么被误认为是更多。 这是非常可悲的,我们希望SVM在数据中至少找到一些XGB不可用的模式,但是可惜。
- XGBoost的稳定性很复杂。 例如,将其从0.72版本升级到0.80莫名其妙地将经过训练的模型的准确性降低了5-10%。 还有一件事:XGBoost支持在训练期间更改训练参数,并与标准scikit-learn API兼容,但严格分开。 不能一起做。 不得不修复它。
- 如果将单词带入字典形式,与单词中的tf-idf结合使用,可以稍微提高质量,但是在所有其他情况下都没有用。 最后,我们将其关闭以节省时间。
体验1.数据清理或标记处理
聊天操作员就是人。 在定义用户查询的类别时,它们经常会出错并且对类别之间的边界具有不同的解释。 因此,必须无情地和密集地清理源数据。
我们在第一个项目上的模型训练数据:
- 几年来在线聊天消息的历史。 这是60,000个对话中的250,000个帖子。 在对话结束时,话务员选择了用户呼叫所属的类别。 此数据集中大约有50个类别。
- 脚本树。 在我们的情况下,操作员没有有效的脚本。
到底什么数据不好,我们将其表述为假设,然后进行检查,并在可能的情况下进行更正。 这是发生了什么:
第一种方法。 在整个庞大的课程列表中,您可以放心离开5到10。
我们丢弃小类(小于样本的1%):数据少+影响小。 我们统一难以区分的类,操作员仍然以相同的方式做出反应。 例如:
'dms'+'如何预约医生'+'填写程序的问题'
“取消” +“取消状态” +“取消付费政策”
“续订问题” +“如何续签政策”?
接下来,我们抛出诸如“其他”,“其他”之类的类:对于聊天机器人,它们是无用的(无论如何都重定向到操作员),同时它们极大地破坏了准确性,因为20%的请求(30、50、90)被操作员不适当地分类在这里。 现在,我们抛弃了聊天机器人无法使用的类(尚未)。
结果:在一种情况下,精度从0.40增长到0.69,在另一种情况下,精度从0.66增长到0.77。
第二种方法。 聊天开始时,操作员本身不太了解如何选择要与用户联系的类别,因此数据中存在很多“噪音”和错误。
实验:我们只进行最后两个(三个,六个,...)个月的对话,并在
他们。
结果:在一种显着的情况下,准确性从0.40提高到0.60,在另一种情况下-从0.69提高到0.78。
第三种方法。 有时,精度为0.70并不意味着“在30%的情况下该模型被错误”,而是“在30%的情况下该标记是虚假的,并且该模型可以非常合理地对其进行校正”。
通过准确性或对数损失等度量,无法验证该假设。 为了进行实验,我们将自己限制在数据科学家的视线范围内,但是在理想情况下,您需要定性地重新安排数据集,而不要忘记交叉验证。
为了处理此类样本,我们提出了“迭代富集”的过程:
- 将数据集分成3-4个片段。
- 在第一个片段上训练模型。
- 通过训练后的模型预测第二个类别。
- 仔细查看预测类别和模型的置信度,选择置信度的边界值。
- 从第二个片段的边界下方移出充满信心的预测文本(对象),并以此训练模型。
- 重复直到碎片累或耗尽。
一方面,结果非常好:第一个迭代模型的准确度为70%,第二个-95%,第三个-99 +%。 仔细查看预测结果完全可以确认这一准确性。
另一方面,如何在此过程中系统地验证后续模型不学习先前模型的错误? 有一种想法是在带有高质量初始标记的手动“嘈杂”数据集上测试该过程,例如MNIST。 但是,a,没有足够的时间进行此操作。 在没有验证的情况下,我们不敢在生产中启动迭代充实和生成的模型。
第四种方法。 数据集可以扩展-从而提高准确性并减少重新培训,从而为现有文本添加许多错别字。
错别字是错别字-将字母加倍,跳过字母,在位置重新排列相邻的字母,用键盘上的相邻字母替换字母。
实验:出现错字的p个字母的比例:2%,4%,6%,8%,10%,12%。 数据集增加:通常最多60,000个副本。 根据初始大小(在过滤器之后),这意味着增加了3–30倍。
结果:取决于数据集。 在小型数据集(约300个副本)上,错别字的4–6%可使准确度稳定且显着提高(0.40→0.60)。 在大型数据集上,一切都变糟了。 错别字比例在8%或以上时,文本会变成胡扯,并且准确性会降低。 误差率为2–8%时,准确度会在几个百分点的范围内波动,很少会超过没有错字的准确度,而且看起来不需要多次增加训练时间。
结果,我们获得了一个模型,该模型可以以0.86的准确度区分5个呼叫类别。 我们与客户协调五个分支中每一个的问答文本,将其固定在聊天机器人上,然后发送给质量检查人员。
经验2.深入数据,或不加标记怎么办
在第一个项目上取得了良好的结果后,我们满怀信心地接近了第二个项目。 但是,幸运的是,我们没有忘记如何感到惊讶。
我们遇到了什么:
- 大约一年前,与客户商定了一个五分支的脚本树。
- 带标签的500封邮件样本和11种未知来源的类别。
- 由聊天操作员根据220,000条消息,21,000个对话和其他50个类别进行了标记。
- SVM模型是在第一个样本上训练的,准确性为0.69,是从以前的数据科学家团队继承而来的。 为什么使用SVM,历史却是寂静的。
首先,我们看一下这些类:在脚本树中,在SVM模型的示例中,在主要示例中。 这是我们看到的:
- SVM模型的类大致对应于脚本的分支,但绝不对应于较大样本中的类。
- 脚本树是在一年前写在业务流程上的,几乎已经没用了。 不建议使用SVM模型。
- 大型样本中最大的两个类别是销售(50%)和其他(45%)。
- 在五个第二大类中,三个与Sales一样通用。
- 其余的45个类每个包含少于30个对话框。 即 我们没有脚本树,没有类列表,也没有标记。
在这种情况下该怎么办? 我们卷起袖子,继续努力从数据中获取类和标记。
第一次尝试。 让我们尝试聚类用户问题,即 对话中的第一则讯息,问候除外。
我们检查。 我们通过计算3克来对副本进行矢量化处理。 我们将尺寸降低到TSVD的前十个测量值。 我们通过具有欧氏距离和目标Ward函数的聚集聚类进行聚类。 使用t-SNE再次降低尺寸(最多两次测量,以便您可以用眼睛观察结果)。 我们在平面上绘制副本点,以群集的颜色进行绘制。
结果:恐惧和恐怖。 Sane集群,我们可以假设不存在:
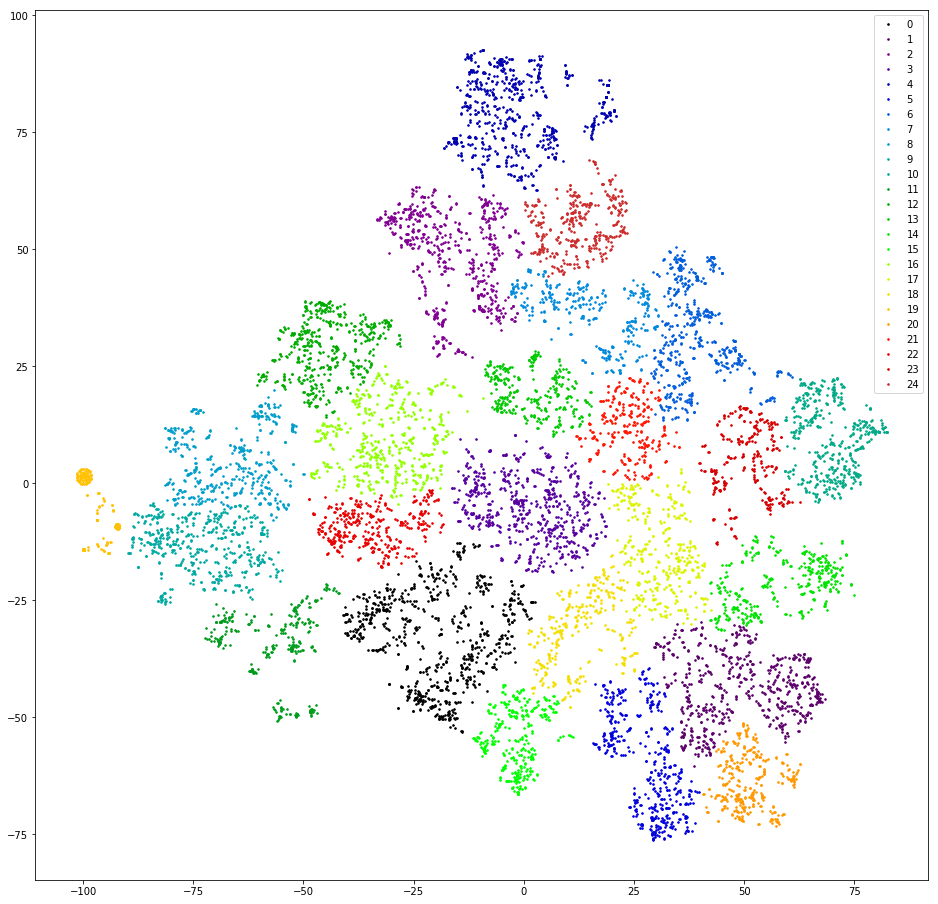
几乎没有-左边有一个橙色,这是因为其中所有消息都包含3克“ @”。 这3克是预处理工件。 在过滤标点符号的过程中,“ @”不仅被过滤掉,而且还长满了空格。 但是该工件很有用。 该群集包括首先写电子邮件的用户。 不幸的是,仅凭邮件的可用性,还不清楚用户的要求是什么。 我们继续前进。
第二次尝试。 如果运营商经常以或多或少的标准链接做出响应怎么办?
我们检查。 我们从操作员消息中提取类似链接的子字符串,略微修改链接,使其拼写不同,但含义相同(http / https,/ search?City =%city%),请考虑链接频率。
结果:没有希望。 首先,操作员仅对链接的一小部分请求(<10%)做出响应。 其次,即使在手动清理和过滤曾经发生过的链接之后,仍然有三十多个链接。 第三,在以链接结束对话的用户的行为中,没有特别的相似性。
第三次尝试。 让我们寻找运营商的标准答案-如果它们将成为消息分类的指示符怎么办?
我们检查。 在每次对话中,我们都会获取操作员的最后一个副本(除了再见:“我可以帮助其他事情”等),并考虑唯一副本的频率。
结果:很有希望,但不方便。 50%的操作员响应是唯一的,另外10–20%被发现两次,其余的30–40%被相对较少的流行模板所覆盖。 相对较小-大约三百。 仔细查看这些模板,就可以发现它们中的许多都是相同答案的变体-它们在一个字母,一个单词,一个段落的位置上有所不同。 我想将这些含义相近的答案归为一组。
第四次尝试。 聚集语句的最新副本。 将它们更好地聚集在一起:
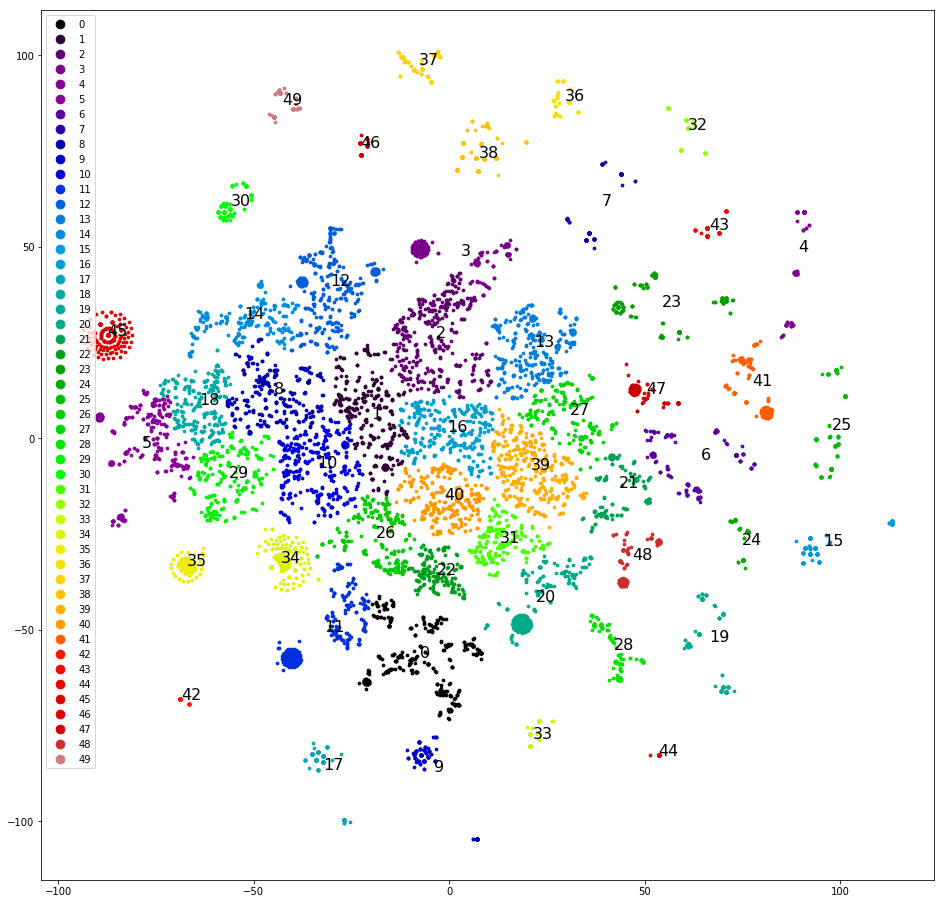
您已经可以使用此功能。
如在第一次尝试中一样,我们在平面上聚类并绘制副本,手动确定最分离的聚类,将其从数据集中删除并再次聚类。 在分离了大约一半的数据集之后,清晰的集群结束了,我们开始考虑分配给它们的类。 我们根据原始的五个类对群集进行分散-样本“偏斜”,五个原始类中的三个不接收单个群集。 太可惜了 我们将群集分为五个类别,我们随机指定以下类别:“呼叫”,“来临”,“等待一天的答案”,“验证码问题”,“其他”。 偏斜较小,但准确度仅为0.4-0.5。 再次不好。 为30多个集群中的每个集群分配自己的类。 样本再次偏斜,准确度再次为0.5,尽管大约五种选定类别具有良好的准确性和完整性(0.8或更高)。 但是结果仍然不令人满意。
第五次尝试。 我们需要集群的所有来龙去脉。 我们检索完整的聚类树状图,而不是前三十个聚类。 我们将其保存为客户分析人员可以访问的格式,并帮助他们进行标记-我们绘制类列表。
对于每条消息,我们从根开始计算一簇簇,其中包括每条消息。 我们构建一个包含以下列的表:文本,链中第一个集群的ID,链中第二个集群的ID,...,与文本相对应的集群的ID。 我们将表保存在csv / xls中。 进一步,您可以使用办公工具。
我们将数据和用于标记的类列表的草图提供给客户端。 客户分析师重新标记了约10,000条第一条用户消息。 我们已经从经验中吸取教训,要求对每个消息至少标记两次。 并非一无所有-必须丢弃这10,000个中的4,000个,因为两个分析师的区分方式不同。 在剩下的6,000个中,我们很快就重复了第一个项目的成功:
- 基准:完全不进行过滤-精度为0.66。
- 从操作员的角度来看,我们合并了相同的类。 我们得到的精度为0.73。
- 我们删除了“其他”类别-准确性提高到0.79。
模型已经准备就绪,现在您需要绘制脚本树。 由于无法解释的原因,我们无权访问脚本以进行操作员响应。 我们并没有感到惊讶,假装是用户,并且在实地工作了几个小时,我们收集了响应模板并在所有情况下阐明了操作员的问题。 他们用一棵树装饰它们,用机器人包装它们,然后进行测试。 客户批准。
结论或经验表明:
- 您可以分别试验模型的各个部分(预处理,向量化,分类等)。
- XGBoost仍然可以控制球,尽管如果您需要一些不寻常的东西,也会遇到问题。
- 用户是混乱输入的外围设备,因此您需要清除用户数据。
- 迭代富集虽然很危险,但却很酷。
- 有时值得将数据返回给客户端进行标记。 但是不要忘记帮助他获得高质量的结果。
待总结。