
本文的主题仅是狭义的,但是对于那些正在开发自己的数据仓库并考虑与Spring Framework集成的人来说可能很有用。
背景知识
开发人员通常不喜欢改变其习惯(通常,框架也包含在习惯列表中)。 当我开始使用CUBA时 ,我不必学习太多的新知识,几乎可以立即积极参与该项目的工作。 但是有一件事我不得不坐更长的时间-它正在处理数据。
Spring有几个可用于数据库的库,最流行的库之一是spring-data-jpa ,在大多数情况下,该库不允许您编写SQL或JPQL。 您只需要使用以特殊方式命名的方法创建一个特殊接口,Spring就会为您生成并完成其余工作,以从数据库中获取数据并创建实体对象的实例。
以下是界面,其中包含一种用于计算具有给定姓氏的客户的方法。
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
该接口可以直接在Spring服务中使用,而无需创建任何实现,从而大大加快了工作速度。
CUBA具有用于处理数据的API,该API包括各种功能,例如部分加载的实体或对数据库表中实体属性和行具有访问控制的棘手的安全系统。 但是此API与Spring Data或JPA / Hibernate中开发人员所使用的API略有不同。
为什么CUBA中没有JPA存储库,我可以添加它们吗?
在CUBA中处理数据
在CUBA中,有三个主要的类负责处理数据:DataStore,EntityManager和DataManager。
DataStore是任何数据存储的高级抽象:数据库,文件系统或云存储。 通过此API,您可以对数据执行基本操作。 在大多数情况下,除非开发自己的存储库,或者需要对存储库中的数据进行某些非常特殊的访问,否则开发人员无需直接使用DataStore。
EntityManager是著名的JPA EntityManager的副本。 与标准实现不同,它具有用于处理CUBA表示 ,“软”(逻辑)删除数据以及用于CUBA中的查询的特殊方法。 与DataStore一样,在90%的项目中,普通开发人员将不必处理EntityManager,除非有必要绕过数据访问限制系统来满足某些请求。
DataManager是在CUBA中处理数据的主要类。 提供用于数据操作的API,并支持数据访问控制,包括对属性和行级限制的访问。 DataManager隐式修改在CUBA中运行的所有查询。 例如,它可以从select语句中排除当前用户无权访问的表字段,并在where添加条件以从选择中排除表行。 这使开发人员的工作变得更加轻松,因为您不必考虑如何正确考虑访问权限来编写查询,CUBA会根据数据库服务表中的数据自动执行此操作。
下图是通过DataManager提取数据所涉及的CUBA组件之间的交互关系图。
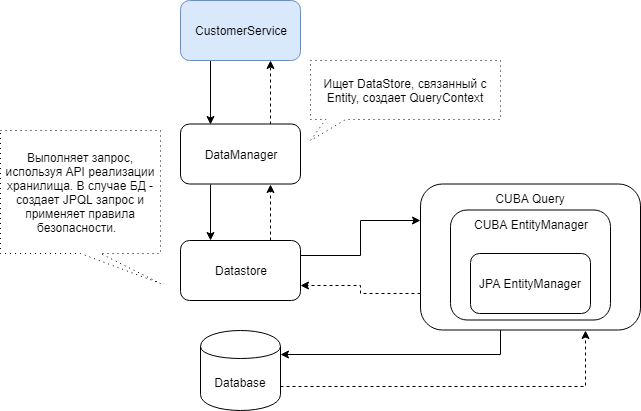
使用DataManager,您可以相对轻松地使用CUBA视图加载实体和实体的整个层次结构。 以最简单的形式,查询如下所示:
dataManager.load(Customer.class).list();
如前所述,DataManager将过滤掉“逻辑删除”的记录,从请求中删除禁止的属性,并自动打开和关闭事务。
但是,涉及更复杂的查询时,您必须在CUBA中编写JPQL。
例如,如果您需要计算具有给定姓氏的客户(如上一节中的示例所示),则需要编写类似以下代码的内容:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
或诸如此类:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
在CUBA API中,您需要将JPQL表达式作为字符串传递(尚不支持Criteria API),这是创建查询的可读且可理解的方式,但是调试此类查询会带来很多乐趣。 另外,在容器初始化期间,编译器和Spring框架都不会验证JPQL字符串,这只会导致运行时错误。
将此与Spring JPA进行比较:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
该代码短三倍,并且没有行。 另外,在Spring容器初始化期间检查方法名称countByLastName 。 如果输入错误,并且您写了countByLastNsme ,那么应用程序将在部署期间崩溃并显示错误:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
CUBA是围绕Spring框架构建的,因此您可以在使用CUBA编写的应用程序中插入spring-data-jpa库,但是存在一个小问题-访问控制。 Spring CrudRepository实现使用其EntityManager。 因此,所有查询将绕过DataManager执行。 因此,要在CUBA中使用JPA存储库,您需要将所有EntityManager调用替换为DataManager调用,并添加对CUBA视图的支持。
也许有人会说spring-data-jpa是一个不受控制的黑匣子,并且始终最好编写纯JPQL甚至SQL。 这是便利与抽象级别之间取得平衡的永恒问题。 每个人都可以选择自己喜欢的方法,但是拥有在武器库中处理数据的其他方式永远不会受到伤害。 对于那些需要更多控制权的人,Spring 可以为JPA存储库方法定义自己的请求 。
实作
JPA存储库使用spring-data-commons库实现为CUBA模块。 我们放弃了修改spring-data-jpa的想法,因为与编写我们自己的查询生成器相比,工作量要大得多。 特别是由于spring-data-commons完成了大部分工作。 例如,解析方法名称并将名称与类和属性相关联完全在此库中完成。 Spring-data-commons包含用于实现自己的存储库的所有必需基类,并且无需花费很多精力即可实现。 例如,该库在spring-data-mongodb中使用 。
最困难的事情是基于对象的层次结构-解析方法名称的结果来准确地实现JPQL生成。 但是,幸运的是,已经在Apache Ignite中实现了类似的任务,因此从那里获取了代码,并对其进行了一些修改以生成JPQL而不是SQL,并支持delete运算符。
Spring-data-commons使用代理来动态创建接口实现。 初始化CUBA应用程序上下文时,所有到接口的链接都替换为到该上下文中发布的代理容器的链接。 调用接口方法时,它会被相应的代理对象拦截。 然后,该对象通过方法名称生成JPQL查询,替换参数并将带有参数的查询发送到DataManager以执行。 下图显示了模块关键组件之间交互的简化过程。

在CUBA中使用存储库
要在CUBA中使用存储库,您只需要在项目构建文件中连接模块即可:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
您可以使用XML配置来“启用”存储库:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
您可以使用批注:
@Configuration @EnableCubaRepositories public class AppConfig {
激活存储库支持后,可以按通常的形式创建它们,例如:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
对于每种方法,可以使用注释:
@CubaView设置要在DataManager中使用的CUBA视图@JpqlQuery指定将执行的JPQL查询,而不管方法名称如何。
此模块在CUBA框架的global模块中使用,因此,存储库可在core模块和web 。 您唯一需要记住的是激活两个模块的配置文件中的存储库。
在CUBA服务中使用存储库的示例:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
结论
CUBA是一个灵活的框架。 如果要向其中添加某些内容,则无需自己修复内核或等待新版本。 我希望该模块可以使CUBA开发更高效,更快。 该模块的第一个版本在GitHub上提供 ,并在CUBA 6.10版上进行了测试