许多人怀疑自己分叉和写东西的前景。 价格通常太高。 听说您自己的JDK(据说在每个相当大的公司中都存在)特别奇怪。 到底是什么在发胖? 本文将详细介绍有关该公司的故事,这一切都会带来真正的商业利益,并且做得糟透了,因为它们:
- 开发了多租户虚拟Java机器;
- 他们提出了一种操作对象的机制,该机制不会给垃圾回收带来开销。
- 他们做了类似Azul Zing的ReadyNow同行的事情。
- 他们用yield s和continuation洗净了自己的协程(甚至准备与我在秋天写的 Loom分享他们的经验);
- 他们将所有这些奇迹归结为自己的诊断子系统。
与往常一样,视频,全文解密和幻灯片正等着您切入。 欢迎来到开源项目最困难的适应领域之一!

医生,你从哪里得到这些照片? 奥赖利(O'Reilly)封面人物:KDPV背景由约书亚·牛顿(Joshua Newton)提供,描绘了印度尼西亚乌布(Ubud)的Sangyang Jaran圣舞。 这是由火舞和dance舞组成的经典巴厘岛表演。 一个光着脚跟的男人在篝火旁移动,在椰子壳上饲养,用脚sho东西,在马魂的影响下以tr状态跳舞。 您自己的JDK的完美插图,对吗?
幻灯片和报告说明 (您不需要它们,此哈伯狗足动物拥有您所需的一切)。
您好,我叫李三宏,我在阿里巴巴工作,我想谈一谈我们为满足业务需求对OpenJDK进行的更改。 该职位包括三个部分。 在第一篇中,我将讨论如何在阿里巴巴中使用Java。 我认为第二部分是最重要的-我们将在其中讨论如何根据业务需求配置OpenJDK。 第三部分将介绍我们为诊断而创建的工具。
但是在继续第一部分之前,我想简单介绍一下我们公司。
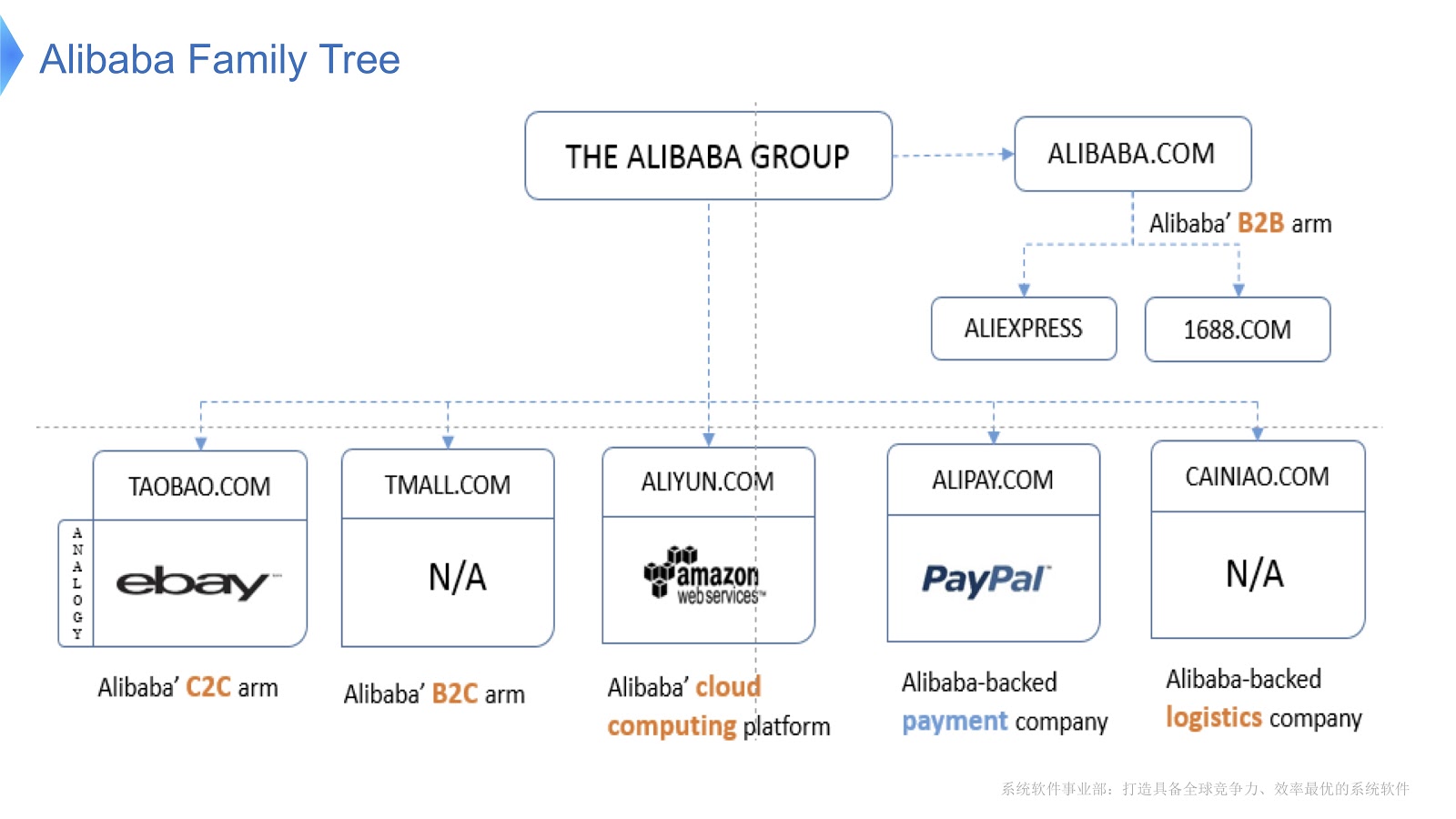
该图显示了阿里巴巴的内部结构。 它由各种公司组成,这些公司的主要专业是组织电子市场以及提供金融和物流平台。 我认为俄罗斯的大多数人都熟悉速卖通。 阿里巴巴拥有一支专门的程序员团队,他们开发和支持整个分布式堆栈,为全球速卖通客户提供服务。
为了了解阿里巴巴的工作规模,让我们看看光棍节在中国发生了什么。 每年的11月11日庆祝它,这一天人们通过阿里巴巴购买了很多商品。 据我所知,在世界各地的假期中,这是购物最多的一次。
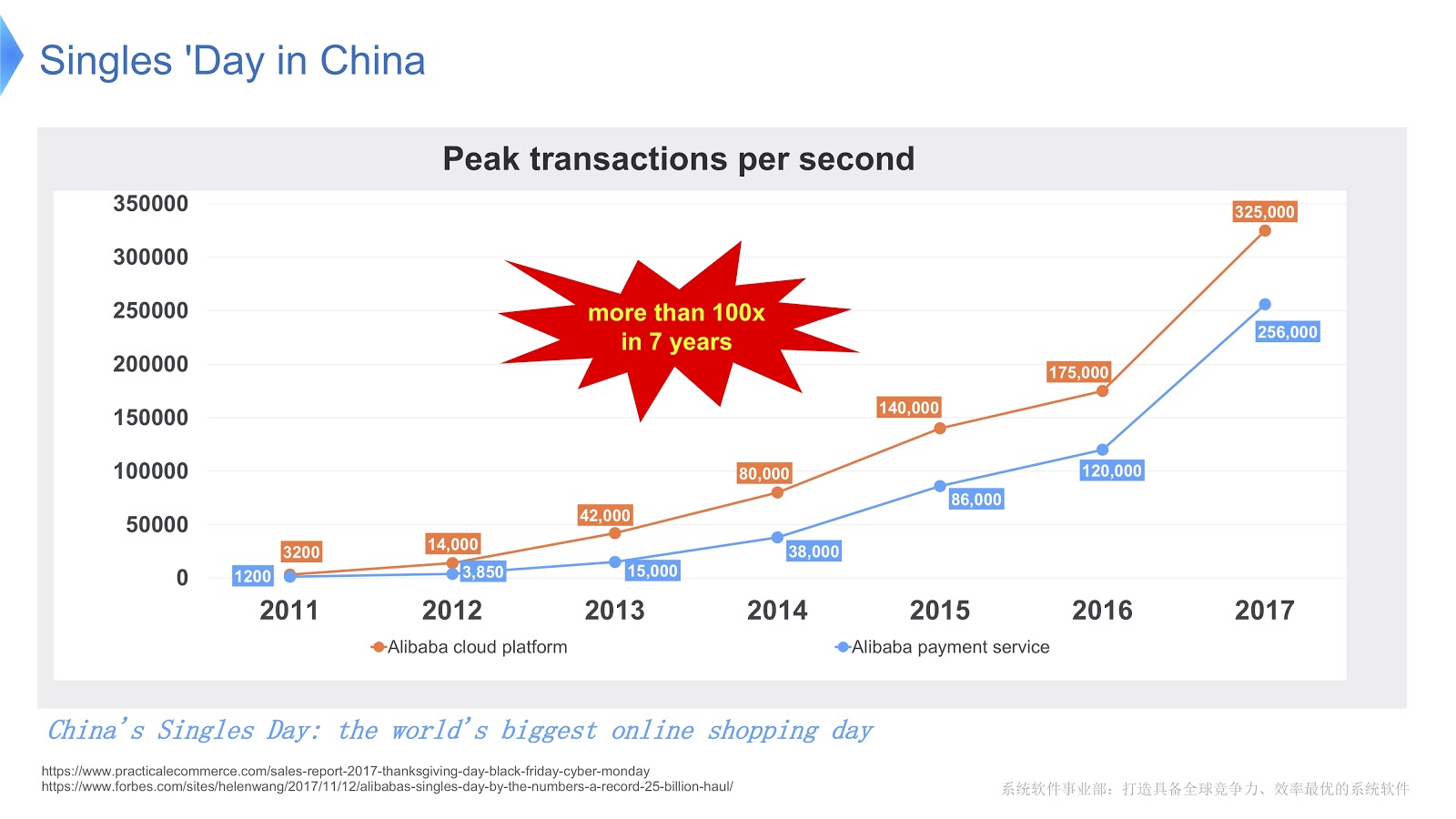
在上图中,您可以看到一个图表,显示了我们的支持系统上的负载。 红线显示了我们的订单服务的工作,并显示了每秒的峰值交易数量,去年达到了32.5万。 蓝线表示付款服务,她的数字为25.6万。 我想谈谈如何优化服务于这么多事务的堆栈。
让我们讨论使用Java在阿里巴巴中工作的主要技术。 首先,我必须说,我们有许多开源应用程序作为基础。 对于大数据处理,我们使用HBase Hadoop。 作为容器,我们使用Tomcat和OSGi。 Java的使用范围非常广泛-我们的数据中心部署了数百万个JVM实例。 我还必须说我们的体系结构是面向服务的,也就是说,我们创建了许多使用RPC调用相互通信的服务。 最后,我们的体系结构是异构的。 为了提高性能,许多算法都是使用C和C ++库编写的,因此它们使用JNI调用与Java通信。

我们与OpenJDK的合作历史始于2011年的OpenJDK6。我们选择OpenJDK的三个重要原因。 首先,我们可以根据业务需要直接更改其代码。 其次,当出现紧急问题时,我们可以比等待正式发布更快地自行解决问题。 这对我们的业务至关重要。 第三,我们的Java开发人员使用我们自己的工具进行快速,高质量的调试和诊断。
在继续讨论技术问题之前,我想列举我们必须克服的主要困难。 首先,我们启动了大量的JVM实例-在这种情况下,降低硬件成本的问题是一个紧迫的问题。 其次,我已经说过,我们为大量交易提供服务。 多亏了垃圾收集器,Java向我们承诺了“无限内存”。 另外,由于使用了JIT编译器,因此它在较低的性能上胜出。 但这也有另一面:更长的世界垃圾收集时间。 另外,Java需要额外的CPU周期来编译Java方法。 这意味着编译器争夺CPU周期。 随着应用程序变得越来越复杂,这两个问题都恶化了。
第三个困难是我们正在运行许多应用程序。 我认为这里的每个人都熟悉OpenJDK附带的工具,例如JConsole或VisualVM。 问题在于它们没有提供我们需要配置的确切信息。 另外,当我们在生产中使用这些工具(例如JConsole或VisualVM)时,低开销不仅是愿望,而且是必要条件。 我必须编写自己的诊断工具。

图片概述了我们对OpenJDK所做的更改。 让我们看一下我们如何克服上面提到的困难。
多租户JVM
我们将一种解决方案称为多租户JVM。 它使您可以在一个容器中安全地运行多个Web应用程序。 另一个解决方案称为GCIH(GC不可见堆)。 这是一种为您提供成熟的Java对象的机制,同时它不需要垃圾收集的费用。 此外,为了减少线程上下文的成本,我们在Java平台上实现了协程。 此外,我们编写了一种名为JWarmup的机制-其功能与ReadyNow非常相似。 道格拉斯·霍金斯(Douglas Hawkins)似乎在报告中提到了他 。 最后,我们开发了自己的配置工具ZProfiler。
让我们仔细看看我们如何实现基于OpenJDK的多租户。
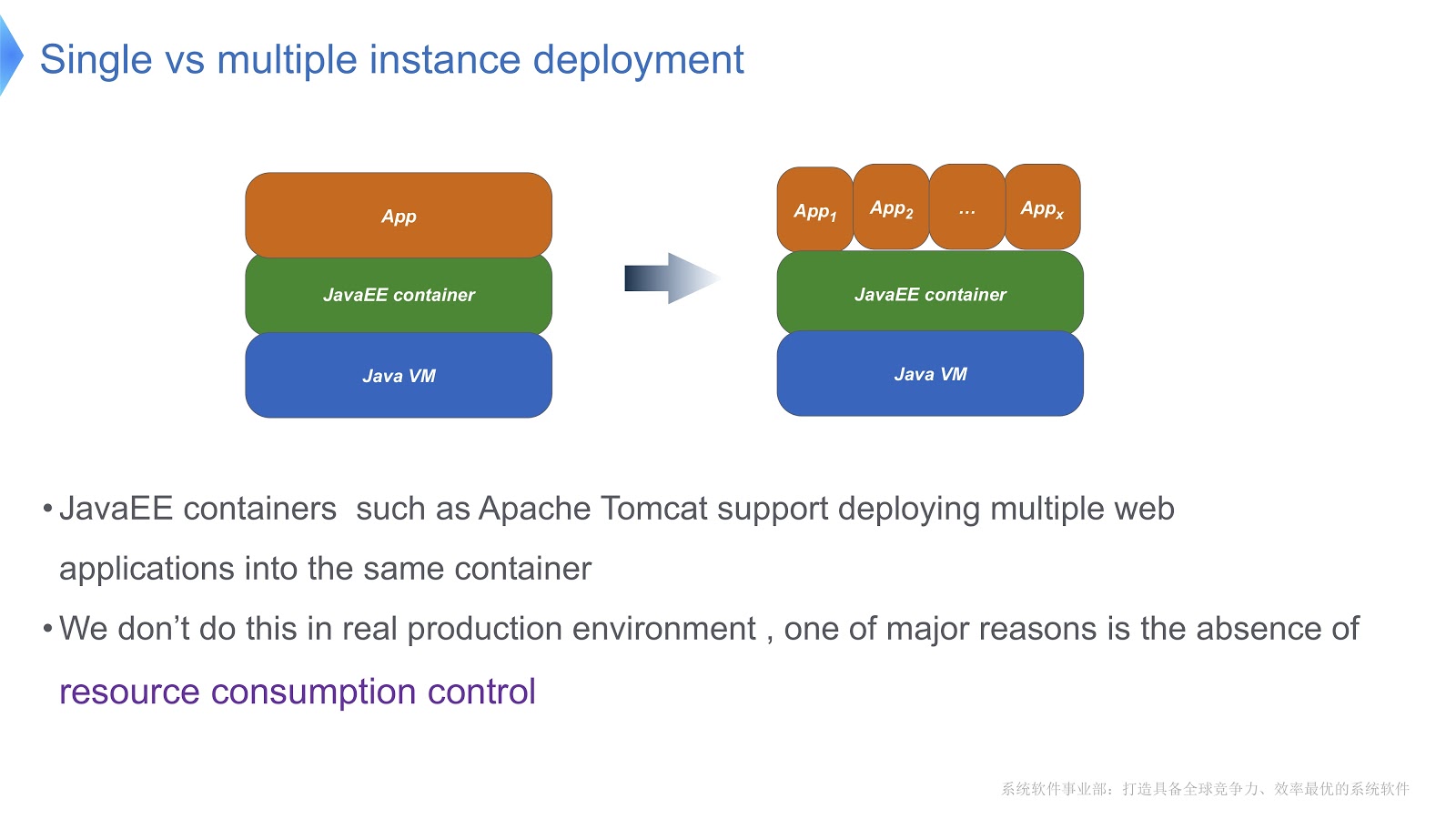
看一下上面的图片-我想你们大多数人都熟悉这种模式。 将传统方法与多租户进行比较。 如果您的应用程序使用Apache Tomcat运行,则还可以在同一容器中运行多个实例。 但是Tomcat不能为它们每个提供稳定的资源消耗。 假设,如果一个正在运行的应用程序比其他应用程序需要更多的CPU时间,您将如何控制CPU时间分配? 如何确保此应用程序不会影响他人的工作? 正是这个问题使我们转向多租户技术。
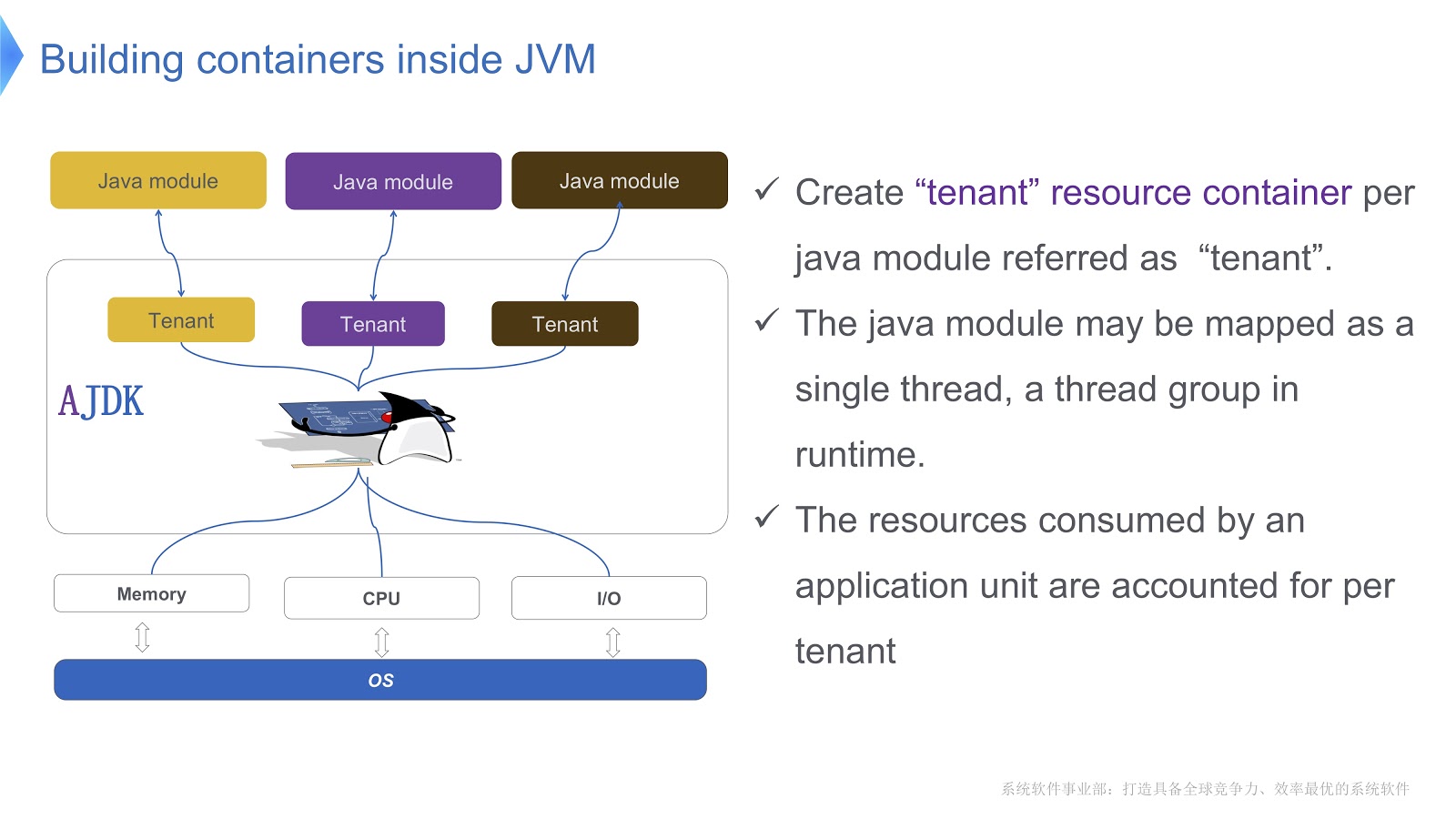
图片示意性地显示了我们如何实现它。 我们在JVM中为租户创建了多个容器。 这些容器中的每一个都为每个Java模块提供可靠的资源消耗控制。 可以在一个容器中部署多个模块。 每个模块可以在运行时与一个线程或一组线程关联。
让我们看一下租户容器API的外观。 我们有一个租户配置类,用于存储有关资源消耗的信息。 接下来,有一个容器本身的类。
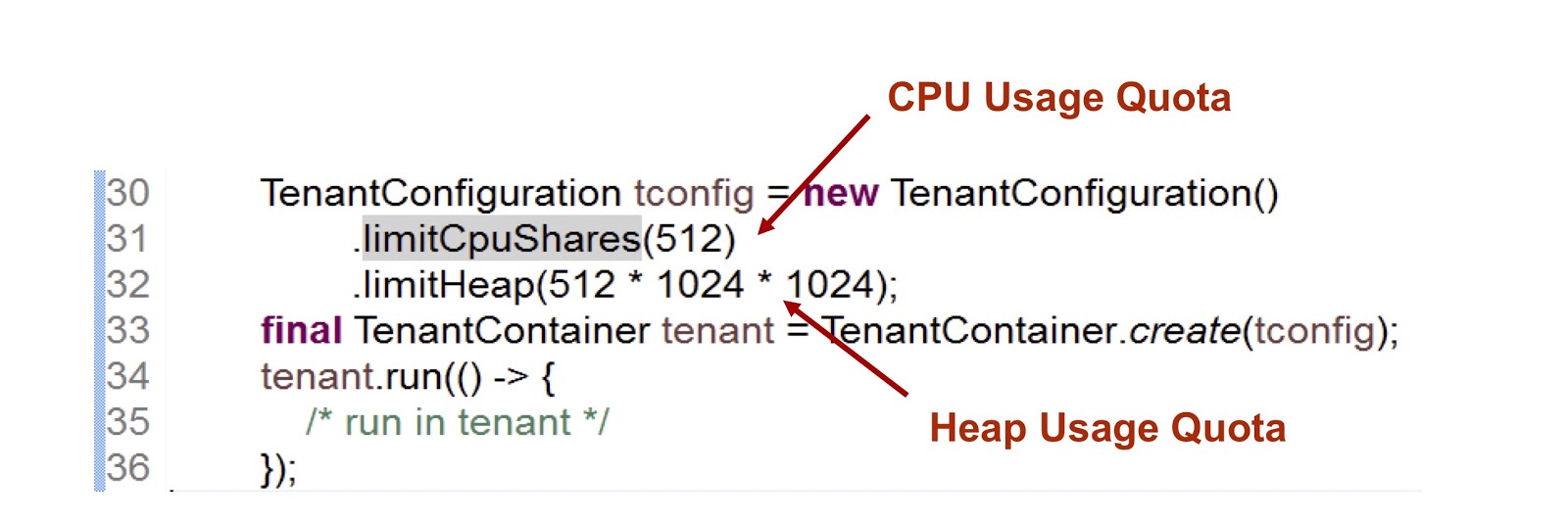
在提供的代码段中,我们创建一个租户,然后指出为其提供了多少时间的CPU和内存。 第一个指标是整数,这意味着租户可用的CPU时间份额,在这种情况下,我们表示为512。对于cgroup,我们使用非常相似的方法,我将对此进行详细介绍。 第二个指标是租户可以使用的最大堆大小。
考虑租户如何与线程交互。 TenantContainer类提供了.run()方法,当线程进入它时,它会自动附加到租户,而当它离开它时,就会发生相反的过程。 因此,所有代码都在.run()方法内执行。 此外,在.run()方法内部创建的任何线程都将附加到父线程的租户。
我们遇到了一个非常重要的问题-如何在多租户JVM中管理CPU? 我们的解决方案刚刚在Linux x64平台上实现。 存在一个控制组机制,即cgroups。 它允许您在单独的组中选择一个进程,然后指示每个组的资源消耗方式。 让我们尝试将这种方法转移到Hotspot JVM的上下文中。 在Hotstpot,Java线程被组织为本地线程。

如上图所示:每个Java线程与本机线程一一对应。 在我们的示例中,我们有一个TenantA容器,其中有两个本机线程。 为了能够控制CPU时间的分配,我们将两个本机线程放在一个控制组中。 因此,我们可以仅依靠[控制组]( https://zh.wikipedia.org/wiki/Cgroups )。
让我们看一个更详细的例子。
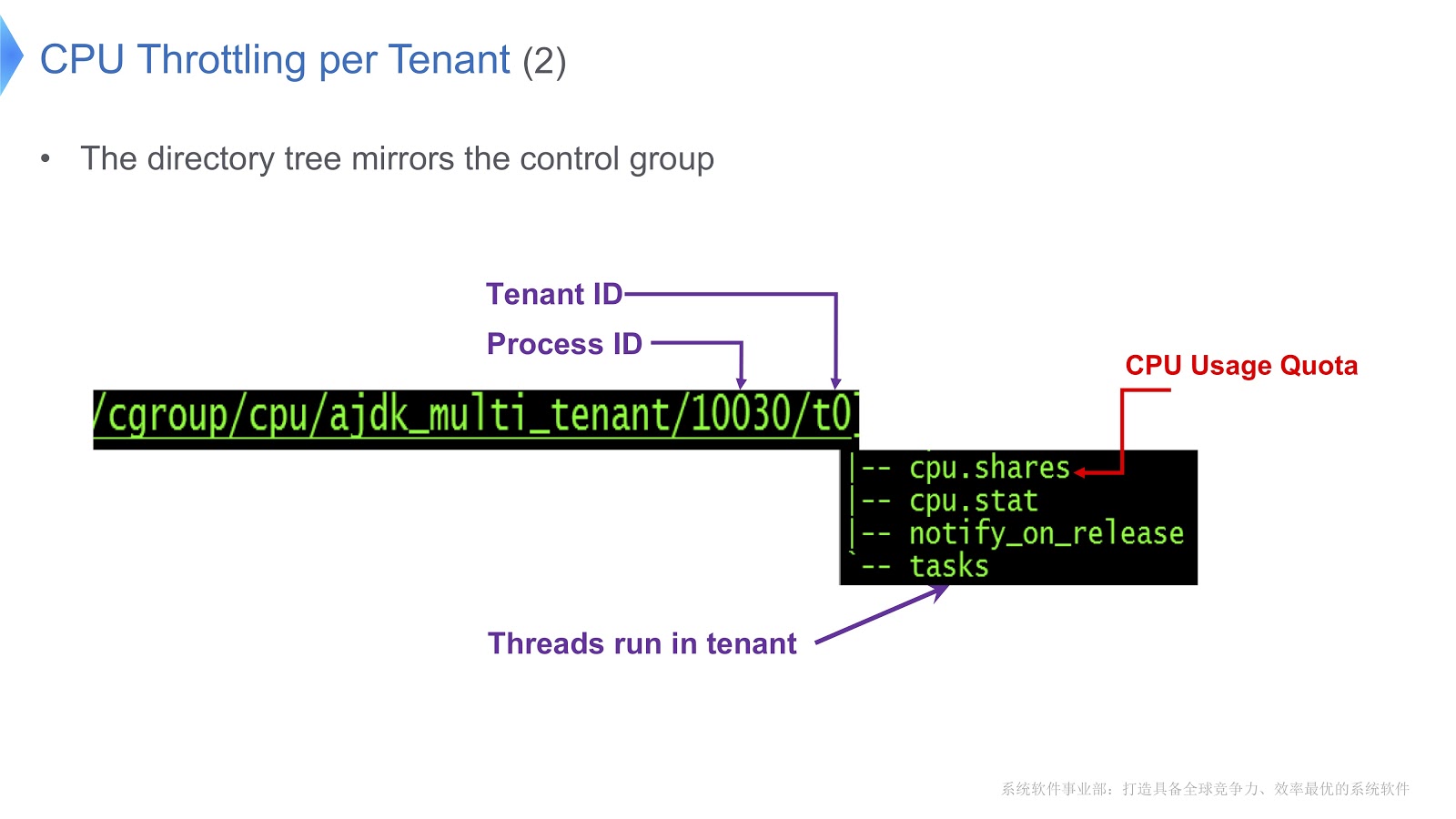
Linux上的控制组被映射到目录。 在我们的示例中,我们为租户0创建了/t0目录。该目录包含/t0/tasks目录,所有t0线程都位于此处。 另一个重要文件是/t0/cpu.shares 。 它指示将CPU分配给该租户多少时间。 整个结构继承自控制组-我们只需确保Java线程,本机线程和控制组之间具有直接对应关系。
另一个重要问题涉及管理每个租户。
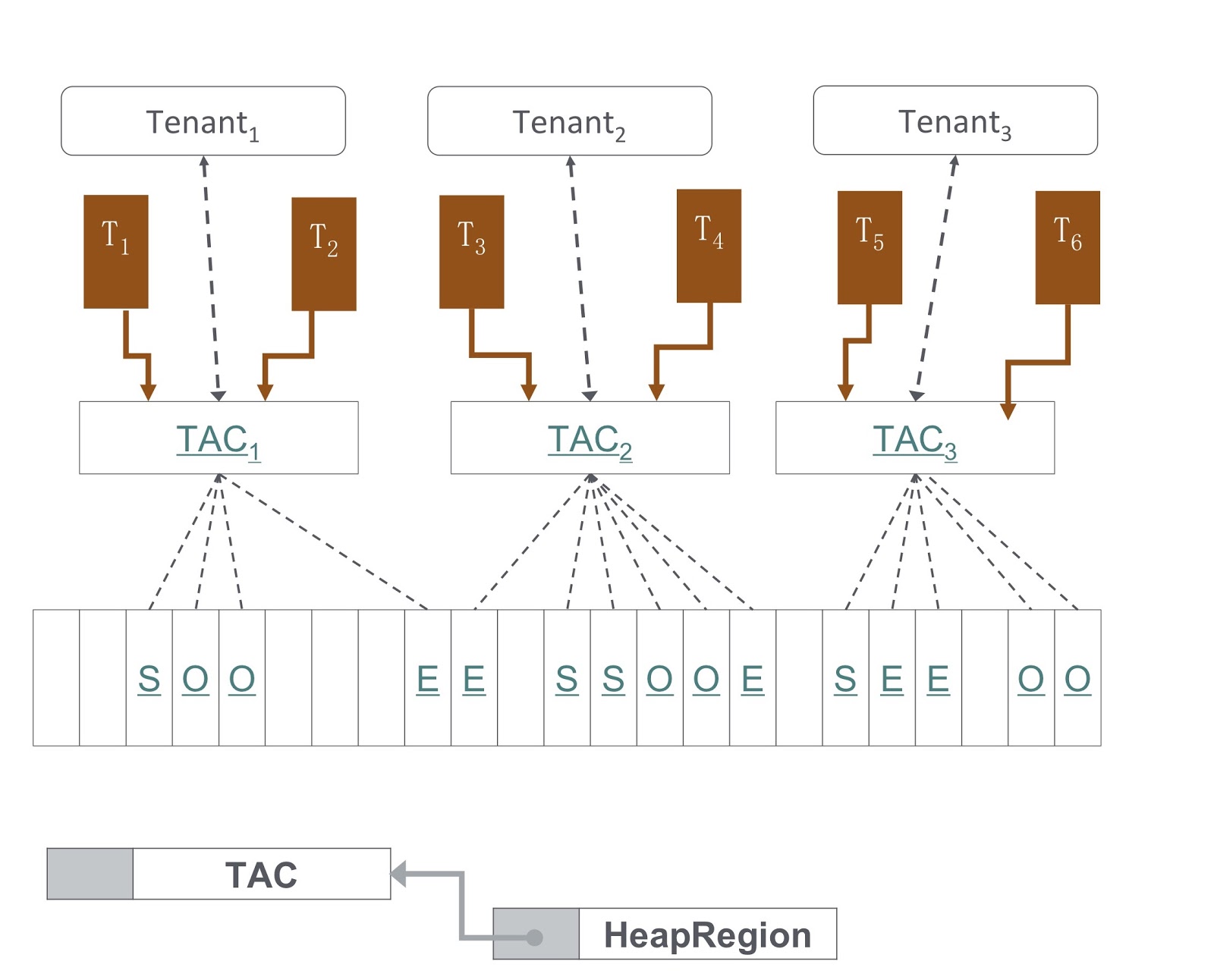
在图片中,您可以看到实现方式的示意图。 我们的方法基于G1GC。 在图片的底部,G1GC将堆划分为相同大小的部分。 基于它们,我们创建承租人分配上下文TAC,承租人用其管理堆部分。 通过TAC,我们限制了可供租户使用的堆部分的大小。 在此原则适用,根据该原则,堆的每个部分仅包含一个租户的对象。 要实现它,我们需要对垃圾回收期间复制对象的过程进行更改-必须确保将对象复制到堆的正确部分。
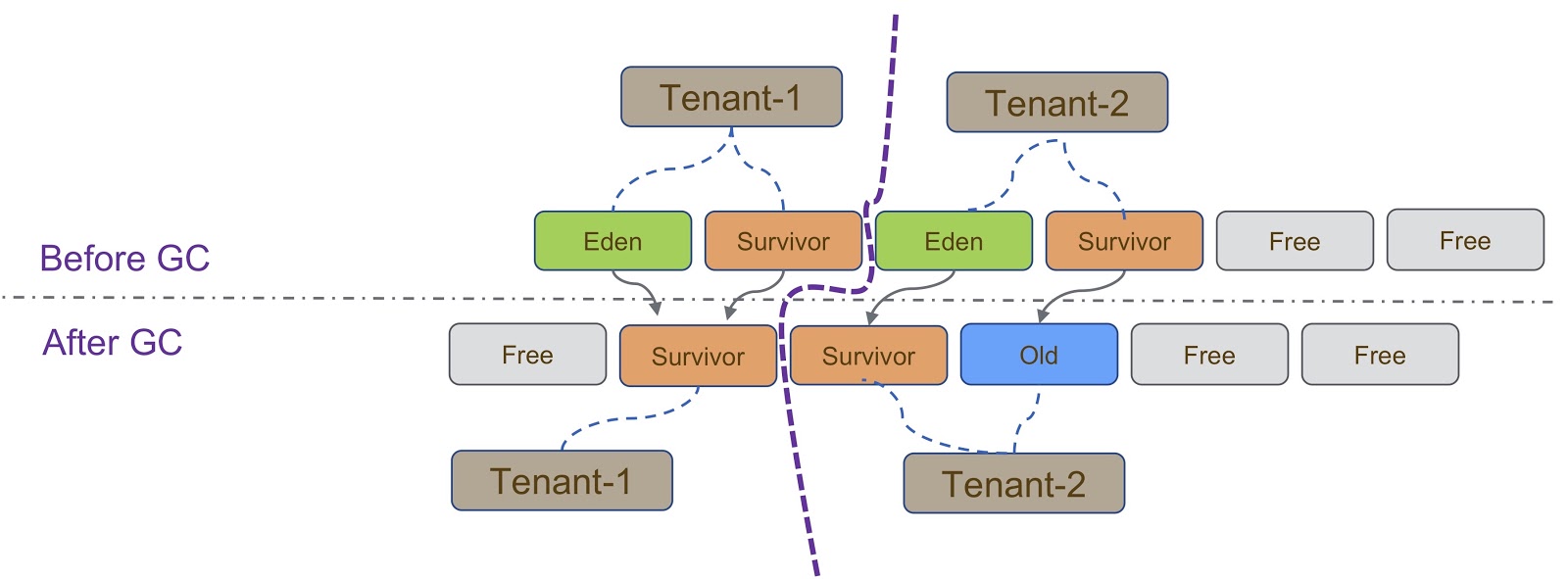
上图示意性地说明了此过程。 如我所说,我们的实现基于G1GC。 G1GC是一个复制垃圾收集器,因此在垃圾收集期间,我们需要确保将对象复制到堆的正确部分。 在幻灯片上,类似于Tenant-2 ,必须将Tenant-1创建的所有对象复制到其堆的一部分中。
当租户彼此隔离时,还会产生其他考虑因素。 在这里,我必须说一下TLAB(线程本地分配缓冲区)-一种用于快速分配内存的机制。 TLAB空间取决于堆部分。 如我所说,不同的租户具有不同的堆节组。

幻灯片上显示了使用TLAB的细节-当线程从Tenant 1切换到Tenant 2 ,我们需要确保TLAB空间使用了正确的堆部分。 这可以通过两种方式来实现。 第一种方法是,当Thread A从Tenant 1切换到Tenant 2 ,我们只是摆脱了旧的Tenant 2 ,而在Tenant 2创建了一个新Tenant 2 。 这种方法相对容易实现,但是浪费了TLAB中的空间,这是不希望的。 第二种方法更复杂-使TLAB了解租户。 这意味着我们将为一个线程提供多个TLAB缓冲区。 当Thread A从Tenant 1切换到Tenant 2 ,我们需要更改缓冲区并使用在Tenant 2中创建的缓冲区。
与租户划界有关的另一种机制是IHOP(发起线程占用百分比)。 最初,IHOP是基于整个堆计算的,但是对于多租户机制,它必须仅基于堆的一部分进行计算。
让我们仔细看看什么是GCIH(GC隐形堆)。 此机制在堆上创建一个部分,该部分对垃圾收集器隐藏,因此不受垃圾收集的影响。 该站点由GCIH租户管理。

在这里必须说,我们向Java开发人员提供了公共API,这一点很重要。 屏幕上可以看到一个使用它的示例。 它允许使用moveIn()方法将对象从常规堆移动到GCIH堆的一部分。 它的优点是您仍然可以像使用常规Java对象一样与这些对象进行交互,它们在结构上非常相似。 但是同时,它们并不需要垃圾收集的成本。 我认为结论是,如果您想加快垃圾收集的速度,则需要根据应用程序的需求自定义垃圾收集器的行为。
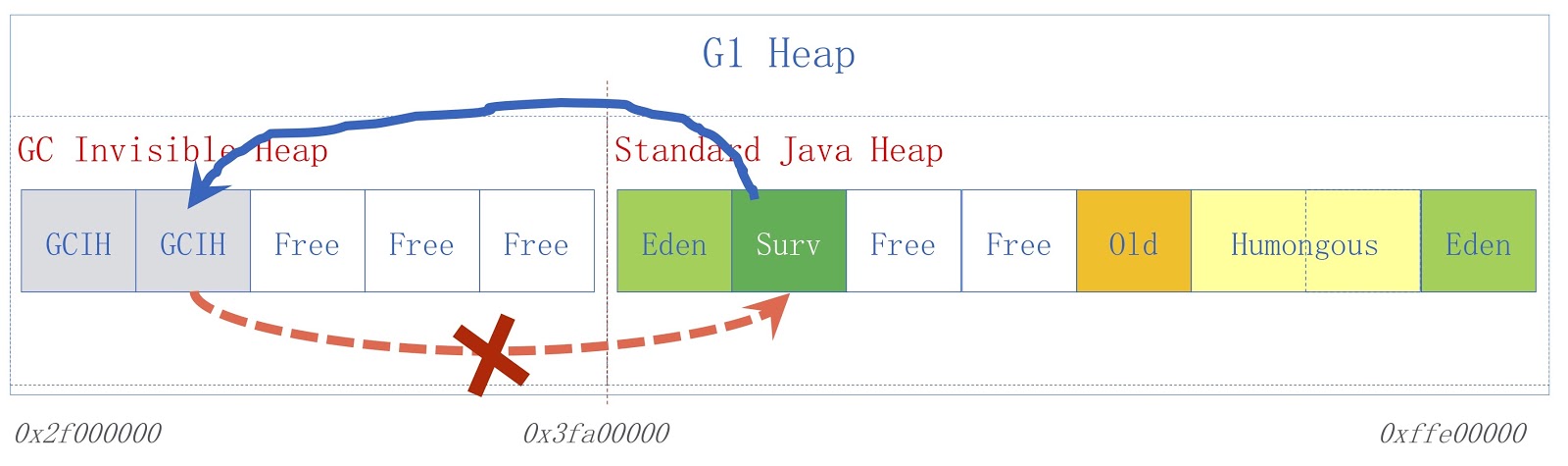
图片显示了高级GCIH方案。 右侧是常规Java堆,左侧是为GCIH分配的空间。 从常规堆到GCIH中的对象的链接有效,但从GCIH到常规堆的链接无效。 要了解为什么会这样,请考虑一个示例。 GCIH中有对象“ A”,它在常规堆中包含对对象“ B”的引用。 问题是垃圾收集器可以移动对象B。 正如我已经说过的,我们不会在GCIH中进行更新,因此在垃圾收集器工作之后,对象“ A”可能包含对对象“ B”的无效引用。 可以使用预写障碍来解决此问题-在先前的报告中已讨论了它们。 例如,假设有人需要保存从常规Java堆到GCIH的链接,然后我们假设保存将导致带有指示符标志的违反规则的预测器异常。
对于特定的应用程序,我们的淘宝个性化平台(简称TPP)中使用了多租户JVM。 这是针对我们的电子购物应用程序的推荐系统。 TPP可以在一个容器中部署多个微服务,借助多租户JVM,我们可以控制提供给每个微服务的内存和CPU时间。
至于GCIH,它在我们的其他系统UM平台中使用。 这是一个在线折扣应用程序。 该应用程序的所有者使用GCIH在本地计算机上预缓存GCIH数据,以便不访问远程缓存服务器或远程数据库上的对象。 结果,我们减轻了网络负载,并减少了序列化和反序列化。
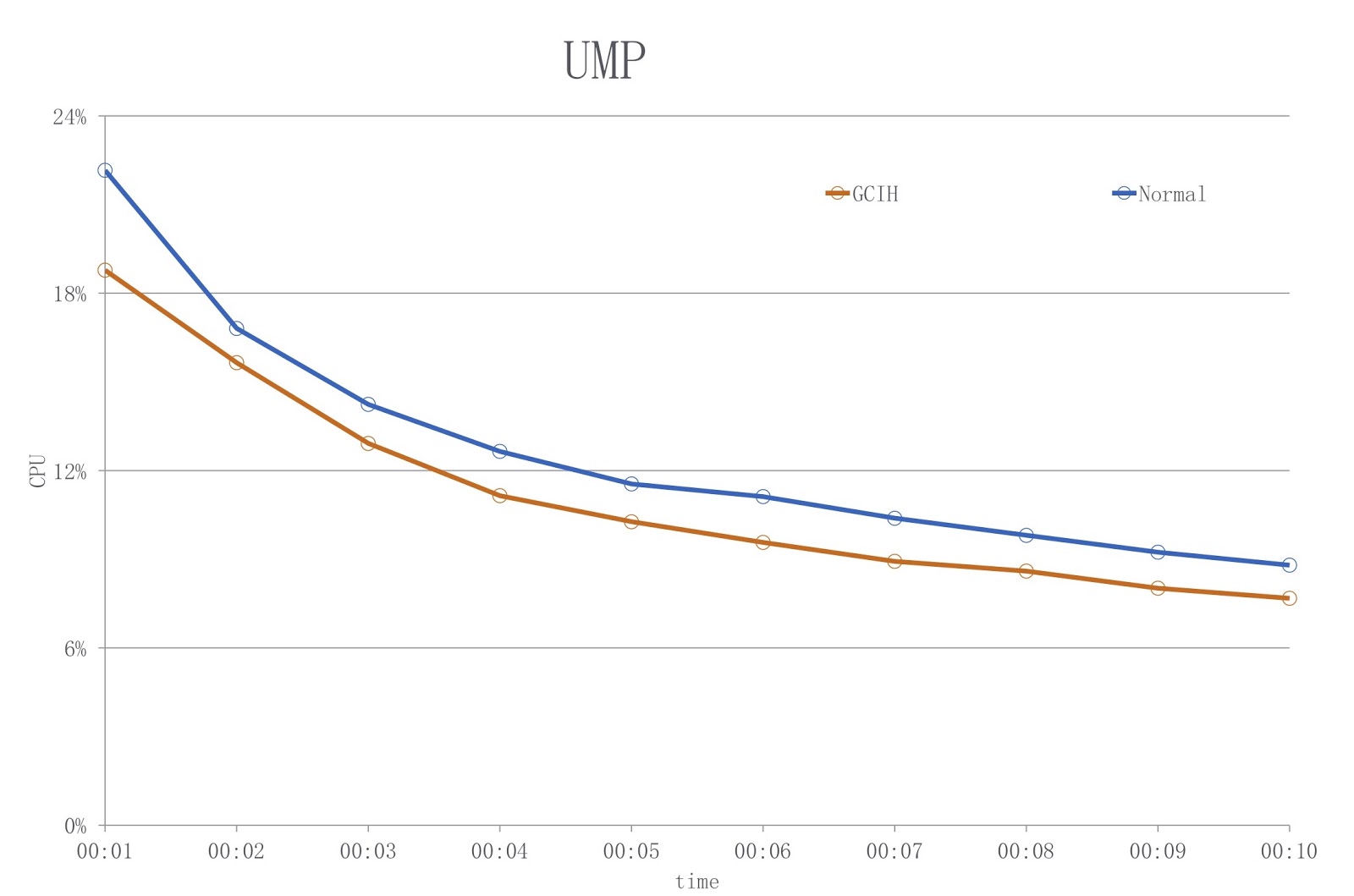
该图显示了一个示意图,其中蓝色表示使用常规JDK时的负载,红色表示GCIH。 如您所见,我们将CPU利用率降低了18%以上。
据我所知, BellSoft解决了类似的问题,其解决方案与GCIH类似,但是他们使用了不同的方法来降低序列化和反序列化的成本。
Java协程
让我们回到阿里巴巴,看看如何在Java中实现协程。 但是首先,让我们谈谈起源,以及为什么我们需要这样做。 在Java中,编写多线程应用程序总是非常容易的。 但是创建此类应用程序的问题在于,正如我所说,在Hotspot中,Java线程已经实现为本机线程。 因此,当您的应用程序中有很多线程时,更改线程上下文的成本变得很高。

考虑一个示例,其中我们将具有4个I / O线程和200个线程以及您的应用程序逻辑。 屏幕上的表格显示了启动此简单演示的结果-您可以看到CPU更改上下文所花费的时间。 解决此问题的方法可能是用Java实现corutin。
要提供它,我们需要两件事。 首先,阿里巴巴JDK需要添加延续支持。 这项工作基于JKU补丁,我们将对其进行详细介绍。 其次,我们添加了一个用户模式的sheduler,它将负责线程的继续。 第三,阿里巴巴有很多应用。 因此,我们的解决方案对于我们的Java开发人员非常重要,因此有必要使其对他们绝对透明。 这意味着在我们的业务应用程序中,代码实际上应该没有任何更改。 我们称我们的解决方案为Wisp。 我们在Java中实现的协程在Alibaba中得到了广泛使用,因此可以认为它已在Java中运行。 更详细地了解他。

让我们从上面的代码示例开始-这是一个完全普通的Java应用程序。 首先,创建一个线程池。 然后,创建另一个接受套接字的Runnable任务。 之后,执行从流的读取。 接下来,我们创建另一个Runnable任务,通过该任务连接到服务器,最后将数据写入流。 如您所见,一切看起来都很标准。 如果在常规JDK上运行代码,则这些Runnable任务中的每一个将在单独的线程中执行。 但是在我们的决定中,机制将完全不同。
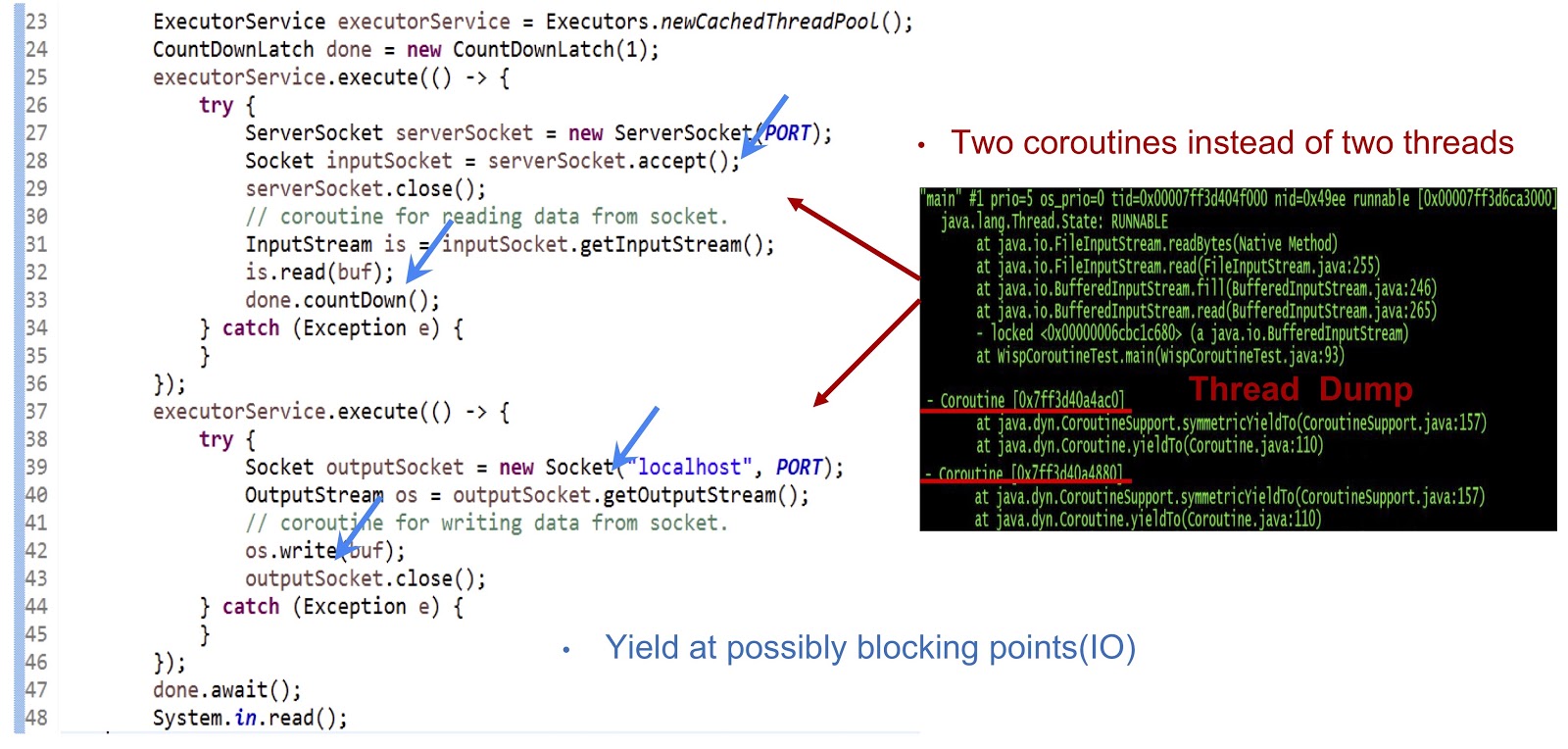
从幻灯片所示的转储中可以看到,我们在一个线程中创建了两个协程,而不是两个线程。 现在,您需要使此解决方案生效。 这里最主要的是使yieldTo事件在所有可能的阻塞点处生成。 在我们的示例中,这些点将是serverSocket.accept() , serverSocket.accept() is.read(buf) ,套接字连接和os.write(buf) 。 由于在这些位置产生了收益事件,我们将能够在同一线程内将控制权从一个协程转移到另一个协程。 总而言之,我们的方法是使用协程实现异步性能,但是我们的程序员可以以同步方式编写代码,因为此类代码更加简单,并且易于维护和调试。
让我们确切地看一下我们如何在阿里巴巴JDK中提供继续支持。 正如我所说,这项工作基于社区创建的多语言虚拟机项目-它是在公共领域中。 我们在阿里巴巴JDK中使用了此补丁,并修复了在生产环境中发生的一些错误。
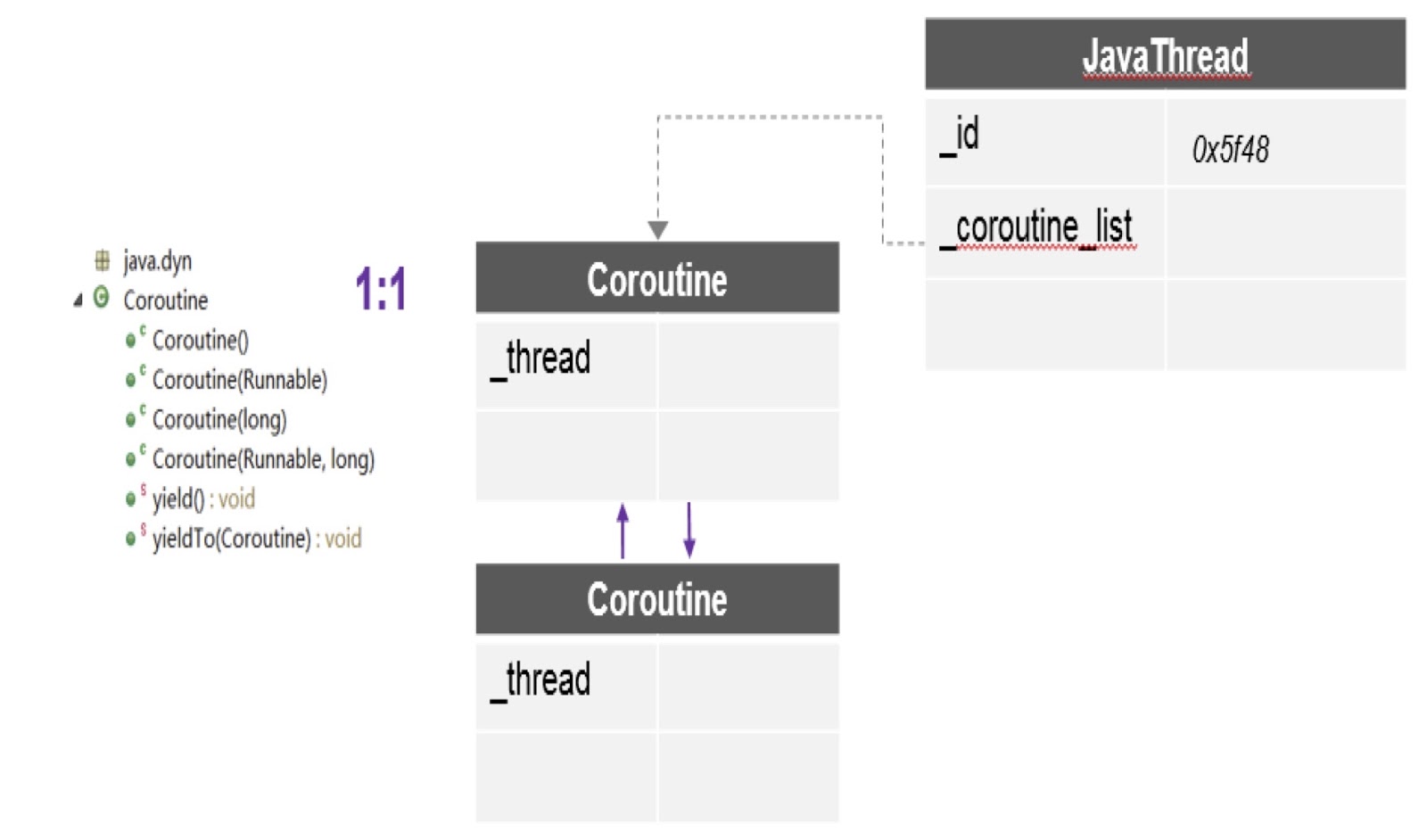
从图中可以看出,在一个线程中可以有多个协程,并且为每个协程创建一个单独的堆栈。 另外,我所讨论的补丁在这里为我们提供了最重要的API-yieldTo,并借助该API将控制权从一个协程转移到另一个协程。
让我们继续介绍如何为协程实现用户模式sheduler。 我们使用一个选择器,并用它注册几个通道。 当发生任何I / O事件(套接字读取,套接字写入,套接字连接或套接字接受)时,它将作为选择器的键写入。 因此,在此事件结束时,我们收到来自选择器的警报。 因此,在发生I / O锁定时,我们使用选择器来计划协程。 考虑一个如何工作的例子。
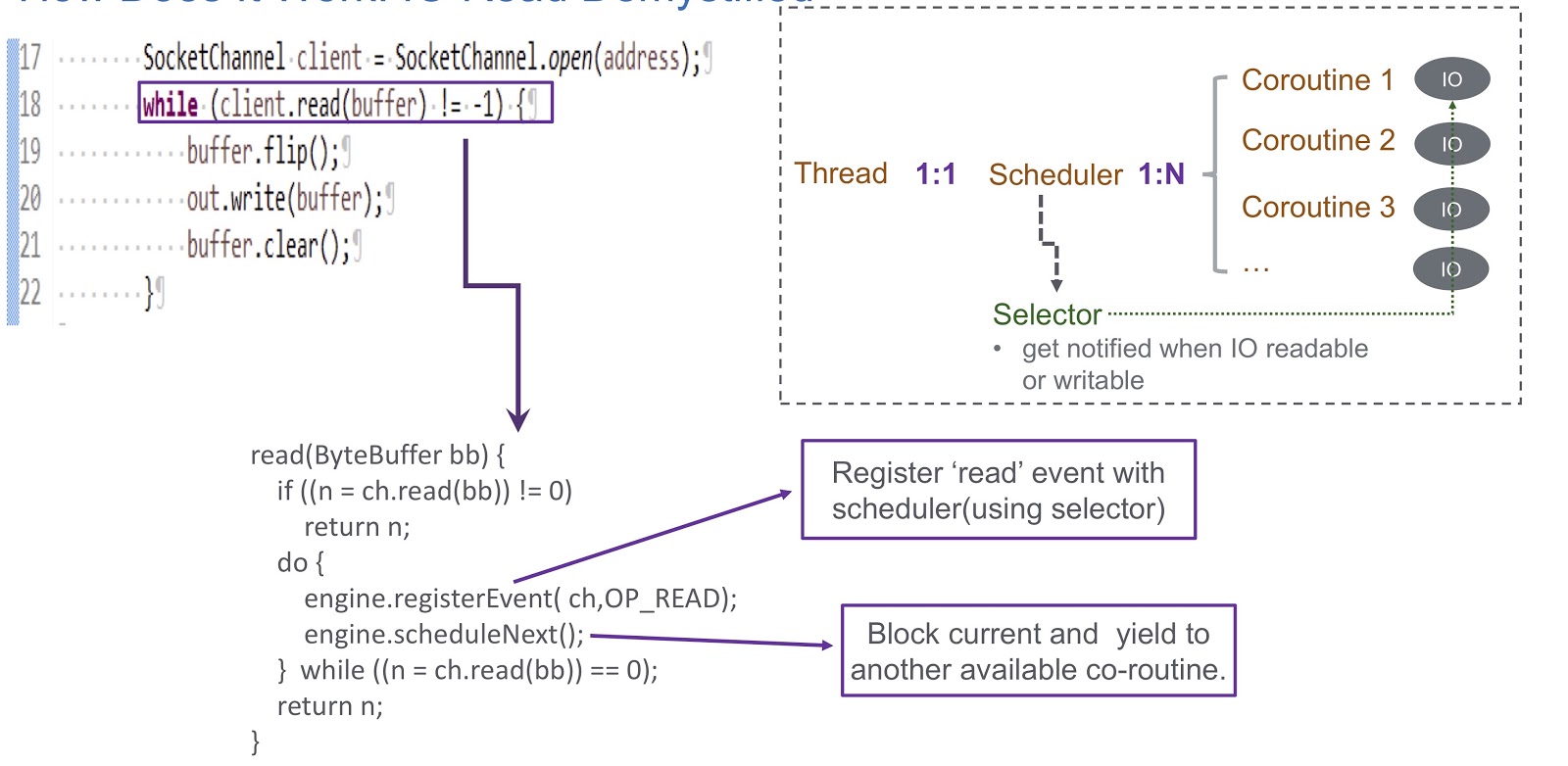
在图片中,我们看到了套接字和同步调用client.read(buffer) 。 在幻灯片的底部,编写了将在此调用内执行的代码。 首先,它检查是否可以从通道读取。 如果是这样,那么我们返回结果。 如果无法阅读,则会发生最有趣的事情。 然后,我们使用选择器在我们的调度程序中注册读取事件。 这使得可以计划其他协程的执行。 看看这是怎么发生的。 我们有一个在其中创建调度程序的线程。 线程和我们的协程彼此一一对应。 Sheduler允许我们管理此线程的协程。 如果I / O被阻止怎么办? 当发生I / O事件时,Sheduler会收到警报,在这种情况下,他完全依赖选择器。 在这样的事件之后,sheduler有机会计划下一个可用的协程。
让我们总结一下我们的Sheduler(称为WispEngine)的概述。 对于每个线程,我们分配一个单独的WispEngine。 当协程锁发生时,我们使用WispEngine记录某些事件(套接字读取/写入等)。 某些事件与线程thread.sleep()有关,例如,如果您以100毫秒的延迟调用thread.sleep() 。 在这种情况下,将为您生成线程驻留事件,然后将其注册到选择器中。 另一个重要的问题是当Sheduler任命下一个可用协程时。 有两个主要条件。 第一个是生成某些事件(例如I / O事件或超时事件)的时间。 这里的一切都非常简单:假设您以200毫秒的延迟调用thread.sleep() 。 当它们过期时,sheduler有机会执行下一个可用的协程。 或者在这里我们可以讨论一些通过调用object.notify()或object.notifyAll()生成的拆包事件。第二个条件是用户提交新请求时,我们创建了一个协程以服务这些请求,然后由sheduler分配它的实现。
在这里,您还需要说明一下我们创建的服务WispThreadExecutor。

屏幕上显示了一个示例代码,我们看到这是一个常规的ExecutorService,以相同的方式创建。 .execute()和.execute()方法可用于Runnable任务,但是问题在于,所有通过Submit submit()方法传递的Runnable任务都将在corutin中执行,而不是在线程中执行。 对于将实施我们的应用程序的人来说,该解决方案是完全透明的,他们将能够使用我们的API进行协程。

我谈到了文章的最后一个困难部分-如何解决协程中的同步问题。 这是一个复杂的问题,所以让我们用一个简化的例子来看看。 在这里,我们有协程A( test::foo )和corutin test::bar )。 首先,我们将test:foo的执行分配给协程wait() 。 如果不执行任何操作,则当前线程将被wait()调用阻塞。 从该线程的转储中可以看出,将发生死锁,并且我们将无法安排要执行的下一个协程。
如何解决这个问题? 热点提供三种类型的锁。 首先是快速锁定。 在这里,锁的所有者由堆栈上的地址确定。 正如我所说,我们的每个协程都有单独的堆栈。 因此,在快速锁定的情况下,我们不需要执行任何其他工作。 我们的系统中没有类似的支持偏向锁定。 我们在生产中进行了尝试,结果表明,在没有偏向锁的情况下,性能不会下降。 对我们来说,这是非常合适的。
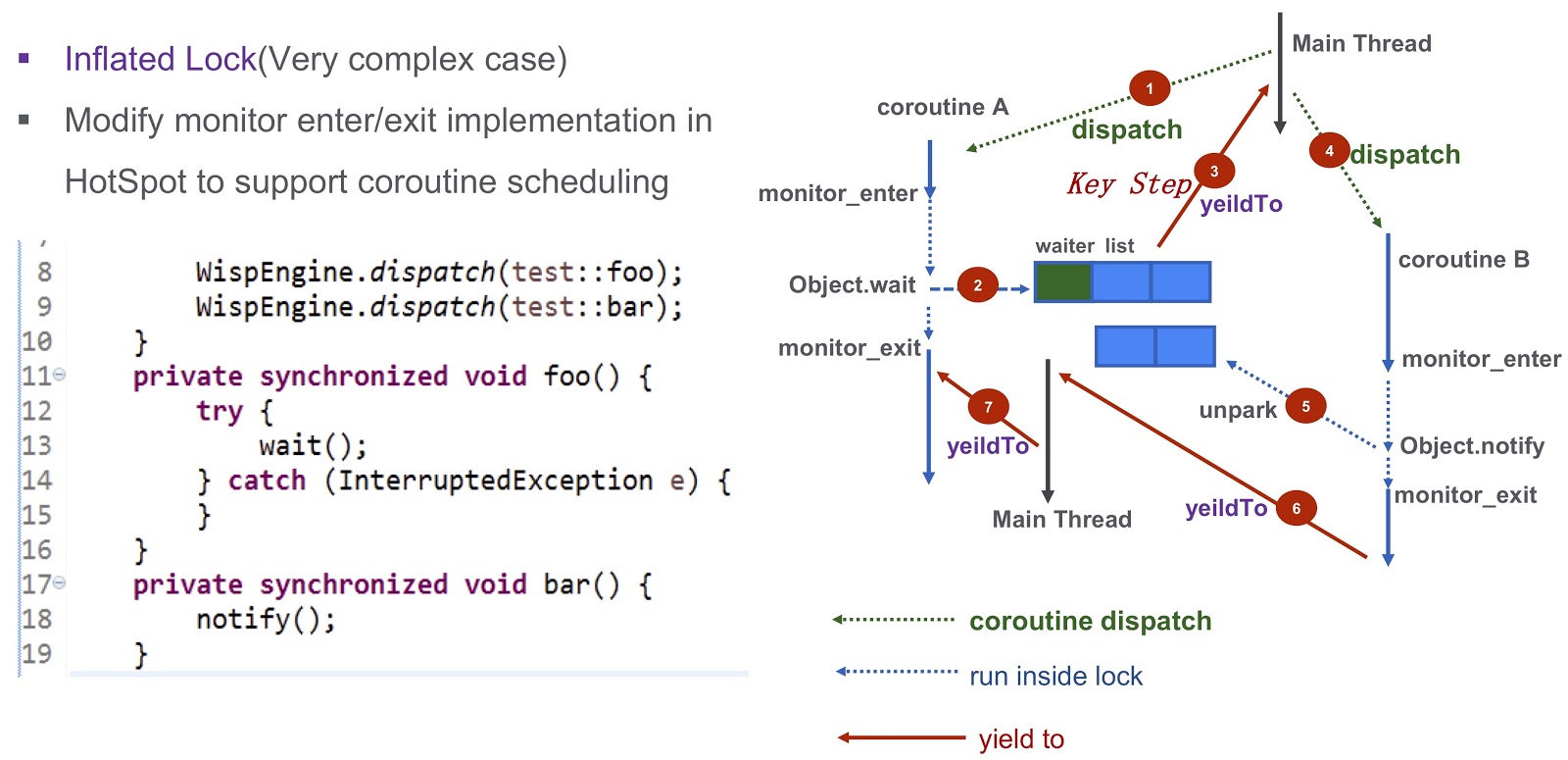
让我们来讨论一个更复杂的情况-膨胀锁。 让我们再次看一下我上面引用的示例。 我们有Corutin .foo() )和Corutin B ( .bar() )。 首先,我们指定协程Object.wait ,之后进入等待列表。 之后,我们采取了非常重要的步骤:我们生成yieldTo事件,该事件会将控制权转移到主线程。 接下来,我们启动CorutinB B 它调用Object.notify ,并unpark相应的Object.notify事件。 他们最终将唤醒协程bar()的执行bar() ,可以将控制权转移到协程
让我们现在讨论性能。 我们在Carts在线应用程序之一中使用协程。 基于此,我们可以将corutin的工作与普通JDK的工作进行比较。
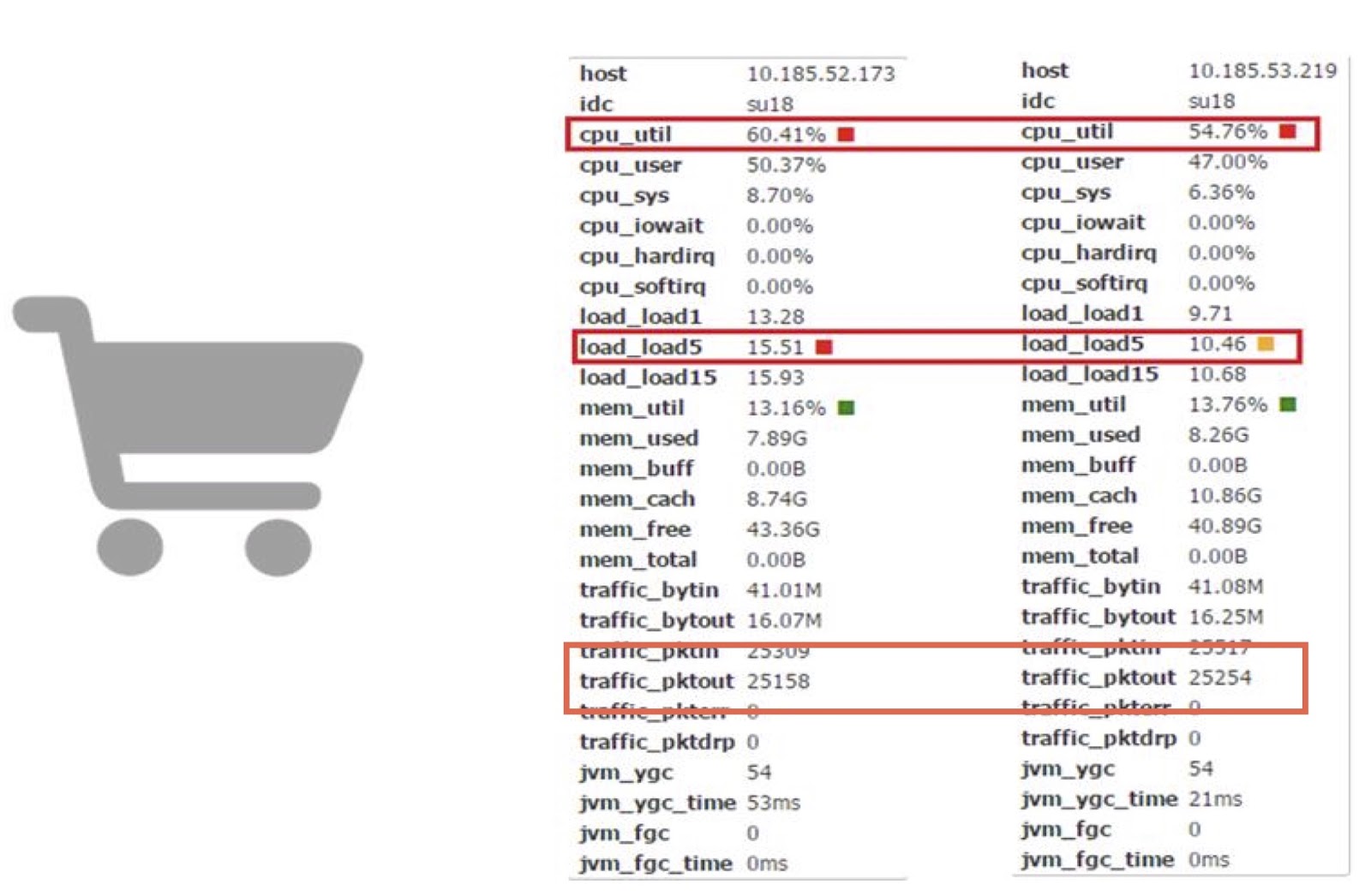
如您所见,它们使我们可以将处理器时间消耗减少近10%。 我知道你们中的大多数人很可能没有能力直接对JDK代码进行如此复杂的更改。 但我认为,这里的主要结论是,如果性能损失要花钱,而产生的损失也足够大,则可以尝试使用协程库来提高性能。
Jarmarm
让我们继续其他工具-JWarmup。 它与另一个工具ReadyNow非常相似。 众所周知,在Java中有一个预热问题-此阶段的编译器需要更多的CPU周期。 这给我们带来了问题-例如,发生了超时错误。 在扩展时,这些问题只会恶化,在我们的案例中,我们所谈论的是非常复杂的应用程序-超过2万个类和5万多个方法。
在开始使用JWarmup之前,我们的应用程序所有者使用模拟数据进行预热。 根据此数据,JIT编译器在收到请求之前进行了预编译。 但是模拟的数据与实际的数据不同;因此,对于编译器而言,它并不具有代表性。 在某些情况下,会发生意外的优化不足,从而降低性能。 解决此问题的方法是JWarmup。 他有两个主要的工作阶段-记录和汇编。 阿里巴巴有两种类型的环境,即beta和生产环境。 两者都接收到来自用户的真实请求,然后在这两个环境中部署相同版本的应用程序。 在beta环境中,仅收集概要分析数据,然后在此基础上进行生产中的初步编译。

让我们更详细地了解我们收集什么样的信息。 我们需要准确记下要初始化的类,要编译的方法,然后将这些数据刷新到硬盘驱动器上的日志中,编译器可以访问该日志。 最困难的时刻是类的初始化。 . — Bar Foo.test() , foo.count . , .
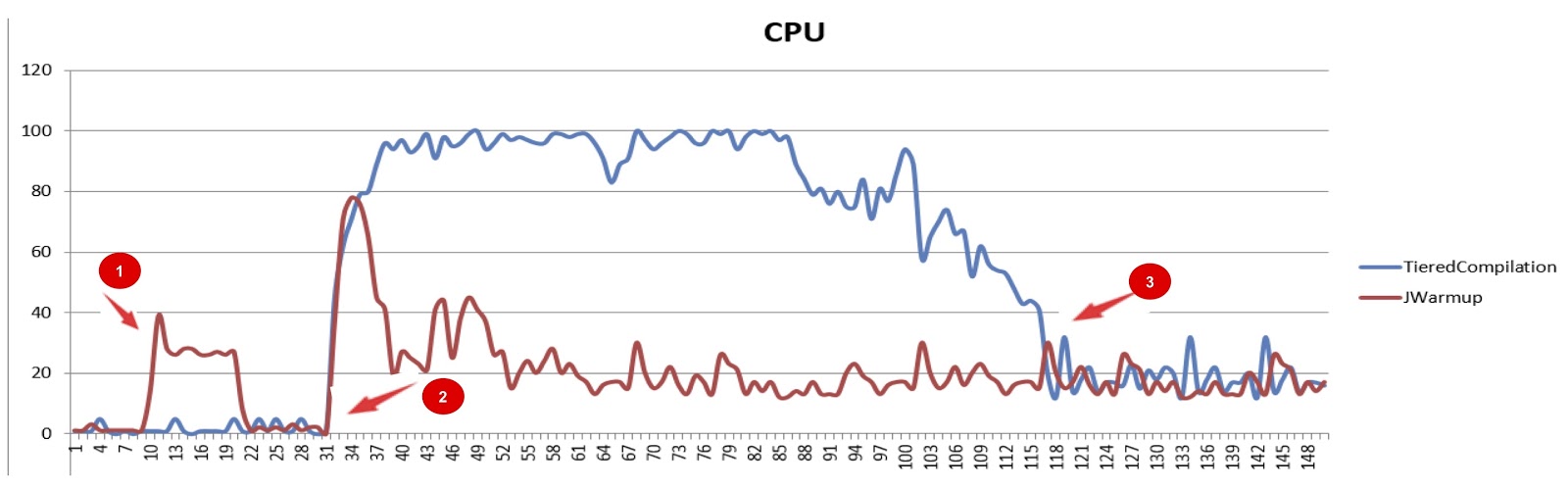
JWarmup (tiered compilation), . , — CPU. JWarmup , CPU, JDK. , , JDK. , , .
JWarmup. , , , groovy-, Java-, . . , , «null check elimination». . , JWarmup , JWarmup, .
, Alibaba.
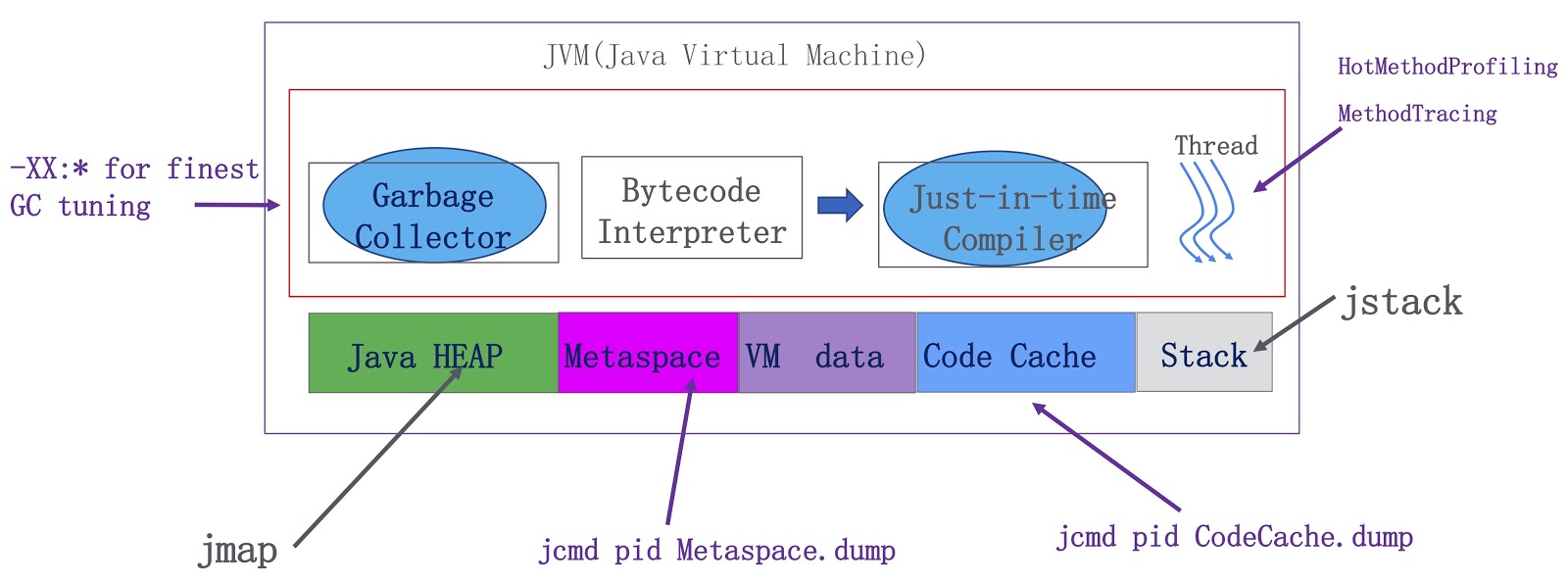
. JVM — , , . Java-, metaspace, VM ( VM) JIT-. OpenJDK. -, , . -, . HotMethodProfiling, , CPU. , , Honest Profiler , , , HotMethodProfiling. MethodTracing. , , . , metaspace . Java-, . metaspace , . Java.
, , ZProfiler.
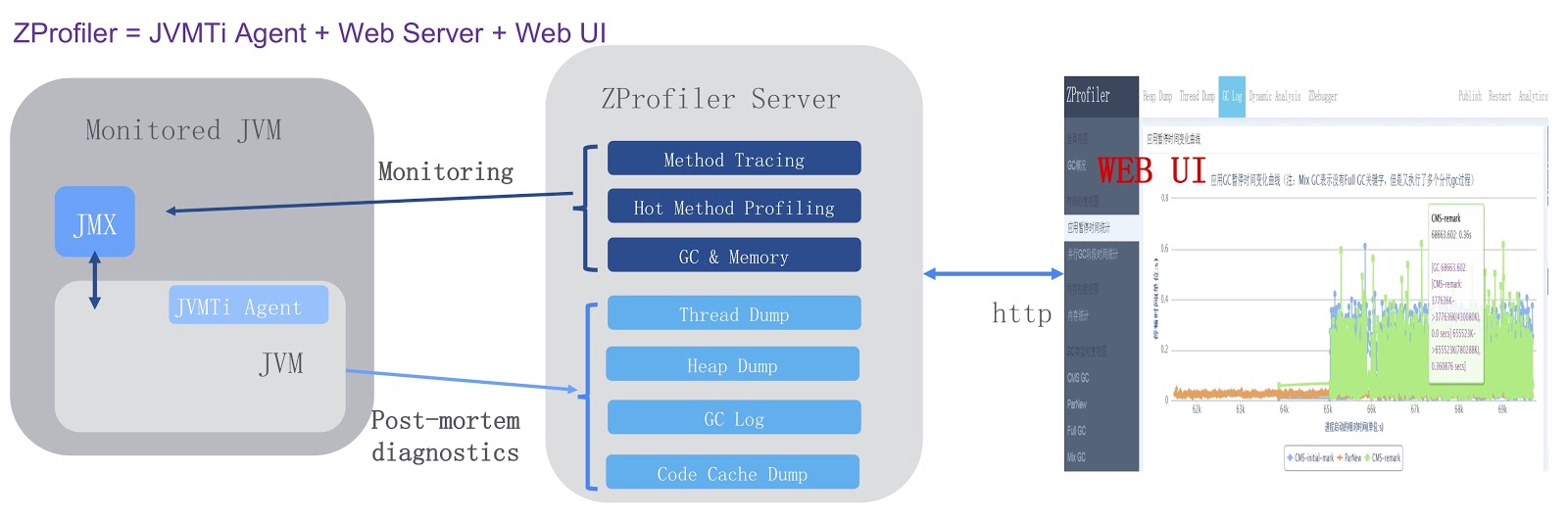
. JVMTi, JVM ( ). , ZProfiler Apache Tomcat. -. ZProfiler JVM. , ZProfiler -UI, . ZProfiler . -, UI JVM. -, ZProfiler post-mortem . , OutOfMemoryError, , JVM ZProfiler, . , , , Eclipse MAT.
. . JVM, GCIH, Alibaba JDK, JWarmup — , ReadyNow Zing JVM. , ZProfiler. , , OpenJDK. , , JWarmup OpenJDK. , OpenJDK Loom, Java. , .
. , , JPoint 2018 . 2019 , JPoint , 5-6 . , Rafael Winterhalter Sebastian Daschner. . , YouTube . JPoint!