
《卫报》是英国最大的报纸之一,成立于1821年。 在将近200年的历史中,档案馆已积累了可观的数量。 幸运的是,在过去的几十年中,并非所有内容都存储在网站上。 该数据库被英国人称为所有在线内容的“真理之源”,包含约230万个元素。 一方面,他们意识到从Mongo迁移到Postgres SQL的需要-在2015年7月的一个炎热的日子之后,对故障转移过程进行了严格的测试。 迁移花了将近3年!
我们翻译
了一篇文章 ,描述了迁移过程如何进行以及管理员面临的困难。 这个过程很漫长,但是总结很简单:完成大任务,调和错误是必要的。 但最终,三年后,英国同事设法庆祝了移民的结束。 睡吧
第一部分:开始
在Guardian,大多数内容(包括文章,博客,图片库和视频)都是在我们自己的CMS Composer中制作的。 直到最近,Composer仍与基于AWS的Mongo DB合作。 该数据库实质上是所有《卫报》在线内容的“真理之源”-约230万个元素。 我们刚刚完成了从Mongo到Postgres SQL的迁移。
Composer及其数据库最初托管在Guardian Cloud中,Guardian Cloud是我们位于Kings Cross附近办公室地下室的数据中心,并在伦敦其他地方进行了故障转移。
2015年的一个
炎热的日子,我们的故障转移程序经受了相当严格的测试。
 热度:适合在喷泉边跳舞,对数据中心来说是灾难性的。 照片:莎拉·李/监护人
热度:适合在喷泉边跳舞,对数据中心来说是灾难性的。 照片:莎拉·李/监护人从那时起,Guardian迁移到AWS成为生死攸关的问题。 为了迁移到云,我们决定购买
OpsManager和Mongo DB管理软件,并签署了Mongo技术支持合同。 我们使用OpsManager来管理备份,编排和监视我们的数据库集群。
由于编辑方面的要求,我们需要在我们自己的AWS基础架构中启动数据库集群和OpsManager,而不要使用Mongo托管解决方案。 由于Mongo没有提供任何可在AWS上进行轻松配置的工具,我们不得不出汗:我们手动设计了整个基础架构,并编写了
数百个Ruby脚本来安装监视/自动化代理并编排新的数据库实例。 结果,我们不得不组织一个有关数据库管理的教育计划团队,这是我们希望OpsManager能够承担的责任。
自从过渡到AWS以来,由于数据库问题,我们发生了两次严重的崩溃,每一次崩溃都至少一个小时不允许在theguardian.com上发布。 在这两种情况下,OpsManager或Mongo技术支持人员都无法为我们提供足够的帮助,而且我们自己解决了问题-在一个案例中,这要归功于
我们团队的一名
成员设法通过电话从阿布扎比郊区的沙漠中处理了这一情况。
每个有问题的问题都应单独发表,但这是要点:
- 请密切注意时间-不要在无法停止NTP的程度上阻止对VPC的访问。
- 在应用程序启动时自动创建数据库索引不是一个好主意。
- 数据库管理非常重要和困难-我们不想自己做。
OpsManager没有遵守其简单数据库管理的承诺。 例如,OpsManager本身的实际管理(尤其是从OpsManager版本1升级到版本2)需要大量时间,并且需要有关OpsManager设置的特殊知识。 由于在不同版本的Mongo DB之间的身份验证方案的更改,他也未能兑现“一键式更新”的承诺。 每年我们至少损失了两个月的工程师来管理数据库。
所有这些问题,再加上我们为支持合同和OpsManager支付的高额年费,迫使我们寻找具有以下特征的替代数据库选项:
- 尽力管理数据库。
- 静态加密。
- Mongo可接受的迁移路径。
由于我们所有其他服务都在运行AWS,因此显而易见的选择是Amazon的NoSQL数据库Dynamo。 不幸的是,当时Dynamo不支持静态加密。 在等待大约九个月的时间添加此功能之后,我们最终决定通过在AWS RDS上使用Postgres放弃了这一想法。
“但是Postgres不是文档存储库!” -您很愤慨...是的,这不是停靠库,但是它具有类似于JSONB列的表,并且支持JSON Blob工具字段中的索引。 我们希望使用JSONB能够在对数据模型进行最小更改的情况下从Mongo迁移到Postgres。 另外,如果我们将来想转向一个更具关系的模型,我们将有这样的机会。 Postgres的另一个优点是解决方案的效果如何:对于我们遇到的每个问题,大多数情况下,答案已经在Stack Overflow中给出了。
在性能方面,我们确信Postgres可以做到:Composer是专门用于记录内容的工具(每次记者停止打印时,它都会写入数据库),并且同时用户的数量通常不超过几百个-这不需要系统超大功率!
第二部分:二十年的内容迁移没有停机
计划大多数数据库迁移都意味着相同的操作,我们也不例外。 这是我们所做的:
- 创建一个新的数据库。
- 他们创建了一种写入新数据库(新API)的方法。
- 我们创建了一个代理服务器,该服务器使用旧的作为主要数据库,将流量发送到旧数据库和新数据库。
- 将记录从旧数据库移到新数据库。
- 他们将新数据库作为主要数据库。
- 删除了旧数据库。
鉴于我们迁移到的数据库提供了CMS的功能,因此至关重要的是,迁移对我们的记者造成的问题应尽可能少。 最后,新闻永无止境。
新API新的基于Postgres的API的工作于2017年7月结束。 这是我们旅程的开始。 但是为了了解它的状态,我们必须首先弄清楚我们从哪里开始。
我们简化的CMS体系结构是这样的:一个数据库,一个API和与之相关的多个应用程序(例如用户界面)。 该堆栈已构建,并且已经基于
Scala ,
Scalatra Framework和
Angular.js运行了4年。
经过分析,我们得出的结论是,在我们可以迁移现有内容之前,我们需要一种方法来联系新的PostgreSQL数据库,同时保持旧的API正常运行。 毕竟,Mongo DB是我们的“真理之源”。 在我们尝试新API的过程中,她充当了我们的生命线。
这就是为什么不在旧API上进行构建不属于我们计划的原因之一。 原始API中的功能分离极少,即使在控制器级别,也可以找到专门用于Mongo DB的特定方法。 结果,将另一种类型的数据库添加到现有API的任务太冒险了。
我们用另一种方法复制了旧的API。 因此诞生了APIV2。 它或多或少是与Mongo相关的旧API的精确副本,并包含相同的端点和功能。 我们使用了
doobie (Scala的纯JDBC功能层),添加了
Docker在本地运行和测试,并改进了操作日志记录和责任分担。 APIV2被认为是API的快速和现代版本。
截至2017年8月,我们已部署了一个新的API,使用PostgreSQL作为其数据库。 但这仅仅是开始。 Mongo DB中有一些文章是二十多年前首次创建的,它们都必须迁移到Postgres数据库。
迁移无论文章何时发布,我们都应该能够编辑该网站上的任何文章,因此所有文章都作为唯一的“真理来源”存在于我们的数据库中。
尽管所有文章都存储在
Guardian的Content API(CAPI)中 ,该
API为应用程序和站点提供服务,但是对于我们而言,无任何故障地迁移非常重要,因为我们的数据库是我们的“真理之源”。 如果Elasticsearch CAPI集群发生问题,我们将从Composer数据库对其重新编制索引。
因此,在禁用Mongo之前,我们必须确保对在Postgres上运行的API和在Mongo上运行的API的相同请求将返回相同的答案。
为此,我们需要将所有内容复制到新的Postgres数据库中。 这是通过使用脚本直接与新旧API交互来完成的。 这种方法的优势在于,与编写直接访问相应数据库的内容相反,这两个API已经提供了经过良好测试的接口,用于在数据库中读写文章。
基本迁移顺序如下:
- 从Mongo获取内容。
- 将内容发布到Postgres。
- 从Postgres获取内容。
- 确保它们的答案相同。
仅当最终用户没有注意到这种情况发生时,数据库迁移才能被视为成功,并且良好的迁移脚本将始终是成功的关键。 我们需要一个脚本,该脚本可以:
- 执行HTTP请求。
- 确保在迁移了某些内容之后,两个API的响应是相同的。
- 发生错误时停止。
- 创建详细的操作日志以诊断问题。
- 从正确的位置出现错误后,重新启动。
我们从使用
Ammonite开始。 它使您可以使用Scala语言编写脚本,这是我们团队的核心。 这是一个很好的机会,尝试我们以前从未使用过的东西,看看它是否对我们有用。 尽管Ammonite允许我们使用一种熟悉的语言,但我们在使用它时发现了一些缺点。 Intellij目前
支持 Ammonite,但在迁移过程中并没有这样做-我们丢失了自动补全和自动导入功能。 此外,很长一段时间以来,Ammonite脚本都无法运行。
最终,Ammonite并不是完成此工作的正确工具,而是我们使用sbt项目进行了迁移。 这样一来,我们就可以使用自己有信心的语言进行工作,并可以在主要工作环境中启动之前执行几次“测试迁移”。
出乎意料的是,它在检查Postgres上运行的API版本方面有多么有用。 我们发现了一些以前没有发现的难以发现的错误和有限的情况。
快进到2018年1月,是时候在我们的预生产CODE环境中测试全面的迁移了。
像我们的大多数系统一样,CODE和PROD之间的唯一相似之处在于正在启动的应用程序的版本。 支持CODE的AWS基础架构的功能远不及PROD强大,这仅仅是因为它获得的工作量要少得多。
我们希望在CODE环境中进行测试迁移可以帮助我们:
- 估计在PROD环境中迁移将花费多长时间。
- 评估迁移(如果有的话)如何影响生产力。
为了获得这些指标的准确度量,我们必须使两种环境完全相互对应。 这包括将Mongo DB备份从PROD还原到CODE,以及升级AWS支持的基础架构。
迁移超过200万个数据项所需的时间应比标准工作日所允许的时间长得多。 因此,我们在晚上在
屏幕上运行了脚本。
为了衡量迁移的进度,我们将结构化查询(使用令牌)发送到我们的ELK堆栈(Elasticsearch,Logstash和Kibana)。 在这里,我们可以通过跟踪成功传输的文章数,崩溃数和总体进度来创建详细的仪表板。 此外,所有指示器都显示在大屏幕上,以便整个团队可以看到详细信息。
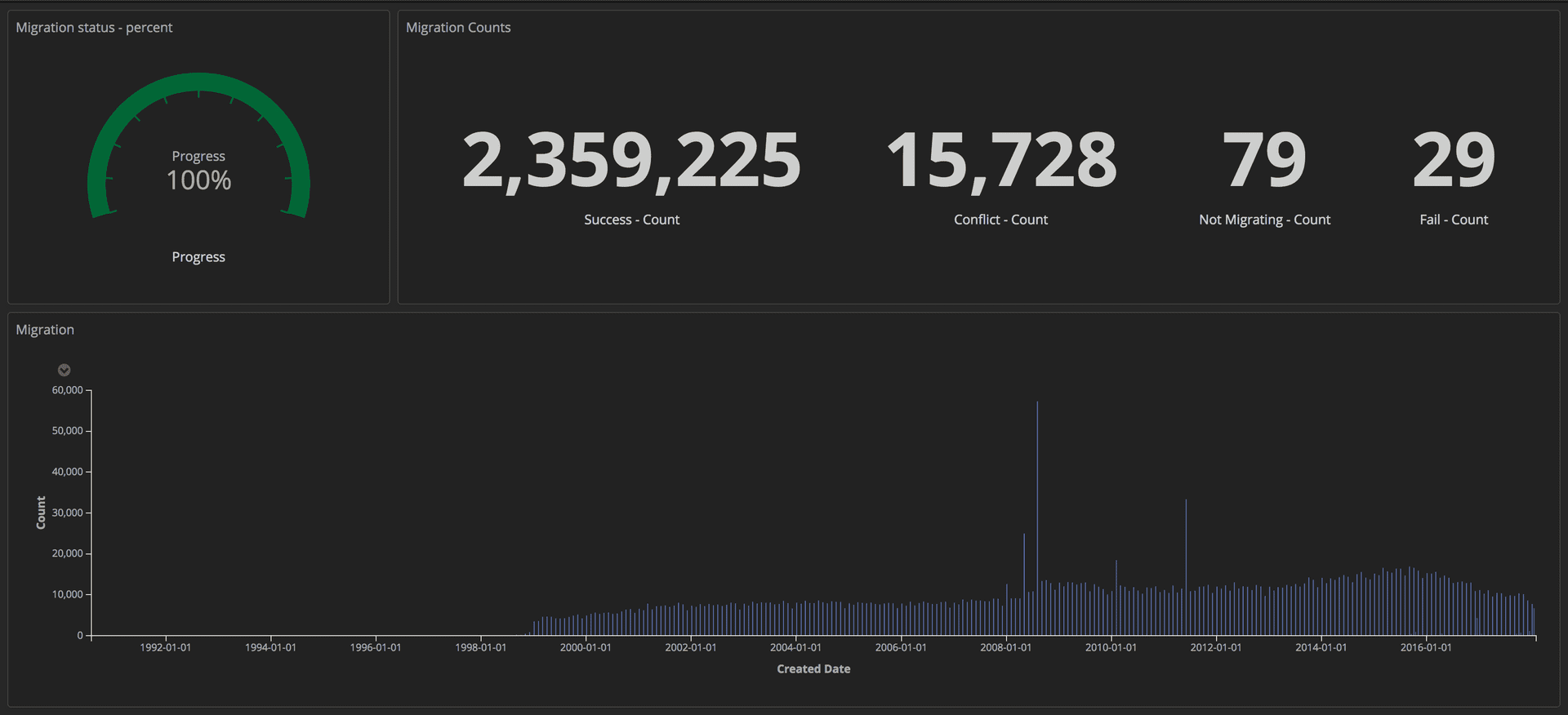 显示迁移进度的仪表板:编辑工具/《卫报》
显示迁移进度的仪表板:编辑工具/《卫报》迁移完成后,我们检查了Postgres和Mongo中每个文档的匹配情况。
第三部分:代理和在产品上发布
代理人现在已经启动了在Postgres上运行的新API,我们需要使用实际流量和数据访问模式对其进行测试,以确保其可靠性和稳定性。 有两种方法可以执行此操作:更新访问Mongo API的每个客户端,以便它可以访问两个API。 或运行可以为我们完成任务的代理。 我们使用
Akka Streams在Scala上编写代理。
代理非常简单:
- 从负载平衡器接收流量。
- 将流量重定向到主要API,反之亦然。
- 将相同流量异步转发到其他API。
- 计算两个答案之间的差异,并将其记录在日志中。
最初,代理记录了许多差异,其中包括需要修复的两个API中一些难以发现但重要的行为差异。
结构化日志在Guardian,我们使用
ELK堆栈(Elasticsearch,Logstash和Kibana)进行记录。 使用Kibana为我们提供了以最便捷的方式可视化杂志的机会。 Kibana使用
Lucene的查询语法 ,这很容易学习。 但是我们很快意识到,无法在当前设置中对日记帐分录进行过滤或分组。 例如,我们无法筛选出由于GET请求而发送的邮件。
我们决定将更多结构化数据发送给Kibana,而不仅仅是消息。 一个日志条目包含多个字段,例如,时间戳和发送请求的堆栈或应用程序的名称。 添加新字段非常容易。 这些结构化字段称为标记,可以使用
logstash-logback-encoder库实现。 对于每个请求,我们都提取了有用的信息(例如,路线,方法,状态代码),并创建了带有日志所需其他信息的地图。 这是一个例子:
import akka.http.scaladsl.model.HttpRequest import ch.qos.logback.classic.{Logger => LogbackLogger} import net.logstash.logback.marker.Markers import org.slf4j.{LoggerFactory, Logger => SLFLogger} import scala.collection.JavaConverters._ object Logging { val rootLogger: LogbackLogger = LoggerFactory.getLogger(SLFLogger.ROOT_LOGGER_NAME).asInstanceOf[LogbackLogger] private def setMarkers(request: HttpRequest) = { val markers = Map( "path" -> request.uri.path.toString(), "method" -> request.method.value ) Markers.appendEntries(markers.asJava) } def infoWithMarkers(message: String, akkaRequest: HttpRequest) = rootLogger.info(setMarkers(akkaRequest), message) }
日志中的其他字段使我们可以创建信息丰富的仪表板,并为差异添加更多上下文,这有助于我们识别这两个API之间的一些细微不一致。
流量复制和代理重构将内容传输到CODE数据库后,我们获得了PROD数据库的几乎完全相同的副本。 主要区别在于CODE没有流量。 为了将实际流量复制到CODE环境,我们使用了开源工具
GoReplay (以下
称为 gor)。 它非常容易安装,并且可以灵活地根据您的要求进行自定义。
由于所有进入我们的API的流量首先都流向了代理,因此在代理容器上安装gor很有意义。 参见下文,了解如何将gor加载到您的容器中以及如何开始监视端口80上的流量并将其发送到另一台服务器。
wget https://github.com/buger/goreplay/releases/download/v0.16.0.2/gor_0.16.0_x64.tar.gz tar -xzf gor_0.16.0_x64.tar.gz gor sudo gor --input-raw :80 --output-http http://apiv2.code.co.uk
一段时间后,一切正常,但很快,代理服务器在几分钟内变得不可用时出现了故障。 在分析中,我们发现所有三个代理容器都定期同时挂起。 起初,我们认为代理崩溃了,因为gor使用了太多资源。 在进一步分析AWS控制台后,我们发现代理容器会定期挂起,但不能同时挂起。
在进一步深入研究问题之前,我们试图找到一种运行gor的方法,但是这次没有给代理增加额外的负担。 该解决方案来自于Composer的辅助堆栈。 该堆栈仅在紧急情况下使用,我们的
工作监控工具会对其进行不断测试。 这次,从该堆栈到CODE的流量回放速度提高了两倍,没有任何问题。
新发现提出了许多问题。 代理是作为临时工具构建的,因此它可能不像其他应用程序那样经过精心设计。 此外,它是使用
Akka Http构建的,我们的团队都不熟悉。 该代码是凌乱的,充满了快速修复。 我们决定开始大量重构以提高可读性。 这次我们使用了for生成器,而不是之前使用的不断增长的嵌套逻辑。 并添加了更多的日志记录标记。
我们希望,如果我们深入研究系统内部发生的事情并简化其操作逻辑,就能够防止代理容器冻结。 但这没有用。 在尝试使代理服务器更可靠的两个星期后,我们感到受困。 有必要做出决定。 我们决定冒险,让代理保持原样,因为将时间花在迁移本身上比尝试修复一个月不需要的软件要好。 我们为该解决方案付费,但又出现了两次失败-每个失败将近两分钟-但必须完成。
快进到2018年3月,那时我们已经完成了向CODE的迁移,而没有牺牲API性能或CMS中的客户端体验。 现在我们可以开始考虑注销CODE中的代理了。
第一步是更改API的优先级,以便代理首先与Postgres进行交互。 如上所述,这是由设置更改决定的。 但是,有一个困难。
更新文档后,Composer将消息发送到Kinesis流。 仅需要一个API即可发送消息以防止重复。 为此,这些API在配置中具有一个标志:对于Mongo支持的API为true,对于受支持的Postgres为false。 仅更改代理以使其首先与Postgres交互是不够的,因为直到请求到达Mongo,消息才被发送到Kinesis流。 已经太久了。
为了解决此问题,我们创建了HTTP端点以即时动态更改负载均衡器所有实例的配置。 这使我们可以非常快速地连接主API,而无需编辑配置文件并重新部署。 另外,这可以自动化,从而减少了人机交互和错误的可能性。
现在,所有请求都首先发送到Postgres,并且API2与Kinesis进行了交互。 可以通过更改配置和重新部署使替换永久化。
下一步是完全删除代理,并强制客户端仅访问Postgres API。 由于我们有许多客户,因此不可能分别更新每个客户。 因此,我们将此任务提高到了DNS级别。 也就是说,我们在DNS中创建了一个CNAME,该CNAME首先指向ELB代理,然后将其更改为指向ELB API。 这允许进行单个更改,而不是更新每个单独的API客户端。
现在该移动PROD了。 虽然有点吓人,但是,因为这是主要的工作环境。 该过程相对简单,因为一切都是通过更改设置来决定的。 此外,由于在日志中添加了阶段标记,因此只需更新Kibana过滤器就可以重新配置先前构造的仪表板。
禁用代理和Mongo DB经过10个月和240万篇文章的迁移,我们终于能够禁用与Mongo相关的所有基础架构。 但是首先,我们必须做所有我们等待的事情:杀死代理。
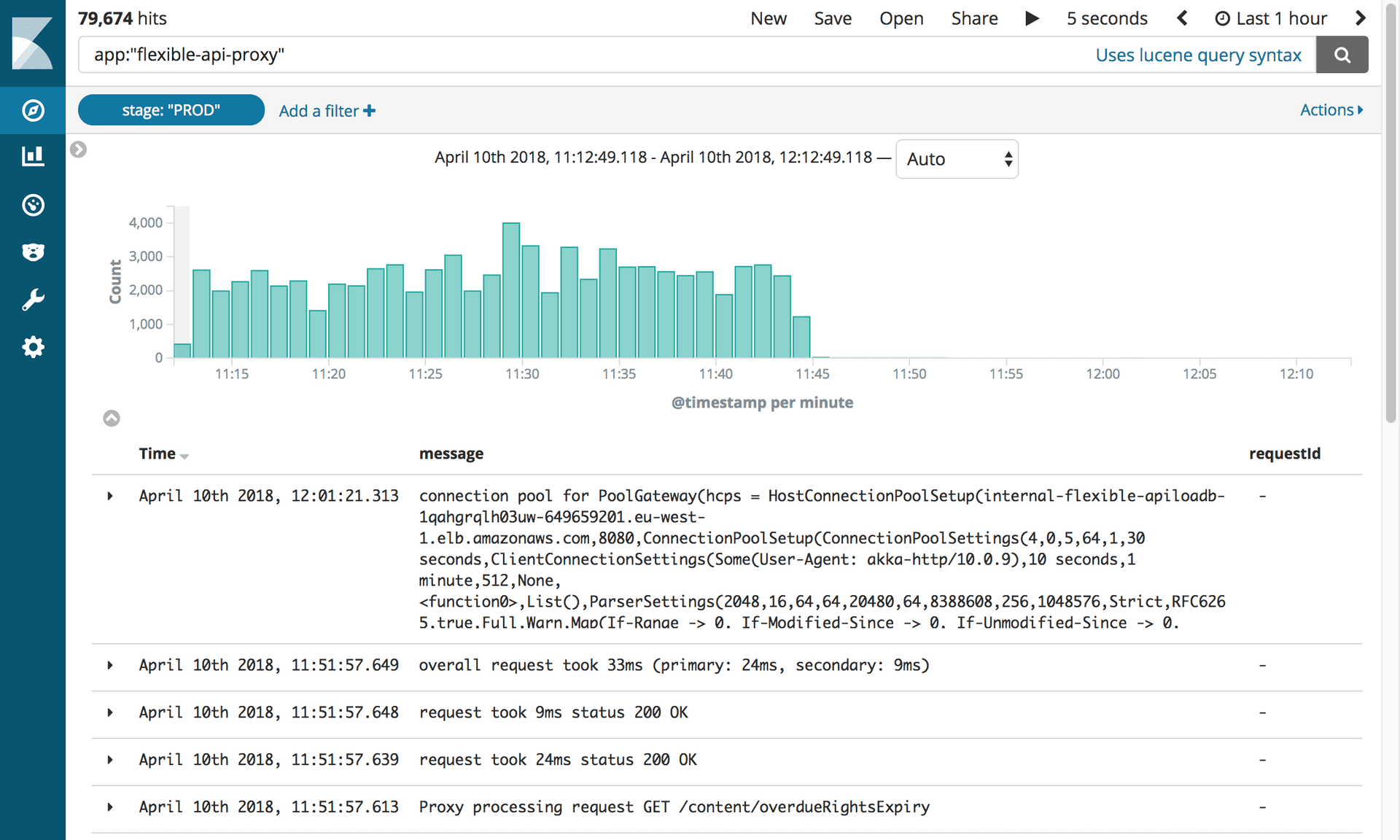 显示禁用Flex API代理的日志。 照片:社论工具/《卫报》
显示禁用Flex API代理的日志。 照片:社论工具/《卫报》这个小软件给我们带来了很多问题,我们渴望尽快将其断开连接! 我们要做的就是更新CNAME记录以直接指向APIV2负载平衡器。
整个团队聚集在一台计算机上。 仅需敲击一次即可。 大家屏住呼吸! 完全沉默...点击! 工作完成了。 没有飞! 我们都快乐地呼气。
但是,删除旧的Mongo DB API充满了另一项测试。 迫切希望删除旧代码,我们发现集成测试从未调整为使用新API。 一切很快变成红色。 幸运的是,大多数问题都与配置有关,我们很容易解决了这些问题。 测试发现了PostgreSQL查询的一些问题。 考虑如何避免这种错误,我们吸取了一个教训:开始一项大任务时,要调和会出错。
在那之后,一切顺利。 我们从OpsManager断开了Mongo的所有实例,然后断开了它们。 剩下要做的就是庆祝。 睡吧