我是Miro(前RealtimeBoard)的首席DevOps工程师。 我将分享我们的DevOps团队如何解决整体式有状态应用程序的每日服务器发布问题,并使它们自动化,对用户不可见以及对自己的开发人员方便。
我们的基础设施
我们的开发团队有60个人,分为Scrum团队,其中还包括DevOps团队。 大多数Scrum命令支持该产品的当前功能,并提供新功能。 DevOps的任务是创建和维护基础架构,以帮助应用程序快速可靠地运行,并允许团队快速向用户交付新功能。

我们的应用程序是一个无休止的在线留言板。 它由三层组成:Java中的站点,客户端和服务器,这是一个整体的有状态应用程序。 该应用程序与客户端保持恒定的Web套接字连接,每个服务器在内存中保留打开的板的缓存。
整个基础设施-超过70台服务器-位于亚马逊地区:超过30台带有我们的Java应用程序的服务器,Web服务器,数据库服务器,代理等等。 随着功能的增长,所有这些必须定期更新,而又不影响用户的工作。
更新站点和客户端很简单:我们将旧版本替换为新版本,并且下次用户访问新站点和新客户端时。 但是,如果在释放服务器时执行此操作,则会导致停机。 对于我们来说,这是不可接受的,因为我们产品的主要价值在于实时用户的共同努力。
我们的CI / CD流程看起来如何
与我们一起进行的CI / CD流程是git commit,git push,然后自动组装,自动测试,部署,发布和监视。
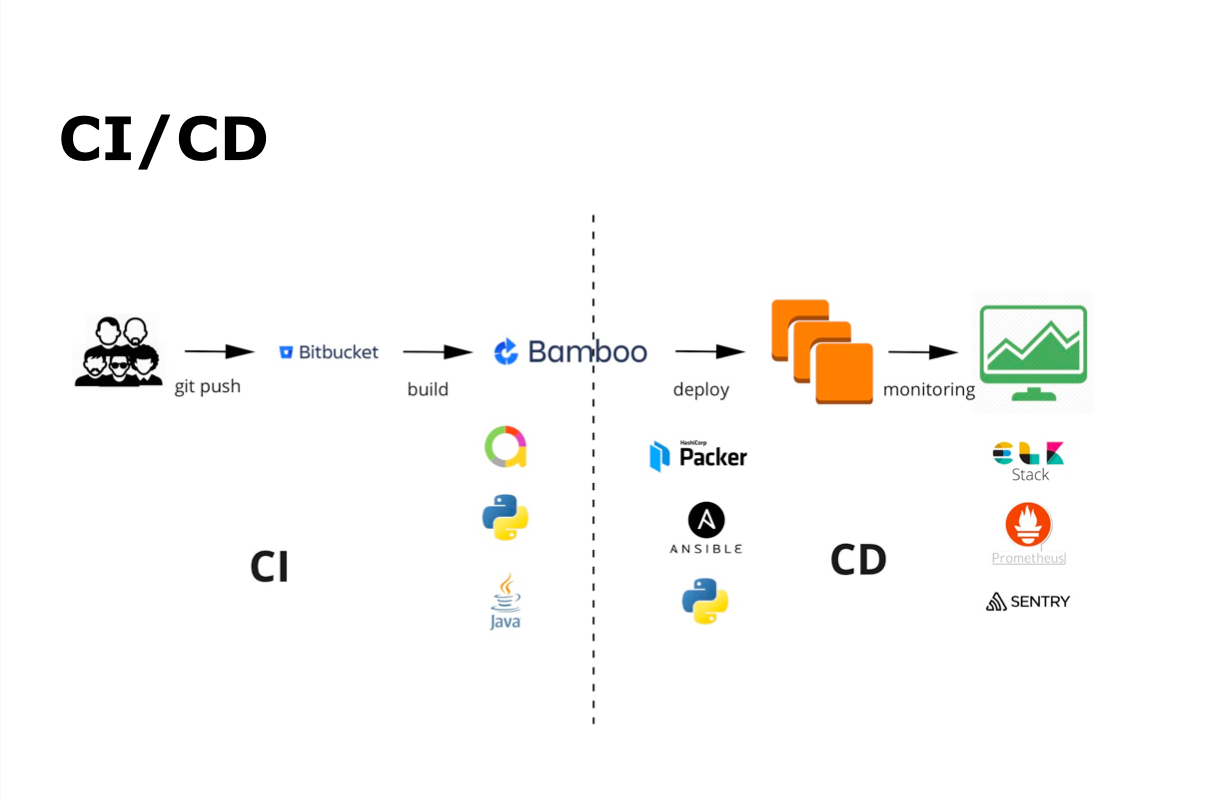
为了进行持续集成,我们使用Bamboo和Bitbucket。 对于自动测试-Java和Python,以及Allure-显示自动测试的结果。 对于连续交付-Packer,Ansible和Python。 使用ELK Stack,Prometheus和Sentry进行所有监视。
开发人员编写代码,将其添加到存储库中,然后启动自动组装和自动测试。 同时,团队内部从其他开发人员那里收集并进行代码审查。 完成所有必需的过程(包括自动测试)后,团队将构建保留在主分支中,然后开始构建主分支并将其发送以进行自动测试。 整个过程由团队自行调试和执行。
AMI图片
在构建构建和测试的同时,开始为Amazon构建AMI映像。 为此,我们使用HashiCorp的Packer,这是一个出色的开源工具,可用于构建虚拟机的映像。 所有参数都通过一组配置键传递给JSON。 主要参数是builders,它指示我们正在为哪个提供程序创建映像(在本例中为Amazon)。
"builders": [{ "type": "amazon-ebs", "access_key": "{{user `aws_access_key`}}", "secret_key": "{{user `aws_secret_key`}}", "region": "{{user `aws_region`}}", "vpc_id": "{{user `aws_vpc`}}", "subnet_id": "{{user `aws_subnet`}}", "tags": { "releaseVersion": "{{user `release_version`}}" }, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ami_name": "packer-board-ami_{{isotime \"2006-01-02_15-04\"}}" }],
重要的是,我们不仅要创建虚拟机的映像,还要使用Ansible对其进行预先配置:安装必要的程序包并进行配置设置以运行Java应用程序。
"provisioners": [{ "type": "ansible", "playbook_file": "./playbook.yml", "user": "ubuntu", "host_alias": "default", "extra_arguments": ["--extra_vars=vars"], "ansible_env_vars": ["ANSIBLE_HOST_KEY_CHECKING=False", "ANSIBLE_NOCOLOR=True"] }]
Ansible角色
我们曾经使用通常的Ansible剧本,但是这导致了很多重复的代码,因此很难及时更新。 我们在一本剧本中更改了某些内容,却忘了在另一本剧本中进行了更改,结果遇到了问题。 因此,我们开始使用Ansible-roles。 我们使它们尽可能通用,以便我们可以在项目的不同部分中重复使用它们,而不会在大型重复片段中使代码过载。 例如,我们对所有类型的服务器使用“监视”角色。
- name: Install all board dependencies hosts: all user: ubuntu become: yes roles: - java - nginx - board-application - ssl-certificates - monitoring
从Scrum团队的角度来看,此过程看起来尽可能简单:团队在Slack中收到有关构建和AMI映像已组装的通知。
预发行
我们引入了预发布版本,以尽快将产品更改交付给用户。 实际上,这些是金丝雀版本,使您可以对一小部分用户安全地测试新功能。
为什么将发布称为Canary? 以前,矿工进入矿山时就随身带着金丝雀。 如果矿井中有瓦斯,金丝雀就死了,矿工们迅速站起来。 我们也是如此:如果服务器出了点问题,则说明发布尚未准备就绪,我们可以快速回滚,并且大多数用户不会注意到任何事情。
金丝雀发布的开始方式:- Bamboo的开发团队单击一个按钮->称为Python应用程序,它将启动预发布版本。
- 它将使用预先准备的AMI映像和新版本的应用程序在Amazon中创建新实例。
- 将实例添加到必要的目标组和负载平衡器。
- 使用Ansible,可以为每个实例配置单独的配置。
- 用户正在使用Java应用程序的新版本。
在Scrum命令的一侧,预发布启动过程看起来又尽可能简单:团队在Slack中收到有关该过程已开始的通知,并且7分钟后新服务器已在运行。 此外,应用程序将发行版本中的更改的整个更改日志发送到Slack。
为了使这种保护和可靠性检查障碍发挥作用,Scrum团队会监视Sentry中的新错误。 这是一个实时的开源错误跟踪应用程序。 Sentry与Java无缝集成,并具有带logback和log2j的连接器。 当应用程序启动时,我们将运行它的版本转移到Sentry,当发生错误时,我们查看它在哪个版本的应用程序中发生。 这有助于Scrum团队快速响应错误并快速修复错误。
预发布版本至少应运行4个小时。 在此期间,团队将监视其工作并决定是否向所有用户发布该版本。
几个团队可以同时发布他们的版本 。 为此,他们彼此同意预发行版中的内容以及谁负责最终发行。 之后,团队将所有更改合并到一个预发布版本中,或者同时启动多个预发布版本。 如果所有预发行版本均正确,则它们将在第二天作为一个发行版本发行。
发布
我们每天发布:
- 我们推出了新的服务器。
- 我们使用Prometheus监视新服务器上的用户活动。
- 关闭新用户对旧服务器的访问。
- 我们将用户从旧服务器转移到新服务器。
- 关闭旧服务器。
一切都使用Bamboo和Python应用程序构建。 该应用程序检查正在运行的服务器的数量,并准备启动相同数量的新服务器。 如果没有足够的服务器,则从AMI映像创建它们。 在它们上部署了新版本,启动了Java应用程序,并使服务器投入运行。
监视时,使用Prometheus API的Python应用程序将检查新服务器上打开的板的数量。 当了解到一切正常后,它将关闭对旧服务器的访问,并将用户转移到新服务器。
import requests PROMETHEUS_URL = 'https://prometheus' def get_spaces_count(): boards = {} try: params = { 'query': 'rtb_spaces_count{instance=~"board.*"}' } response = requests.get(PROMETHEUS_URL, params=params) for metric in response.json()['data']['result']: boards[metric['metric']['instance']] = metric['value'][1] except requests.exceptions.RequestException as e: print('requests.exceptions.RequestException: {}'.format(e)) finally: return boards
在服务器之间转移用户的过程在Grafana中显示。 在图的左半部分,在旧版本上运行的服务器显示在右侧,在新版本上显示。 图表相交是用户转移的时刻。

团队负责监督Slack的发布。 发布之后,整个更改更改日志将在Slack的单独通道中发布,并且在Jira中,与此版本相关的所有任务都将自动关闭。
什么是用户迁移
我们将用户在其上工作的白板的状态存储在应用程序内存中,并将所有更改不断保存到数据库中。 为了在集群交互级别转移板,我们将其加载到新服务器的内存中,并向客户端发送命令以重新连接。 此时,客户端与旧服务器断开连接并连接到新服务器。 几秒钟后,用户看到题词-连接已恢复。 但是,他们继续工作,并没有发现任何不便。
我们在使部署不可见的同时学到了什么
经过一轮迭代之后,我们得出以下结论:
- Scrum团队会自行检查其代码。
- Scrum团队决定何时启动预发布版本,并将某些更改带给新用户。
- Scrum-team决定是否已准备好将其发行版提供给所有用户。
- 用户继续工作,什么也没注意到。
这不可能立即实现,我们多次踩着同一把耙子塞满了许多圆锥体。 我想分享我们收到的教训。
首先是手动过程,然后才是自动化过程。 第一步不需要更深入地进行自动化,因为您可以使最终没有用的自动化。
Ansible很好,但是Ansible角色更好。 我们使角色尽可能地通用:我们摆脱了重复的代码,因此它们仅具有应具有的功能。 这样,您就可以通过重用角色来节省大量时间,而我们已经拥有50多个角色。
重用Python中的代码并将其分成单独的库和模块。 这可以帮助您浏览复杂的项目,并迅速将新人们投入其中。
后续步骤
隐形部署过程尚未结束。 以下是一些步骤:
- 允许团队不仅完成预发行,而且还完成所有发行。
- 发生错误时自动回滚。 例如,如果在Sentry中检测到严重错误,则预发行版应自动回滚。
- 在没有错误的情况下使发布完全自动化。 如果预发行版本中没有错误,则表示可以自动进一步推出。
- 添加自动代码扫描以查找潜在的安全错误。