哈Ha! 长期假期结束后,我们已经有足够的休息时间,我们将竭尽所能再次做好您的准备。 IT部门的同事总是有话要说,今天我们与您分享JavaJam会议上Yandex.Money系统管理员Alexander Prizov的报告。
我们如何使用Graphite和Moira构建反馈流以检测问题释放。 我们将告诉您如何收集和分析有关应用程序中错误数量的指标。
-大家好,我叫Alexander Prizov,我在Yandex.Money的运营自动化部门工作,今天我将告诉您我们如何收集,处理和分析有关系统的信息。
您可能会想知道为什么将该报告称为“第二种方式”(会议上的报告名称为ed。)。 一切都很简单。 DevOps的核心是一些有条件地分为三组的原则。
第一种方法是流动原理。 第二种方式涉及反馈原则。 第三种方式是持续学习和实验。
通常,就软件产品的开发和运营而言,反馈意味着遥测,这是我们收集的有关系统的信息,最常见的情况是度量的收集和处理。
为什么我们需要这些指标? 借助指标,我们可以从系统获得反馈,并且可以知道系统处于什么状态,一切运行是否正常,我们的更改如何影响其操作以及是否需要采取任何干预措施来解决某些问题。
我们收集什么指标?
我们从三个级别收集指标。
从任何业务任务的角度来看, 业务级别都包含有趣的指标。 例如,我们可以获得以下问题的答案,例如我们注册了多少用户,用户登录系统的频率,移动应用程序拥有多少活跃用户。
下一个级别是应用程序级别 。 开发人员通常会查看此级别的指标,因为这些指标可以回答我们的应用程序的运行状况,处理请求的速度如何以及性能是否存在缺陷的问题。 这包括响应时间,请求数,队列长度等等。
最后, 基础设施的水平 。 这里的一切都很清楚。 使用这些指标,我们可以估计消耗的资源量,如何预测它们以及确定与基础架构有关的问题。
现在,简而言之,我将描述我们如何发送,处理以及将这些指标存储在何处。 在应用程序旁边,我们有一个指标收集器。 在我们的例子中,这是Heka服务,该服务侦听UDP端口并期望以StatsD格式输入度量。
StatsD的格式如下:

也就是说,我们确定度量标准的名称,指示该度量标准的值,它是1、26,依此类推,并指示其类型。 StatsD总共大约有四种或五种类型。 如果您突然感兴趣,可以详细查看这些类型的描述 。
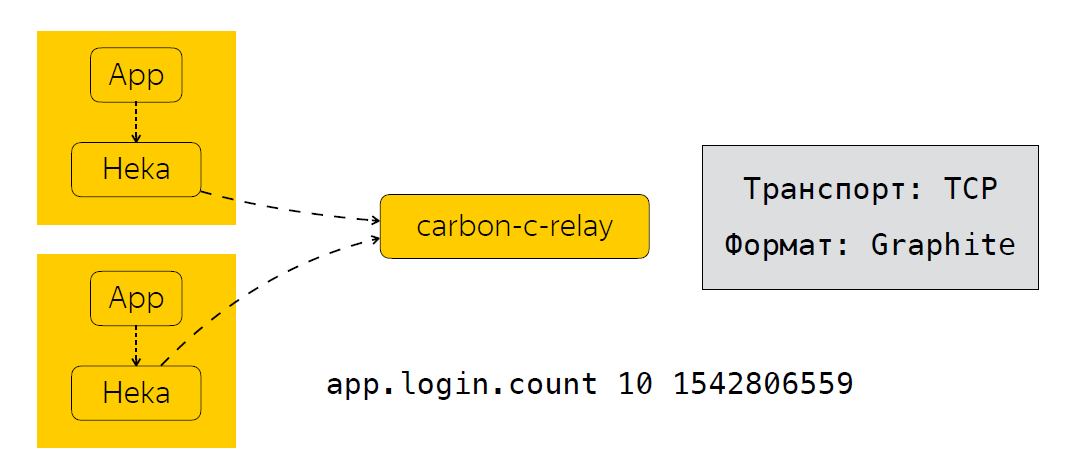
应用程序发送了Heka数据后,指标将在特定时间内汇总。 在我们的例子中,这是30秒,然后Heka将数据发送到carbon-c-relay,它执行过滤,路由,更新指标的功能,然后将指标发送到我们的存储中,我们使用Clickhouse(是的,它不会降低速度),以及在Moira中。 如果没有人知道,这是一项服务,允许您为指标配置某些触发器。 我稍后再谈Moira。 因此,我们研究了收集哪些指标,如何发送和处理它们。 接下来的逻辑步骤是对这些指标进行分析。
我们如何分析指标?
我将给出一个真实的情况,对指标的分析可以给我们带来切实的结果。 以发布过程为例。 一般而言,它包括以下步骤。
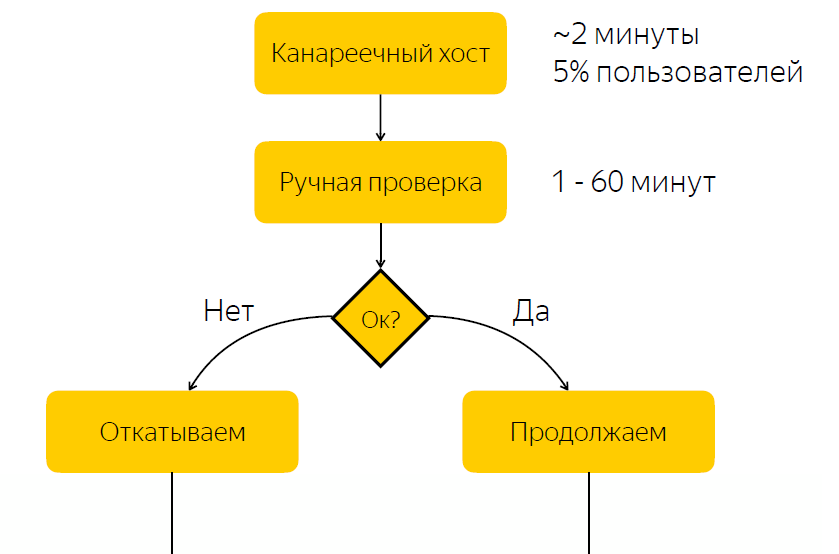
该版本已部署到Canary主机。 它约占用户流量的5%。 向金丝雀主机发布完毕后,我们通知发布负责人,他应该检查发布是否一切正常。 并且他应该做出反应,对这个版本做出反应,然后单击按钮,决定是应该发布该版本还是应该回退该版本。
不难猜测该方案存在重大缺陷,即我们期望负责任的反应。 如果此刻负责的人由于某种原因无法迅速做出响应,那么如果我们有一个错误发布,那么一段时间后,百分之五的流量将流向问题节点。 如果发布时一切正常,那么我们只需花时间等待,从而减慢发布过程。
没有错误-我们放慢了发布过程
有错误-用户喜爱
在了解了这个问题之后,我们决定找出是否有可能使发布是否有问题的决策过程自动化。
当然,我们求助于开发人员以了解发布检查是如何完成的。 事实证明,发布有问题的主要指标是该应用程序日志中错误数量的增加,这似乎合乎逻辑。
开发人员做了什么? 他们打开了Kibana,根据应用程序块的错误级别进行选择,如果他们看到列表,则认为应用程序出了问题。 值得一提的是,我们的应用程序日志存储在Elastic中,似乎一切看起来都很简单。 我们在Elastic中有日志,我们只需要在Elastic中创建一个请求,进行选择并根据此数据了解发布是否有问题。 但是这个决定对我们来说似乎不是很好。
为什么不弹性?
首先,我们担心我们可能无法快速从Elastic接收数据。 例如,在压力测试期间,当我们有大量数据流时,就会出现这种情况,而集群可能无法应对,最终,日志发送会延迟大约10-15分钟。
还有第二个原因,例如,索引缺乏统一的名称。 自动化工具中必须考虑到这一点。 而且,不同平台上的应用程序可能具有不同的日志格式。
我们认为,为什么不尝试制定某种指标,以此为基础来确定发布是否有问题。 同时,我们不想让开发人员负担更改代码库的负担。 而且,在我们看来,通过向log4j添加附加的附加程序,我们找到了一个相当优雅的解决方案。
看起来像什么
<?xml version="1.0" encoding="UTF-8" ?> <Configuration status="warn" name="${sys:application.name}" > <Properties> <Property name="logsCountStatsDFormat">app_name.logs.%level:1|c</Property> </Properties> ... <Appenders> <Socket name="STATSD" host="127.0.0.1" port="8125" protocol="UDP"> <PatternLayout pattern="${logsCountStatsDFormat}"/> </Socket> </Appenders> <Loggers> <Root level="INFO"> <AppenderRef ref="STATSD"/> </Root> </Loggers> </Configuration>
首先,我们确定要发送的指标的格式。 以下是一个附加的附加程序,它通过UDP将上述格式的记录通过UDP发送到端口8125,即Heka。 这给了我们什么? Log4j向具有指定记录级别ERROR,INFO,WARN等的每个日志条目发送类型为Counter的度量。
但是,我们很快意识到向每个日志条目发送指标会产生相当大的负载,并且我们编写了一个库,该库在特定时间内汇总指标并将已汇总的指标发送到Heka服务。 实际上,我们正在将此追加器添加到记录器中,并且通过这种方法,我们现在知道应用程序为调平写入了多少日志,无论使用哪种平台,我们都有统一的度量名称。 我们可以轻松了解应用程序日志中有多少个错误。 最后,我们能够自动执行有问题的发布的决策过程。
自动化技术
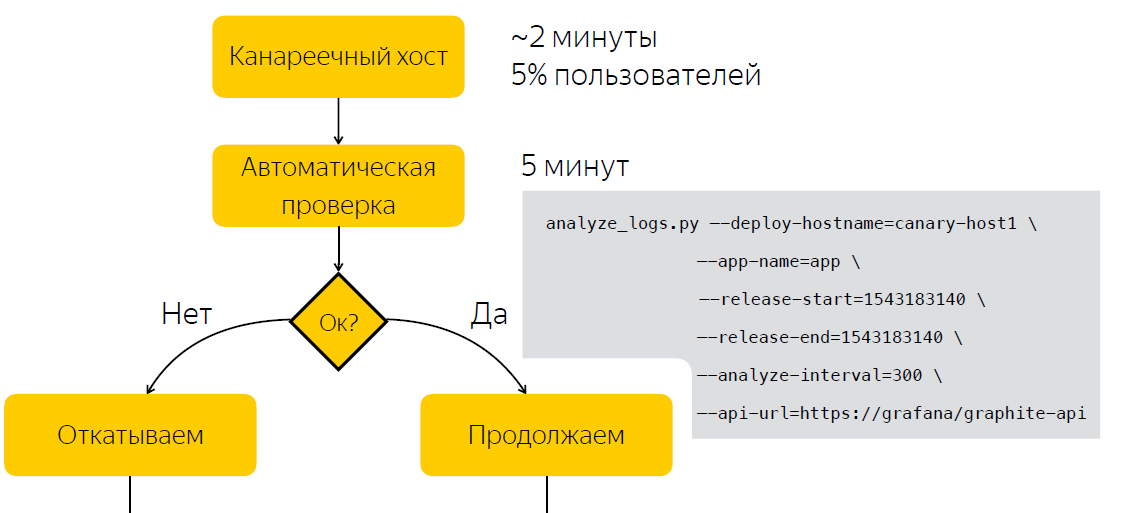
等待五分钟,而不是在发布后手动检查,之后我们将收集有关应用程序日志中条目数量的数据。 在运行脚本之后,该脚本将基于两个示例在发行之前和发行之后确定发行是否有问题。 因此,我们将决策所花费的时间减少到五分钟。
除了有关日志中错误数量的信息在发行期间很有用之外,事实证明这是一个很好的好处,它在操作期间也很有用。 因此,例如,我们可以可视化Grafana中日志中的错误数量,并在应用程序日志中记录异常激增。
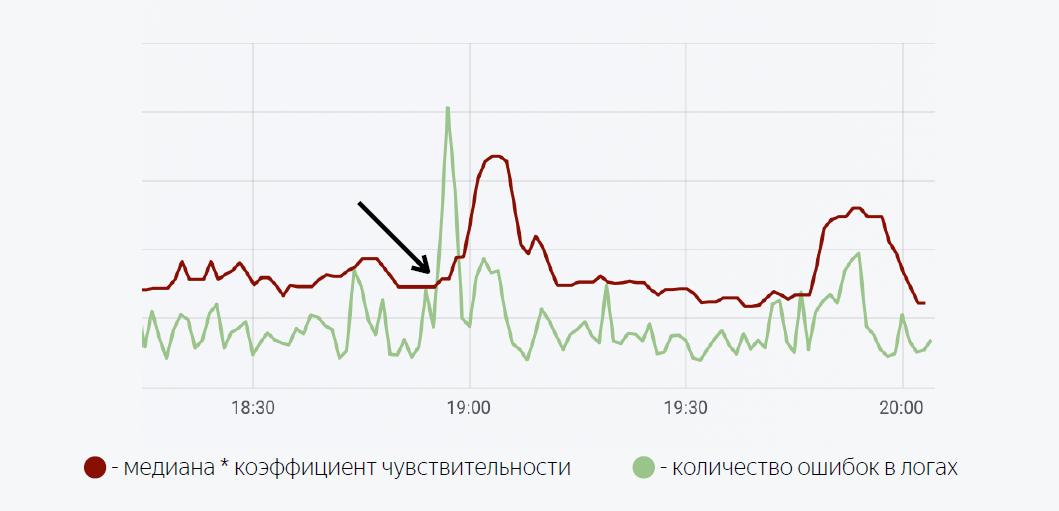
这里使用一个相当简单的数学模型。 绿线是应用程序日志中的错误数。 深红色是中位数乘以灵敏度系数。 如果日志中的错误数量超过中位数,则触发一个触发器,当触发该触发器时,将通过Moira发送通知。
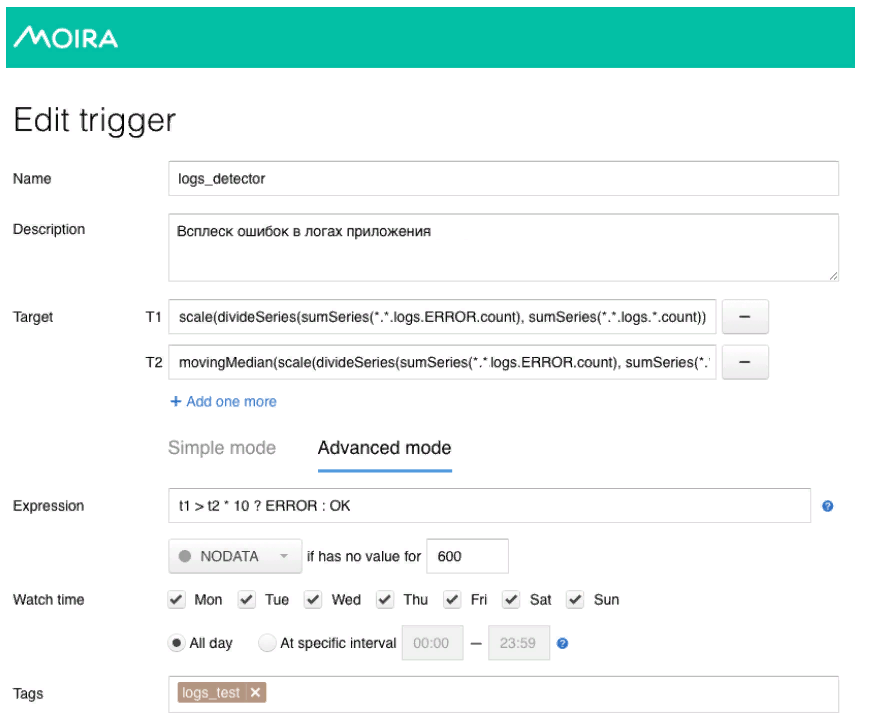
正如我所承诺的,我将向您介绍Moira的原理。 我们定义我们要观察的目标指标。 这是错误数和移动的中位数,以及此触发器将在其下工作的条件,即,当日志中的错误数超过中位数乘以灵敏度系数时。 触发触发器后,开发人员会收到通知,告知应用程序中已记录异常突发错误,因此应采取一些措施。

到底我们有什么? 我们为所有后端应用程序开发了一种通用机制,该机制使我们能够获取有关给定级别日志中条目数量的信息。 另外,使用有关应用程序日志中错误数量的度量,我们能够自动确定发布是否有问题的决策过程。 他们还为log4j写了一个库,如果您想尝试我描述的方法,可以使用该库。 链接到下面的库。
这可能就是我的全部。 谢谢啦
有用的链接
Log4j-count-appender
莫伊拉