在2018年初,我们积极启动了公司生产和流程数字化流程。 在石化领域,这不仅是一种流行趋势,而且是朝着提高效率和竞争力迈出的新的进化步骤。 考虑到没有进行任何数字化即可显示出良好经济效果的业务细节,数字化人员将面临一项艰巨的任务:更改公司中已建立的流程是一项艰巨的任务。
我们的数字化始于创建两个中心及其相应的功能模块。
这是“数字技术功能”,包括所有产品领域:流程数字化,IIoT和高级分析,以及已成为独立领域的数据管理中心。

数据办公室的主要任务是完全实施基于数据的决策文化(是,是,由数据驱动的决策),并且原则上简化与数据处理相关的所有工作:分析,处理,存储和报告。 特殊之处在于,我们所有的数字工具都不仅必须主动使用自己的数据(即,它们自己产生的数据)(例如,移动弯路或IIoT传感器),而且还必须使用外部数据,并清楚地了解在何处以及为何需要它们使用。
我叫Artyom Danilov,我是SIBUR基础设施和技术部门的负责人,在这篇文章中,我将告诉您我们如何以及基于什么为整个SIBUR构建大型数据处理和存储系统。 首先,我们仅讨论顶级架构以及如何成为我们团队的一员。
以下是数据办公室的工作范围:
1.处理数据积极参与数据清单和目录编制的人员在这里工作。 他们了解特定功能的需求,可以确定可能需要哪种分析,应该监视哪些度量以制定决策以及如何在特定业务领域中使用数据。
2. BI和数据可视化方向与第一个团队密切相关,可让您直观地看到第一个团队的工作成果。
3.数据质量控制的方向这里介绍了数据质量控制工具,并实现了这种控制的整个方法。 换句话说,这里的人实施软件,编写各种检查和测试,了解如何在不同系统之间进行交叉检查,记录负责数据质量的员工的职能,并建立通用的方法。
4. NSI的管理我们是一家大公司。 我们有许多不同种类的目录-承包商,材料和企业目录...总的来说,相信我,目录已经足够了。
当公司积极购买某种东西用于其活动时,通常会有特殊的过程来填写这些目录。 否则,混乱将达到无法完全使用“完全”一词的程度。 我们也有这样的系统(MDM)。
这里有问题。 假设在我们拥有很多人的一个地区部门中,员工坐在那里并将数据输入到系统中。 手工贡献,此方法将产生所有后果。 也就是说,他们需要输入数据,验证所有内容都以正确的形式到达系统,且没有重复。 同时,在填写一些详细信息和必填字段的情况下,您必须独立搜索和搜索。 例如,您有一个TIN公司,并且您需要其他信息-检查特殊服务和注册。
当然,所有这些数据都已经存在,因此简单地自动将其上拉将是正确的。
以前,该公司原则上没有任何职位,一个明确的团队可以做到这一点。 手动输入数据的部门分散很多。 但是,对于这样的结构,通常甚至很难确定在处理数据的过程中确切地定义什么以及确切地在何处,以使一切都完美无缺。 因此,我们正在审查NSI的格式和管理结构。
5.实施数据仓库(数据节点)这正是我们在这方面开始做的事情。
让我们立即定义术语,否则我使用的短语可能与其他一些概念相交。 粗略地说,数据节点=数据湖+数据仓库。 我会更详细地揭示这一点。
建筑学
首先,我们试图找出要处理的数据类型-存在哪些系统,哪些传感器。 我们了解了什么样的流数据(这是企业自己从所有设备生成的数据,这是IIoT等)以及传统系统,不同的CRM,ERP等。
我们意识到,当前系统中的数据将无法直接提供足够大的数据量,但是随着数字工具和IIoT的引入,将会有很多数据。 而且还将有来自经典会计系统的非常不同的数据。 因此,他们提出了这样一个计划的架构。

有关块的更多详细信息。
贮藏
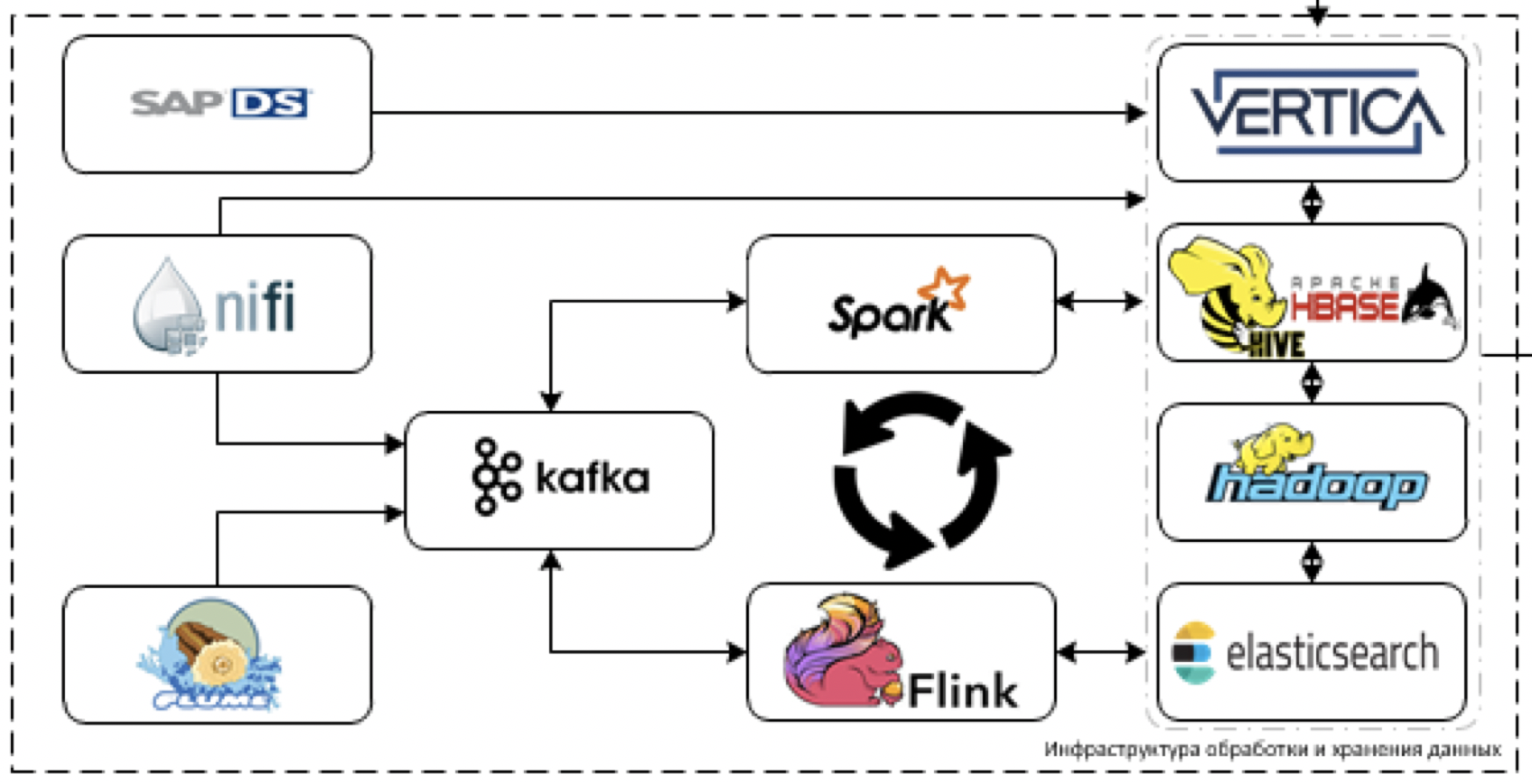
这是我们平台的核心核心。 用于处理和存储数据的内容。 挑战在于,当60多个不同的系统开始提供数据时,便要下载它们。 也就是说,通常存在所有可能对做出某些决策有用的数据。
让我们从数据的提取和处理开始。 为此,我们计划使用NiFi ETL工具处理流和分组数据,以及流处理工具:将Flume用于主要数据的接收和解码,将Kafka用于缓冲,将Flink和Spark Streaming作为处理数据流的主要工具。
使用SAP堆栈系统最困难。 您必须使用单独的ETL工具-SAP数据服务从SAP检索数据。
作为存储工具,我们计划使用Cloudera Hadoop平台(HDFS,HBASE,Hive,Impala本身),Vertica分析型DBMS,并在个别情况下使用elasticsearch。
基本上,我们使用最高级的堆栈。 是的,我们可以尝试向我们扔西红柿,然后嘲笑我们所谓的最现代的烟囱,但实际上-是的。
我们不仅限于旧版开发,而且由于平台的明确的企业定位,我们不能在工业解决方案中使用前沿技术。 因此,也许我们不拖拽Horton,而是将自己限制在Clouder中,只要有可能,我们肯定会尝试拖拽一个更新的工具。

SAS数据质量用于控制数据质量,而气流用于管理所有这些优势。 我们通过ELK堆栈监视整个平台。 我们计划在Tableau上进行大部分可视化,在SAP BO上进行一些完全静态的报告。
我们已经了解到,部分任务无法通过标准BI解决方案来实现,因为需要非常复杂的实时可视化以及许多纸板控件。 因此,我们将编写自己的可视化框架,该框架可以嵌入正在开发的数字产品中。
关于数字平台
如果您放宽一点,现在我们的数字技术职能部门的同事正在构建一个单一的数字平台,其任务是快速开发我们自己的应用程序。
数据湖是该平台的要素之一。
作为此活动的一部分,我们了解到我们将需要实现一个方便的接口来访问分析数据。 因此,我们计划实现Data API和生产对象模型,以更方便地访问生产数据。
我们还需要做什么?
除了存储和处理数据外,所有机器学习以及IIoT框架都将在我们的平台上运行。 该湖泊将既充当培训和工作模型的数据源,又充当工作模型的能力。 可以在平台顶部运行的ML框架已经准备就绪。

现在,我有一个团队,几个架构师和6个开发人员,所以我们正在积极寻找新人(我需要
数据架构师和
数据工程师 )来为我们开发平台提供帮助。 您无需老掉牙(传统仅在系统入口处出现),堆栈是新鲜的。
那就是微妙之处-在集成中。 将旧与新连接在一起,使其工作正常并解决问题,是一项挑战。 此外,有必要发明,制定并保留一系列不同的指标。
数据收集是从所有主要系统(1C,SAP和许多其他所有系统)中进行的。 根据此处收集的数据,将构建所有分析,所有预测和所有数字报告。
简而言之,我们要使数据工作真的很酷。 例如,市场营销和销售-他们拥有人工收集所有统计信息的人员。 也就是说,它们坐着,从5个不同的系统中抽出不同格式的不同数据,从5个不同的程序中下载它们,然后将所有这些数据卸载到Excel中。 然后他们将信息汇总到统一的Excel表中,以某种方式尝试使其可视化。
通常,旅行车需要花费所有时间。 我们希望通过我们的平台解决此类问题。 在以下帖子中,我们将详细介绍如何将元素连接在一起并设置系统的正确操作。
顺便说一下,除了这个团队中的
架构师和
数据工程师外 ,我们将很高兴看到: