俄语版
假设您正在开发软件和硬件设备。 该设备由自定义OS分布式高端服务器和许多业务逻辑组成,因此,它必须使用真实的硬件。 如果释放损坏的设备,则用户将不满意。 如何稳定发布?
我想分享我的故事我们如何处理。
概念证明
如果您不知道目标,将很难完成任务。 第一个部署变量看起来像bash :
make dist for i in abc ; do scp ./result.tar.gz $i:~/ ssh $i "tar -zxvf result.tar.gz" ssh $i "make -C ~/resutl install" done
脚本被简化只是为了显示主要思想:没有CI / CD。 我们的流程是:
- 建立在开发者主机上。
- 部署到演示的测试环境。
在当前阶段,如何配置它的知识,所有已知的错误都是开发人员心中的肮脏魔术。 由于团队的成长,这对我们来说是一个真正的问题。
做就做
我们在项目中使用了TeamCity,而gitlab并不受欢迎,因此我们决定使用TeamCity。 我们手动创建了一个VM。 我们正在虚拟机中运行测试 。
构建流程中包含一些步骤:
- 在手动准备的环境中安装一些实用程序。
- 检查它是否有效。
- 如果可以,请发布RPM。
- 将登台更新为新版本。
make install && ./libs/run_all_tests.sh make dist make srpm rpmbuild -ba SPECS/xxx-base.spec make publish
我们收到了一个临时结果:
- 可运行的东西在master分支中。
- 它在某处工作。
- 我们可以发现一些偶然的问题。
你闻到气味了吗?
- RPM有一个依赖地狱。
- 每个人都有自己的宠物开发环境。
- 测试在未知环境中运行。
- 共有三个完全不受限制的实体:操作系统构建,安装配置和测试。
减少肮脏的魔法
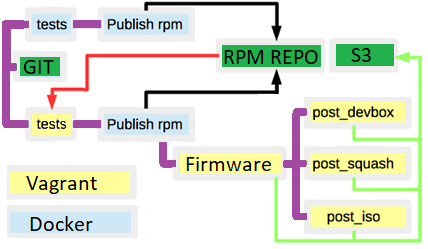
我们更改了流程和流程:
- 我们已经创建了RPM元数据包并删除了依赖地狱。
- 我们通过无业游民创建了一个开发VM模板。
- 我们将bash脚本移到了ansible中。
- 一方面,我们创建了一个集成测试框架,但另一方面,我们使用了serverspec 。
作为当前阶段的结果,我们收到了:
- 我们所有的开发环境都是相同的。
- 应用代码和配置逻辑已相互同步。
- 我们加快了新开发人员的入职流程。
一方面,构建确实很慢(大约30至60分钟),但另一方面,它足够好并且可以在手动质量保证之前成功解决了绝大多数问题。 但是,我们遇到了新的不同问题,例如,我们更新了内核或回滚了软件包。
改善它
我们解决了许多不同的问题:
- 集成测试的运行速度越来越慢,因为开发VM模板早于实际RPM。 我们正在手动重建模板,然后我们决定对其进行自动化:
- 自动创建VMDK。
- 将VMDK附加到VM。
- 打包VM并上传到s3。
- 在合并的情况下,无法获得构建状态,因此,我们移至gitlab。
- 我们过去每周都会进行一次手动发布,因此我们将其自动化。
- 自动递增版本。
- 根据已解决的问题生成发行说明。
- 更新变更日志。
- 创建合并请求。
- 创建一个新的里程碑。
- 我们将一些步骤移入了docker(皮棉,运行一些测试,发送消息,构建文档等)。
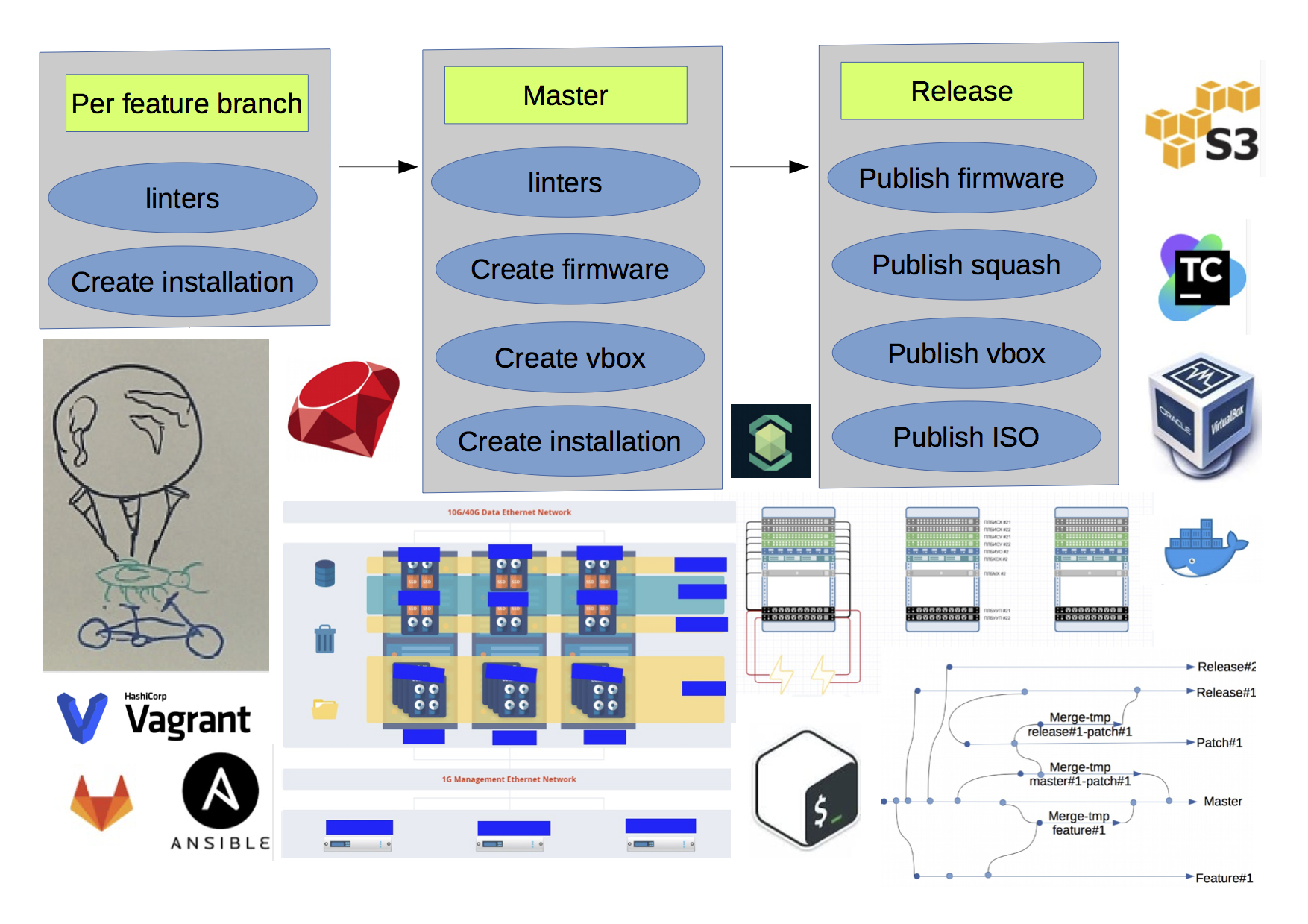
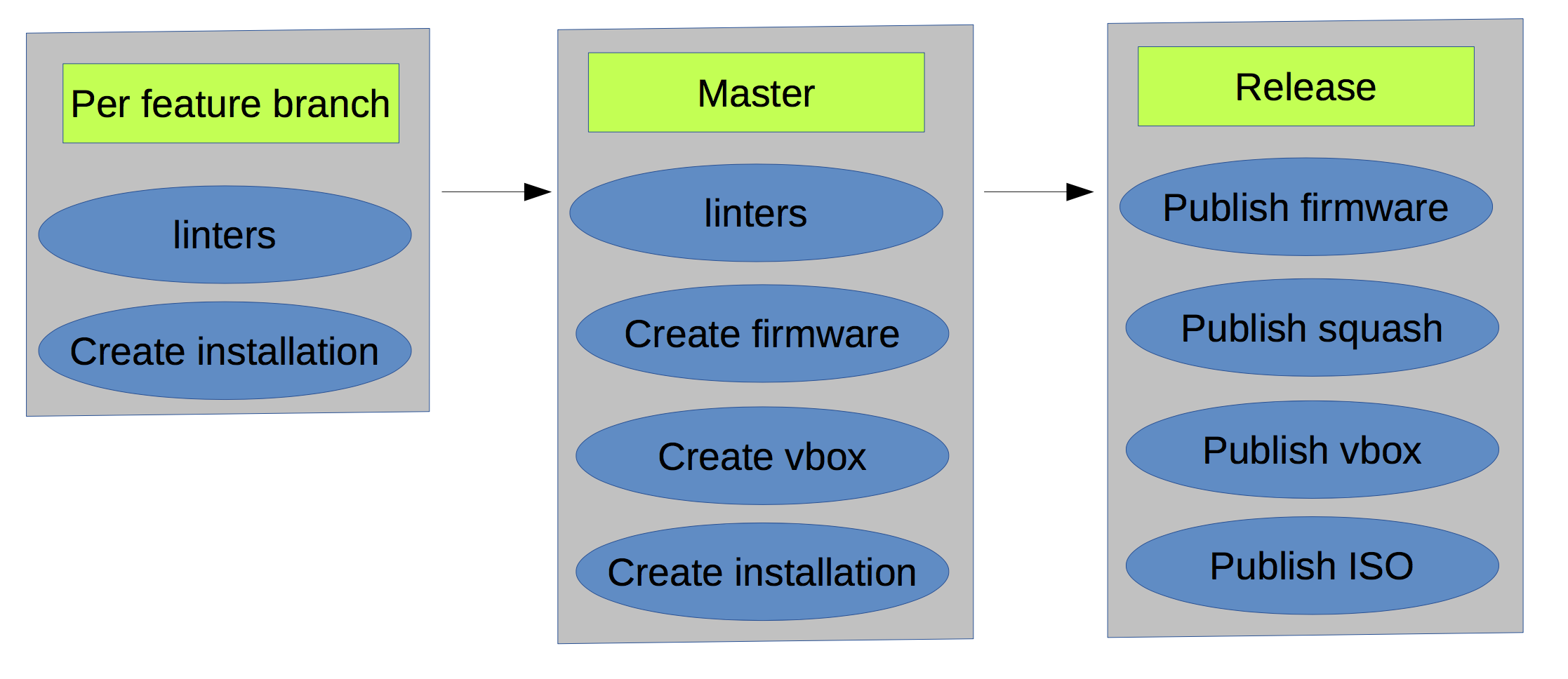
结果,当前阶段的方案如下所示:

- 软件包有很多RPM / DEB仓库。
- 有s3作为人工制品仓库。
- 如果您为同一分支运行两次构建,则将收到不同的结果,因为未对meta包依赖项进行硬编码。
- 整个版本之间没有明显的界限(红色线条)。
但是,我们每周都能发布版本并提高开发速度。
结论
结果并不理想,但从第一步开始一千里的旅程便是©。
PS这是交叉