大量的静态分析材料提示我写这篇文章,这种材料越来越引起我的注意。 首先,这是
PVS-studio博客 ,该
博客通过其开源项目中的工具发现的错误检查,在Habré上积极推广自己。 最近,PVS-studio实现了
对Java的支持 ,当然,IntelliJ IDEA的开发人员
也无法幸免,后者的内置分析器可能是当今Java最先进的分析器。
阅读此类评论时,有一种我们在谈论魔术长生不老药的感觉:单击该按钮,这是-眼前的缺陷列表。 似乎随着分析仪的改进,将自动发现越来越多的错误,并且由这些机器人扫描的产品将变得越来越好,而无需我们付出任何努力。
但是没有神奇的灵丹妙药。 我想谈一谈通常在“机器人可以找到的东西”之类的文章中通常没有提及的内容:分析器无法执行的操作,它们在软件交付过程中的真正作用和地位以及如何正确实施它们。
 棘齿(来源: Wikipedia )。
棘齿(来源: Wikipedia )。静态分析仪无法做到的
从实用的角度来看,什么是源代码分析? 我们将一些源提交给输入,然后在很短的时间内(比测试运行要短得多)在输出中获得有关系统的一些信息。 从根本上和数学上无法克服的限制是,我们只能以这种方式获得相当狭窄的信息类别。
不能通过静态分析解决的问题的最著名例子是
关机问题 :这是一个定理,证明无法开发一种通用算法来确定程序是在有限时间内循环还是结束,该算法将由程序的源代码确定。 该定理的一个扩展是
莱斯定理,该
定理指出,对于可计算函数的任何非平凡属性,确定任意程序是否使用该属性计算函数是算法上无法解决的问题。 例如,不可能编写一个通过任何源代码确定所分析程序是否是计算(例如,对整数进行平方)算法实现的分析器。
因此,静态分析仪的功能具有不可克服的局限性。 在所有情况下,静态分析器将永远无法检测到诸如可空语言中“空指针异常”的出现,或者在所有情况下将确定动态类型语言中“未找到属性”的发生。 最先进的静态分析器所能做的就是突出特定的情况,在不言而喻的情况下,您的源代码可能出现的所有问题中有很多是零花钱。
静态分析不是错误搜索
得出以下结论:静态分析不是减少程序中缺陷数量的方法。 我敢断言:在将其首次应用于您的项目时,它将在代码中找到“已占用”的位置,但是很可能不会发现任何会影响程序质量的缺陷。
分析仪自动发现的缺陷示例令人印象深刻,但我们不要忘记,这些示例是通过扫描大量大型代码库发现的。 按照相同的原理,能够在大量帐户上枚举几个简单密码的破解者最终会找到具有简单密码的那些帐户。
这是否意味着不需要应用静态分析? 当然不是! 并且出于完全相同的原因,值得检查每个新密码以进入“简单”密码的停止列表。
静态分析不仅仅是错误搜索
实际上,分析实际解决的任务要广泛得多。 确实,总的来说,静态分析是对源发布之前进行的任何验证。 您可以执行以下操作:
- 在广义上验证编码风格。 这包括检查格式,搜索空括号/多余括号的使用,为行数/方法的圈复杂度等指标设置阈值,所有这些都有可能使代码难以阅读和维护。 在Java中,此类工具是Checkstyle,在Python中是flake8。 此类程序通常称为linters。
- 不仅可执行代码可以分析。 可以(并且应该!)自动检查诸如JSON,YAML,XML,.properties之类的资源文件。 毕竟,最好是发现由于一些不成对的引号,与执行测试或在运行时相比,在自动“拉取请求”检查的早期阶段就违反了JSON结构? 提供了相关工具:例如, YAMLlint , JSONLint 。
- 编译(或解析为动态编程语言)也是静态分析的一种形式。 通常,编译器能够发出警告,以信号形式说明源代码的质量问题,因此不应忽略它们。
- 有时,编译不仅是可执行代码的编译。 例如,如果您拥有AsciiDoctor格式的文档,则在将其转换为HTML / PDF时,AsciiDoctor( Maven插件 )处理程序可能会发出警告,例如有关内部链接断开的警告。 这是不接受对文档进行更改的“拉取请求”的充分理由。
- 拼写检查也是静态分析的一种形式。 aspell实用程序不仅可以检查文档中的拼写,还可以检查各种编程语言(包括C / C ++,Java和Python)的程序源代码(注释和文字)。 用户界面或文档中的拼写错误也是一个缺陷!
- 配置测试(关于它的含义-参见此报告和本报告),尽管它们在pytest之类的单元测试的运行时环境中运行,但实际上也是一种静态分析,因为它们在执行期间不会执行源代码。
如您所见,在此列表中搜索错误的作用最不重要,使用免费的开放源代码工具可以获取其他所有信息。
您的项目中应使用哪种类型的静态分析? 当然,一切都越多越好! 最主要的是正确实现它,这将进一步讨论。
交付管道为多级过滤器,静态分析为第一级
持续集成的经典隐喻是变更流经的管道-从变更源代码到交付生产。 该管道中的标准步骤顺序如下:
- 静态分析
- 合编
- 单元测试
- 整合测试
- UI测试
- 手动检查
在输送机第N阶段拒绝的更改不会转移到N +1阶段。
为什么这样,否则就不这样? 在管道的测试部分中,测试人员会认识到众所周知的测试金字塔。
 测试金字塔。 资料来源:马丁·福勒(Martin Fowler)的文章 。
测试金字塔。 资料来源:马丁·福勒(Martin Fowler)的文章 。该金字塔的底部是易于编写的测试,这些测试执行起来更快,并且没有误报的趋势。 因此,应该有更多的代码,它们应该涵盖更多的代码并首先执行。 在金字塔的顶部,一切都是相反的,因此集成和UI测试的数量应减少到所需的最低限度。 此链中的人是最昂贵,最慢且最不可靠的资源,因此,他只能在最后一步并且只有在前面的步骤没有发现任何缺陷的情况下才能进行工作。 但是,根据相同的原理,传送带内置于与测试没有直接关系的零件中!
我想以多级水过滤系统的形式进行类比。 入口处供应了脏水(有缺陷的变化),在出口处我们必须获得纯净水,其中消除了所有不良污染。
 多级过滤器。 资料来源: Wikimedia Commons
多级过滤器。 资料来源: Wikimedia Commons如您所知,清洁过滤器的设计使每个随后的级联都可以过滤出越来越少的污染物。 同时,较粗的级联具有更高的吞吐量和更低的成本。 以我们的类比来说,这意味着输入质量的门具有更高的速度,启动时所需的精力更少,并且本身在工作中更为朴实无华-正是按照这种顺序来建造它们。 众所周知,静态分析的作用是消除最严重的缺陷,这是过滤器级联开始时“污物陷阱”格栅的作用。
仅仅进行静态分析并不能提高最终产品的质量,就像集泥器不能制造饮用水一样。 然而,与输送机的其他元件一起,其重要性是显而易见的。 尽管在多级滤波器中,输出级可能具有捕获与输入级相同的所有功能的能力,但很明显,没有输入级的精细级尝试会导致什么后果。
“污物收集器”的目的是减轻后续的级联捕获非常严重的缺陷。 例如,至少代码审查人员不应因格式错误的代码和违反已建立的编码标准(例如多余的括号或嵌套太深的分支)而分心。 NPE之类的错误应该通过单元测试捕获,但是即使在测试之前分析器告诉我们不可避免地会发生错误,这也会大大加快其纠正速度。
我相信现在很清楚,如果偶尔进行静态分析,为什么静态分析不能改善产品质量,应该连续使用它来筛选出存在重大缺陷的变更。 问题是使用静态分析仪是否会提高产品质量,大致等于“从脏水箱中获取的水如果经过漏勺,其饮用水质量会改善吗?”
在旧版项目中实施
一个重要的实际问题:如何将静态分析作为“质量门”整合到持续集成的过程中? 在自动测试的情况下,一切都是显而易见的:有一组测试,其中任何一个测试的失败都足以使我们相信装配没有通过质量检验。 尝试根据静态分析的结果以相同的方式设置门的尝试将失败:遗留代码中的分析警告过多,您不想完全忽略它们,但是仅由于包含分析器警告而无法停止交付产品。
首次应用时,分析仪会在任何项目上生成大量警告,其中绝大多数与产品的正常运行无关。 不可能立即更正所有这些注释,并且许多注释都是不必要的。 最后,我们知道我们的产品在整体上可行,并且在引入静态分析之前!
结果,当在组装过程中简单地发布分析器报告时,许多操作仅限于静态分析的临时使用,或仅在通知模式下使用。 这相当于没有进行任何分析,因为如果我们已经有很多警告,那么在更改代码时就会注意到另一个警告(任意严重)的出现。
已知以下管理质量门的方法:
- 对警告总数或警告数除以代码行数设置一个限制。 这很不好,因为这样的门会随意跳过具有新缺陷的更改,直到超出其限制为止。
- 在某一时刻将代码中的所有旧警告修复为忽略,并在出现新警告时拒绝构建。 该功能由PVS-studio和一些在线资源(例如Codacy)提供。 我没碰巧在PVS-studio中工作,就我在Codacy方面的经验而言,他们的主要问题是确定“旧”和“新”是一个相当复杂且并不总是有效的算法,尤其是当文件被大量修改或重命名。 在我的记忆中,Codacy可能会在拉取请求中跳过新的警告,并且由于不与此PR代码的更改无关的警告而不会跳过拉取请求。
- 我认为,最有效的解决方案在《 持续交付 》中的“棘轮”一书中进行了描述。 主要思想是每个发行版的属性是静态分析的警告数量,并且仅允许那些不会增加警告总数的更改。
棘轮
它是这样工作的:
- 在初始阶段,分析器找到的代码中的警告数量会记录在有关该版本的元数据中。 因此,在构建主分支时,不仅“版本7.0.2”而且“版本7.0.2,包含100500 Checkstyle警告”也被写入存储库管理器。 如果您使用高级存储库管理器(例如Artifactory),则可以轻松保存有关您的发行版的此类元数据。
- 现在,组装期间的每个拉取请求都会将收到的警告数量与当前版本中的警告数量进行比较。 如果PR导致此数字增加,则代码不会通过质量门进行静态分析。 如果警告数量减少或没有更改,则通过。
- 在下一个发行版中,计算出的警告数量将被重新写入发行版元数据。
渐渐地,但是稳步地(与棘轮一样),警告的数量趋于于零。 当然,可以通过引入新的警告而纠正其他人的警告来欺骗该系统。 这是正常的,因为在很长的距离内它会产生结果:通常,不是个别地而是而是由某种类型的组立即纠正警告,通常不会单独纠正,并且所有容易消除的警告也会被迅速消除。
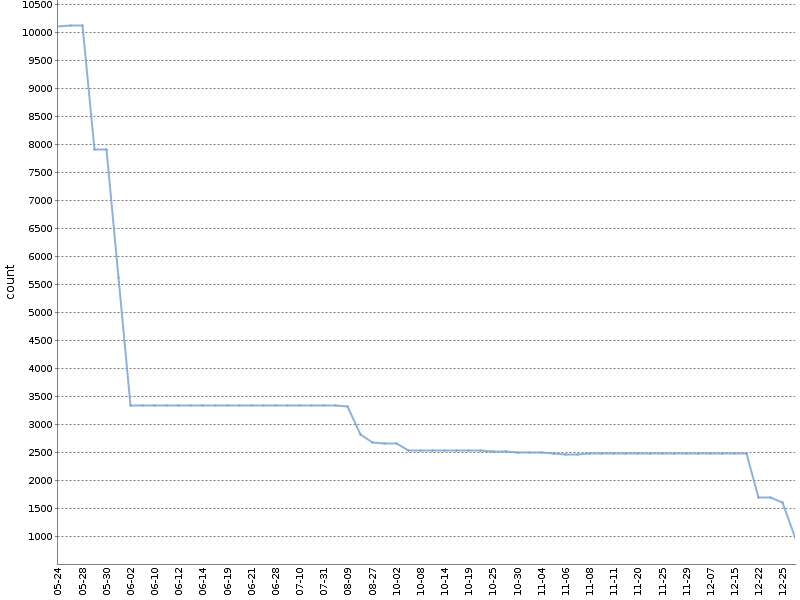
此图显示了在
我们的一个OpenSource项目中进行这种棘轮测试半年后,Checkstyle警告的总数。 警告的数量减少了一个数量级,这与产品的开发同时发生是自然的!
我使用此方法的修改版,分别计算由项目模块和分析工具细分的警告,生成的带有组件元数据的YAML文件如下所示:
celesta-sql: checkstyle: 434 spotbugs: 45 celesta-core: checkstyle: 206 spotbugs: 13 celesta-maven-plugin: checkstyle: 19 spotbugs: 0 celesta-unit: checkstyle: 0 spotbugs: 0
在任何高级CI系统中,可以为任何静态分析工具实现“棘轮”功能,而无需依赖插件和第三方工具。 每个分析仪都以简单的文本或XML格式生成其报告,易于分析。 只剩下在CI脚本中注册必要的逻辑。 您可以在
此处或
此处查看基于Jenkins和Artifactory的开源项目中如何实现
此功能 。 这两个示例都依赖于
ratchetlib库:
countWarnings()方法
countWarnings()对Checkstyle和Spotbugs生成的文件中的xml标记进行计数,而
compareWarningMaps()实现相同的棘轮,当任何类别中的警告数量增加时都会引发错误。
棘轮的一种有趣实现是可以使用aspell分析注释,文本文字和文档的拼写。 如您所知,在检查拼写时,并非标准词典中未知的所有单词都不正确;可以将它们添加到用户词典中。 如果将自定义词典作为项目源代码的一部分,则可以按以下方式制定拼写的质量门:使用标准和自定义词典运行aspell
应该不会发现任何拼写错误。
关于修复分析仪版本的重要性
总之,应注意以下几点:无论如何将分析集成到交付管道中,都必须修复分析器版本。 如果您允许分析器自发更新,则在组合下一个拉取请求时,可能会“弹出”与更改代码无关的新缺陷,但又与新分析器仅能发现更多缺陷这一事实有关,这将中断接收拉取请求的过程。 分析仪升级必须是自觉的。 但是,紧密固定组件的每个组件的版本通常是必要的要求,并且是单独对话的主题。
结论
- 静态分析不会发现您的错误,也不会因为单个应用程序而提高产品质量。 只有在交付过程中不断使用质量,才能对质量产生积极影响。
- 搜索错误根本不是分析的主要任务,开源工具提供了绝大多数有用的功能。
- 在交付管道的第一阶段,基于静态分析的结果来实现质量控制,并使用棘轮式的遗留代码。
参考文献
- 持续交付
- 答:Kudryavtsev:程序分析:如何理解您是有关各种代码分析方法的优秀程序员报告(不仅是静态的!)