因此,在1月4日晚上7:15,我从睡眠中消除了眼睛,我从Zabbix服务器的Telegram组中发现了一堆消息,其中一台虚拟服务器的CPU负载增加了:
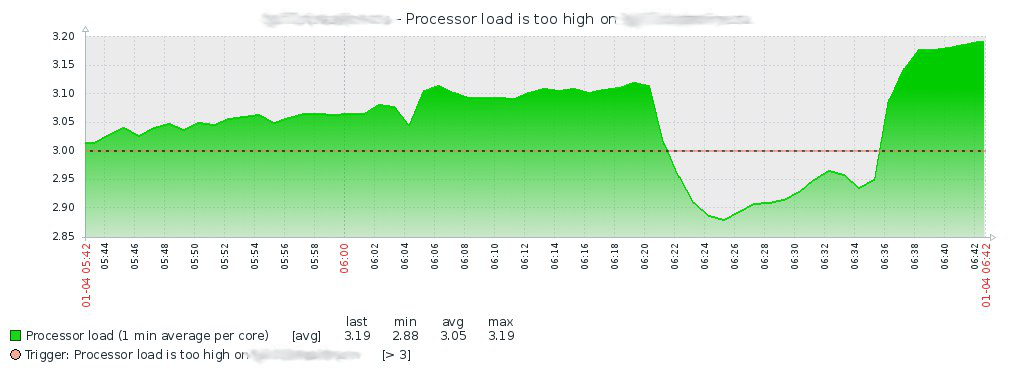
在查看Zabbix的历史之后,我爬到服务器上并在dmesg中查找以下内容:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter. [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device [ 3 20:05:28 2019] sd 10:0:0:1: rejecting I/O to offline device
我正在爬入QLogic FC适配器正在查看的存储,我发现在1月1日19:54,该存储中的一个驱动器已停用,备用驱动器被提起,并且重新同步于1月2日9:11结束:

我以为:也许某些东西来自存储库或FC交换机,这导致驱动程序对QLogic适配器感到恼火。
乍一看,在跟踪器中创建了一个任务,重新启动了服务器,一切都恢复了正常运行。
为此,他将进一步的行动推迟到新年假期结束之前。
从1月9日工作周开始,他开始理清故障原因。
由于消息:
[ 3 20:05:18 2019] qla2xxx [0000:21:00.1]-015b:10: Disabling adapter.
不太翔实,爬进了驱动程序源。
根据驱动程序代码判断,由于PCI错误(Linux / drivers / scsi / qla2xxx / qla_os.c(内核v4.15))而卸载驱动程序时,会发出一条消息:
qla2x00_disable_board_on_pci_error(struct work_struct *work) { struct qla_hw_data *ha = container_of(work, struct qla_hw_data, board_disable); struct pci_dev *pdev = ha->pdev; scsi_qla_host_t *base_vha = pci_get_drvdata(ha->pdev); /* * if UNLOAD flag is already set, then continue unload, * where it was set first. */ if (test_bit(UNLOADING, &base_vha->dpc_flags)) return; ql_log(ql_log_warn, base_vha, 0x015b, "Disabling adapter.\n");
我开始进一步研究,进入BMC,查看事件日志:
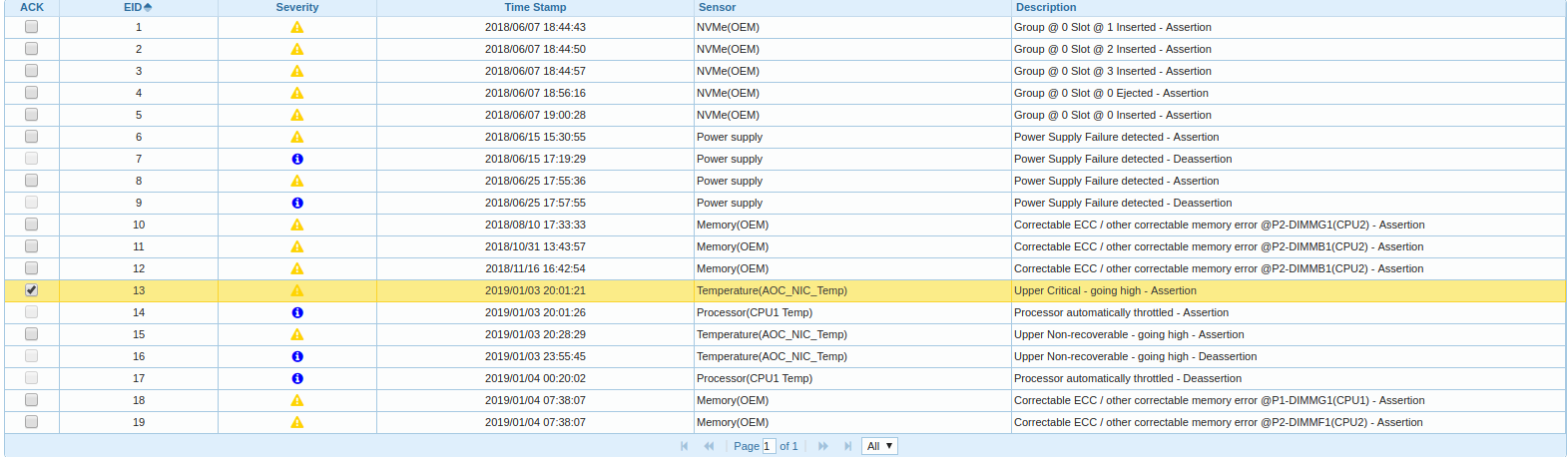
事实证明,平台中的两个CPU节点之一正在预热和节流,有关卸载FC适配器驱动程序的消息的时间与节流的开始时间相关。
这里值得一提的是,我们在这里拥有的服务器平台是https://www.supermicro.com/Aplus/system/2U/2123/AS-2123BT-HNC0R.cfm ,每个节点有两个EPYC 7601:
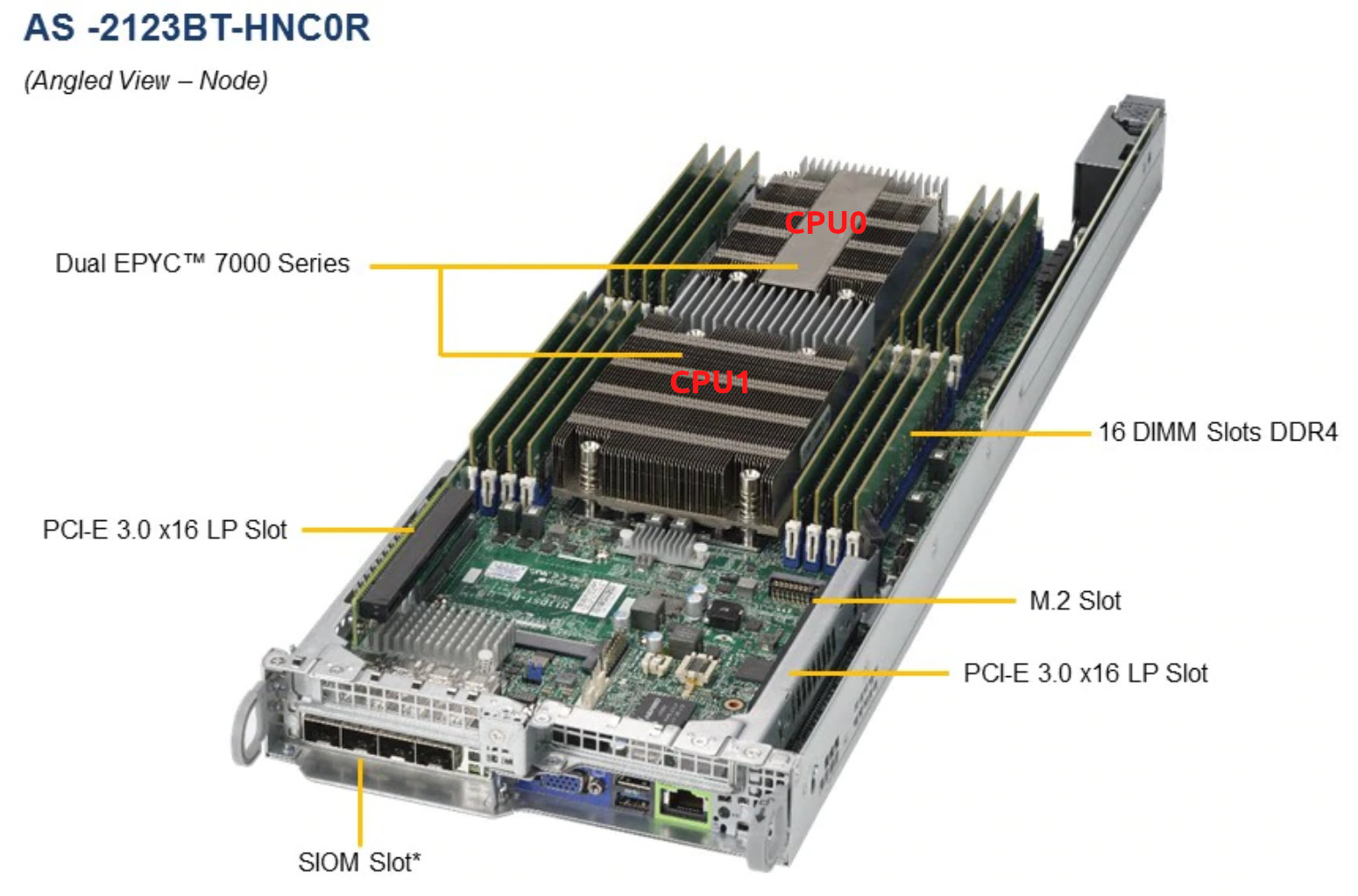
我将其移至数据中心,从服务器上删除了该节点,更改了导热膏,将其粘贴回去,但是它仍然会变热。
我们注意到,服务器某一部分的气流不如另一部分强。 稍微给所有节点施加压力ng后,很明显,平台右侧的节点处理器无法正常工作,并且两个节点中第二个CPU的温度很快达到临界值。
尝试在BMC中更改吹塑参数后,结果表明它们无效:
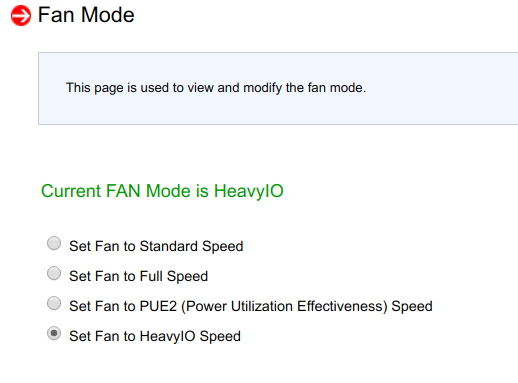
重新启动BMC也不起作用。
查看传感器读数后,我发现在53个传感器中的一个节点上,仅检测到4个传感器,而在另一个节点上,仅检测到6个传感器:
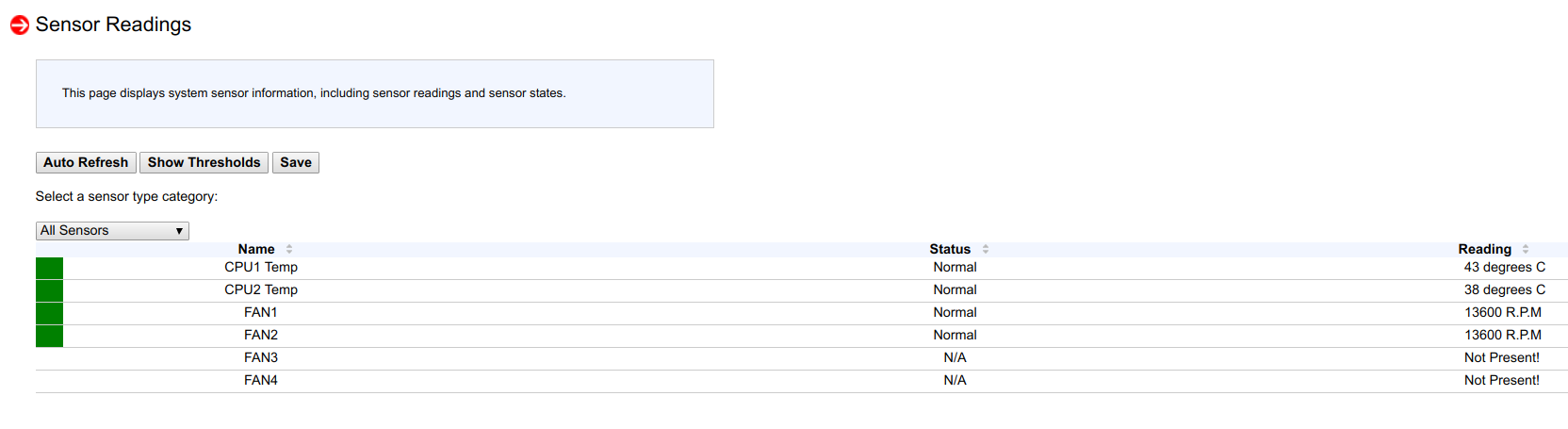
然后,我记得一个月或两个月前向节点刷新了新的BIOS版本和新的BMC,在两个节点上,我没有将BMC配置重置为出厂设置(以检查一种特殊的调整情况)。
将BMC重置为出厂参数后,再次检测到所有53个传感器,风扇速度控制再次起作用,处理器停止加热。
QLogic驱动程序卸载的原因是处理器过热,这一事实并不准确,但是我没有发现其他紧密相关的事实。
结论:
- 使用BMC固件后,即使乍看之下一切正常,仍然值得将其重置为出厂设置;
- 当然,必须监视温度和内核错误消息,这在计划中是很自然的,但并非一次完成。