我的名字叫Vladislav,我
一口气参与了
Tarantool -DBMS和应用服务器的开发。 今天,我将告诉您我们如何使用
VShard模块在Tarantool中实现水平缩放。
首先,一点理论。
缩放有两种类型:水平缩放和垂直缩放。 水平分为两种:复制和分片。 复制用于扩展计算,分片用于扩展数据。
分片分为两种:按范围分片和按哈希分片。
使用范围进行分片时,我们从集群中的每个记录计算一些分片键。 这些分片键投影到一条直线上,该直线划分为我们添加到不同物理节点的范围。
使用散列进行分片更简单:从群集中的每个记录中考虑一个散列函数,我们将具有相同散列值的记录添加到一个物理节点。
我将讨论使用哈希分片的水平缩放。
先前的执行
我们拥有的第一个水平缩放模块是
Tarantool Shard 。 这是通过哈希进行的非常简单的分片,它考虑了集群中所有条目的主键中的分片键。
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
但是随后出现了一个任务,Tarantool Shard由于三个基本原因而无法处理。
首先,需要
逻辑相关数据的
局部性 。 当我们具有逻辑连接的数据时,无论群集拓扑如何更改或执行平衡,我们总是希望将其存储在同一物理节点上。 而且,Tarantool Shard不保证这一点。 他仅通过主键考虑哈希,并且在重新平衡时,即使具有相同哈希的记录也可以分离一段时间-传输不是原子的。
数据局部性不足的问题最大程度地阻止了我们。 我举一个例子。 有一家客户在其中开户的银行。 帐户和客户数据必须始终物理存储在一起,以便可以在一个请求中读取它们,并在一次交易中进行交换,例如,从帐户中转移资金时。 如果您将经典分片与Tarantool Shard一起使用,则对于客户和客户,分片函数的值将有所不同。 数据可能在不同的物理节点上。 这极大地使与这样的客户的阅读和事务工作变得复杂。
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
在上面的示例中,
id字段很容易无法匹配帐户和客户。 它们通过帐户字段
customer_id和
customer_id id 。 相同的
id字段将破坏帐户主键的唯一性。 而且,碎片无法分片。
下一个问题是重新分片
缓慢 。 这是所有散列碎片的经典问题。 最重要的是,当我们更改集群的组成时,我们通常会更改分片函数,因为分片函数通常取决于节点数。 并且当函数更改时,您需要遍历集群中的所有条目并再次重新计算分片函数。 也许转移一些笔记。 而且,当我们传输它们时,我们不知道下一个传入请求所需的数据是否已经传输,也许它们正在传输过程中。 因此,在重新分片期间,每次读取都必须请求两个分片功能:旧功能和新功能。 请求的速度变慢了两倍,对我们来说这是无法接受的。
Tarantool Shard的另一个功能是,当副本集中的某些节点发生故障时,它将显示
较差的读取可访问性 。
新解决方案
为了解决上述三个问题,我们创建了
Tarantool VShard 。 它的主要区别在于数据存储级别是虚拟化的:虚拟存储出现在物理存储之上,并且记录分布在其中。 这些存储称为bucket'ami。 用户不需要考虑什么以及在哪个物理节点上。 桶是原子不可分割的数据单位,就像经典分片一个元组一样。 VShard始终将整个存储桶存储在一个物理节点上,并且在重新分片期间以原子方式传输一个存储桶的所有数据。 因此,提供了位置。 我们只需要将数据放在一个存储桶中,就可以始终确保该数据将与集群中的所有更改一起存储。

如何将数据放在一个存储桶中? 在我们先前为银行客户引入的方案中,我们将根据新字段将
bucket id添加到表中。 如果链接的数据相同,则记录将位于同一存储桶中。 好处是我们可以将具有相同
bucket id这些记录存储在不同的空间,甚至存储在不同的引擎中。 无论这些记录如何存储,都将提供
bucket id 。
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
为什么我们如此渴望呢? 如果我们有经典的分片,那么数据可以在我们仅有的所有物理存储中蔓延。 在银行的示例中,当请求客户的所有帐户时,您将不得不转到所有节点。 事实证明读取O(N)的难度,其中N是物理存储的数量。 太慢了。
多亏了bucket'am和按
bucket id本地性设置,无论群集大小如何
bucket id我们始终可以在一个请求中从一个节点读取数据。

您需要计算
bucket id并自己分配相同的值。 对于某些人来说,这是一个优势,对于某人来说则是劣势。 我认为您可以选择该函数
bucket id计算
bucket id的优势。
经典分片和带桶的虚拟分片之间的主要区别是什么?
在第一种情况下,当我们更改群集的组成时,我们有两个状态:必须进入的当前状态(旧状态)和新状态。 在过渡过程中,您不仅需要传输数据,还需要重新计算所有记录的哈希函数。 这非常不方便,因为在任何给定时间我们都不知道哪些数据已经传输,哪些数据没有传输。 另外,这既不是可靠的也不是原子的,因为对于具有相同散列函数值的一组记录的原子传输,在需要恢复的情况下有必要持久地存储传输状态。 存在冲突,错误,您必须多次重新启动该过程。
虚拟分片要简单得多。 我们没有两个选定的集群状态,只有桶的状态。 集群变得更具可操作性,它逐渐从一种状态移动到另一种状态。 现在有两个以上的州。 借助平稳的过渡,您可以即时更改余额,删除新添加的存储。 即,平衡的可控制性大大提高,变得精细。
使用方法
假设我们选择了一个用于
bucket id的函数,并将大量数据注入集群,以至于没有更多空间。 现在我们要添加节点,以便数据可以自己移动到它们。 在VShard中,此操作如下进行。 首先,在它们上启动新节点和Tarantools,然后更新VShard配置。 它描述了所有群集成员,所有副本,副本集,母版,分配的URI等。 我们将新节点添加到配置中,并使用
VShard.storage.cfg函数在群集的所有节点上使用它。
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
您还记得,在经典分片中,随着节点数量的变化,分片功能也发生了变化。 在VShard中,这不会发生,我们有固定数量的虚拟存储-bucket'ov。 这是在启动群集时选择的常数。 因此,似乎可伸缩性受到了限制,但实际上并非如此。 您可以选择大量的bucket,ov,数十万。 最主要的是,群集中应该有比副本集最大数量大至少两个数量级的副本。
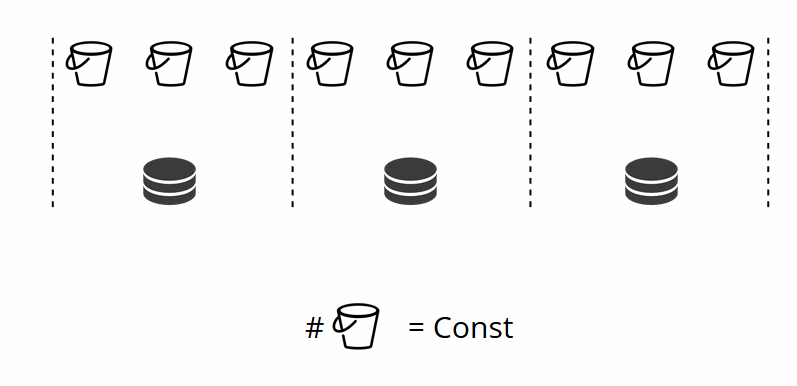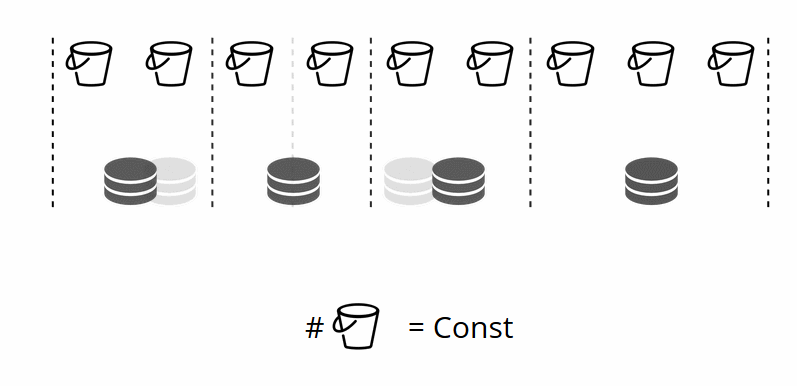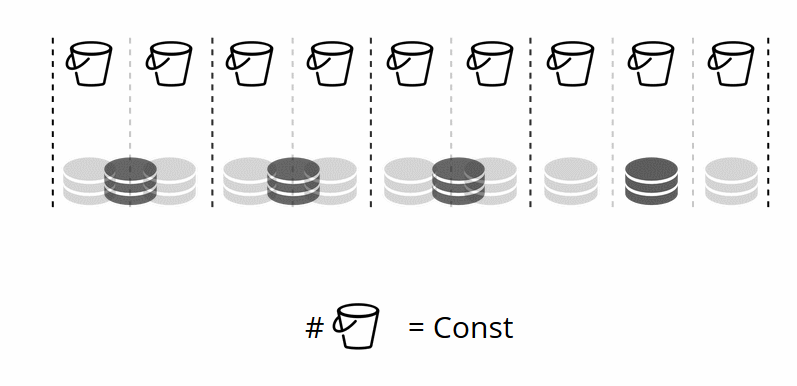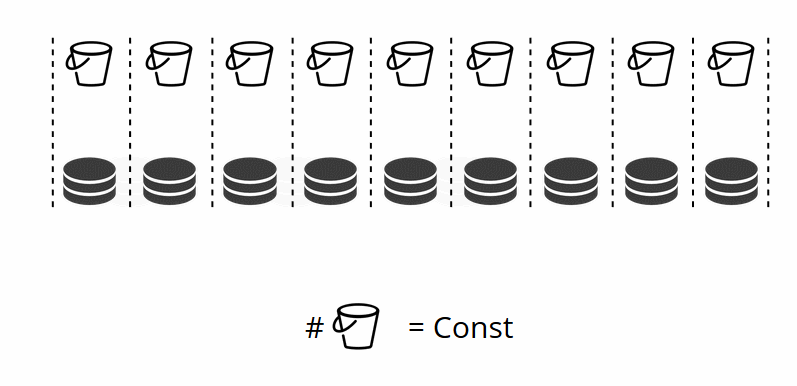
由于虚拟存储的数量不会改变-并且分片功能仅取决于此值-我们可以根据需要添加任意数量的物理存储,而无需重新计算分片功能。
buket如何在实体商店之间自行分配? 在其中一个节点上调用VShard.storage.cfg时,重新平衡过程将唤醒。 这是一个分析过程,可计算出群集中的最佳平衡。 他前往所有物理节点,询问谁拥有多少bucket'ov,并为其移动建立路径以求平均分布。 重新平衡器将路由发送到拥挤的存储,然后它们开始发送存储桶。 一段时间后,群集将变得平衡。
但是在实际项目中,完美平衡的概念可能有所不同。 例如,我要在一个副本集上存储的数据少于在另一个副本集上的数据,因为硬盘空间更少。 VShard认为一切都平衡良好,实际上我的存储空间即将溢出。 我们提供了一种使用权重调整平衡规则的机制。 每个副本集和存储库都可以加权。 当平衡器决定向谁发送多少bucket'ov时,他会考虑所有重量对的
关系 。
例如,一家商店的权重为100,另一家商店的权重为200。那么,第一家商店的存储桶比第二家商店少两倍。 请注意,我在说的
是重量
比 。 绝对含义不起作用。 您可以基于100%的集群分布选择权重:一个商店有30%,另一家商店有70%。 您可以以GB的存储容量为基础,也可以用bucket'ov的数量来衡量权重。 最主要的是观察您需要的态度。
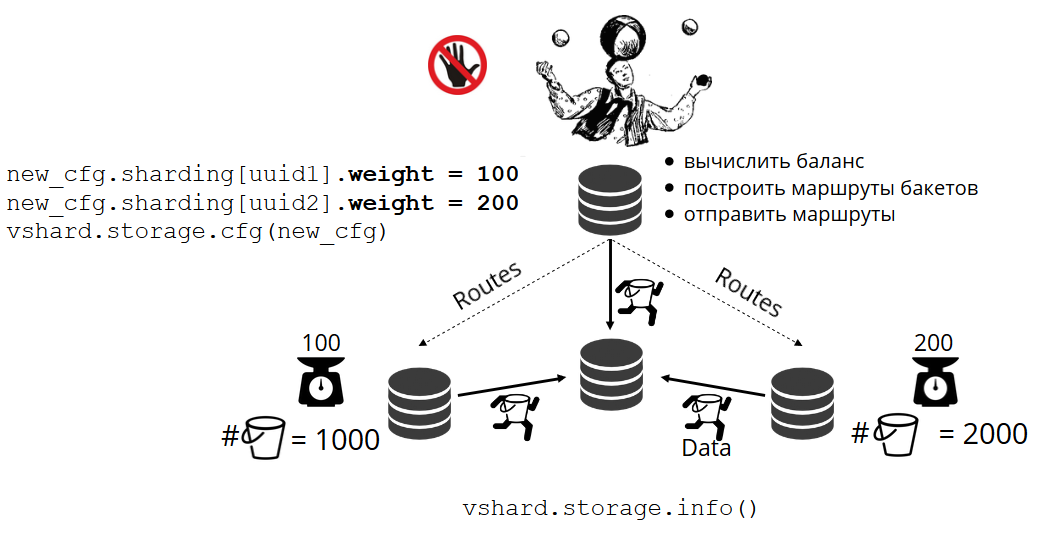
这样的系统有一个有趣的副作用:如果您为某个商店分配零权重,那么平衡器将命令商店分配其所有存储桶。 之后,您可以从配置中删除整个副本集。
原子桶转移
我们有一个存储桶,它接受某种读取和写入请求,然后平衡器要求将其传输到另一个存储。 Bucket停止接受记录请求,否则他们将有时间在传输过程中对其进行更新,然后他们将有时间将可移植更新更新,然后将可移植更新更新,等等,直至无限。 因此,记录被阻止,您仍然可以从存储桶中读取。 开始将块转移到新位置。 传输完成后,存储桶将再次开始接受请求。 在旧的地方,它仍然位于,但是已经被标记为垃圾,随后垃圾收集器将逐块删除它。
每个存储桶都与物理存储在磁盘上的元数据相关联。 以上所有步骤均保存到磁盘,无论存储库发生什么情况,存储桶的状态都会自动恢复。
您可能有问题:
- 当开始使用存储桶时,那些使用存储桶的请求将会发生什么?
每个存储桶的元数据中有两种类型的链接:读取和写入。 当用户向存储桶发出请求时,他会指示如何处理存储桶,只读或读写。 对于每个请求,相应的参考计数器都会增加。
为什么我需要一个参考计数器来阅读请求? 假设存储桶被悄悄地转移了,垃圾收集器来到这里,想要删除这个存储桶。 他看到链接计数大于零,因此您无法删除它。 并且在处理请求时,垃圾收集器将能够完成其工作。
用于写入请求的参考计数器可确保在至少一个写入请求正在处理存储桶时,存储桶甚至不会开始转移。 但是写入请求会不断出现,因此存储桶将永远不会转移。 事实是,如果平衡器表示希望转移它,那么新的记录请求将开始被阻止,并且当前系统将等待某个超时的完成。 如果请求未在指定时间内完成,则系统将再次开始接受新的写请求,从而将存储桶的传输延迟一段时间。 因此,平衡器将进行转移尝试,直到成功为止。
如果您没有一些高级功能,VShard会提供一个低级的bucket_ref API。 如果您真的想自己做某事,只需从代码中访问此API。 - 是否可以完全不阻止记录?
这是不可能的。 如果存储桶包含需要持续写入访问权限的关键数据,则必须完全阻止其传输。 为此,有一个功能bucket_pin ,它将存储桶紧密地连接到当前副本集,以防止其传输。 在这种情况下,相邻的bucket'y将能够不受限制地移动。

有一个比bucket_pin更强大的工具-副本集阻止。 它不再通过代码完成,而是通过配置完成。 阻塞禁止从该副本集“ a”移动任何存储桶和接收新存储桶。 因此,所有数据将始终可用于记录。

VShard.router
VShard由两个子模块组成:VShard.storage和VShard.router。 它们甚至可以在一个实例上独立创建和缩放。 访问群集时,我们不知道哪个存储桶位于何处,VShard.router会根据
bucket id为我们搜索它。
让我们看一个例子。 我们返回银行群和客户帐户。 我希望能够从群集中提取特定客户的所有帐户。 为此,我编写了用于本地搜索的常用函数:
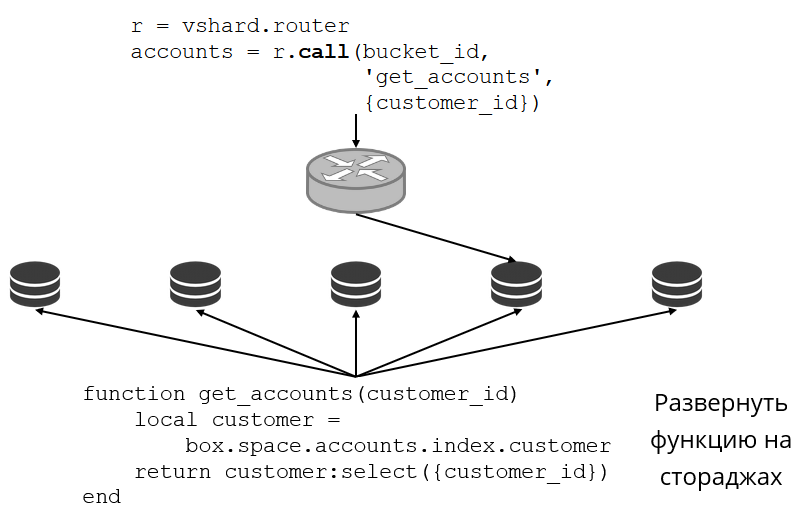
她通过他的ID搜索所有客户帐户。 现在,我需要决定在哪个存储库中调用此函数。 为此,我根据请求中的客户端ID计算
bucket id ID,并要求VShard.router在存储有生成
bucket id的存储桶的存储区中调用此类函数。 子模块中有一个路由表,在其中指定了存储区在副本集中的位置。 VShard.router代理了我的请求。
当然,这可能发生在此时重新分片开始并且铲斗开始移动。 后台的路由器逐步大表更新表:它查询存储库以获取其当前存储桶表。
甚至可能发生了,我们转向刚刚移动的存储桶,而路由器尚未设法更新其路由表。 然后,他将转到旧的存储库,它将告诉路由器在哪里寻找存储桶,或者简单地回答说它没有必要的数据。 然后,路由器将遍历所有存储,以查找所需的存储桶。 所有这些对我们都是透明的,我们甚至不会在路由表中发现任何遗漏。
读取不稳定
回想一下我们最初遇到的问题:
- 没有数据的局部性。 我们决定通过添加bucket'ov。
- 重新分片使一切变慢并且变慢。 实现了原子数据传输bucket'ami,摆脱了重新计算分片功能的麻烦。
- 阅读不稳定。
VShard.router使用自动读取故障转移子系统解决了最后一个问题。
路由器会定期ping通配置中指定的存储。 然后其中一些停止了ping操作。 路由器与每个副本都有热备份连接,如果当前副本停止响应,它将转到另一个副本。 读取请求将被正常处理,因为我们可以读取副本(但不能写入)。 我们可以设置副本的优先级,路由器应通过该副本选择故障转移进行读取。 我们通过分区来做到这一点。
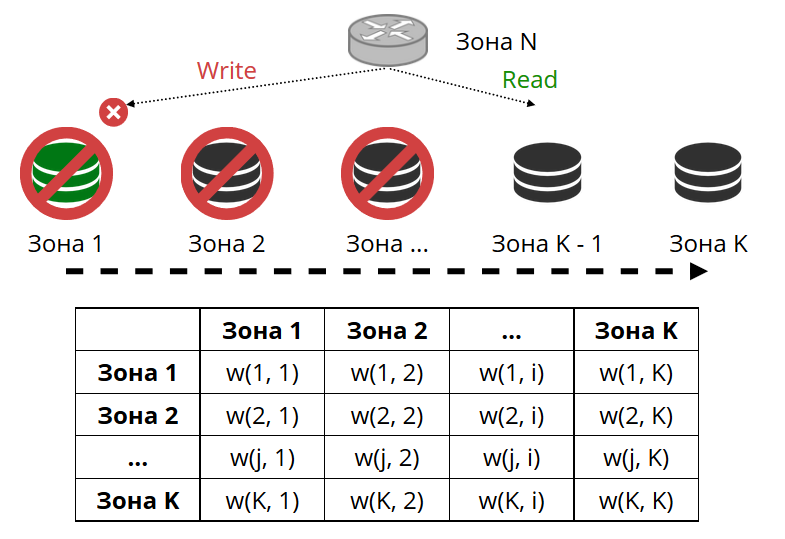
我们为每个副本和每个路由器分配一个区域号,并设置一个表,在其中指示每对区域之间的距离。 当路由器决定将读取请求发送到何处时,它将在最靠近其自身的区域中选择一个副本。
在配置中的外观:
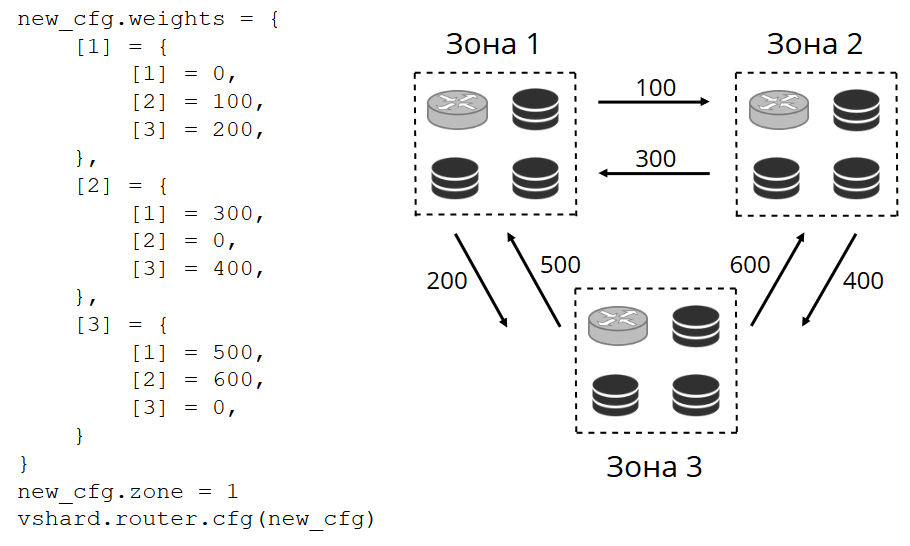
在一般情况下,您可以引用任意副本,但是如果群集很大且很复杂,分布很分散,则分区非常有用。 不同的服务器机架可以是区域,以免使网络负载流量。 也可以是地理上彼此远离的点。
分区还有助于改变副本的性能。 例如,在每个副本集中,我们都有一个备份副本,该副本不应接受请求,而仅存储数据的副本。 然后,我们将其放置在区域中,该区域将与表中的所有路由器相距很远,在最极端的情况下,它们将转向该区域。
记录不稳定
既然我们在谈论读故障转移,那么在更改向导时写故障转移又如何呢? 在这里,VShard并不那么乐观:新的主服务器的选举并未在其中实现,您必须自己做。 当我们以某种方式选择它时,此实例现在必须接管主服务器的权限。 我们通过为旧主机指定
master = false并为新主机指定
master = false来更新配置,通过VShard.storage.cfg应用它并将其滚动到存储中。 然后,一切都会自动发生。 旧的主服务器停止接受写请求,并开始与新的主服务器同步,因为可能已有数据已应用到旧的主服务器,但新的主机尚未到达。 此后,新的主服务器进入角色并开始接受请求,而旧的主服务器成为副本。 这就是VShard中写入故障转移的工作方式。
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
现在如何处理所有这些各种各样的事件?
在一般情况下,两个句柄就足够了
VShard.storage.info和
VShard.router.info 。
VShard.storage.info在几个部分中显示信息。
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
第一个是复制部分。 将显示应用此功能的副本集的状态:它具有哪些复制滞后,与谁建立连接以及与谁不可用,谁可用和不可用,为哪个配置了哪个向导等。
在“存储桶”部分中,您可以实时查看当前有多少存储桶正在移动到当前副本集,有多少存储桶正在离开,有多少当前正在使用它,有多少被标记为垃圾桶,有多少附件。
Alert部分是VShard能够独立确定的所有问题的大杂烩:未配置主服务器,冗余级别不足,主服务器在那儿,但是所有副本都失败,等等。
最后一部分是当情况真的变坏时会亮红色的灯。 它是一个从零到三的数字,数字越差。
VShard.router.info具有相同的部分,但它们的含义有所不同。
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
第一部分是复制。 , : , replica set' , , , replica set' bucket' , .
Bucket bucket', ; bucket' ; , replica set'.
Alert, , , failover, bucket'.
, .
VShard?
— bucket'.
int32_max ? bucket' — 30 16 . bucket', . bucket', bucket'. , .
— -
bucket id . , - , bucket — . , bucket' , VShard bucket'. -, bucket' bucket, -. .
总结
Vshard :
- ;
- ;
- ;
- read failover;
- bucket'.
VShard . - . —
. , . .
—
lock-free bucket' . , bucket' . , .
—
. : - , , ? .