Prometheus 2.6.0优化了WAL加载,从而加快了启动过程。
开发Prometheus 2.x TSDB的非官方目标是加快发布速度,以使发布时间不超过一分钟。 最近几个月,有报道称该过程花费了更长的时间,如果Prometheus由于某种原因而重启,那么这已经是一个问题。 几乎所有时间都加载了WAL(预记录录制),其中包括最近几个小时中尚未压缩成块的样本。 十月下旬,我终于设法弄清楚了。 结果是PR#440 ,这使CPU时间减少了6.5倍,计算时间减少了4倍。 让我们看看我如何进行这些改进。

首先,需要测试设置。 我创建了一个小型Go程序,该程序可以用WAL生成TSDB,并在10,000个时间序列中散布十亿个样本。 然后,我打开了这个TSDB,查看了使用time实用程序(不是内置结构,因为它不包含内存统计信息)花费了多长时间,还使用runtime / pprof包创建了一个CPU配置文件:
f, err := os.Create("cpu.prof") if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile()
CPU配置文件不允许我们直接确定我们感兴趣的计算时间,但是存在很大的相关性。 结果,在我的台式计算机(具有16 GB RAM和固态驱动器的i7-3770处理器)上,下载过程耗时约4分钟,而峰值时的RAM不到6 GB:
1727.50user 16.61system 4:01.12elapsed 723%CPU (0avgtext+0avgdata 5962812maxresident)k 23625165inputs+95outputs (196major+2042817minor)pagefaults 0swaps
这不是嗡嗡声,所以让我们使用go tool pprof cpu.prof加载配置文件,并查看如果使用top命令,该过程将花费多长时间。

这里flat是花在给定功能上的时间,而cum是花在该功能上以及它所调用的所有功能上的时间。 在图形中查看此数据以了解问题也可能很有用。 我更喜欢使用web命令,但是还有其他选项,包括svg,png和pdf文件。
可以看出,大约有三分之一的CPU用于将样本添加到内部数据库中,大约三分之二用于WAL处理,四分之一用于清理内存( runtime.scanobject )。 让我们使用list memSeries.*append来查看其中第一个过程的代码list memSeries.*append
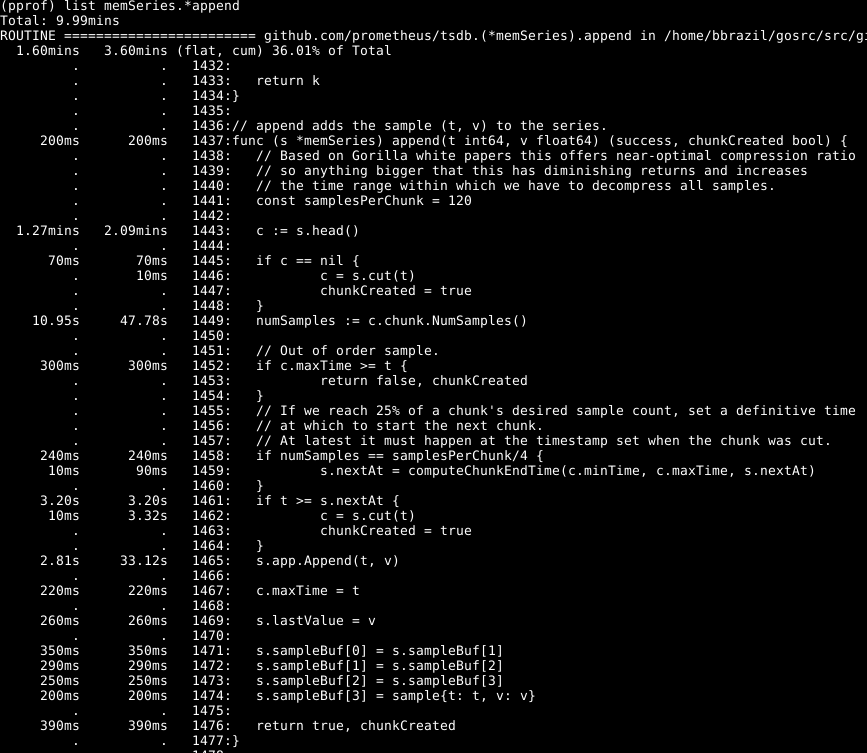
令人震惊的是:在行1443上花费了一半以上的时间来获取该系列的主要数据。另外,在行1449上花费了不少时间来设置该数据中的样本数。完成行1465所花费的时间-预期的,因为这是此功能的核心。 因此,我预计该操作将花费大部分时间。
看一下memSeries.head元素:它计算每次返回的一条数据。 数据片段仅在每添加120次之后发生变化,因此,我们可以将当前的head片段保存在系列的数据结构中 。 这会占用一些RAM( 我将在稍后返回 ),但节省了大量CPU。 总体而言,它还可以加快Prometheus的速度。
然后让我们看一下Head.processWALSamples :
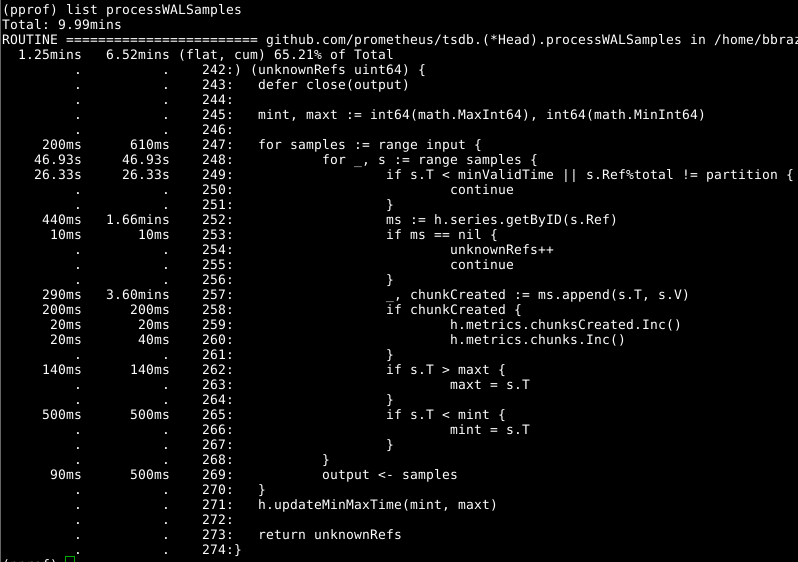
上面已经对该附加组件进行了优化,因此请看一下下一个明显的罪魁祸首,第252行上的getByID :
(代码)
似乎存在某种阻塞冲突,并且在进行两级地图搜索时浪费了时间。 每个标识符的缓存大大减少了该指标。
值得再次看一下Head.processWALSamples ,而您对第249行花了多少时间感到惊讶。让我们再回到WAL加载方式的问题:除了为读取和读取另一个CPU之外,还为每个可用的CPU创建了Head.processWALSamples Head.processWALSamples从磁盘解码WAL。 这些goroutine对行进行了分段,因此并发可能是一个优势。 实现方法如下:将所有样本发送到第一个gorutin,第一个gorutin处理所需的元素。 然后,她将所有样本发送到第二个gorutin,后者处理所需的元素,依此类推,直到最后一个gorutin Head.processWALSamples将所有数据发送回控制gorutin。
同时,附加组件分布在整个内核中(这是您所需要的),每个gorutin中执行许多重复的任务,必须处理所有样本并计算模块。 实际上,核心越多,重复工作就越多。 我进行了更改以对控制器gourutin中的数据进行分段,以便Head.processWALSamples的每个Head.processWALSamples 现在仅获取所需的样本 。 在我的计算机上-运行8个gorutin-虽然节省了一些计算时间,但是CPU体积还不错。 对于具有大量内核的计算机,好处应该更大。
我们再次回到问题:清除内存的时间。 我们通常不能通过CPU配置文件来确定这一点。 相反,请注意动态内存配置文件以找到引人注目的元素。 这需要在程序末尾进行一些代码扩展:
runtime.GC() hf, err := os.Create("heap.prof") if err != nil { log.Fatal(err) } pprof.WriteHeapProfile(hf)
正式内存清除与动态内存中的某些信息相关联,这些信息的收集和清除仅在内存清除期间进行。
我们再次使用相同的工具,但是指定-alloc_space标签,因为我们对所有内存分配操作感兴趣,而不仅是在特定时刻使用内存的操作; 因此,运行go tool pprof -alloc_space heap.prof 。 如果看一下上层分配器,罪魁祸首很明显:
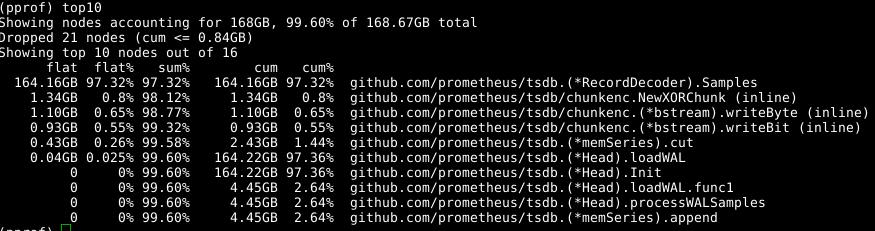
看一下代码:
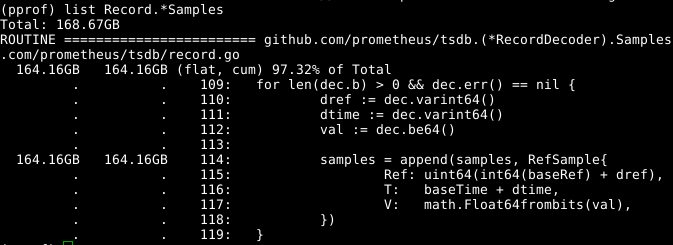
可扩展的samples数组似乎是一个问题。 如果我们可以在调用RecordDecoder.Samples的同时重用该数组,则将节省大量内存。 事实证明,代码是用这种方式编写的,但是很小的编码错误导致它无法正常工作。 如果您对其进行修复 ,则将在CPU的8秒(而不是151秒)内清除内存。
总体结果是很明显的:
269.18user 10.69system 1:05.58elapsed 426%CPU (0avgtext+0avgdata 3529556maxresident)k 23174929inputs+70outputs (815major+1083172minor)pagefaults 0swap
我们不仅将计算时间减少了4倍,将CPU时间减少了6.5倍,而且占用的内存量减少了2 GB以上。
看起来一切都很简单,但是诀窍是这样的:我在代码库中进行了相当大的翻阅,并以事后分析的方式分析了所有内容。 研究代码后,我几次NumSamples ,例如,删除NumSamples调用,在单独的线程中读取和解码以及以多种方式分割processWALSamples 。 我几乎可以肯定,通过调节gorutin的数量,可以实现更多的目标,但是对于这种测试,应该在比我的更强大的机器上进行,以便有更多的内核。 我实现了我的目标:提高生产率,并且我意识到最好不要将程序注册表太大,因此决定在此停下来。