如今,R语言是处理数据的最强大,多功能的工具之一,但众所周知,几乎每桶蜂蜜中都有美中不足。 事实是R默认情况下是单线程的。
这很可能不会使您困扰足够长的时间,并且您不太可能会问这个问题。 但是,例如,如果您面临从API(例如Yandex.Direct)从大量广告帐户收集数据的任务,那么您可以显着减少至少两到三倍的时间来减少使用多线程收集数据的时间。

R中的多线程主题不是新话题,在Habré的此处 , 此处和此处已多次提出,但是上一版出版物的历史可追溯至2013年,正如他们所说的,所有新内容都被遗忘了。 此外,之前讨论了用于计算模型和训练神经网络的多线程,我们将讨论使用异步与API配合使用。 不过,我想借此机会感谢这些文章的作者,因为 他们用他们的出版物为我写这篇文章提供了很大帮助。
目录内容
本文的第二部分提供了有关在R中实现多线程的更现代选项的信息。
什么是多线程
单线程(顺序计算) -一种按顺序执行所有动作(任务)的计算模式,在这种情况下,所有给定操作的总持续时间将等于所有操作的持续时间之和。
多线程(并行计算) -一种计算模式,其中并行执行指定的操作(任务),即 同时,所有操作的总执行时间将不等于所有操作的持续时间之和。
为了简化理解,让我们看一下下表:
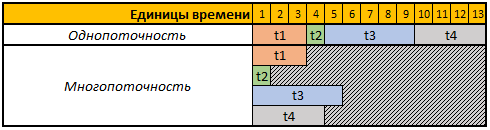
给定表的第一行是有条件的时间单位,在这种情况下,对我们来说,秒,分钟或任何其他时间段都无关紧要。
在此示例中,我们需要执行4个操作,在这种情况下每个操作具有不同的计算持续时间,在单线程模式下,所有4个操作将依次依次执行,因此执行它们的总时间为t1 + t2 + t3 + t4,3 + 1 + 5 + 4 = 13。
在多线程模式下,所有4个任务将并行执行,即 要开始下一个任务,无需等待上一个任务完成,因此,如果我们在4个线程中启动我们的任务,则总计算时间将等于最大任务的计算时间,在本例中是任务t3,在我们的示例中,计算持续时间为5临时单元,在这种情况下所有4个操作的执行时间将等于5个临时单元。
我们将使用哪些软件包
对于多线程模式下的计算,我们将使用foreach , doSNOW和doParallel 。
foreach包允许您使用foreach构造,它实质上是for循环的增强功能。
doSNOW和doParallel本质上是孪生兄弟,允许您创建虚拟集群并使用它们执行并行计算。
在本文的rbenchmark我们将使用rbenchmark包rbenchmark使用以下描述的所有方法来测量和比较Yandex.Direct API中数据收集操作的持续时间。
要使用Yandex.Direct API,我们将使用ryandexdirect包,在本文中,我们将以它为例,有关其功能的更多详细信息,请参见官方文档 。
用于安装所有必需软件包的代码:
install.packages("foreach") install.packages("doSNOW") install.packages("doParallel") install.packages("rbenchmark") install.packages("ryandexdirect")
挑战赛
您必须编写代码,要求从任意数量的Yandex.Direct广告帐户中获取关键字列表。 结果必须在一个日期范围内收集,在该日期范围内,关键字所属的广告帐户的登录将有一个附加字段。
此外,我们的任务是编写一个代码,该代码将在任意数量的广告帐户上尽快执行此操作。
Yandex.Direct中的授权
要使用Yandex.Direct广告平台的API,最初需要在我们计划从中请求关键字列表的每个帐户下进行授权。
本文提供的所有代码均反映了使用常规Yandex.Direct广告帐户的示例,如果您使用代理帐户,则需要使用AgencyAccount参数并将代理帐户登录名传递给它。 您可以在此处使用ryandexdirect包找到有关使用Yandex.Direct代理帐户的更多信息。
为了进行授权,您需要从yadirAuth包中执行yadirAuth函数,对于需要从中请求关键字及其参数列表的每个帐户,都需要重复以下代码。
ryandexdirect::yadirAuth(Login = " ")
尽管ryandexdirect通过第三方站点进行的,但通过ryandexdirect软件包进行的授权过程ryandexdirect完全安全的。 我已经在“使用R包与广告系统API一起使用有多安全”一文中详细讨论了其使用的安全性。
授权后,将在工作目录中的每个帐户下创建一个login.yadirAuth.RData文件,该文件将存储每个帐户的凭据。 文件名将从Login参数中指定的登录名开始。 如果需要将文件保存在当前工作目录中,而不是当前目录中,请使用TokenPath参数,但是在这种情况下,使用yadirGetKeyWords函数请求关键字时yadirGetKeyWords还需要使用TokenPath参数并指定保存文件的文件夹的路径与凭据。
使用for循环的单线程顺序解决方案
一次从多个帐户收集数据的最简单方法是使用for循环。 简单但不是最有效的,因为 R语言开发的原则之一是避免在代码中使用循环。
以下是使用for循环从4个帐户收集数据的示例代码,实际上,您可以使用此示例从任意数量的广告帐户收集数据。
代码1:我们使用通常的for循环处理4个帐户 library(ryandexdirect) # logins <- c("login_1", "login_2", "login_3", "login_4") # res1 <- data.frame() # for (login in logins) { temp <- yadirGetKeyWords(Login = login) temp$login <- login res1 <- rbind(res1, temp) }
使用system.time函数测量运行时显示以下结果:
工作时间:
用户: 178.83
系统: 0.63
通过: 320.39
收集4个帐户的关键字花费了320秒,从yadirGetKeyWords函数在操作过程中显示的信息消息中,可以看到最大的帐户,其中接收了5970个关键字,并处理了142秒。
R中的多线程解决方案
在上面我已经写过,对于多线程,我们将使用doSNOW和doParallel 。
我想提请注意以下事实:几乎所有API都有其自身的局限性,Yandex.Direct API也不例外。 实际上,使用Yandex.Direct API的帮助说:
代表一个用户最多同时允许五个API请求。
因此,尽管在这种情况下我们将考虑创建4个流的示例,但在使用Yandex.Direct的情况下,即使您在同一用户下发送所有请求,也可以创建5个流。 但是最合理的做法是每1个处理器内核使用1个线程,您可以使用parallel::detectCores(logical = FALSE)命令确定物理处理器内核的数量,可以使用parallel::detectCores(logical = TRUE)查找逻辑内核的数量。 在Wikipedia上可以更详细地了解这种物理和逻辑核心是什么。
除了请求数量的限制外,访问Yandex.Direct API的点数每天都有限制,对于所有帐户而言,它可能都不同,根据所执行的操作,每个请求所消耗的点数也不同。 例如,要查询关键字列表,对于完整的查询,您将被扣除15分,而每2000个字词将被扣除3分,您可以在官方证书中找到如何注销这些积分。 您还可以在由yadirGetKeyWords函数返回到控制台的信息消息中查看有关得分和可用分数的信息,以及它们的每日限额。
Number of API points spent when executing the request: 60 Available balance of daily limit API points: 993530 Daily limit of API points:996000
让我们按顺序处理doSNOW和doParallel 。
DoSNOW软件包和多线程功能
我们为多线程计算模式重写相同的操作,在这种情况下创建4个线程,并且使用foreach构造代替for循环。
代码2:使用doSNOW进行并行计算 library(foreach) library(doSNOW) # logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoSNOW(cl) res2 <- foreach(login = logins, # - .combine = 'rbind', # .packages = "ryandexdirect", # .inorder=F ) %dopar% {cbind(yadirGetKeyWords(Login = login), login) } stopCluster(cl)
在这种情况下,使用system.time函数测量运行时将显示以下结果:
工作时间:
使用者: 0.17
系统: 0.08
通过: 151.47
相同的结果 我们在151秒内,即从4个Yandex.Direct帐户收到了关键字集合。 快2倍。 另外,我在上一个示例中写道,从最大的帐户加载关键字列表需要多长时间(142秒),即 在此示例中,总时间几乎与最大帐户的处理时间相同。 事实是,借助foreach函数,我们同时启动了以4个流(即 同时从所有4个帐户中收集数据,总时间等于最大帐户的处理时间。
我makeCluster 代码2进行一些说明, makeCluster函数负责线程的数量,在这种情况下,我们创建了一个由4个处理器核心组成的集群,但是正如我先前在使用Yandex.Direct API时所写的那样,无论有多少个帐户,您都可以创建5个线程您需要处理5-15-100或更多,您可以同时向API发送5个请求。
接下来, registerDoSNOW函数启动创建的集群。
之后,我们使用了foreach构造,如我之前所说,该构造是for循环的改进。 您将计数器指定为第一个参数,在我命名为示例的示例中,它将在每次迭代时遍历logins向量的元素,如果我们for ( login in logins)编写for ( login in logins) ,则会在for循环中获得相同的结果。
接下来,您需要在.combine参数中指定将合并每次迭代获得的结果的函数,最常见的选项是:
rbind将结果表彼此逐行连接;cbind将结果表连接到列中;"+" -总结每次迭代获得的结果。
您还可以使用任何其他功能,甚至可以自己编写。
如果您不关心合并结果的顺序,则参数.inorder = F可以使您加快功能的速度,在这种情况下,顺序对我们而言并不重要。
接下来是%dopar%运算符,它将在并行计算模式下启动循环,如果使用%do%运算符,则将依次执行迭代,以及使用常规的for循环时。
stopCluster函数停止集群。
多线程,或者说多线程模式下的foreach构造,具有一些功能,实际上,在这种情况下,我们在一个全新的干净R会话中启动每个并行进程。 因此,为了使用其中在foreach构造外部定义的通用函数和内部对象,您需要使用.export参数导出它们。 此参数采用文本向量,其中包含要在foreach使用的对象的名称。
另外,在并行模式下, foreach在默认情况下不会看到以前连接的软件包,因此,还需要使用.packages参数将它们传递到foreach内部。 还需要通过在文本向量中列出软件包的名称来传输软件包,例如.packages = c("ryandexdirect", "dplyr", "lubridate") 。 在上面的代码示例2中 ,我们只是以这种方式在foreach每次迭代中加载ryandexdirect包。
DoParallel套餐
正如我在上面所写, doSNOW和doParallel是双胞胎,因此它们具有相同的语法。
代码5:使用doParallel进行并行计算 library(foreach) library(doParallel) logins <- c("login_1", "login_2", "login_3", "login_4") cl <- makeCluster(4) registerDoParallel(cl) res3 <- data.frame() res3 <- foreach(login=logins, .combine= 'rbind', .inorder=F) %dopar% {cbind(ryandexdirect::yadirGetKeyWords(Login = login), login) stopCluster(cl)
工作时间:
使用者: 0.25
系统: 0.01
通过: 173.28
如您所见,在这种情况下,执行时间与使用doSNOW包的并行计算代码的上一个示例稍有不同。
三种方法之间的速度测试
现在,使用rbenchmark软件包运行速度测试。
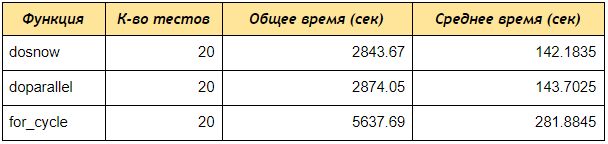
如您所见,即使在4个帐户的测试中, doSNOW和doParallel通过关键字接收数据的速度也比顺序for循环快2倍,如果您创建5个内核的集群并处理50或100个帐户,则差异将更加明显。
代码6:用于比较多线程和顺序计算速度的脚本 # library(ryandexdirect) library(foreach) library(doParallel) library(doSNOW) library(rbenchmark) # for for_fun <- function(logins) { res1 <- data.frame() for (login in logins) { temp <- yadirGetKeyWords(Login = login) res1 <- rbind(res1, temp) } return(res1) } # foreach doSNOW dosnow_fun <- function(logins) { cl <- makeCluster(4) registerDoSNOW(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login } }) stopCluster(cl) return(res2) } # foreach doParallel dopar_fun <- function(logins) { cl <- makeCluster(4) registerDoParallel(cl) res2 <- data.frame() system.time({ res2 <- foreach(login=logins, .combine= 'rbind') %dopar% {temp <- ryandexdirect::yadirGetKeyWords(Login = login) } }) stopCluster(cl) return(res2) } # within(benchmark(for_cycle = for_fun(logins = logins), dosnow = dosnow_fun(logins = logins), doparallel = dopar_fun(logins = logins), replications = c(20), columns=c('test', 'replications', 'elapsed'), order=c('elapsed', 'test')), { average = elapsed/replications })
总而言之,我将对上面的代码5进行解释,以此来测试工作速度。
最初,我们创建了三个函数:
for_fun从多个帐户请求关键字的功能, for_fun周期对它们进行顺序排序。
dosnow_fun使用doSNOW包以多线程模式请求关键字列表的函数。
dopar_fun使用doParallel包以多线程模式请求关键字列表的函数。
接下来,在内部构造中,我们从rbenchmark包运行benchmark函数,指定测试的名称(for_cycle,dosnow,doparallel),每个函数分别指定函数: for_fun(logins = logins) ; dosnow_fun(logins = logins) ; dopar_fun(logins = logins) 。
复制参数负责测试的数量,即 每个函数将运行多少次。
columns参数允许您指定要接收的列,在我们的例子中,'test','replications','elapsed'意味着要返回这些列:测试名称,测试数量,所有测试的总执行时间。
您还可以添加计算出的列(( { average = elapsed/replications } ),即 输出将是一个平均列,它将用总时间除以测试次数,因此我们计算每个函数的平均执行时间。
订单负责对测试结果进行排序。
结论
在本文中,原则上描述了一种相当通用的方法来加速API的工作,但是每个API都有其局限性,因此,特别是在这种形式下,具有如此多的线程,以上示例适用于Yandex.Direct API,可以与API一起使用对于其他服务,最初需要阅读有关API中同时发送的请求数限制的文档,否则可能会收到“ Too Many Requests错误。
本文的续篇在这里提供 。