
机器学习在我们生活的许多领域都得到了积极使用。 算法有助于识别交通标志,过滤垃圾邮件,识别我们的朋友在Facebook上的面孔,甚至有助于在证券交易所进行交易。 该算法会做出重要的决定,因此您需要确保它不会被欺骗。
在本系列文章的第一篇中,我们将向您介绍机器学习算法的安全性问题。 不需要从读者那里获得高水平的机器学习知识,就足以拥有该领域的一般知识。
首先,我们给出机器学习算法安全性主题中使用的术语:
一个对抗示例是向矢量提供输入的矢量,该算法在该矢量上产生错误的输出。
对抗攻击 -一种动作算法,目的是获得对抗示例。
为了理解对抗性示例的问题,让我们回想一下机器学习的任务之一-在评分中与老师一起学习。 在这个问题中,我们有“对象-标签”对,我们必须学习预测新对象的价值。
如果我们从几何学的角度考虑这个问题,则有必要划分空间,以预测新对象的“正确”类。 而且,如果我们有一个通用的数据集(例如,对于一组手写数字MNIST,具有所有数字的各种图像),那么只要这些类是可分离的,则可以理想地执行此超平面。 但是由于总人口不多,为了解决这个问题,我们使用机器学习算法使用已有的数据尽可能准确地近似“理想”超平面。
超平面与理想平面的任何偏离都会引起一定的“间隙”,从而导致物体分类错误。 这就是为什么出现像大熊猫这样的例子的原因。 而且,攻击者的任务被简化为更改对象参数的向量,以使其落入此“空白”。
对抗攻击的例子
有一个神经网络可以检测照片中的面部。 她成功地完成了任务(左图)。 但是,在向这张照片添加少量噪点(右图)后,所获得的对抗示例(中心图)上的算法不再检测到图像中的脸部。

该示例在文章“ 使用基于神经网络的约束优化的人脸检测器的对抗性攻击 ”中得到了展示,因为许多实际的人脸识别系统都使用神经网络方法来检测人脸,因此该示例很有趣。 在观看两个图像时,人都不会注意到差异。
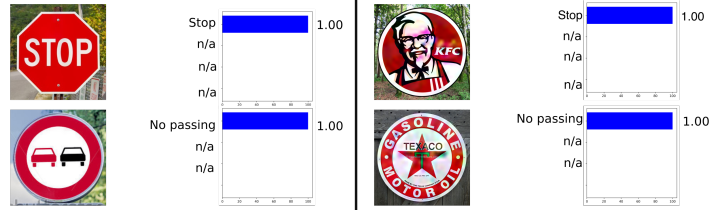
以下示例取自汽车,即交通标志识别。 该示例很有趣,因为对抗示例不必是至少在某种程度上接近训练网络的对象的对象。 例如,在“ 恶意标志:利用恶意广告和徽标识别交通标志识别”中,表明肯德基标志的对抗示例将被原始神经网络“识别”为STOP标志,概率为100%。
许多人可能会怀疑在现实世界中使用对抗性示例,因为先前的示例是在计算机上测试过的,而在现实生活中,很难获得这样的对象。 但是事实并非如此。 综合强大的对抗性示例表明,在计算机上制作的对抗性示例可以成功地在3D打印机上打印,并且该算法会犯与计算机模拟相同的错误。

在这里,您会看到在3D打印机上打印的乌龟,无论在任何角度都无法识别为乌龟。
以下示例显示了如果我们对对抗攻击的理解超出常规,该怎么办。 即,对源网络进行重新编程以使用其自己的有效负载。 换句话说,我们学会使用别人的神经网络来解决攻击者提出的问题。 例如, 神经网络的对抗性重新编程演示了在ImageNet上训练的网络如何完美地计算图像中的平方数并从MNIST集合中识别出该数。
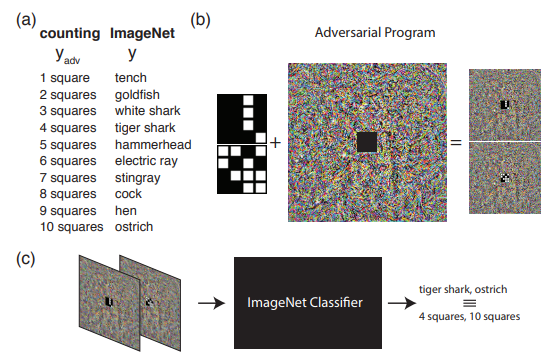
该图演示了用于对抗性重新编程的算法,建议您在原始文章中更好地了解该算法。
在本文中,我想专门讨论生成对抗性示例的方法,在第二篇文章中,我们将继续介绍保护和测试机器学习算法的方法。
攻击分类
所有攻击都可以分为2类: WhiteBox(WB)和BlackBox(BB) 。 在WB的情况下,我们知道有关算法训练模型的所有信息,而在BB的情况下,我们只能访问模型的输入和输出。 实际上,当我们不知道关于训练模型的信息,但是有关于算法类型及其超参数的信息时,GrayBox选项仍然可行。 但是这种类型在单独的类别中并不突出,因为附加信息不足以传递给WB,这意味着这只是进行BB攻击的附加信息集。
接下来,值得对Targeted和Non Targeted的攻击进行分类。 有针对性的攻击是指在特定方向上进行攻击。 例如,在MNIST数据集上,我们训练神经网络并从测试集中获取图像0。 经过训练的神经网络在该对象中产生的0类概率为1.00。 如果我们希望在应用对抗攻击后将对抗示例识别为1类,那么我们将使用目标攻击。 否则,如果对于我们来说神经网络将接收图像的类别不是特别重要(主要是它不再是0类),那么这种攻击将是非针对性的。
此外,根据两个对象被视为相似的对象,攻击被分为一个指标- 规范。 norm-更改的参数数。 两个向量之间的欧式距离。 两个向量之间的最大逐元素差异。
Python库
Python资料库可让您使用对抗性范例。 它们是FoolBox,CleverHans和ART-IBM。
| 傻瓜盒子 | Cleverhans | IBM公司 |
|---|
| 支持的框架 | TensorFlow,Keras,Theano,PyTorch,Lasagne,MXNet | TensorFlow,Keras | TensorFlow,Keras,诺言MXNet,PyTorch |
现在,让我们更详细地了解攻击,并从WhiteBox攻击开始。
L-BFGS攻击
L-BFGS方法的语句可以编写如下。
由此得出结论,我们希望在目标类别的方向上使损失函数最小化,并限制引入的更改最小。 同时,有人提出在原始文章中使用L-BFGS方法解决此问题,因此将其称为“攻击”。
原始文章- 神经网络的有趣特性
在3个以前带有声音的库中,有2个存在这种攻击-FoolBox和CleverHans。
这种针对FoolBox的攻击在Python中需要3行代码:
from foolbox.attacks import LBFGSAttack attack = LBFGSAttack(fmodel) adversarial = attack(image, label)
使用L-BFGS将帮助您根据自己的局限性找到最佳的对抗示例,但是,首先,搜索这样的示例可能会花费很长时间,其次,该方法很可能不会收敛。
FGSM攻击
下一阶段的开发是FGSM(快速梯度算法),可以使用以下公式显示:
该方法比L-BFGS更快。 在这里,我们只是从原始损失函数的梯度函数中提取符号,然后将符号乘以 ,添加到原始图像。

这是此方法如何工作的示例。 噪声图 等于0.007,事实证明熊猫的照片现在被识别为长臂猿,概率为99.3%
此方法易于实现,但与此同时,此方法的结果也很嘈杂。
原始文章- 解释和利用对抗性示例
您可以在库中找到此方法的实现,并且使用foolbox也不会花费很多时间。
from foolbox.attacks import FGSM attack = FGSM(fmodel) adversarial = attack(image, label)
傻瓜攻击
DeepFool是一种非目标方法。 它与以前的方法的主要区别在于,它试图制作一个最小的噪声图,它将欺骗算法。 该方法不允许您从一个类中选出一个特定的类,但可以进行与原始图像最接近的任何其他类。

一个示例在底线(FGSM方法)和中间的原始图片中显示了DeepFool攻击。 可以看出,噪声卡比FGSM小得多。
原始文章-DeepFool:愚弄深度神经网络的一种简单而准确的方法
可以使用任何列出的库来进行这种攻击,并且在ART-IBM上的实现只需三行代码:
from art.attacks import DeepFool attack = DeepFool(model) img_adv = attack.generate(img)
雅可比显着性图攻击
在JSMA方法中,考虑了直接导数,并以此为基础构建了梯度图。 在地图上,对象的每个参数实际上都对应于该参数对更改算法最终结果的贡献。 因此,该方法允许您在受攻击的对象中更改尽可能少的参数。 并且,因此,它适用于 正常
原始文章- 对抗环境中深度学习的局限性
可以使用CleverHans或ART-IBM进行此攻击。 在CleverHans上,它看起来像这样:
from cleverhans.attacks import SaliencyMapMethod jsma = SaliencyMapMethod(model, sees=sees) jsma_params = { 'theta' : 1., 'gamma' : 0.1, 'clip_min' : 0., 'clip_max' : 1., 'y_target' : None} adv_x = jsma.generate_np(img, **jsma_params)
一像素攻击
逻辑上的问题是,为了对算法进行攻击,需要更改的最小像素数是多少,并且正如攻击名称中已经猜到的那样,一个像素就足够了。

例如,仅改变一个像素的一匹马的图像就变成了一只青蛙,概率为99.9%
原始文章- 愚弄深度神经网络的一次像素攻击
仅FoolBox支持此攻击,其实现如下:
from foolbox.attacks import SinglePixelAttack attack = SinglePixelAttack(fmodel) adversarial = attack(image,max_pixel=1)
值得保留的是,与原始文章相比,Foolbox中算法的实现虽然有一个共同的目标(改变图像中特定的像素数量),但在获取图像的方法上却有所不同。
基于BlackBox模型泛化的方法
大多数方法都需要了解模型的体系结构如何构造,其参数的确切值的知识,但实际上这是不可能的。 这就是为什么出现单独的攻击方向的原因-BlacBox / GrayBox攻击。 对于此类攻击,访问模型的输入和输出就足够了。
对BlackBox模型实施攻击的方法之一是将该模型概括为Student模型(在Substitute图片中)。
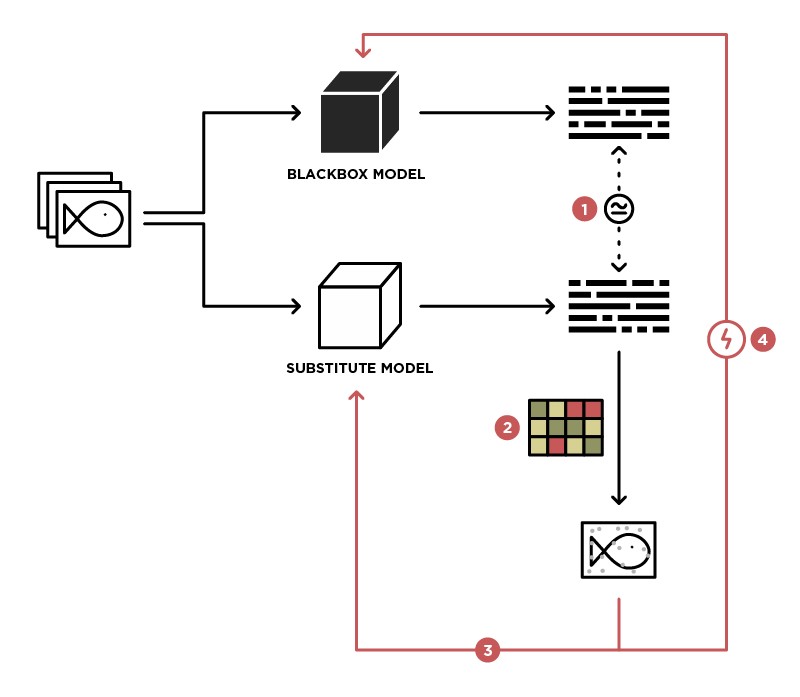
有权将数据发送到BlackBox模型(教师)并访问该模型的输出,我们可以创建一个数据集,可以在该数据集上训练我们自己的模型(学生),从而推广教师模型。 之后,您可以对Student模型使用WhiteBox攻击,并且这种攻击也很有可能在Teacher模型上发生。 发生这种攻击的可能性越高,我们对教师模型的了解就越多。 例如,我们知道教师模型会处理图像,最常见的是将具有ImageNet权重的预训练体系结构(ResNet,Inception)用于图像处理。 基于具有相同体系结构的Student模型,成功攻击的可能性将最大化。
原始文章- 针对机器学习的实用黑匣子攻击
该方法未在任何库中提供,并且需要独立实现Student模型,并且可以使用上述方法对它进行攻击。
基于GAN的方法
BlackBox攻击发展的下一阶段是基于将BlackBox模型嵌入到生成对抗网络(GAN)的体系结构中的攻击,GAN是一种允许生成新对象的网络,该网络随后将被转移到Black-Box模型中。
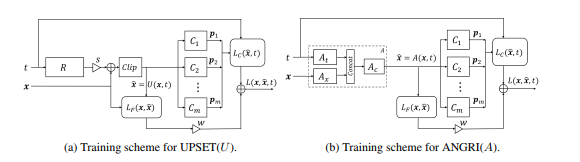
这种方法可以生成几乎所有架构的对抗示例。 它还需要访问受攻击模型的入口和出口。
在原始文章-UPSET和ANGRI:破坏高性能图像分类器中了解有关此方法的更多信息。
您可能已经猜到了,这些方法在任何库中都没有表示。
结论
实际上,存在大量的攻击。 本文仅涵盖其中的一些。 我们希望该材料可以帮助您了解对抗性示例的基本概念及其生成算法。 如需更详细的评论,建议您从参考文献列表中阅读原始文章和材料。
在下一篇文章中见,它将重点介绍保护和测试机器学习算法的方法。
参考文献
- 计算机视觉中深度学习的对抗性攻击威胁:一项调查 -计算机视觉中深度学习算法的攻击方法概述
- 使用对抗性示例攻击机器学习 -专门针对对抗性示例的OpenAI博客
- 出色的Adversarial机器学习 -github上有许多有关Adversarial主题的有用材料的链接
- 对抗机器学习演示-莫斯科PythonConf2018对抗机器学习会议的演示