引言
在上一篇文章(
“第2部分:使用赛普拉斯PSoC UDB块减少3D打印机中的中断数” )中,我提到了一个非常有趣的事实:如果UDB中的计算机从FIFO中删除数据的速度过快,它会设法注意到有新的状态。 FIFO中没有数据,之后数据进入错误状态
Idle 。 当然,我对这个事实很感兴趣。 我向一群熟人展示了打开的结果。 一个人回答说,这很明显,甚至说出了原因。 其余的内容与我刚开始研究时一样感到惊讶。 因此,一些专家不会在这里找到任何新东西,但是最好将此信息带给公众,以便所有微控制器程序员都可以想到。
并不是说这是某种掩护的崩溃。 事实证明,所有这些都已被很好地记录在案,但是麻烦在于不是在主要文件中,而是在其他文件中。 就我个人而言,我感到很无知,因为DMA是一个非常灵活的子系统,可以显着提高程序的效率,因为系统地进行了数据传输,而不会分散寄存器的增量,也不会将循环组织为相同的命令。 至于提高效率-一切都是正确的,但由于情况略有不同。
但是首先是第一件事。
赛普拉斯PSoC实验
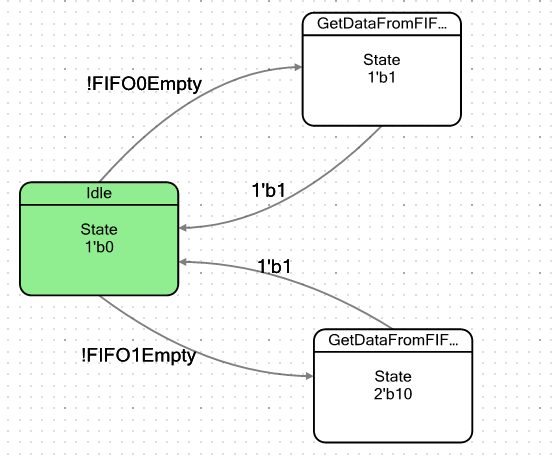
让我们做一个简单的机器。 它有条件地具有两种状态:空闲状态和当FIFO中至少有一个字节数据时它将进入的状态。 进入此状态,他将仅获取此数据,然后再次处于休息状态而失败。 我没有偶然地引用“有条件的”一词。 我们有两个FIFO,因此我将创建两个这样的状态,每个FIFO一个,以确保它们的行为完全相同。 机器的过渡图如下所示:
退出空闲状态的标志定义如下:
不要忘记将状态号的位提交到数据路径输入:

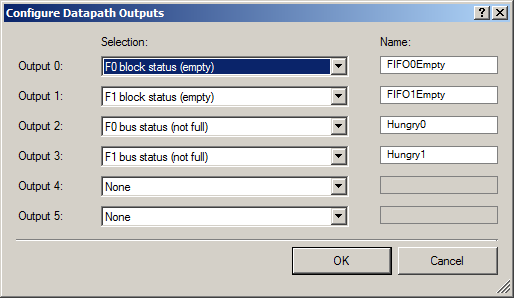
在外部,我们输出两组信号:一对FIFO有可用空间的信号(以便DMA可以开始向其上载数据),以及一对FIFO空的信号(以在示波器上显示这一事实)。

ALU只是虚拟地从FIFO中获取数据:

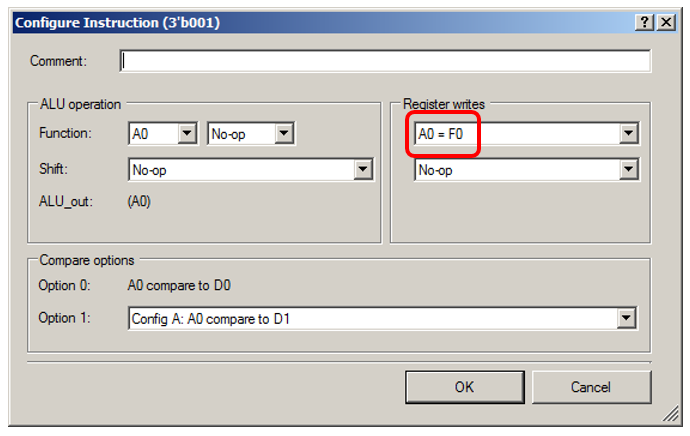
让我向您显示状态“ 0001”的详细信息:
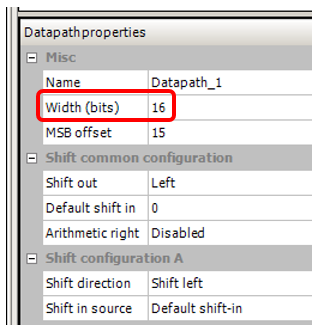
我还设置了总线宽度,该宽度在我注意到此效果的项目中为16位:
我们进入项目本身的计划。 在外部,我不仅发出FIFO为空的信号,还发出时钟脉冲。 这将使我无需在示波器上进行光标测量。 我可以用手指采取措施。
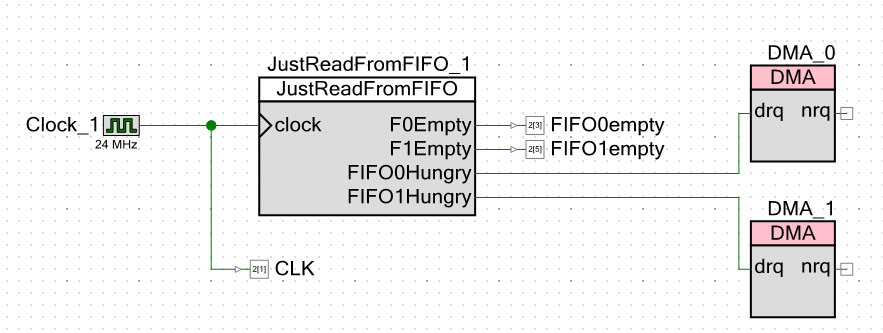
显然,我的时钟速度为24兆赫。 处理器核心频率完全相同。 频率越低,在中国示波器上的干扰就越少(官方的示波器带宽为250 MHz,但随后为中国兆赫兹),并且所有测量都将针对时钟脉冲进行。 无论频率如何,系统都将相对于它们工作。 我本来会设置一个兆赫兹,但是开发环境禁止我输入小于24 MHz的处理器核心频率值。
现在测试的东西。 要写入FIFO0,我做了以下功能:
void WriteTo0FromROM() { static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; // DMA , uint8 channel = DMA_0_DmaInitialize (sizeof(steps[0]),1,HI16(steps),HI16(JustReadFromFIFO_1_Datapath_1_F0_PTR)); CyDmaChRoundRobin (channel,1); // , uint8 td = CyDmaTdAllocate(); // . , . CyDmaTdSetConfiguration(td, sizeof(steps), CY_DMA_DISABLE_TD, TD_INC_SRC_ADR / TD_AUTO_EXEC_NEXT); // CyDmaTdSetAddress(td, LO16((uint32)steps), LO16((uint32)JustReadFromFIFO_1_Datapath_1_F0_PTR)); // CyDmaChSetInitialTd(channel, td); // CyDmaChEnable(channel, 1); }
函数名称中的ROM一词是由于以下事实:要发送的阵列存储在ROM区域中,并且Cortex M3具有哈佛架构。 我想检查一下对RAM总线和ROM总线的访问速度可能会有所不同,因此我具有从RAM发送数组的类似功能(
步骤数组的主体中没有
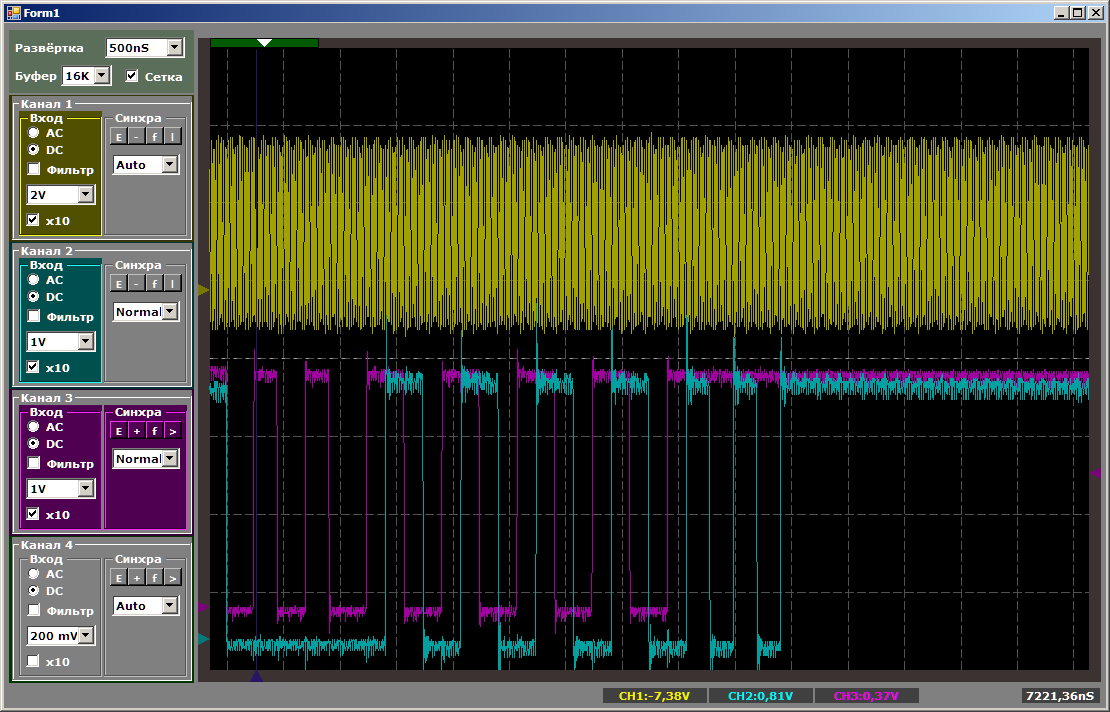
静态const修饰符)。 好了,有一对发送到FIFO1的函数,接收器寄存器在那里不同:不是F0,而是F1。 否则,所有功能都相同。 由于我没有注意到结果有太大差异,因此我将考虑完全调用上述函数的结果。 黄色射线时钟脉冲,蓝色输出
FIFO0empty 。

首先,检查在两个时钟周期内为何填充FIFO的合理性。 让我们更详细地查看该站点:
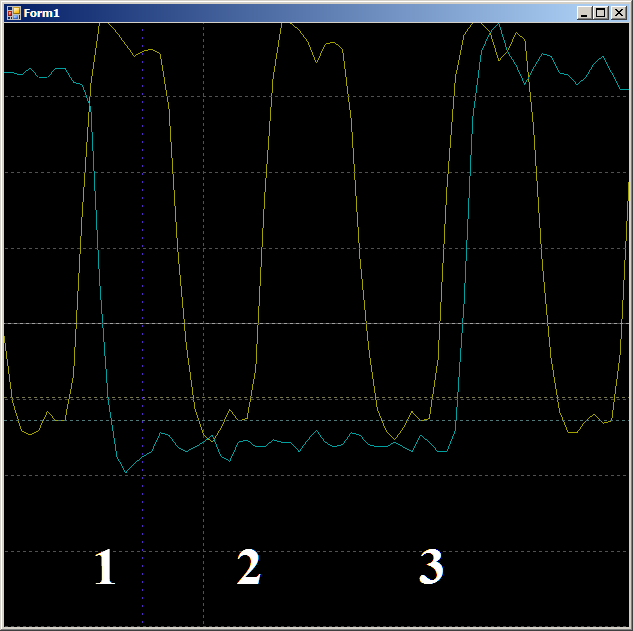
在边沿1,数据落入FIFO,
FIFO0enmpty标志下降。 在边缘2上,自动机进入
GetDataFromFifo1状态。 在边缘3上,在这种状态下,来自FIFO的数据被复制到ALU寄存器,FIFO被清空,
FIFO0empty标志再次
升高 。 也就是说,波形表现合理,您可以依靠它的时钟周期。 我们得到9件。
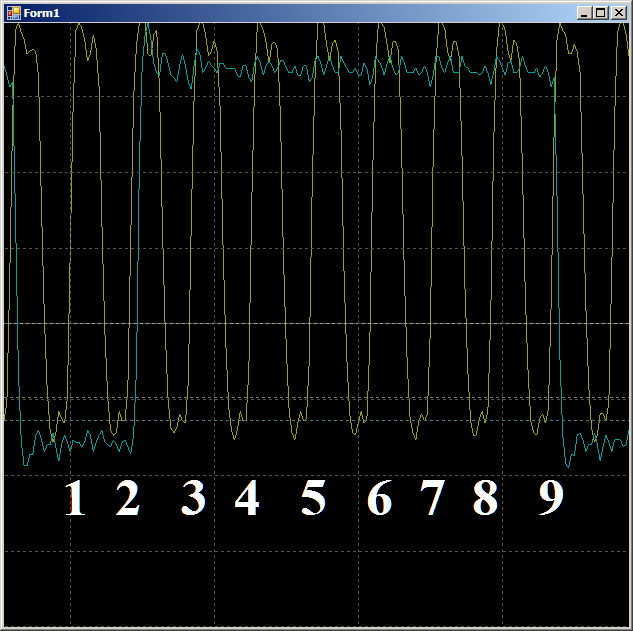 总的来说,在被检查的区域中,需要9个时钟周期才能使用DMA将一个数据字从RAM复制到UDB。
总的来说,在被检查的区域中,需要9个时钟周期才能使用DMA将一个数据字从RAM复制到UDB。现在,同样的事情有了,但是有了处理器核心的帮助。 首先,在现实生活中很难实现的理想代码:
volatile uint16_t* ptr = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; ptr[0] = 0; ptr[0] = 0;
什么会变成汇编代码:
ldr r3, [pc, #8] ; (90 <main+0xc>) movs r2, #0 strh r2, [r3, #0] strh r2, [r3, #0] bn 8e <main+0xa> .word 0x40006898
没有休息,没有额外的周期。 连续两对措施...
让我们使代码更真实一些(组织循环,获取数据和增加指针的开销):
void SoftWriteTo0FromROM() { // . // static const uint16 steps[] = { 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001, 0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001,0x0001 }; uint16_t* src = steps; volatile uint16_t* dest = (uint16_t*)JustReadFromFIFO_1_Datapath_1_F0_PTR; for (int i=sizeof(steps)/sizeof(steps[0]);i>0;i--) { *dest = *src++; } }
收到的汇编代码:
ldr r3, [pc, #14] ; (9c <CYDEV_CACHE_SIZE>) ldr r0, [pc, #14] ; (a0 <CYDEV_CACHE_SIZE+0x4>) add.w r1, r3, #28 ; 0x28 ldrh.w r2, [r3], #2 cmp r3, r1 strh r2, [r0, #0] bne.n 8e <main+0xa>
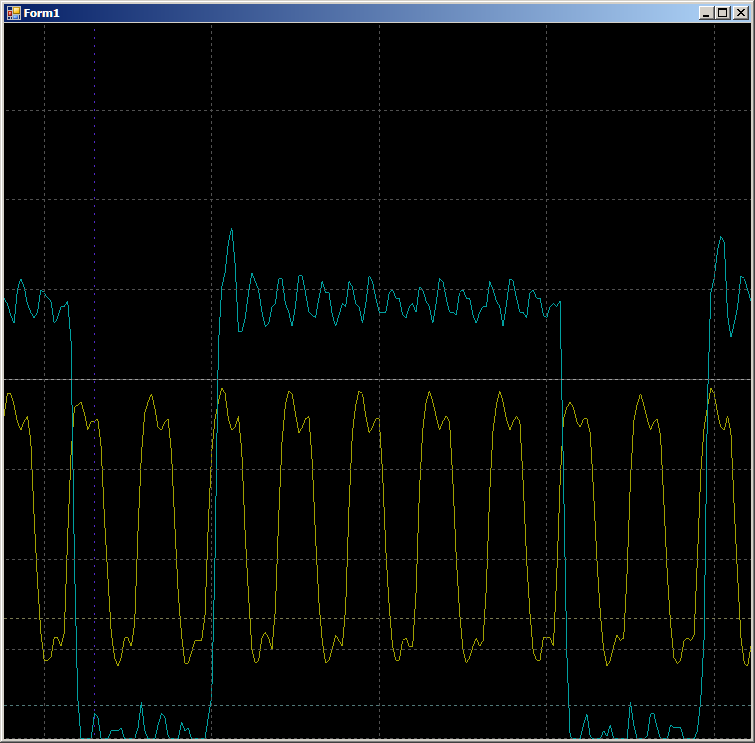
在波形图中,我们看到每个周期只有7个周期,而在DMA的情况下是9个周期:
关于神话的一点
老实说,对我而言,这本来就是震惊。 我曾经以某种方式相信DMA机制可让您快速有效地传输数据。 总线频率的1/9并不是那么快。 但事实证明,没有人隐藏它。 PSoC 5LP的TRM文档甚至包含许多理论上的考虑,文档“ AN84810-PSoC 3和PSoC 5LP Advanced DMA主题”详细描述了访问DMA的过程。 延迟是罪魁祸首。 与总线的交换周期需要一定的滴答声。 实际上,正是这些措施在延误的发生中起着决定性的作用。 通常,没有人隐藏任何东西,但是您需要知道这一点。
如果FX2LP(赛普拉斯制造的另一种架构)中使用的著名的GPIF没有任何限制,则速度限制是由于访问总线时出现的延迟引起的。STM32上的DMA检查
我印象深刻,因此决定在STM32上进行实验。 将具有相同Cortex M3处理器内核的STM32F103用作实验兔。 它没有可以从中导出服务信号的UDB,但是很有可能检查DMA。 什么是GPIO? 这是公共地址空间中的一组寄存器。 很好 我们在“内存-内存”复制模式下配置DMA,将实内存(ROM或RAM)指定为源,将不增加地址的GPIO数据寄存器指定为接收器。 我们将交替发送0或1,并用示波器固定结果。 首先,我选择端口B,在面包板上连接它更加容易。

我真的很喜欢用手指而不是光标来计算度量。 是否可以在此控制器上执行相同的操作? 挺好的! 从连接到STM32F10C8T6的PA8端口的MCO支路获取示波器的参考时钟频率。 这种廉价晶体的信号源选择并不多(与STM32F103相同,但更令人印象深刻,它提供了更多选择),我们将向该输出发送SYSCLK信号。 由于MCO上的频率不能高于50 MHz,因此我们将整体系统时钟速度降低到48 MHz。 我们将8 MHz石英的频率不乘以9,而是乘以6(因为6 * 8 = 48):

相同的文字: void SystemClock_Config(void) { RCC_OscInitTypeDef RCC_OscInitStruct; RCC_ClkInitTypeDef RCC_ClkInitStruct; RCC_PeriphCLKInitTypeDef PeriphClkInit; /**Initializes the CPU, AHB and APB busses clocks */ RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSE; RCC_OscInitStruct.HSEState = RCC_HSE_ON; RCC_OscInitStruct.HSEPredivValue = RCC_HSE_PREDIV_DIV1; RCC_OscInitStruct.HSIState = RCC_HSI_ON; RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON; RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE; // RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL9; RCC_OscInitStruct.PLL.PLLMUL = RCC_PLL_MUL6; if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK) { _Error_Handler(__FILE__, __LINE__); }
我们将使用Konstantin Chizhov的
mcucpp库对MCO进行
编程 (从现在开始,我将通过这个奇妙的库对设备进行所有调用):
// MCO Mcucpp::Clock::McoBitField::Set (0x4); // MCO Mcucpp::IO::Pa8::SetConfiguration (Mcucpp::IO::Pa8::Port::AltFunc); // Mcucpp::IO::Pa8::SetSpeed (Mcucpp::IO::Pa8::Port::Fastest);
好了,现在我们在GPIOB中设置数据数组的输出:
typedef Mcucpp::IO::Pb0 dmaTest0; typedef Mcucpp::IO::Pb1 dmaTest1; ... // GPIOB dmaTest0::ConfigPort::Enable(); dmaTest0::SetDirWrite(); dmaTest1::ConfigPort::Enable(); dmaTest1::SetDirWrite(); uint16_t dataForDma[]={0x0000,0x8001,0x0000,0x8001,0x0000, 0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001,0x0000,0x8001}; typedef Mcucpp::Dma1Channel1 channel; // dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set(); // , DMA channel::Init (channel::Mem2Mem|channel::MSize16Bits|channel::PSize16Bits|channel::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); while (1) { } }
产生的波形与PSoC上的波形非常相似。

中间是一个大的蓝色驼峰。 这是DMA初始化过程。 左侧的蓝色脉冲完全由PB1上的软件接收。 扩大他们:

每个脉冲2次测量。 系统的运行符合预期。 但是,现在让我们来看一下主波形上带有深蓝色背景的较大区域。 此时,DMA模块已经在运行。
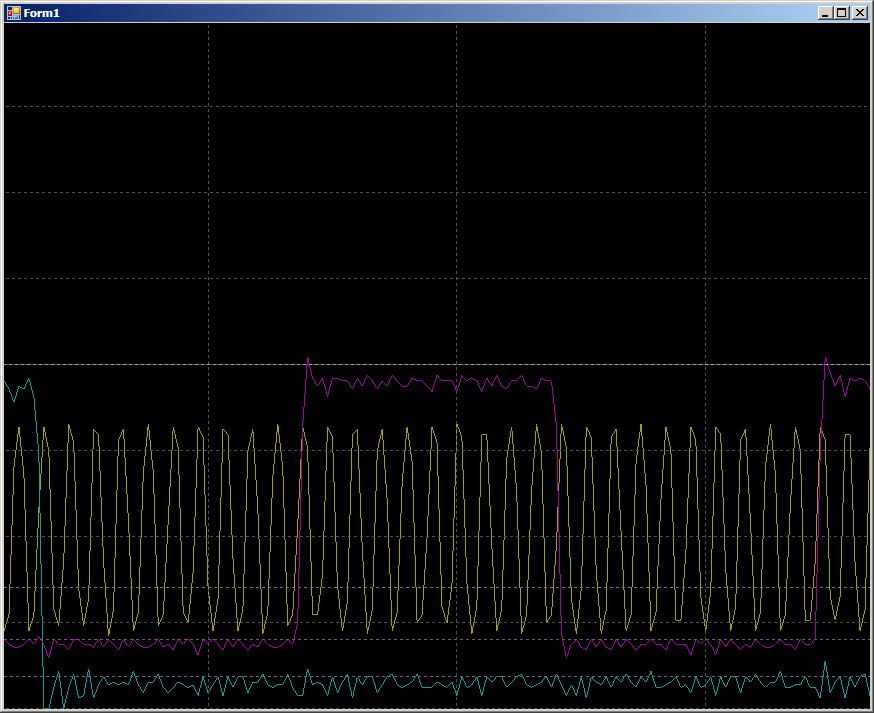
每个GPIO线更改10个周期。 实际上,工作由RAM进行,程序以恒定周期循环。 处理器内核没有对RAM的调用。 总线完全由DMA单元处理,但需要10个周期。 但是实际上,结果与在PSoC上看到的结果并没有很大不同,因此只需开始查找与STM32上的DMA相关的应用笔记。 有几个。 F0 / F1上有AN2548,L0 / L1 / L3上有AN3117,F2 / F4 / F77上有AN4031。 也许还有更多...
但是,尽管如此,从他们那里我们也看到延迟归咎于此。 而且,F103无法通过DMA批量访问总线。 对于F4,它们是可能的,但最多四个字。 然后,再次会出现等待时间问题。
让我们尝试执行相同的操作,但是要借助程序记录。 在上面,我们看到了直接记录到端口的过程立即进行。 但是有一个完美的记录。 行数:
// dmaTest1::Set(); dmaTest1::Clear(); dmaTest1::Set();
遵循此类优化设置(您必须指定时间的优化):

变成了以下汇编代码:
STR r6,[r2,#0x00] MOV r0,#0x20000 STR r0,[r2,#0x00] STR r6,[r2,#0x00]
在实际复制中,将有一个对源,对接收者的调用,循环变量的更改,分支……通常,会有很多开销(据认为,这只是消除了DMA)。 港口变化的速度如何? 因此,我们写:
uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
此C ++代码变成这样的汇编代码:
MOVS r1,#0x0E LDRH r3,[r0],#0x02 STRH r3,[r2,#0x00] LDRH r3,[r0],#0x02 SUBS r1,r1,#2 STRH r3,[r2,#0x00] CMP r1,#0x00 BGT 0x080032A8
我们得到:
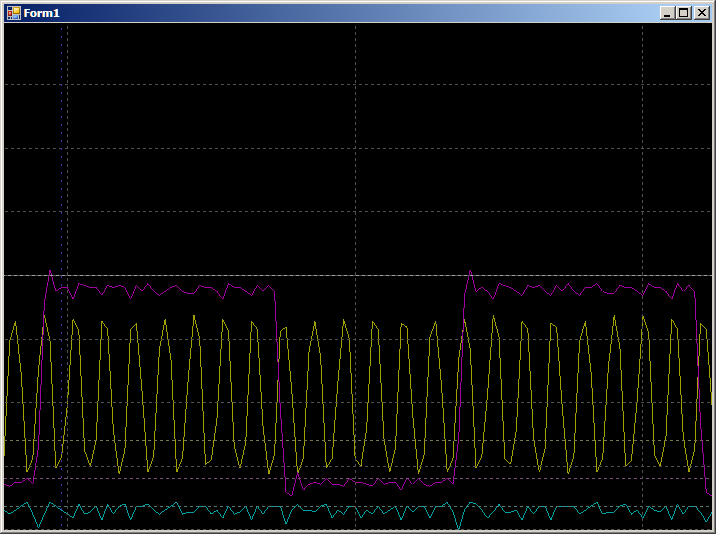
在上半个周期中有8个小节,在下半个周期中有6个小节(我检查过,所有半周期都重复该结果)。 之所以出现差异,是因为优化程序每次迭代制作了2个副本。 因此,将一半期间之一中的2个小节添加到分支操作中。
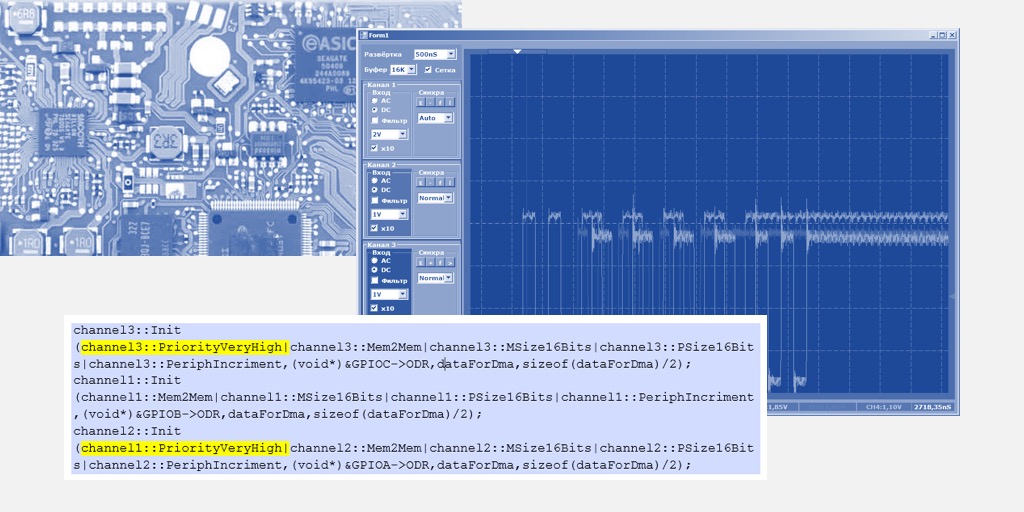
粗略地说,使用软件复制时,要用14个小节来复制两个字,而用20个小节来复制两个字,但是要用DMA。 结果已被详细记录,但对于那些尚未阅读扩展文献的人来说是非常出乎意料的。好啊 但是,如果您一次开始在两个DMA流中写入数据会怎样? 多少速度会下降? 将蓝光连接到PA0并按如下所示重写程序:
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
首先,让我们检查一下脉冲的性质:
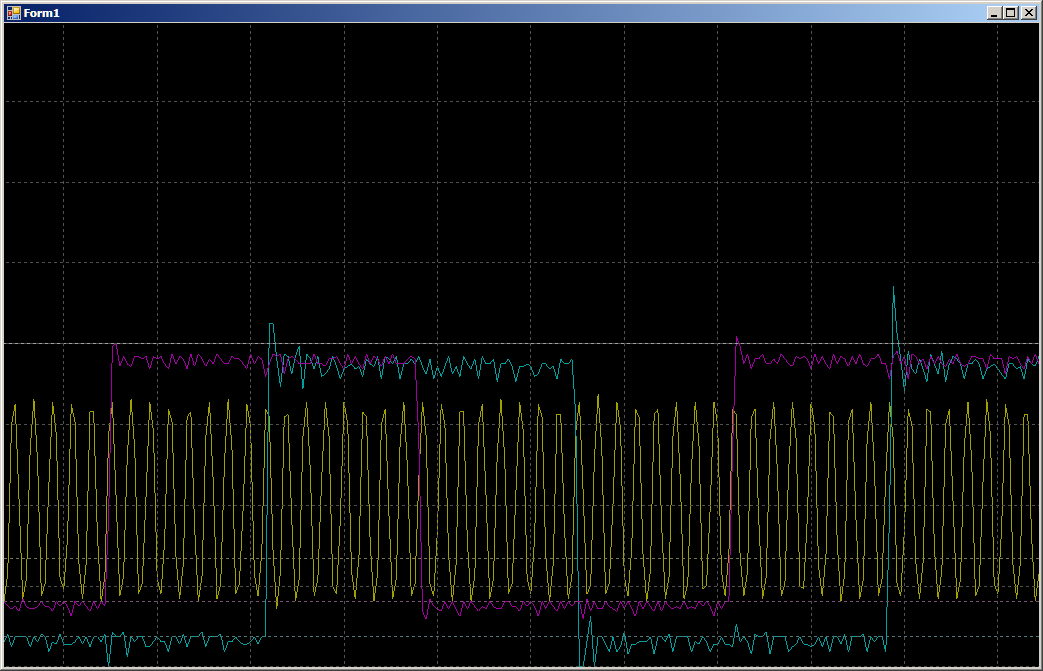
在调谐第二个通道时,第一个通道的复制速度较高。 然后,成对复制时,速度下降。 当第一个频道结束时,第二个频道开始更快地工作。 一切都是合乎逻辑的,只剩下确切地找出速度下降了多少。
虽然只有一个通道,但是录制需要10到12小节(数字是浮动的)。

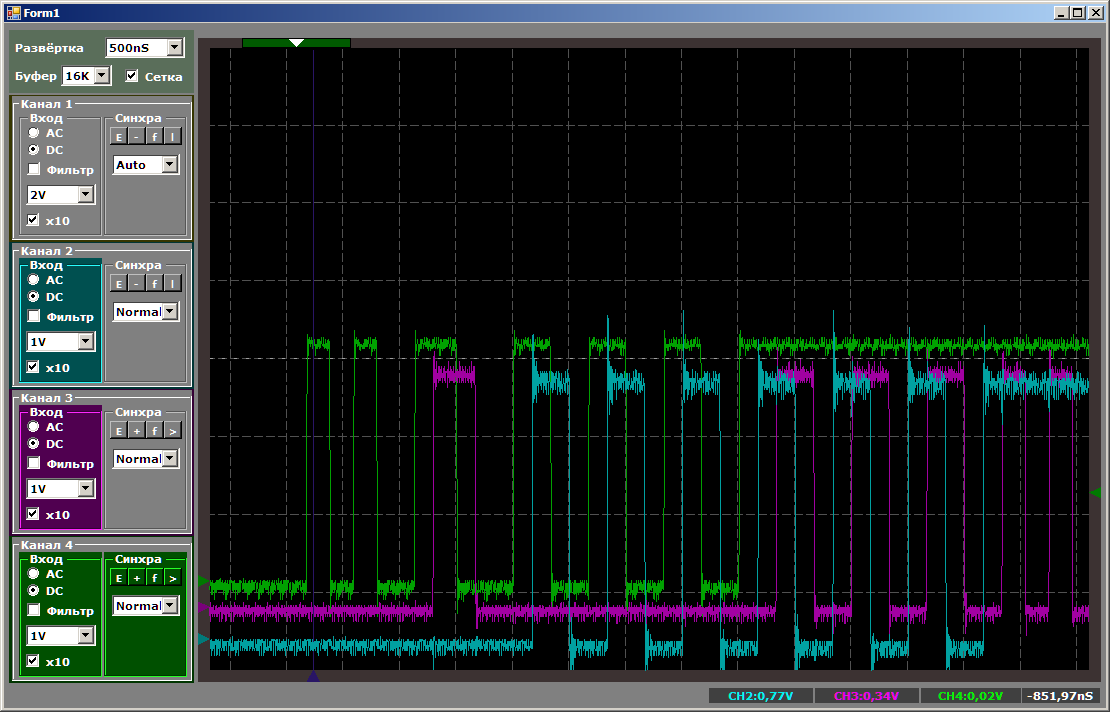
在协作期间,我们在每个端口的每个记录获得16个周期:
也就是说,速度不会减半。 但是,如果您一次开始在三个线程中编写该怎么办? 由于未输出PC0,因此添加了PC15的工作(这就是为什么不在数组中发出0、1、0、1 ...而是0x0000,0x8001,0x0000,0x8001 ...的原因)。
typedef Mcucpp::Dma1Channel1 channel1; typedef Mcucpp::Dma1Channel2 channel2; typedef Mcucpp::Dma1Channel3 channel3; // , DMA channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2);
在这里结果出乎意料,以至于我关闭了显示时钟频率的光束。 我们没有时间进行测量。 我们看工作的逻辑。

直到第一个频道完成工作,第三个频道才开始工作。 三个频道无法同时使用! 可以从AppNote到DMA推论这个话题,它表示F103在一个块中只有两个Engine(并且我们使用一个DMA块进行复制,第二个现在处于空闲状态,并且本文的内容已经足够我可以使用了)我不会)。 我们重写示例程序,以使第三个通道比其他所有人更早开始:

相同的文字: // , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
图片将发生如下变化:

启动了第三个渠道,甚至与第一个渠道一起工作,但是当第二个渠道进入业务时,第三个渠道被取代,直到第一个渠道完成。
关于优先事项
实际上,前面的图片与DMA的优先级有关,有一些。 如果所有工作频道都具有相同的优先级,则它们的编号会起作用。 在一个给定的优先级之内,编号较小的是优先级。 让我们尝试第三个渠道来指示不同的全局优先级,将其提高到所有其他优先级之上(顺便说一句,我们还将提高第二个渠道的优先级):

相同的文字: channel3::Init (channel3::PriorityVeryHigh|channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel1::PriorityVeryHigh|channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2);
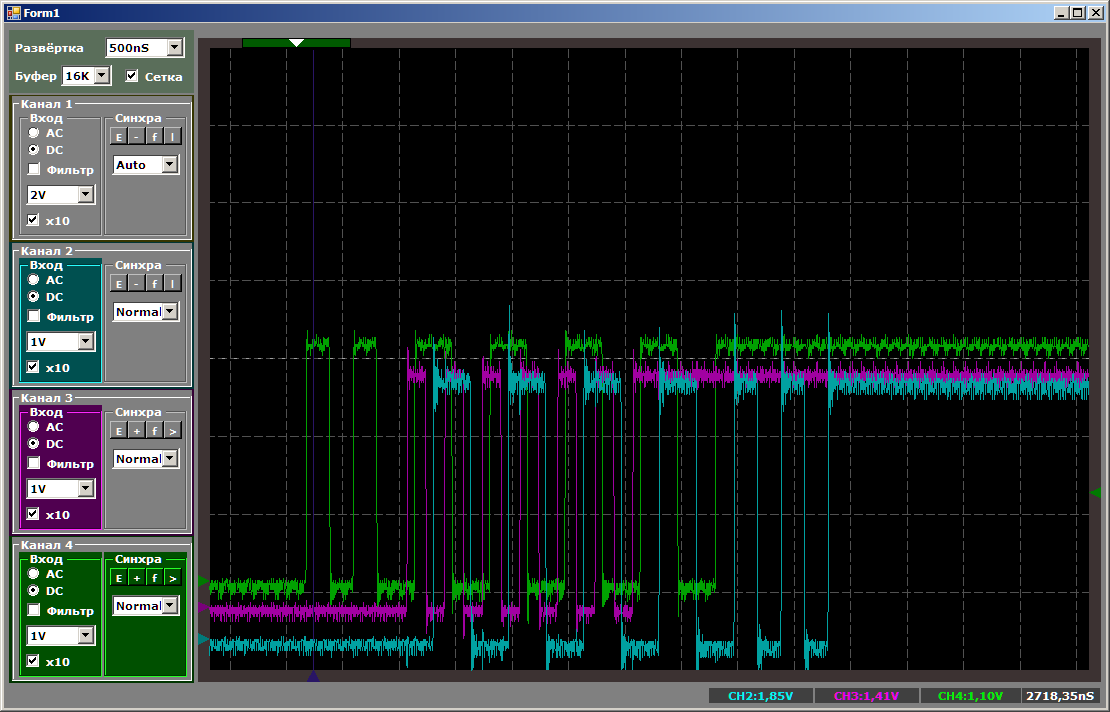
现在,第一个曾经最酷的将处于不利地位。
总的来说,我们看到即使在优先级方面发挥作用,STM32F103也不能在一个DMA模块上启动两个以上的线程。 原则上,第三个线程可以在处理器内核上运行。 这将使我们能够比较性能。
// , DMA channel3::Init (channel3::Mem2Mem|channel3::MSize16Bits|channel3::PSize16Bits|channel3::PeriphIncriment,(void*)&GPIOC->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint16_t* src = dataForDma; uint16_t* dest = (uint16_t*)&GPIOB->ODR; for (int i=sizeof(dataForDma)/sizeof(dataForDma[0]);i>0;i--) { *dest = *src++; }
首先,一般图片显示所有内容都可以并行工作,并且处理器核心具有最高的复制速度:
现在,我将为所有人提供机会,在所有副本流都处于活动状态时计算度量值:
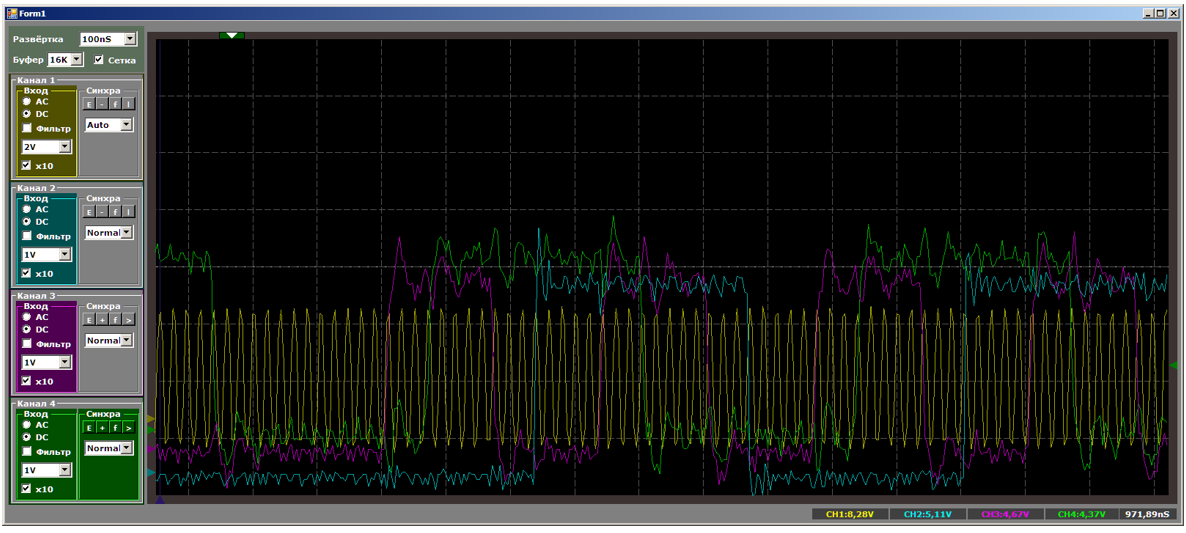
处理器核心优先处理所有
现在让我们回到一个事实,即在双线程操作期间,第二个通道被调谐时,第一个通道以不同数量的时钟周期发出数据。 在DMA的AppNote中也充分记录了这一事实。 事实是,在第二个通道的建立过程中,对RAM的请求会定期发送,并且访问RAM时,处理器内核的优先级高于DMA内核。 当处理器请求一些数据时,DMA占用了时钟周期,因此延迟接收数据,因此复制速度较慢。 让我们做今天的最后一个实验。 让我们把工作带到一个更真实的地方。 启动DMA之后,我们将不会进入一个空循环(绝对不能访问RAM),但是将执行从RAM到RAM的复制操作,但是此操作与DMA内核的操作无关:
channel1::Init (channel1::Mem2Mem|channel1::MSize16Bits|channel1::PSize16Bits|channel1::PeriphIncriment,(void*)&GPIOB->ODR,dataForDma,sizeof(dataForDma)/2); channel2::Init (channel2::Mem2Mem|channel2::MSize16Bits|channel2::PSize16Bits|channel2::PeriphIncriment,(void*)&GPIOA->ODR,dataForDma,sizeof(dataForDma)/2); uint32_t src1[0x200]; uint32_t dest1 [0x200]; while (1) { uint32_t* src = src1; uint32_t* dest = dest1; for (int i=sizeof(src1)/sizeof(src1[0]);i>0;i--) { *dest++ = *src++; } }

在某些地方,周期从16小节延长到17小节。 我担心情况会更糟。
开始下结论
实际上,我们转向我想说的。
我从远处开始。 几年前,我开始研究STM32,然后研究了当时存在的用于USB的MiddleWare版本,并想知道为什么开发人员删除了通过DMA进行的数据传输。 显然,最初出现了这样的选择,然后将其移至后院,最后只有一些雏形。 现在,我开始怀疑我对开发人员的了解。
在
关于UDB的
第一篇文章中,我曾说过,尽管UDB可以处理并行数据,但不太可能用它自己代替GPIF,因为FX2LP的PSoC USB总线以全速或高速运行。 事实证明,还有一个更严重的限制因素。 DMA根本没有时间以与GPIF相同的速度来传送数据,即使在控制器内,也没有考虑USB总线。
如您所见,没有单个实体DMA。 首先,每个制造商都按自己的方式做。 不仅如此,即使是一家面向不同家庭的制造商也可以改变构建DMA的方法。 如果您打算认真加载此设备,则应仔细考虑是否满足需求。
可能有必要用一种乐观的话语淡化悲观的情绪。 我什至会突出她。
Cortex M控制器的DMA使您能够按照著名的标枪的原理提高系统性能:“启动并忘记”。 是的,软件复制数据要快一点。 但是,如果您需要复制多个线程,则没有优化器可以使处理器将它们全部驱动,而没有寄存器重新加载和旋转循环的开销。 此外,对于慢速端口,处理器必须仍然等待可用性,而DMA在硬件级别执行此操作。但是即使在这里,各种细微差别也是可能的。 如果端口仅相对较慢...例如,以最高可能的频率运行的SPI,则从理论上讲可能存在DMA没有时间从缓冲区收集数据而发生溢出的情况。 反之亦然-将数据放入缓冲寄存器中。 当数据流为单个时,这不太可能发生,但是当数据流很多时,我们看到了会发生什么惊人的叠加。 为了解决这个问题,您不应该单独开发任务,而应该联合开发。 测试人员会尝试引发此类问题(对测试人员而言是破坏性的工作)。
再一次,没有人隐藏此数据。 但是由于某种原因,所有这些通常不包含在主文档中,而是包含在应用说明中。 因此,我的任务是引起程序员的注意,即DMA不是灵丹妙药,而只是方便的工具。
但是,当然,不仅程序员,而且硬件开发人员也是如此。 说,在我们的组织中,正在开发大型软件和硬件组合,用于嵌入式系统的远程调试。 这个想法是有人在开发设备,但想从侧面订购“固件”。 并且由于某种原因,无法向一侧提供设备。 它可能体积庞大,价格昂贵,可能是独特的并且“需要您自己”,不同的团队可以在不同的时区使用它,提供某种多班制工作,因此可以不断地想到它……总的来说,您可以提出自己的理由很多情况下,我们小组只是把这项任务视为理所当然。
因此,调试中心应该能够模拟尽可能多的外部设备,从简单的按钮模拟到各种SPI,I2C,CAN,4-20 mA协议以及其他其他东西,以便仿真器可以通过它们重现外部的不同行为。与正在开发的设备相连的模块(我个人曾经为直升机附件的地面调试制作了很多模拟器,在我们的
网站上,用Cassel Aero一词搜索了相应的案例 )。
等等,在技术要求上有一定的发展要求。 这么多的SPI,那么多的I2C和这么多的GPIO。 它们必须以这样的极端频率运行。 一切似乎都很清楚。 我们将STM32F4和ULPI放在HS模式下使用USB。 该技术已被证明。 但是,这是一个漫长的周末,与11月的假期有关,我在UDB那里就知道了。 看到有什么问题,晚上我得到了本文开头给出的实际结果。 我意识到,一切当然都很棒,但是对于这个项目却不是。 正如我已经指出的那样,当可能的峰值系统性能接近上限时,所有内容都不应单独设计,而要设计复杂。
但是,这里的任务综合设计原则上不可能。
今天,我们正在使用一种第三方设备,明天-则完全不同。对于每种仿真情况,程序员将自行决定使用总线。因此,该选项被拒绝,在电路中添加了许多不同的FTDI桥。在桥接器中,将根据严格的方案来解析一个,两个或四个功能,并且在桥接器之间,USB主机将解析所有内容。 las DMA. , , , , – , .
. DMA (, 10: 1 , , 1 , 10 ) .