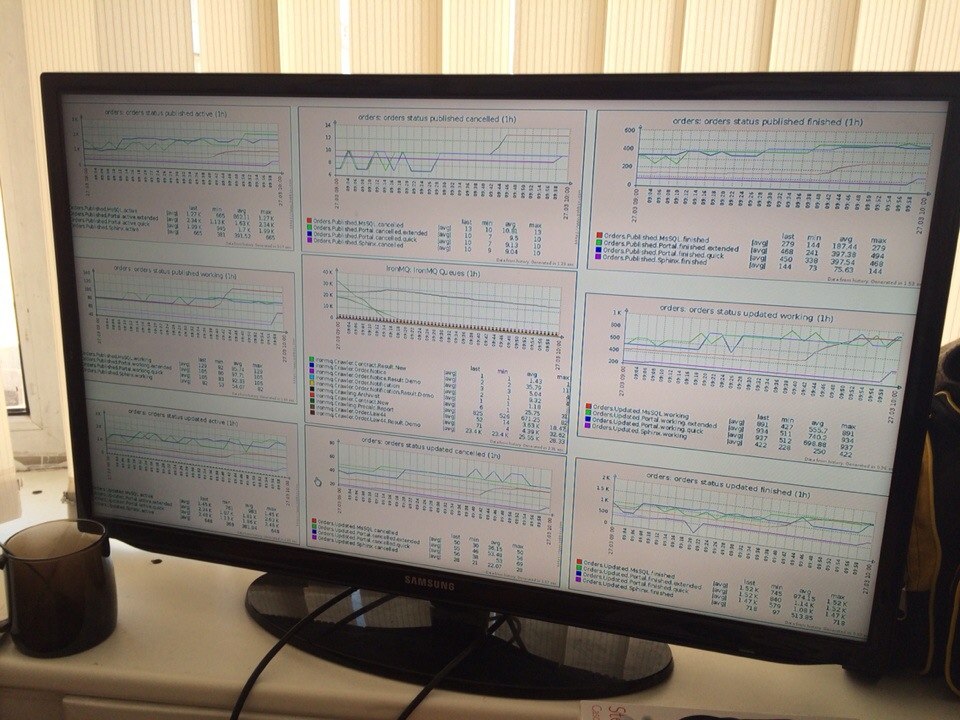
监视是基础架构中最重要的部分。 监视是系统工程师的基础。 但是,每个人都有自己的理解方式。 我的方式包括否认。 愤怒和接受。
拒绝

很难相信,但是照片上有一个服务器室 。
那是2007年。我在大二时就读于信息安全系的CSU(车里雅宾斯克州立大学)。 我决定申请CSU作为信息安全实验室的助理。 这是一个临时的兼职工作。 在那之后的2009年,我又在一家贸易生产组织获得了兼职的永久性工作,担任系统管理员。 那个时候,我不习惯监视,我被弄湿了,以为可以成为英雄来解决任何面临的问题。 希望那是我一生的短暂时期,我觉得那是错误的。
怒气

2010年是最疲惫的一年之一。 我曾为2位雇主工作; 进行课程; 正在准备硕士论文; 而且,我是省长。 在经验压力下,我对监视的看法正在发生变化。 我辞职后,这一过程发生了冲突。 在毕业考试之前,我决定辞职并寻找一份新工作。 绝大多数面试官都因为我是学生而感到困惑。 但是,其中一个人同意雇用我,我在一家国际跨国公司担任全职长期工作。 我毕业了 我正在提高技能和经验,曾在人员编制公司工作。 我们的绝大多数项目都是令人惊叹且有趣的创业公司。 我极大地提高了自己的资格,因为对于单人来说,没有其他方法可以使用400台服务器。 在成为主流之前,我曾担任过DevOps。 我在工作上精疲力尽,决定换工作。
我以为那个时候我们必须监视所有事情。 这真的很重要。 每个人都应该收到监视通知。 此外,监视工具集也在不断变化和改进。 最早的实现之一是bash / PowerShell脚本(可用空间,可用更新计数,备份状态等)和外部服务Red Alert,懒惰的农民(用于站点检查的内部工具)。 在2010-2011年,这已经足够了,但是,我们面临许多不同的问题:
我们决定让我们的生活更轻松一些,然后选择Zabbix。 我们监视了所有内容:
- 连接到wifi的用户数。
- 打印页数。
- 计算存活的VPN隧道。
- 服务器温度。
- 网络负载。
- 等...
另外,我想分享一些面临的问题:
- 有跨DC的分布式基础架构和许多指标。 我们面临有时缺少指标的情况。 我们通过Zabbix代理对其进行了修复。
- 如果VPN隧道失败,我们将收到大量消息。 我们配置了基础架构依赖性。
- 我们自动化了重复任务。 即在可用空间不足的情况下,我们尝试自动清洁它。
- 我们知道,如果在30秒钟内将CPU平均负载指标超过95%通知他人,那是个坏主意,因此,我们添加了阈值周期之类的内容。
- 我们检查了业务关键型方案(即Web登录,搜索等)。
- 由于聊天操作,我们将Zabbix添加到了Skype集成中。
- Quis custodiet ipsos custodes?。
- 等...
验收
稍后,我了解到,一方面,业务人员不在乎RAM / CPU / IOPS。 他们对TTM(上市时间)和业务指标感兴趣,但另一方面,IT专家应该能够追踪任何类型的问题。
外卖
- 拒绝 。 您不应该监视任何内容,因为如果发生奇怪的事情,您的用户会标记您。
- 怒气 您必须监视所有内容。 如果在30秒钟内CPU平均负载指标超过95%,则可以通知CTO / CEO。
- 验收 商务人士不在乎RAM / CPU / IOPS。 他们对TTM(上市时间)和业务指标的兴趣。
Zabbix足够出色,但是世界正在发生变化。 有很多现代的监视方法。
- 可以将整体监控应用程序划分为不同的级别:收集,存储和显示。
- 业务和IT必须使用完全相同的数据,但是他们应该以不同的角度看待数据。
- 没有灵丹妙药,这意味着您应该自定义解决方案。
聚苯乙烯